

CQRS – neues Architekturprinzip zur Trennung von Befehlen und Abfragen
Command Query Responsibility Segregation ist ein erfolgreicher Gegenentwurf zum klassischen Schichtenmodell für Systeme mit parallelem Nutzerzugriff. Das Prinzip fordert eine Aufteilung in Verhaltens- und Abfragemodelle, mit der man die Geschäftslogik als wertvollsten Bestandteil einer Anwendung von der Datenbereitstellung für Benutzerschnittstellen und Reporting entkoppelt entwickeln kann.
- Marco Heimeshoff
- Philip Jander

CQRS ist ein erfolgreicher Gegenentwurf zum klassischen Schichtenmodell für Systeme mit parallelem Nutzerzugriff. Das Prinzip fordert eine Aufteilung in Verhaltens- und Abfragemodelle, mit der man die Geschäftslogik als wertvollsten Bestandteil einer Anwendung von der Datenbereitstellung für Benutzerschnittstellen und Reporting entkoppelt entwickeln kann.
Das Architekturprinzip CQRS (Command Query Responsibility Segregation) fordert im Kern die Aufteilung der Softwarearchitektur in zwei Teile [1, 2, 3, 4]. Diese haben klar getrennte Verantwortlichkeiten: einerseits für das Ausführen von Befehlen (Commands), die eine Zustandsänderung des Softwaresystems nach sich ziehen, andererseits für das seiteneffektfreie Bedienen von Abfragen (Queries). Diese Trennung ist eine Weiterführung von Bertrand Meyers CQS-Prinzip (Command Query Separation) [5, 6], das eine analoge Trennung für einzelne Methoden eines Interfaces verlangt.
CQRS ist durchaus keine neue Idee. Es ist vielmehr als zeitgemäßer Gegenentwurf zum allgegenwärtigen vertikalen Schichtenmodell typischer n-tier Anwendungen zu sehen. Die hierbei übliche Anordnung von Datenbank (relational), Datenzugriffsschicht (O/R Mapper), Geschäftslogik, Applikationsschicht und Präsentationsschicht bedingt in der Regel eine Verletzung des Single-Responsibility-Prinzips (SRP) [7] auf Ebene der Softwarearchitektur. Datenzugriffsschicht und Geschäftslogik werden sowohl zur Validierung und Ausführung von Benutzeraktionen herangezogen als auch für das Bereitstellen von Daten zur Anzeige in Präsentationsschicht und Reporting. Diese Verflechtung zweier unterschiedlicher Verantwortlichkeiten gehen Entwickler und Architekten oft unreflektiert und mit fatalen Folgen ein. Sie führt dazu, dass die Umsetzung der Anforderungen an die Prozesslogik durch Notwendigkeiten der einigermaßen performanten Abfragebearbeitung kompromittiert wird. Im Gegenzug stört implementiertes Verhalten dabei, größere Datenmengen an Abfragen performant zurückzuliefern.
CRUD
CRUD steht für Create, Read, Update und Delete, also ausschließlich grundlegende Datenbankoperationen ohne jegliche Funktion aus der eigentlichen Anwendungsdomäne.
Sollten so konstruierte Systeme parallel von vielen Nutzern verwendet werden, stoßen sie schnell an Grenzen und sind aufwendig zu verbessern. Die Komplexität steigt, und die Wartbarkeit nimmt ab. Der Versuch gegenzusteuern resultiert dann nicht selten in der Vernachlässigung eigentlich gewünschten Verhaltens in der Geschäftslogik und einer Überbetonung von Daten und Strukturen. Im Extremfall erhält man sogenannte Spreadsheet- oder CRUD-Anwendungen (siehe Kasten), bei denen die abzubildenden Prozesse und Geschäftsregeln in Betriebshandbücher und damit aus der Software verdrängt werden. In engem Zusammenhang damit steht das "anämische Domänenmodell", ein Anti-Pattern, das die objektorientierte Modellimplementierung des eigentlichen Verhaltens beraubt und auf Felder und Validierung reduziert ist.
