

Machine Learning: Besser kategorisieren mit Topic Modeling
Machine Learning kann dabei helfen, Texte zu kategorisieren. Ein gutes Framework für das Topic Modeling ist BERTopic.

(Bild: Shutterstock.com/calimedia)
- Manuel Hartenfels
Beim Bearbeiten von Kundenanfragen spielt die Kategorisierung eine zentrale Rolle. In vielen Prozessen ist das Einordnen in Themengebiete entscheidend für die korrekte Zuordnung zu einer Personengruppe, die die Anfrage bearbeiten soll.
Diese Klassifizierung bietet einen idealen Ansatzpunkt, um den Kundenanfrageprozess schrittweise zu automatisieren. Verfahren des maschinellen Lernens und insbesondere künstliche neuronale Netze sind gut geeignet. Da es sich bei den Anfragen häufig um Texte wie E-Mails handelt, ist vor allem das Teilgebiet Natural Language Processing (NLP) interessant. Es umfasst diverse Techniken zum Erfassen und Verarbeiten natürlicher Sprache.
Videos by heise
Das Kategorisieren läuft üblicherweise folgendermaßen ab: Zunächst legt das Team ein Schema aus hierarchisch geordneten Kategorien fest, wofür es meist das Domänenwissen des Fachbereichs nutzt. Anschließend sammelt es Kundenanfragen und bestimmt deren Kategorie manuell (Labeling). Mit diesen Daten kann es einen geeigneten Algorithmus trainieren, um künftige Anfragen möglichst akkurat zu kategorisieren. Um die Qualität der Kategorisierung abschätzen zu können, nutzt das Team unterschiedliche Metriken wie die Genauigkeit (Accuracy).
Bei dieser Vorgehensweise liegt der Fokus auf dem Anlegen und Evaluieren eines geeigneten Klassifizierungsalgorithmus. Dabei verliert man jedoch schnell einen der Faktoren aus den Augen: das Erstellen des Kategorienschemas. Da es häufig eine Aufgabe des Fachbereiches ist, kann die algorithmische Sichtweise zu kurz kommen. Wenn die Verantwortlichen die Kategorien beispielsweise anhand des Organigramms oder nach Produktarten festlegen, kann es für einen Algorithmus schwierig sein, diese Zusammenhänge durch die Analyse von Kundenanfragen zu erkennen.
Wenn beispielsweise die Verantwortung für die Kategorien "Reklamation Produktverpackung" und "Reklamation Versandverpackung" in unterschiedlichen Abteilungen liegt, kann der Algorithmus Anfragen eventuell nicht passend zuordnen.
Um ein besseres Klassifizierungsergebnis zu erreichen, liegt es daher nahe, einem Algorithmus ohne Vorwissen das Erstellen eines Kategorienschemas zu überlassen.
Der gebräuchlichste Ansatz dafür ist das Topic Modeling. Dabei erhält der Algorithmus einen (ungelabelten) Datensatz, aus dem er die dominanten Themenfelder selbstständig extrahieren soll. Besonders einfach ist eine Umsetzung mit dem Framework BERTopic, das im Folgenden als Grundlage dient.
Texte mit Embeddings aufbereiten
Damit ein Algorithmus mit geschriebenen Wörtern umgehen kann, gilt es zunächst, die Texte in eine numerische Repräsentation umzuwandeln. Häufig kommen dafür Embeddings zum Einsatz, die versuchen, Fragmente des Textes wie Wörter, Sätze, Abschnitte und Dokumente in Vektoren umzuwandeln und semantisch ähnliche Elemente innerhalb des Embedding-Raums nahe zueinander platzieren. Dafür existieren unterschiedliche Varianten wie Bag of Words, Word2Vec und Transformer-Modelle. Die Stärke von Letzteren liegt in ihrer Fähigkeit Kontext besonders gut abbilden zu können, weshalb sie bei BERTopic vornehmlich zum Einsatz kommen.
