
Cloud Bursting – platzt die Private Cloud, ist die Public Cloud zur Stelle
On Premises betriebene Anwendungen in der Private Cloud lassen sich bei Auslastungsspitzen durch die Rechenkapazität einer Public Cloud entlasten.

(Bild: Shutter Ryder/Shutterstock.com)
- Simon Mennig
In den vergangenen Jahren hat das Cloudgeschäft ein rasantes Wachstum erlebt. Lag der weltweite Umsatz 2018 noch bei 182,4 Milliarden US-Dollar, wird er für 2022 auf 331,2 Milliarden US-Dollar prognostiziert.

Damit steigt auch das Interesse von Unternehmen, die die Cloud für ihre IT-Zwecke nutzen. Jedoch können oder wollen viele Firmen nicht all ihre Daten in eine Public Cloud verlagern (zum Beispiel aufgrund von Compliance-Regeln) und entscheiden sich deshalb für das Modell der hybriden Cloud. Hierbei lassen sich nicht nur die Vorteile mehrerer Technologien vereinen, sondern auch die Unabhängigkeit und Hoheit eines bestimmten Anbieters gewährleisten. Ein weiterer Vorteil besteht im elastischen Skalieren einzelner Komponenten. Sie bietet die Möglichkeit, die Grundlast auf der eigenen Infrastruktur zu betreiben und aufwendige oder unregelmäßige Lasten in der Public Cloud auszuführen. Aus der Kombination von Public und Private Cloud ergeben sich einige neue Optionen:
- Die Kontrolle über Speicherung und Verarbeitung von Daten bleibt bei der Organisation.
- Unternehmen können fallweise entscheiden, ob Daten die Private Cloud verlassen dürfen (besonders hinsichtlich personenbezogener und unternehmenskritischer Daten).
- Für Anwendungsfälle mit stark schwankender Last (z. B. bei einem Reiseveranstalter) ist die Elastizität der Public Cloud attraktiv.
Weiterhin ist ein sogenanntes Cloud Bursting denkbar: Dabei lässt sich eine Anwendung On Premises betreiben, aber bei hoher Last erweitert eine Public Cloud die Kapazitäten automatisch.
Videos by heise
Was ist eine Hybrid Cloud?
Das NIST (National Institute of Standards and Technology) definiert eine hybride Cloud wie folgt:
„Die Cloud-Infrastruktur [der hybriden Cloud] ist ein Zusammenschluss aus zwei oder mehr unterschiedlichen Cloud-Infrastrukturen (privat, gemeinschaftlich oder öffentlich), die grundsätzlich getrennte Einheiten bilden. Allerdings sind sie durch standardisierte oder proprietäre Technologie miteinander verbunden, die die Portabilität von Daten und Anwendungen ermöglicht, wie im Falle von Cloud Bursting für den Lastausgleich zwischen Clouds.“
Meist handelt es sich um die Kombination einer privaten und einer Public Cloud. Kommen mehrere Public Clouds zum Einsatz, spricht man von einer Multicloud. Ein wichtiges Merkmal ist in jedem Fall die Portabilität von Daten und Anwendungen. Der Einsatz von Containern und Kubernetes ermöglicht hierbei einen standardisierten Umgang mit der Anwendung – unabhängig vom Cloud-Anbieter.
Cloud Bursting: Wenn Clouds aus allen Nähten platzen
Der Begriff „Cloud Bursting“ enthält das englische Wort „to burst“, das für zerplatzen und explodieren steht, aber auch „etwas zum Platzen bringen“ heißen kann. Bildlich gesprochen hieße der Ausdruck auf Deutsch etwa „die Cloud sprengen“. Worum genau geht es hier? Im Kern geht es darum, Anwendungen im privaten Teil einer hybriden Cloud bei steigender Last durch die Ressourcen einer Public Cloud zu erweitern: die Private Cloud „platzt“ gewissermaßen und die Public Cloud fängt sie auf. Viele der eingesetzten Technologien sind dabei nicht auf hybride Clouds beschränkt, sondern sie lassen sich auch auf Multicloud-Umgebungen mit mehreren Kubernetes-Clustern übertragen. Damit ist das Thema für alle interessant, die mehrere Cluster parallel betreiben und diese enger miteinander verzahnen wollen, um die verfügbaren Ressourcen besser zu nutzen. Das trifft insbesondere auf Anwendungsfälle mit schwankender Last zu (s. Abb. 1).
