

Cryptography Engineering, Teil 3: AES auf 8-Bit-Mikrocontrollern
Verschlüsselung hat sich unbestritten einen festen Platz in der IT erobert. Nicht mehr nur leistungsstarken Rechenboliden in Rechenzentren und PC-Systemen ist sie vorbehalten, auch in der Welt der Winzlinge nimmt ihre Bedeutung zu. Embedded-Systeme sind ebenfalls eine Zielplattform für moderne Kryptografie.
- Oliver Müller

Verschlüsselung hat sich unbestritten einen festen Platz in der IT erobert. Nicht mehr nur leistungsstarken Rechenboliden in Rechenzentren und PC-Systemen ist sie vorbehalten, auch in der Welt der Winzlinge nimmt die Bedeutung von Kryptografie zu. Embedded-Systeme mit Mikrocontrollern sind ebenfalls eine Zielplattform für moderne Kryptografie.
Die Implementierung von Kryptografie auf leistungsstarken Systemen bereitet kaum mehr Probleme. Wie der zweite Beitrag der Artikelreihe zeigt, ist die Implementierung ohne kompliziertere mathematische Kunstgriffe auf 32-Bit-Systemen machbar. Bei eingebetteten Systemen ist die Ausgangslage wesentlich ungünstiger. Doch werden die begrenzten Ressourcen der kleinen Systeme gebührend beachtet, lässt sich der Advanced Encryption Standard (AES) auch auf 8-Bit-Mikrocontrollern implementieren. Atmels AVR ATmega ist ein geeignetes Demonstrationsobjekt für einen weiteren Ausflug in die Welt des Cryptography Engineering. Zumal sich die Umgebung ohne echte AVR-Hardware komplett auf Windows simulieren lässt.
Cryptography Engineering
Die Artikel zur Reihe:
- Zur Theorie des AES
- AES-Implementierung für PC- und Serversysteme
- AES-Implementierung für 8-Bit-Microcontroller
- AES-Implementierung auf AVR ATmega
- AES-Implementierung für mobile Endgeräte (Android)
Kryptografische Algorithmen wie AES sind zwar für die Implementierung in Hardware geeignet, um einen in Hardware "gegossenen" AES nutzen zu können, muss jedoch die entsprechende Hardware vorhanden sein. Das ist aber nur bei speziellen Mikrocontrollern der Fall, wie im Online-Banking oder Zahlungsverkehr eingesetzten Chipkarten (Smartcard, Integrated Circuit Card, kurz ICC). Einfache oder Allzweck-Mikrocontroller verfügen über derartige Kryptohardware nicht. Hier bleibt nur eine Implementierung in Software, die bei den erheblich eingeschränkten Ressourcen eines einfachen Mikrocontrollers eine Herausforderung darstellt.
Die Prozessorarchitektur mit dem schmalen 8-Bit-Integer-Rechenwerk ist dabei kein zentrales Problem. Die Operationen über den 128 Bit großen Blöcken (State-Matrix) in AES lassen sich leicht auf einzelne Bytes herunterbrechen. Zugegeben, eine 32- oder 64-Bit-Architektur kann die meisten Operationen parallel in weniger Takten abarbeiten. Ein 8-Bit-Rechenwerk benötigt hier mehrere Durchläufe, also auch mehr Taktzyklen. Zudem beschleunigen auf größeren Mikroprozessoren zusätzlich Barrel-Shifter Schiebe- und Rotationsoperationen. Für derartigen "Luxus" gibt es auf dem Chip des AVR-Zwergs keinen Platz. Der eigentliche Algorithmus aus der Ankündigung des AES-Standards (PDF) lässt sich aber auch auf einem 8-Bit-AVR problemlos implementieren. Die Hardware des ATmega mit schnellen Taktraten von bis zu 20 MHz ist für AES völlig geeignet. Die Herausforderungen liegen an anderer Stelle.
Quellcode
Hinweis: Die Sourcen zu diesem Artikel finden Sie im Tarball auf dem heise Developer FTP zum Download.
Naturgemäß sind die S-Boxen von AES, die für jedes Byte einen Ersetzungseintrag vorhalten, entsprechend ausladend. Für die Ver- und die Entschlüsselung ist jeweils eine eigene 256 Byte große Tabelle vorzuhalten. Insgesamt also 512 Bytes, die die begrenzten Ressourcen eines kleinen Mikrocontrollers erheblich belasten. Bei Mittelklasse-ATmegas wie dem ATmega88 belegen die S-Boxen entweder das gesamte EEPROM (Electrically Erasable Programmable Read-Only Memory) oder die Hälfte des RAM. Eine Alternative wären ein Ablegen im Programmspeicher, also im Flash, und der Zugriff über die speziellen pgmspace-Routinen der AVR libc – das allerdings unter der Voraussetzung, dass der Programmspeicher noch über genügend freien Speicher verfügt. Für eigene Rechenübungen gibt eine Atmel-Webseite einen Überblick über die Größen von RAM, EEPROM und Flash der einzelnen ATmega-Modelle.
Zusätzlich sind aus dem eigentlichen AES-Schlüssel, wie der erste Teil dieser Artikelreihe zeigte, für die einzelnen Runden separate Schlüssel zu erzeugen. Diese Schlüsselexpansion resultiert in einem Array von Rundenschlüsseln, das bei AES128 schon 176 Bytes, bei AES192 208 Bytes und bei AES256 stattliche 240 Bytes umfasst. Zumindest für die kleineren bis mittleren ATmega-Modelle ist das wiederum eine hohe Belastung der geringen Speicherressourcen. Ein Ablegen im Flash (PGMSPACE) scheidet hier zudem von vornherein aus. Es ist unklug, einen individuellen kryptografischen Schlüssel, der ein System identifiziert, in den Flash zu legen. Der Flash-Inhalt eines jeden einzelnen Systems wäre individuell zu erzeugen und zu programmieren. Ist später ein (kompromittierter) Schlüssel auszutauschen, wäre wieder der Flash neu zu programmieren.