CQRS löst diesen Konflikt durch die Einführung von zwei Modellen, eines für die Abbildung der Geschäftslogik (oft in Form eines objektorientierten Domänenmodells) und eines für die Bereitstellung von Daten (Abfragemodell). Die Aufteilung erlaubt nicht nur, beide Modelle auf ihre jeweilige Verantwortlichkeit hin zu optimieren. Sie ermöglicht wesentlich einfachere Tests der Geschäftslogik und öffnet darüber hinaus den Weg für eine ganze Reihe von Vereinfachungen, die im Wegfall einiger "großer" Techniken gipfeln: O/R Mapper werden ebenso überflüssig wie Datenbankcluster oder Caches, und sogar auf relationale Datenbanken lässt sich verzichten.
Eine prototypische Architektur

CQRS beschreibt eine Architektur mit getrennten Pfaden und Verantwortlichkeiten, mit denen sich einerseits Verhalten zur Änderung des Systemzustands ausführen und andererseits Daten abfragen lassen (Abb. 1). Bei der Auswahl der konkreten Implementierung des Prinzips gibt es viel Gestaltungsspielraum durch unterschiedliche Entwurfsmuster. Auch wenn dieser Spielraum anfangs verwirren mag, ist er hilfreich und wichtig, um die Systemarchitektur optimal an den nichtfunktionalen Anforderungen auszurichten. Der Artikel beschränkt sich auf die Darstellung einer gebräuchlichen Variante. Die Autoren kombinieren CQRS mit dem Persistenzmechanismus Event Sourcing [8] und einem objektorientierten Domänenmodell zum Beispiel nach Domain-Driven Design (DDD) [9, 10, 11] für die Geschäftslogik. Einen Überblick über den Informationsfluss in der Architektur gibt Abbildung 2.

Die einzelnen Komponenten seien im Folgenden vorgestellt.
Komponenten
Aufgabenorientiertes Benutzerinterface (Task-based UI)
Ausgangspunkt für die meisten Vorgänge ist der Benutzer. Aufgabe des UI ist daher, dessen Intention beim Arbeiten mit der Software zu erfassen und in Befehle an die Geschäftslogik zu übersetzen. Um das überhaupt zu ermöglichen, benötigt diese Präsentationsschicht ein inneres Modell der durch den Nutzer auszuführenden Aufgaben (siehe Abb. 3).
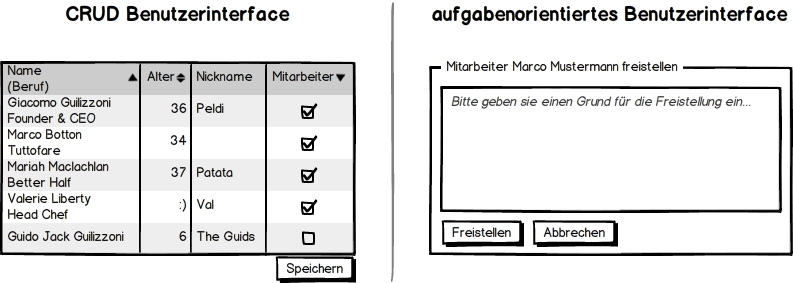
Beispielweise würden die Adressdaten eines Kunden nicht einfach frei zu editieren und zu "speichern" sein. Vielmehr würde man durch geeignete Benutzerführung einen "Umzug" des Kunden an eine neue Adresse vermerken und dabei die neue Anschrift als Parameter angeben. In der Geschäftslogik lässt sich dann zwischen einer Adresskorrektur und einem Umzug unterscheiden. Gegebenenfalls kann man Aktionen auslösen, wie ein Willkommensbrief mit Angabe der nächsten Filiale am neuen Wohnort nebst Geschenkgutschein.