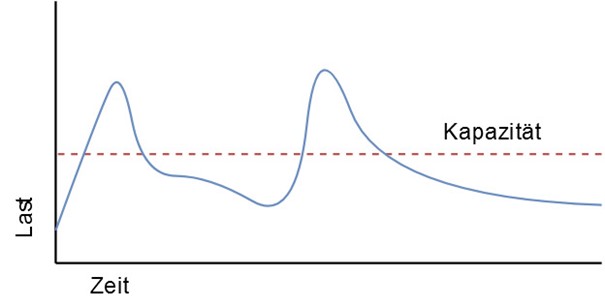
(Bild: doubleSlash)
Die meiste Zeit über befindet sich die Auslastung unterhalb der Kapazitätsgrenze der privaten Cloudinfrastruktur. Es kommt zu kurzen Spitzen, welche die Kapazität überschreiten. Diese bestandsüberschreitenden Auslastungen soll der öffentliche und kostenpflichtige Teil der hybriden Cloud auffangen. Auf diese Weise lassen sich die benötigten Ressourcen elastisch beanspruchen und die zusätzlichen Kosten für die Nutzung des öffentlichen Teils gering halten.
Fallbeispiel: Entwicklung neuer Medikamente
Cloud Bursting kann beispielsweise bei der optischen Analyse von Wirkstoffen im Rahmen der Entwicklung neuer Medikamente zum Einsatz kommen. Dazu werden Proben mit verschiedenen Wirkstoffkandidaten kombiniert. Anhand von Aufnahmen der Proben gilt es, ein neuronales Netz zu trainieren, das bereits in einem frühen Stadium erkennen soll, ob es sich um einen vielversprechenden Wirkstoffkandidaten handelt. Da hierbei von einer schwankenden Auslastung auszugehen ist und teilweise sensible medizinische Daten als Basis dienen, handelt es sich um ein passendes Einsatzgebiet für eine hybride Cloud.
Das Training ist – abhängig von der Menge der Daten und dem Aufbau des Netzwerks – vergleichsweise ressourcenhungrig, damit ist es ein Kandidat für das Cloud Bursting. Ein fertig trainiertes Modell lässt sich zentral im privaten Teil der Cloud speichern. Stößt man das Training eines neuronalen Netzes an, beginnt in der hybriden Cloud die dafür notwendige Arbeit. Abhängig von der Ressourcenauslastung läuft der Job entweder im privaten Kubernetes-Cluster oder im öffentlichen Teil der Cloud. Die Übermittlung des trainierten Modells in das zentrale Repository geschieht gesichert. Dabei spielt es keine Rolle, in welchem Teil der hybriden Cloud das Training letztlich stattgefunden hat.
Hands-On: Cloud Bursting mit Kubernetes
Dazu gilt es, eine private und eine Public Cloud aufzusetzen, die jeweils aus einem eigenen Kubernetes-Cluster bestehen. Zusammen bilden die zwei Cluster die hybride Cloud. Damit aus zwei getrennten Umgebungen eine effektive hybride Cloud inklusive Cloud Bursting wird, sollten folgende Anforderungen erfüllt sein:
- Services in einem Cluster müssen Services im anderen Cluster entdecken und aufrufen können.
- Die Kommunikation zwischen den Clustern sollte abgesichert sein.
- Die Freigabe von Anwendungen in der hybriden Cloud lässt sich zentral verwalten.
- Die Ressourcen beider Cluster sind gebündelt.
Ziel ist es, dass sich die beiden Teile der hybriden Cloud möglichst wie ein einziges, homogenes System verhalten. Unter den Begriffen Cross-Cluster-Kommunikation, Multicluster-Verwaltung und Multicluster-Scheduling lassen sich diese Vorgänge zusammenfassen. Kubernetes selbst bietet hierfür keine Lösung an. Glücklicherweise bietet das Kubernetes-Ökosystem aber für jeden dieser Punkte ein Kubernetes-Projekt, das die jeweilige Funktion zur Verfügung stellt.