Die daraus resultierenden Vektoren sind hochdimensional. BERT-Modelle liefern beispielsweise Vektoren mit 768 Dimensionen oder mehr. Die hohe Zahl der Dimensionen birgt einige Herausforderungen, die sogenannte Curse of Dimensionality. Die offensichtlichsten sind eine höhere Komplexität der Modelle und damit einhergehend eine höhere Anforderung an die Rechenleistung. Weniger offensichtlich ist das Verhalten von Distanzmetriken in höherdimensionalen Räumen. Das Verhältnis zwischen dem Abstand eines Punktes zu seinem nächsten und zu dem am weitesten entfernten Nachbarn verliert an Aussagekraft, da es je nach gewählter Metrik entweder gegen null, gegen einen bestimmten Wert oder gegen unendlich tendiert. Daher gilt die Faustregel: Je höher die Dimension ist, desto niedriger sollte die Norm sein.
Dimensionen reduzieren mit UMAP
Das Ziel der Dimensionalitätenreduktion ist es, die Vektoren in einen Raum mit weniger Dimensionen zu transformieren und dabei möglichst wenige Informationen zu verlieren.
Ein passender Algorithmus, der auch häufig für die Visualisierung von Embeddings zum Einsatz kommt, ist t-Distributed Stochastic Neighbor Embedding (t-SNE). Er projiziert die hochdimensionalen Vektoren in einen zwei- oder dreidimensionalen Raum und versucht dabei, keine Informationen über deren Lokalität zu verlieren.
t-SNE projiziert in einem ersten Schritt die Daten beliebig in den neuen Raum. Anschließend berechnet er ein Ähnlichkeitsmaß für alle Punkte im ursprünglichen Raum. Dazu zentriert er eine Wahrscheinlichkeitsfunktion (im Fall von t-SNE meist eine T-Verteilung) um einen Punkt. Sie dient dazu, die Ähnlichkeit zu anderen Datenpunkten zu ermitteln. Die Metrik drückt aus, wie wahrscheinlich es ist, dass ein Punkt einen anderen als seinen Nachbarn auswählt. Anschließend verschiebt t-SNE die Daten in dem neuen Raum in einer Weise, bei der das Ähnlichkeitsmaß der Punkte möglichst gleich bleibt.
Eine Weiterentwicklung von t-SNE ist Uniform Manifold Approximation and Projection (UMAP). Der Algorithmus hat viele Gemeinsamkeiten mit t-SNE, optimiert jedoch zusätzlich einige Details. Unter anderem initialisiert er die Datenpunkte in dem neuen Raum nicht zufällig, und die Platzierung erfolgt nicht für alle Punkte gleichzeitig, sondern immer nur für einen kleinen Teil.
Diese Verbesserungen sorgen dafür, dass sich UMAP für größere Datensätze mit mehr Dimensionen eignet. Außerdem zeigt sich, dass der Algorithmus im Vergleich zu t-SNE lokale und globale Strukturen besser abbilden kann. Bei UMAP lässt sich die Anzahl der Dimensionen des Raums, in den der Algorithmus die Punkte projiziert, als Hyperparameter angeben. Bei BERTopic ist dieser Wert beispielsweise standardmäßig auf fünf eingestellt.
Clustering mit HDBSCAN
Um Gruppen mit ähnlichen Datenpunkten zu selektieren, kommt der Cluster-Algorithmus Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) zum Einsatz. Dabei handelt es sich um ein dichtebasiertes, hierarchisches Clustering-Verfahren, das anders als Algorithmen wie k-Means keine Annahmen über die Form der Cluster macht. Zur Veranschaulichung soll ein Datensatz mit lediglich einer Dimension dienen.

Die Wahrscheinlichkeitsverteilung in Abbildung 2 zeigt, dass Bereiche mit einer hohen Punktdichte eine hohe Wahrscheinlichkeit haben.