Befehlsobjekte
Kernelement aller CQRS-Implementierungen sind Datentransferobjekte, die einen Befehl an die Geschäftslogik nebst allen dafür notwendigen Daten kapseln. Um die in der Benutzerschnittstelle erfasste Intention nicht zu verlieren, verwendet man spezifische Klassen mit möglichst sprechenden Namen im Imperativ (siehe das folgende Pseudo-Codebeispiel).
class AuftragAnnehmen{
Guid AuftragsId;
Guid KundenId;
String Auftragsnummer;
Auftragsposition[] Zeilen;
Decimal AnteiligerRabatt;
Date AvisierterLiefertermin;
}
Als reine Datenstrukturen ohne Verhalten lassen sich die Befehlsobjekte serialisiert zwischen Clients und Servern übertragen und für Protokollierzwecke speichern. Auch für das Puffern paralleler Benutzeranfragen sind die Befehlsobjekte geeignet.
Die für eine Funktion benötigten Befehlsobjekte ergeben sich direkt aus den jeweiligen Anforderungen. Liegen diese zum Beispiel als Use Case vor, lässt sich dessen Beschreibung oft unmittelbar auf einen oder mehrere Befehle übertragen. Versucht man hingegen, eine wenig dokumentierte, bestehende Anwendung neu zu implementieren, lassen sich Befehle aus den Methodensignaturen eines Domänenmodells extrahieren [12]. Die Befehlsobjekte beschreiben lediglich einen Befehl an das System, enthalten bis auf eventuelle Eingabevalidierung aber keine Logik.
Schnittstelle zur Geschäftslogik (Command Handler)
Für die Ausführung der Befehle ist eine dünne, aber wichtige Schnittstellenschicht verantwortlich, im Englischen als "Command Handler" bezeichnet (siehe auch das folgende Listing). Diese vermittelt nicht nur die Befehlsobjekte als Methodenaufrufe an die zuständigen Entitäten des Domänenmodells, sondern setzt auch Querschnittsbelange wie Autorisierung, Protokollierung und Transaktionen um. Zuletzt ist sie für die Verwertung der Ergebnisse und eventuelle Fehlermeldungen zuständig. Im Beispiel bedeutet das, vom Domänenmodell veröffentlichte Ereignisse zu sichern und an Abonnenten weiterzuleiten. Letztlich stellen die Command Handler eine Konfiguration dar, in der sich für jeden definierten Befehl die Ausführung unterschiedlich handhaben lässt. Während sich zum Beispiel für einfache Teildomänen eher kurze Transaktionsskripte einsetzen lassen, wird man für komplexe und volatile Bereiche der Geschäftslogik eher eine objektorientierte Implementierung wählen.
void Handle(AuftragAnnehmen cmd){
PrüfeAutorisation(cmd);
var kunde = _kundenRepository.Get(cmd.KundenId);
kunde.NeuenAuftragAnnehmen(cmd.AuftragsId,
cmd.Auftragsnummer,
cmd.Zeilen, ...);
SpeichereInEventStoreUndVeröffentliche(kunde.HoleNeueEreignisse);
}
Objektorientiertes Domänenmodell
Domänenmodelle übernehmen die Ausführung der Befehle. Sie bilden spezifische fachliche Anforderungen auf Programmstrukturen ab und kapseln das gewünschte Systemverhalten sowie die dafür notwendigen Daten. Im Beispiel werden die Reaktionen des Modells als Ereignisse veröffentlicht.
class Kunde{
// [...]
void NeuenAuftragAnnehmen(Guid id, string auftragsnummer,
Auftragsposition[] zeilen, ...){
PrüfeKundeNichtGesperrt();
var nettoVolumen = zeilen.Sum(_.Netto);
PrüfeKreditwürdigkeit(nettoVolumen);
NeuesEreignis(new AuftragFürKundeWurdeAngenommen(id,
auftragsnummer, nettoVolumen, ...));
}
// [...]