Die aufgeführte Beispielanwendung soll das Verwalten und das Scheduling von Multiclustern sowie die Kommunikation über Clustergrenzen hinweg (Cross-Cluster) übernehmen:
- ML-Training in Python (Keras plus TensorFlow) anhand des MNIST-Datensatzes, bei dem es darum geht, handgeschriebene Ziffern zu erkennen
- Ausführen der ML-Jobs dort, wo Kapazitäten frei sind (Cloud Bursting)
- Ablegen der trainierten Modelle in einem zentralen Repository – das benötigt Kommunikation über die Clustergrenzen hinweg
Die Cluster-Umgebung aufsetzen
Als Basis für die Umgebung dienen zwei Kubernetes-Cluster, die beide über Azure Kubernetes Service (AKS) aufgesetzt sind. Grundsätzlich lassen sich die Cluster aber auch selbst betreiben oder zum Beispiel bei Amazon Web Services und in der Google Cloud aufsetzen. Wichtig für ein funktionierendes Cloud Bursting ist die Konfiguration der Ressourcen pro Cluster. Für den privaten Teil wird dem Cluster eine feste Anzahl an Nodes zugewiesen. Der öffentliche Cluster hingegen kann die Anzahl seiner Nodes dynamisch skalieren.

(Bild: doubleSlash)
Cross-Cluster-Kommunikation
Anwendungen in Kubernetes lassen sich über einen internen DNS-Server eindeutig identifizieren und aufrufen. Hierfür zuständig ist die Kubernetes-Service-Ressource. Ziel der Cross-Cluster-Kommunikation ist es, diese Funktion auf mehrere Cluster auszuweiten. Eine Möglichkeit ist, ein Service Mesh einzusetzen, das alle Cluster der hybriden Cloud umspannt (s. Abb. 2) – für den Use Case kommt Istio als Multicluster-Installation in der Variante als Shared Control Plane zum Einsatz. Das hat den Vorteil, dass keine VPN-Verbindung zwischen den Clustern erforderlich ist. Die Kommunikation zwischen den Clustern geschieht jeweils über ein Gateway und ist über mutual TLS (mTLS) gesichert. In dieser Variante teilen sich beide Cluster die Istio Control Plane. Sie muss folglich immer aktiv sein und wird deshalb typischerweise in der privaten Cloud angesiedelt.
Um Probleme mit dem Multicluster-Scheduler zu vermeiden, sollte man Prometheus bei der Installation von Istio deaktivieren. Im Anschluss an die Installation von Istio gilt es, die Sidecar Injection auf Namespace-Ebene zu aktivieren. Dazu labelt man den entsprechenden Namespace in jedem Cluster folgendermaßen:
$ kubectl label namespace sample istio-injection=enabled
Damit eine Anwendung aus beiden Clustern ansprechbar ist, auch wenn sie nur in einem Cluster existiert, muss in jedem Cluster der zugehörige Service eingerichtet sein.
Abbildung 3 ist an die Istio-Beispielanwendung Bookinfo angelehnt und zeigt die Kommunikation zwischen verschiedenen Microservices, die sich über zwei Cluster verteilen. Sie besteht aus einem Frontend und zwei Backend-Services, die Details zu Büchern und Reviews bereitstellen. Der Microservice „Details“ ist in beiden Clustern vorhanden. Anfragen lassen sich so zwischen beiden Instanzen verteilen. Der Microservice „Reviews“ ist nur im privaten Cluster ausgerollt. Da die Service-Definition aber auch im öffentlichen Cluster verfügbar ist, leitet das Istio-Gateway alle Anfragen automatisch vom öffentlichen zum privaten Cluster weiter (s. Abb. 3).

(Bild: doubleSlash)
Multicluster-Verwaltung
Wie die Einrichtung von Istio vielleicht schon erahnen lässt, fallen viele Aufgaben bei einer hybriden Cloud mehrfach an, da sie in jedem Cluster auszuführen sind. Ziel ist es, das Anlegen von Ressourcen zu vereinheitlichen, um zum Beispiel Namespaces, Services oder Deployments zentral zu verwalten. Bei der Verwaltung mehrerer Cluster ist es dann möglich, solch redundante Aufgaben einzusparen.
Das entsprechende Kubernetes-Projekt heißt Kubernetes Cluster Federation. Es ist für den Einsatz von Cloud Bursting nicht zwingend notwendig, erleichtert Entwicklern aber die Arbeit. Der User Guide unterstützt bei der Installation.
Nach dem Installieren gibt es einen Host-Cluster, dem beliebige Cluster beitreten können. Sinnvollerweise wird der private Cluster zum Host. Im Host-Cluster können Entwickler zentral Ressourcen anlegen und dann auf ausgewählte Cluster verteilen. Zu den gebräuchlichsten Kubernetes-Objekten existiert jeweils eine Variante mit dem Präfix „Federated“.