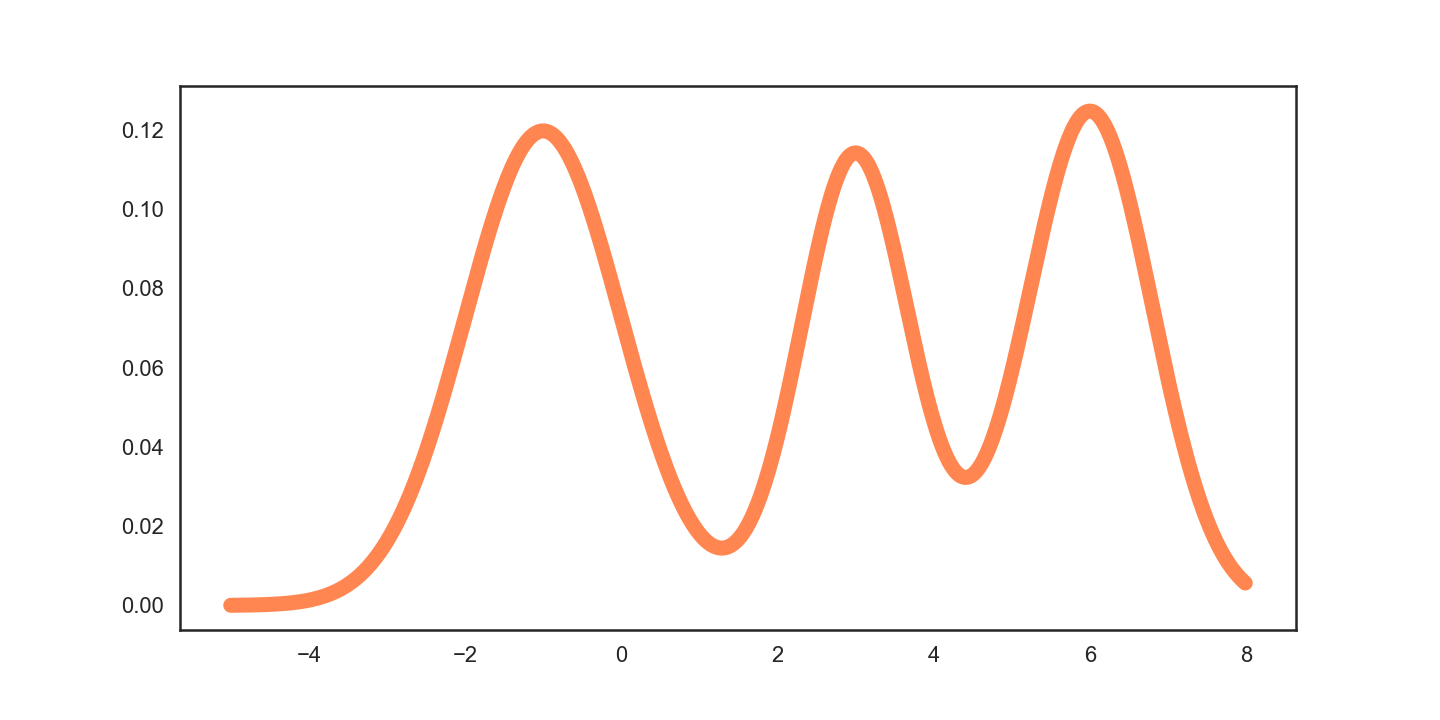
Das bedeutet im Umkehrschluss, dass sich für eine bekannte Wahrscheinlichkeitsfunktion recht einfach Cluster, also Punkte mit einer hohen Dichte, extrahieren lassen. Dazu bestimmt man einfach einen beliebigen Grenzwert λ und definiert alle zusammenhängenden Punkte mit einer höheren Wahrscheinlichkeit als λ als Cluster. Das Bestimmen dieses Grenzwerts gestaltet sich jedoch schwierig und wenig intuitiv.
Außerdem funktioniert diese Herangehensweise bei Clustern mit unterschiedlichen Dichten nur eingeschränkt. Hinzu kommt, dass die Wahrscheinlichkeitsdichtefunktion eines Datensatzes selten bekannt ist. Um sie anzunähern, verwendet HDBSCAN den Abstand zu den n nächsten Nachbarpunkten. Anschaulich betrachtet sucht der Algorithmus für jeden Punkt einen Kreis, der eine Anzahl n nächster Nachbarn einschließt. Das Ergebnis heißt Core Distance. Je niedriger der Wert für einen Punkt, desto dichter ist die Region um ihn herum.