}
Eine bewährte Methode zum Design von Domänenmodellen ist Domain Driven Design (DDD). Es liefert Grundbausteine, aus denen sich ein Domänenmodell aufbaut. Entitäten sind Objekte mit einer Identität, wie "Kunde" oder "Produkt", Wertobjekte hingegen sind Objekte, die sich nur über ihren Wert definieren wie "5 EUR" oder "Musterstraße 5, 12345 Musterstadt". Objektunabhängige Domänenregeln (z. B. Mehrwertsteuerberechnung) werden in zustandslosen Diensten abgebildet. Aggregate fassen eng kooperierende Teile des Domänenmodells zusammen, deren Zustand sich häufig gemeinsam ändert.
Persistenz durch Event Sourcing
Grundsätzlich sind die Persistenzmechanismen für das Domänen- ebenso wie für das Abfragemodell ein internes Implementierungsdetail des jeweiligen Bereichs. Die verwendete Technik lässt sich daher mindestens auf Komponenten-, teilweise sogar auf Klassenebene innerhalb einer Komponente frei wählen. Die Artikelautoren haben gute Erfahrungen mit Event Sourcing gemacht. Dessen Grundgedanke ist, jede Reaktion des Domänenmodells auf externe Befehle in Form von Ereignissen (Events) zu veröffentlichen. Ein Ereignis beschreibt allgemein eine Zustandsänderung der Domäne und erfasst dabei primär den Grund und sekundär die Daten der Zustandsänderung (siehe folgendes Listing).
class AuftragFürKundeWurdeAngenommen{
Guid KundeId;
Guid IdDesNeuenAuftrags;
String Auftragsnummer;
Währung NettoVolumen;
Date Auftragsdatum;
Date Lieferziel;
[...]
}
Statt dann den Zustand des Domänenmodells zu persistieren, wird nur eine Historie aller Ereignisse geführt, neue Ereignisse werden hier angehängt. Die Datenbank mit der Historie wird als "Event store" bezeichnet (Jonathan Oliver's event store v3). Die Historie enthält also die vollständige Information, um jede Änderung des Domänenmodells nachvollziehen zu können. Wird später ein Zustand eines Aggregats für die Abarbeitung eines weiteren Befehls benötigt, lässt sich dieser jederzeit durch eine Projektion der Historie rekonstruieren. Der Zustand des Domänenmodells als Struktur existiert daher nur vorübergehend im Speicher und findet sich nicht unnötig fixiert in einer Datenbankstruktur wieder. Dadurch entfällt zum einen das Problem des sogenannten objektrelationalen Impedance Mismatch, das üblicherweise durch den Einsatz schwergewichtiger O/R Mapper zu lösen ist. Zum anderen werden Aktualisierungen der Geschäftslogik stark vereinfacht, da kein Umstrukturieren eines Datenschemas notwendig ist.
Abgeschlossene Ereignisse sind, per definitionem, unveränderlich. Sie lassen sich daher problemlos replizieren und cachen. Gleichzeitig dient die Historie als Protokoll für Audits. Dieses ist garantiert korrekt und vollständig, da sowohl der Zustand des Domänenmodells als auch alle Daten in Abfragen aus dieser Historie abgeleitet werden.
Abfragemodell mit projizierten Daten
Die Abfrageseite soll von Clients benötigte Daten möglichst performant bereitstellen. Daher orientiert sich die Struktur dieser Modelle an den zu erwartenden Abfragen. Sind diese heterogen, können parallele Abfragemodelle die unterschiedlichen Anforderungen erfüllen. Üblicherweise verwendet man Listen, davon unabhängige Detaildatensätze sowie Analysemodelle analog zu OLAP-Systemen (siehe das folgende Listing).