Aus einem Service wie dem blob-storage wird dann ein FederatedService, wie die folgenden Listings veranschaulichen. Neben dem geänderten Namen ist vor allem das Attribut placement entscheidend. Durch die Auswahl von Labels oder die Auflistung von Clusternamen lässt sich hier die Verteilung auf die Cluster bestimmen. Standardmäßig legt man die Ressource in allen Clustern an. Wird der FederatedService nun also im Host-Cluster angelegt, resultiert daraus ein entsprechender Service im privaten und öffentlichen Cluster.
apiVersion: v1
kind: Service
metadata:
name: blob-storage
spec:
ports:
- port: 10000
protocol: TCP
targetPort: 10000
selector:
app: blob-storage
sessionAffinity: None
type: ClusterIP
Listing 1: Service blob-storage
apiVersion: types.kubefed.io/v1beta1
kind: FederatedService
metadata:
name: blob-storage
spec:
placement:
clusterSelector: {}
template:
spec:
ports:
- port: 10000
protocol: TCP
targetPort: 10000
selector:
app: blob-storage
sessionAffinity: None
type: ClusterIPListing 2: FederatedService blob-storage
Zusammen mit einem Istio-Multicluster-Mesh lässt sich über die Federation die Verteilung von Services vereinfachen. Das gilt insbesondere für das Betreiben von mehr als zwei Clustern, um beispielsweise verschiedene geografische Regionen abzudecken.
Multicluster-Scheduling
Da nun die Kommunikation innerhalb der hybriden Cloud sichergestellt ist, fehlt für das Cloud Bursting noch die Unterstützung eines übergreifenden Schedulers. Dieser entscheidet, in welchem Cluster das Machine Learning letztlich zur Ausführung kommt. Die Funktion steht über den Multicluster-Scheduler von admiralty.io bereit.
Nach der Installation genügt es, die Annotation multicluster.admiralty.io/elect: "" zu einem Deployment, Job oder Pod hinzuzufügen. Anschließend übernimmt der Multicluster-Scheduler und entscheidet, in welchem Cluster ein Pod zum Ausführen des Containers entsteht. Listing 3 zeigt, wie das geht:
apiVersion: batch/v1
kind: Job
metadata:
labels:
app: mnist-ml
name: ml-job
spec:
parallelism: 1
template:
metadata:
annotations:
multicluster.admiralty.io/elect: ""
labels:
app: mnist-ml
spec:
containers:
image: smennig/ml-job:mnist
imagePullPolicy: Always
name: ml-job
restartPolicy: Never
dnsPolicy: ClusterFirstListing 3: Batch Job für das Multicluster-Scheduling
Aus technischer Sicht erstellt man einen so annotierten Pod wie gewohnt und lässt ihn anschließend vom Multicluster-Scheduler durch einen sogenannten Proxy Pod ersetzen, der nichts tut. Der Scheduler wählt dann einen Cluster zur Ausführung aus und erstellt darin einen sogenannten Delegate Pod. In ihm kommt die eigentliche Anwendung zur Ausführung.
Deployment der Beispielanwendung
Die Beispielanwendung ist im GitHub-Repository des Autors namens „Hybrid Cloud Burst“ verfügbar. Der Aufbau lässt sich dem Übersichtsbild entnehmen (s. Abb. 4). Im Cluster der privaten Cloud befindet sich ein File Repository für die Ablage von trainierten Modellen. Über den zugehörigen Service ist es aus beiden Clustern erreichbar.

(Bild: doubleSlash)
Mit den folgenden drei Befehlen legt man zuerst einen Namespace an, in dem Istio und der Scheduler aktiviert sind. Anschließend gilt es, das Deployment und den Service für das File-Repository anzulegen. Da es sich jeweils um Kubernetes-Federation-Ressourcen handelt, lassen sie sich automatisch auf beide Cluster anwenden.