Dabei kommt die vorher durchgeführte Dimensionsreduktion zum Tragen, da bei einer zu hohen Zahl der Dimensionen die Gefahr bestünde, dass der Abstand zwischen allen Punkten ähnlich ist (Curse of Dimensionality). Der Kehrwert der Core Distance approximiert die tatsächliche Wahrscheinlichkeitsverteilung recht gut.
Um Regionen mit einer hohen Dichte besser von denen mit einer geringen Dichte separieren zu können, verwendet HDBSCAN eine Metrik namens Mutual Reachability Distance (MRD), die folgendermaßen definiert ist:
dmreach-k (a,b)=max{ corek(a),corek(b), d(a,b)}
Ziel ist es, Punkte mit einer geringen Dichte weiter voneinander zu entfernen, um bessere Cluster finden zu können. Abbildung 3 zeigt das Konzept mit drei Punkten und deren Core Distance.
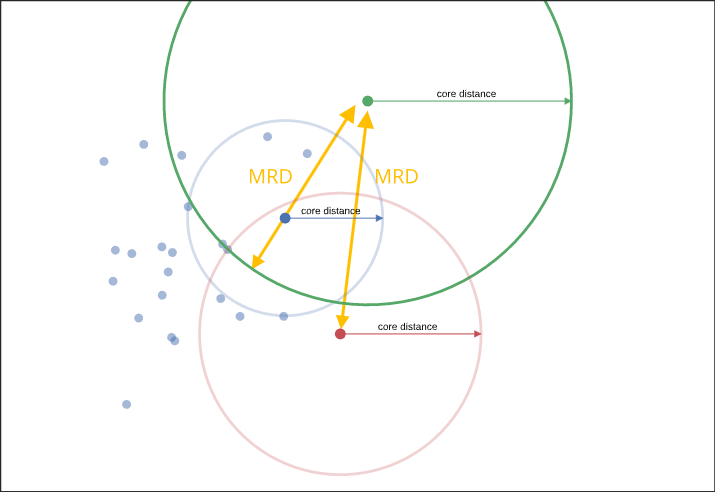
Die MRD zwischen dem blauen und dem grünen Punkt in der Abbildung ist die Core Distance des grünen Punkts, da sie größer ist als die Core Distance des blauen und als der Abstand der beiden Punkte zueinander. Somit wird der grüne Punkt weiter von dem blauen weggeschoben. Anders ist es zwischen dem roten und dem grünen Punkt: Da die MRD dem Abstand zwischen den beiden Punkten entspricht, ändert sich nichts.
Der Algorithmus ermittelt die einzelnen Cluster, indem er zunächst alle Punkte filtert, deren Core Distance niedriger als der Wert λ ist. Die damit selektierten Punkte verbindet er zu einem Cluster, wenn ihr Abstand nicht größer als λ ist. Allgemein ausgedrückt: Zwei Punkte werden miteinander verbunden, wenn sie zwei Bedingungen erfüllen: Sie müssen einen geringen Abstand zueinander haben und sich in einer dichten Region befinden. Diese Voraussetzungen spiegeln sich in der Formel zur Mutual Reachability Distance wieder. Die ersten beiden Terme beschreiben die Core Distance und der letzte den benötigten Abstand der Punkte zueinander. Nach einem Durchlauf, wiederholt man den Vorgang mit einem höheren λ.
Durch das Verändern von λ können neue Verbindungen zwischen Punkten entstehen, die sich bereits in einem Cluster befinden, sozusagen als Abkürzung. Diese sind jedoch irrelevant, da nur neu geschaffene Beziehungen zwischen einzelnen Regionen von Bedeutung sind.
Zusammengefasst gilt am Anfang des Prozesses jeder Punkt als separates Cluster, und durch das Verändern von λ sucht der Algorithmus die kürzesten Verbindungen zwischen den Clustern. Beendet ist der Prozess, wenn nur noch ein Cluster vorhanden ist, also alle Punkte miteinander verbunden sind. Das Resultat ist ein minimaler Spannbaum (Minimum Spanning Tree, MST): ein Graph, der alle Knoten enthält. Die Kanten zwischen den Punkten sind dabei durch die MRD gewichtet.