class KundenlisteEintrag {
Guid KundenId;
String Kundennummer;
String Bezeichnung;
Waehrung OffenesAuftragsvolumen;
Date LetztesAuftragsdatum;
Waehrung UmsatzImGeschäftsjahr;
}
class Kundendetails{
Guid KundenId;
String Kundennummer;
String Bezeichnung;
Auftragsdetails[] OffeneAufträge;
Auftragsdetails[] AbgeschlosseneAufträge;
}
class OLAPDatenpunkt{
int Geschäftsjahr;
Produktgruppe Produktkategorie;
Währung Nettoumsatz;
}
Diese Abfragemodelle werden über Projektionen aus der Befehlsseite mit Daten versorgt. Hierbei wird Push-Semantik angewandt, eine Aktualisierung erfolgt also sofort bei Änderung der Quelle. Dadurch stehen immer aktuelle Daten zum Abruf bereit. In einer Implementierung mit Event Sourcing sind die Ereignisse die Quelle, aus der die Abfrageseite erstellt wird. Aufgrund der unterschiedlichen Abfragemodelle sind Daten hier grundsätzlich redundant vorhanden. Das ist tatsächlich sinnvoll, da das die Optimierung auf verschiedene Anwendungsfälle ermöglicht, ohne diese aneinander zu koppeln. Das DRY-Prinzip (Don't Repeat Yourself) findet keine Anwendung, schließlich kommen alle Daten aus einer einzigen autoritativen Quelle – dem Event store.
Durch diese Architektur lassen sich die Abfragemodelle jederzeit beliebig verändern und ergänzen. Aus der Historie der Ereignisse können auch nachträglich definierte Abfragemodelle in wenigen Sekunden durch eine erneute Projektion auf den aktuellen Stand gebracht werden. Darüber hinaus ist eine Datensicherung hier überflüssig. Sinnvollerweise implementiert man diese Seite der CQRS-Architektur so, dass sie sich jederzeit selbstständig aus der Historie des Domänenmodells regenerieren kann. Tatsächlich kann die Art der Datenhaltung für jede Gruppe von Abfragemodellen frei gewählt werden. Für kleine, häufig verwendete Datenbestände ist der Arbeitsspeicher ausreichend. Listen und Detaildatensätze werden idealerweise als Dokument in einem Key-Value-Store abgelegt. Und für große Datenbestände, die Ad-hoc-Abfragen dienen, sind relationale und OLAP-Datenbanken geeignete Speicher.
Komplettiert wird der Kreislauf aus Abbildung 2 durch eine dünne Fassade, die Abfragen seitens der Präsentationsschicht autorisiert und die entsprechenden Abfragemodelle zurückliefert.
Und die Datenbank?
CQRS verdrängt die Datenhaltung und die Datenstruktur zugunsten des Verhaltens aus dem Fokus der Softwareentwicklung. Dadurch wird Datenhaltung zwar nicht überflüssig, aber zu einem nebensächlichen Detail der Implementierung. In einzelnen Komponenten des Systems lässt sich eine gegebenenfalls notwendige Datenbank frei wählen. Soweit Event Sourcing eingesetzt wird, ist die Historie der Events in dem erwähnten Event store [9] persistiert.
Für Komponenten ohne Event Sourcing reicht ein einfacher Key-Value Store aus, da Aggregate immer als Ganzes geschrieben und gelesen werden. Zum Vorhalten der Abfragemodelle, soweit diese nicht in den Hauptspeicher der Serversysteme passen, lassen sich ebenfalls Key-Value Stores, relationale oder OLAP-Datenbanken einsetzen. Hierbei werden üblicherweise weder Sicherungen der Daten und deren Clustering noch Datenbankfunktionen wie Views und Stored Procedures benötigt. Daher ist der Betrieb dieser Datenbanken vergleichsweise unaufwendig.