$ kubectl �context ${PRIVATE_CLUSTER_CTX} apply -f k8s/namespace.yaml
$ kubectl �context ${PRIVATE_CLUSTER_CTX} apply -f k8s/blob-storage.yaml
$ kubectl �context ${PRIVATE_CLUSTER_CTX} apply -f k8s/blob-storage-service.yamlListing 4: Deployment für den privaten und den öffentlichen Cluster
Anschließend sollte der private Cluster folgendermaßen aussehen:
$ kubectl --context ${PRIVATE_CLUSTER_CTX} get all
NAME READY STATUS RESTARTS AGE
pod/blob-storage-d4556c66f-z79f2 2/2 Running 0 2d5h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/blob-storage ClusterIP 10.0.225.183 <none> 10000/TCP 3d6h
service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 5d23h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/blob-storage 1/1 1 1 3d5h
NAME DESIRED CURRENT READY AGE
replicaset.apps/blob-storage-d4556c66f 1 1 1 3d5hListing 5: Privater Cluster nach dem initialen Deployment
Der öffentliche Cluster sollte dann entsprechend aussehen wie in Listing 6:
$ kubectl --context ${REMOTE_CLUSTER_CTX} get all
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/blob-storage ClusterIP 10.0.42.74 <none> 10000/TCP 3d6h
service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 7d6hListing 6: Öffentlicher Cluster nach dem initialen Deployment
Nun ist es möglich, einen Job anzulegen, den der Multicluster-Scheduler automatisch einem freien Cluster zuweist. In diesem Fall ist der Pod (ml-job-6ymu-xvrv2-p5bbl) dem Cluster in der Public Cloud zugewiesen. Bei dem Pod im privaten Cluster handelt es sich lediglich um den Proxy-Pod, wie Listing 7 veranschaulicht:
$ ./k8s/new-job.sh
job.batch/ml-job-6ymu created
$ kubectl --context ${PRIVATE_CLUSTER_CTX} get pods
NAME READY STATUS RESTARTS AGE
blob-storage-d4556c66f-z79f2 2/2 Running 0 2d5h
ml-job-6ymu-xvrv2 2/2 Running 0 20
$ kubectl --context ${REMOTE_CLUSTER_CTX} get pods
NAME READY STATUS RESTARTS AGE
ml-job-6ymu-xvrv2-p5bbl 2/2 Running 0 27sListing 7: Scheduling eines ML-Jobs im öffentlichen Cluster
Beim Erstellen weiterer Jobs sieht man, dass beide Cluster nach und nach stärker ausgelastet sind. Ab einem gewissen Punkt greift in der Public Cloud das Autoskalieren, dem betroffenen Cluster werden neue Nodes und damit Ressourcen hinzugefügt. Sobald die Trainingsjobs abgeschlossen sind, sinkt die Last erneut. Mit einer gewissen Verzögerung sollte dann auch die Anzahl der Nodes in der Public Cloud wieder zum Ausgangswert skalieren. Über die Mechanismen Node Selector und Node Affinity lässt sich das Verhalten des Schedulers beeinflussen, um zum Beispiel den privaten Cluster für die Ausführung eines Pods zu bevorzugen.
Fazit
Mit den entsprechenden Kubernetes-Erweiterungen lässt sich vergleichsweise einfach eine hybride Cloud mit Unterstützung für Cloud Bursting aufsetzen. Ein elementarer Baustein dafür ist die Cross-Cluster-Kommunikation, das konkrete Beispiel hat sie mit Istio umgesetzt. Die zweite wichtige Komponente ist der Multicluster-Scheduler, der dafür sorgt, dass sich die Ressourcen der hybriden Cloud zu einem gemeinsamen Pool zusammenfassen lassen. Auch wenn es nicht zwingend notwendig ist, erleichtert die Verwendung von Kubernetes Cluster Federation die Verwaltung mehrerer Cluster und ist damit besonders für größere Projekte von Nutzen.
Cloud Bursting kann dabei helfen, die Cloud bei Lastschwankungen besser zu nutzen. Durch die weite Verbreitung von Kubernetes gibt es eine große Auswahl an Cloud-Anbietern, die dafür in Frage kommen. Entwickler können auf ein wachsendes Ökosystem an Erweiterungen zurückgreifen. Weitere Projekte, die sich ebenfalls mit dem Thema Multicloud und hybride Cloud beschäftigen, sind zum Beispiel Cillium, Submariner und Google Anthos.


Simon Mennig
hat Wirtschaftsinformatik (B.Sc.) und Informatik mit Schwerpunkt Software Engineering (M.Sc.) studiert.
Er arbeitet als Softwareentwickler bei doubleSlash und hat umfassendes Know-how in den Bereichen IoT, Cloud Computing und Java.
Das Thema „Cloud Bursting“ war ein Teil seiner Masterarbeit bei doubleSlash.
(sih)