Szenarien
Anwendungsbereiche
Vorweg eine Warnung: Die Autoren empfehlen CQRS nicht als "globale" Architektur. Tatsächlich lässt sich ein hinreichend komplexes Softwaresystem nicht durchgängig mit einem einzigen Architekturmuster erstellen. Architektonische Entscheidungen für jeden Teilbereich sind explizit und unabhängig voneinander zu treffen. Nur so lassen sich verschiedene nichtfunktionale Anforderungen optimal implementieren. Jedoch bietet CQRS einen Ansatz für eine Reihe unabhängiger Probleme. Im Folgenden seien Typen von Systemkomponenten vorgestellt, bei denen der Einsatz von CQRS einen deutlichen Mehrwert darstellt.
Komponenten, bei denen Daten wesentlich häufiger gelesen als verändert werden, profitieren am offensichtlichsten von der Trennung in Abfrage- und Domänenmodell. Für alle Formen von Datenabfragen, wie der Bildschirminhalte einer Applikation, Ausdrucke im Reporting oder Schnittstellen zu externen Systemen, liegen die benötigten Daten jederzeit exakt so aufbereitet vor, wie die jeweilige Datenabfrage sie benötigt. Somit ist das Abfragen von Daten immer maximal performant. Das Bearbeiten von Änderungen findet unabhängig vom Abfragemodell statt. Erst im Anschluss werden diese Daten aktualisiert und dadurch das Locking minimiert.
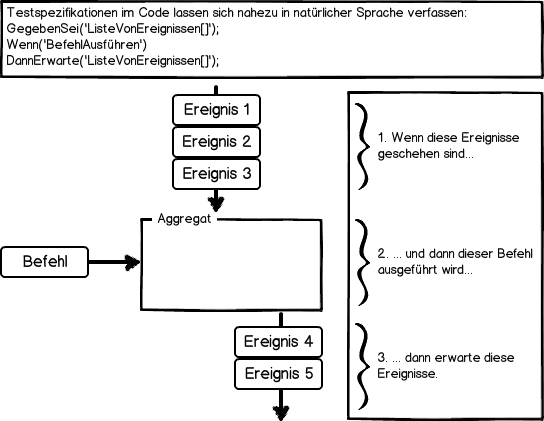
Komponenten der Kerndomäne eines Systems bieten ihren Mehrwert häufig durch komplexes Verhalten, dessen Spezifikationen sich mit der Zeit aus verschiedenen Gründen ändert. Sei es, dass Kunden neue Anforderungen stellen, Änderungen des Markts oder der Gesetzeslage Rechnung zu tragen ist oder Vertrieb und Marketingabteilung sich von Erweiterungen des Systems einen Mehrwert versprechen. CQRS ermöglicht gerade bei volatilen und evolvierenden Systemen, die Flexibilität in Wartung und Weiterentwicklung zu erhalten. Das Verhalten von mit CQRS aufgebauten Komponenten ist frei vom Ballast der Datenbereitstellung "leichtgewichtig" implementiert. Ausgehend von der klaren Erfassung der Benutzerintention in den Befehlsobjekten orientiert sich der Aufbau des Quellcodes entlang der fachlich spezifizierten Anforderungen. In Kombination mit Event Sourcing lassen sich diese Anforderungen optimal durch Akzeptanztests prüfen. Durch die Formulierung der Voraussetzungen eines Tests sowie der erwarteten Ergebnisse als Ereignisse werden Anforderungen direkt in Code übertragen. Umgekehrt lässt sich ein Testprotokoll von Fachanwendern sofort lesen und verstehen (Abb. 4).
Das zentrale Anwendungsfeld von CQRS sind Systeme mit hoher Kollaboration und häufigen konkurrierenden Zugriffen durch mehrere Benutzer. Hier erlaubt CQRS, auf klassisches Locking zu verzichten und Zugriffskonflikte aufzulösen. Durch das Erfassen der Intention der Benutzer in den Befehlen lässt sich für jeden Befehl einzeln definieren, ob das auszulösende Verhalten mit anderen Befehlen oder dem vorliegenden Systemzustand kollidiert oder kompatibel ist. So kollidieren in einer Warenwirtschaft die parallelen Befehle "Füge Produktfoto hinzu" und "Erhöhe Produktpreis um 20 EUR" nicht, obwohl sie formal das gleiche Produkt beeinflussen.
In einer CRUD-Anwendung, in der beide Nutzer nur die Anweisung "SpeichereÄnderungenAmProdukt" zur Verfügung haben, bliebe nur die Entscheidung zwischen optimistischem oder pessimistischem Locking. Dort würde also einer der beiden Vorgänge bereits im Vorfeld unmöglich sein ("Ein Kollege bearbeitet gerade das gleiche Produkt ...") oder im Nachgang fehlschlagen ("Ein Bearbeitungskonflikt ist aufgetreten").
Selbst im Fall einer echten fachlichen Kollision zweier Befehle – wie “Lege Produkt in den Warenkorb” und “Setze Produktstatus zu nicht lieferbar” – kann man im Einzelfall genau definieren, wie die Software den Konflikt behandeln soll. Ein Produkt das nicht lieferbar sein soll, sollte grundsätzlich auch nicht mehr bestellt werden können, unabhängig davon, welcher Befehl nun einen Augenblick früher an der Domäne ankam. Wenn die Kollision allerdings mit einem Produkt auftrat, dessen Bestellwert einen gewissen Betrag überschreitet, könnte das System die Kollision zugunsten der Bestellung behandeln, da ein Mehrwert für das Unternehmen gegeben ist, der den Aufwand rechtfertigt, das Problem später manuell zu lösen. Für das Unternehmen wären die Kosten einer händischen Nachbestellung oder eines kostenlosen Upgrades auf ein höherwertiges Produkt geringer als der Verlust durch den sonst entgangenen Umsatz.
Eine häufige fachliche Anforderung an Software ist die detaillierte Nachvollziehbarkeit aller Vorgänge im System. CQRS mit Event Sourcing erfüllt diese Anforderung ganz nebenbei ohne weiteren Aufwand: Die Historie der Ereignisse ist ein garantiert vollständiges Protokoll, da der Systemzustand aus ihr abgeleitet wird. Darüber hinaus ist sie für die Analyse von Fehlern und unerwartetem Verhalten hilfreich. Anstelle der üblichen Support-Vorgehensweisen, wie Analyse einer Zustandsdatenbank aus dem Backup und Gespräche mit den Usern, kann man den Hergang einfach nachlesen. Auch lässt sich ein Systemzustand der Vergangenheit jederzeit gezielt für forensische Zwecke rekonstruieren.
Risiken und Nebenwirkungen
Der Einsatz von CQRS führt zu einer deutlich vereinfachten Systemarchitektur. Allerdings besitzt diese für viele Entwickler anfangs eine recht hohe "gefühlte" Komplexität. Das resultiert nicht so sehr aus der vermeintlich steilen Lernkurve, ein interessantes Podcast-Projekt zeigt, dass diese eher flach ist. Vielmehr bereitet das Entlernen des Einsatzes komplizierter Enterprise-Frameworks oftmals Schwierigkeiten. Objektiv gesehen ist dies durchaus ein Risiko, da größere Änderungen des Werkzeugkoffers einer Entwicklungsabteilung zunächst zu einem deutlichen Einbruch der Produktivität führen können. Auch besteht die Gefahr von Fehleinschätzungen aus mangelnder Erfahrung mit dem Werkzeug CQRS. Daher sollte bei der Einführung jeder neuen Methode zunächst an einem nicht übermäßig geschäftskritischen Projekt geübt werden.
Ein reales Problem hingegen ist die noch nicht umfangreiche Tool-Unterstützung für die Bestandteile einer CQRS-Architektur. Beide Autoren haben genau deshalb noch bei ihren letzten Projekten auf SQL-Server-Implementierungen zurückgegriffen. Zwischenzeitlich wird aber die Tool-Ausstattung deutlich besser. Nicht zuletzt ist seit Herbst 2012 ein kommerzieller (quelloffener) Event store auf dem Markt verfügbar, inklusive den für die zentrale Datenhaltungskomponente oft zwingend vorausgesetzten professionellen Supportangeboten.
Eine weitere Nebenwirkung sei nicht verschwiegen: Der starke Fokus auf das Verhalten der Software führt gerade bei einfachen Systemen zu größeren Aufwänden bei Analyse und Design als eine reine Implementierung von Datenstrukturen. Bei letzterer lässt sich das Verhalten schlicht weglassen und die regelkonforme Bearbeitung der Daten an den Benutzer delegieren. Da CQRS das Erfassen der Intention des Benutzers und das Abarbeiten der Geschäftslogik aufgrund dieser Intention in den Vordergrund stellt, ist eine saubere Analyse der Problemdomäne schwer zu umgehen. Ob das ein Vor- oder Nachteil ist, mag jeder Leser für sich entscheiden.
Fazit
Fazit
Der Begriff CQRS ist etwa vier Jahre alt. Das technikunabhängige und plattformneutrale Prinzip der Trennung von Befehlen und Abfragen ist jedoch viel älter und inzwischen zum erprobten Architekturmuster geworden. Mit CQRS lässt sich die Architektur von Softwaresystemen flexibler gestalten und Antworten für eine Reihe verbreiteter Probleme in der Softwareentwicklung finden. Für Entwickler und Architekten ist dieses, auf einfache Ideen setzende Prinzip zu einem wichtigen Werkzeug neben und anstelle schwergewichtiger Frameworks geworden. Doch auch für Projektleiter bietet CQRS interessante Aspekte, so vereinfacht die grundlegende Trennung von Benutzerinterface, Geschäftslogik und Datenaufbereitung die Aufteilung der Teams nach Kompetenzen und Erfahrung.
Die Entwurfsmuster rund um CQRS sind in jüngster Zeit ständiges Thema auf Konferenzen und in Publikationen, weit über den .NET-Bereich hinaus, in dem Greg Young CQRS zuerst formuliert hatte. Im Sommer 2012 wurde CQRS sogar durch Microsofts Pattern & Practices Group mit der Veröffentlichung eines Architekturleitfadens geadelt. Der stetig steigende Einsatz in der Praxis lässt sich gut an den vermehrten Nachfragen in der aktiven Google-Gruppe DDD/CQRS ablesen. Hier wird CQRS weiter definiert und entwickelt und Anfängern wie Profis gleichermaßen geholfen.
Marco Heimeshoff
ist Abteilungsleiter der Softwareentwicklung bei der ASD Personalinformationssysteme GmbH, Osnabrück, und bloggt unter Heimeshoff.de.
Philip Jander
ist selbstständiger Softwareentwickler und Trainer mit Schwerpunkt .NET in Münster, Westf.
Literatur
- Greg Young; CQRS Introduction
- Greg Young; CQRS and Event Sourcing
- Udi Dahan; Clarified CQRS
- Martin Fowler; CQRS
- Bertrand Meyer; Object-Oriented Software Construction (2nd edition); Prentice Hall, 1997, S. 751
- Martin Fowler; Command Query Separation
- Robert C. Martin; Agile Software Development, Principles, Patterns, and Practices; Prentice Hall, 2002, S. 149, ein Auszug
- Martin Fowler, Further Patterns of Enterprise App. Architecture – Event Sourcing
- Eric Evans; Domain Driven Design; Addison-Wesley, 2003
- Jimmy Nilsson; Applying Domain Driven Design and Patterns; Addison-Wesley, 2006
- Vernon Vaughn; Implementing Domain Driven Design; Addison-Wesley, 2013, Auszug
- Martin Fowler; Refactoring; Addison-Wesley, 2000, S. 295
(ane)