Der "verschwenderische" Umgang mit dem Speicher wie bei Server- und PC-Systemen scheidet beim Mikrocontroller folglich aus. Die Hardware weist die bewährten Algorithmen aus den beiden vergangenen Artikeln in ihre Schranken. Obgleich der Algorithmus AES unverändert bleibt, heißt es, für die spezielle Hardwareplattform des ATmega-Mikrocontrollers neue Antworten zu finden.
Problem S-Boxen
Die S-Boxen verursachen ein erhebliches Ressourcenproblem. Wie lässt sich eine Tabelle anders als durch eine Tabelle darstellen? Für den veralteten Kryptostandard DES (Data Encryption Standard) hieß die Antwort noch: Es muss eine Tabelle sein. AES ist an der Stelle intelligenter. Die S-Boxen sind hier nicht willkürlich durch "Würfeln" entstanden. Vielmehr sind die Substitutionen in AES Abbildungen eines Bytes auf sein multiplikatives Inverses im endlichen Körper GF(2^8), auf das noch eine affine Transformation in GF(2) (also bitweise) erfolgt. Die "affine Transformation" klingt komplizierter als sie ist. Sie besteht aus bitweisen XOR-Verknüpfungen und lässt sich der AES-Spezifikation (PDF) aus Abschnitt 5.1.1 auf Seite 15 direkt entnehmen.
Diese Eigenschaft der S-Boxen von AES ermöglicht es, die entsprechenden Werte dynamisch zur Laufzeit zu berechnen und nicht starr in einer Tabelle vorhalten zu müssen. Grundsätzlich stellt sich dabei die Frage, wie das effizient erfolgen kann, ohne die kryptografischen Funktionen zu sehr zu verlangsamen. Schließlich muss die Berechnung mit einem einfachen Table-Lookup (siehe 32-Bit-Implementierung) konkurrieren.
In GF(2^8) gibt es prinzipiell drei Ansätze, um das multiplikative Inverse p^-1 zu einem gegebenen Wert p zu berechnen. Ein Ansatz wäre, den Wert p sukzessive mit jedem Wert von 0 bis 255 in GF(2^8) zu multiplizieren, bis sich 1 ergibt. Dieser Brute-force-Ansatz hat jedoch seine Schwächen. Im schlimmsten Fall benötigt er zur Berechnung des multiplikativen Inversen 256 Multiplikationen. Eine Multiplikation in GF(2^8) ist – wie der erste Beitrag dieser Reihe zeigt – nicht gerade eine schnelle Operation. Einen Rausch der Geschwindigkeit darf man vom Brute-force-Ansatz daher nicht erwarten. Er ist ungeeignet; gerade, aber nicht nur für Mikrocontroller.
Die zweite Möglichkeit ist es, eine Logarithmustabelle in GF(2^8) aufzubauen und die Multiplikation nach dem Rechenschieberprinzip auf Subtraktionen zurückzuführen. Das multiplikative Inverse p^-1 von p ließe sich dann wie folgt errechnen:
p^-1 = alog(0xFF XOR log(p))
log ist hierbei der Logarithmus in GF(2^8), und alog ist der zugehörige Antilogarithmus.
Das Problem ist bei dem Ansatz wieder das Stichwort "Tabelle". In den Tabellen für Logarithmus und Antilogarithmus ist für jedes Byte der zugehörige Wert zu halten. Beide Tabellen sind wiederum je 256 Bytes groß. Das komplizierte und zusätzliche Taktzyklen verbrauchende Logarithmieren kann man sich demnach von vornherein sparen. Die S-Boxen würden als Tabellen realisiert auch nicht mehr Speicherplatz belegen, und gesonderte Rechenoperationen wären dann ebenfalls unnötig.
Alternativ lassen sich Logarithmus und Antilogarithmus dynamisch berechnen. Das läuft aber im Wesentlichen auf eine Schleife ähnlich dem Brute-force-Ansatz hinaus. Auch wenn diese Schleife zur Laufzeit im Mittel effizienter als der Brute-force-Ansatz ist, gibt es eine bessere Alternative: das Berechnen des multiplikativen Inversen mit dem erweiterten euklidischen Algorithmus. Das zeigen Menezes, Oorschot und Vanstone in ihrem "Handbook of Applied Cryptography" [2] ab Seite 71 sowie Hankerson, Menezes und Vanstone im "Guide to Elliptic Curve Cryptography" [3] ab Seite 39.
Invers mit Euklid
Die Grundvariante zum Berechnen des multiplikativen Inversen in GF(2^8) mit dem irreduziblen Polynom 0x011B zeigt Abbildung 1. Der Algorithmus setzt auf den erweiterten euklidischen Algorithmus. Der Parameter u ist hierbei der Wert, für den es das Inverse zu berechnen gilt. Der Parameter v erhält das Polynom 0x011B. Die Funktion deg(p) berechnet den Grad des Polynoms p. Vereinfacht gesagt, liefert deg(p) nichts anderes als die Position des höchsten gesetzten Bits in p zurück. Je nachdem, ob nun zuerst u oder v den Wert 1 annimmt, liegt das Inverse in g1 oder g2. Dieser Algorithmus lässt sich so oder ähnlich der mathematischen Fachliteratur entnehmen. Er enthält für die Implementierung auf einem 8-Bit Mikrocontroller jedoch einige Schwächen.
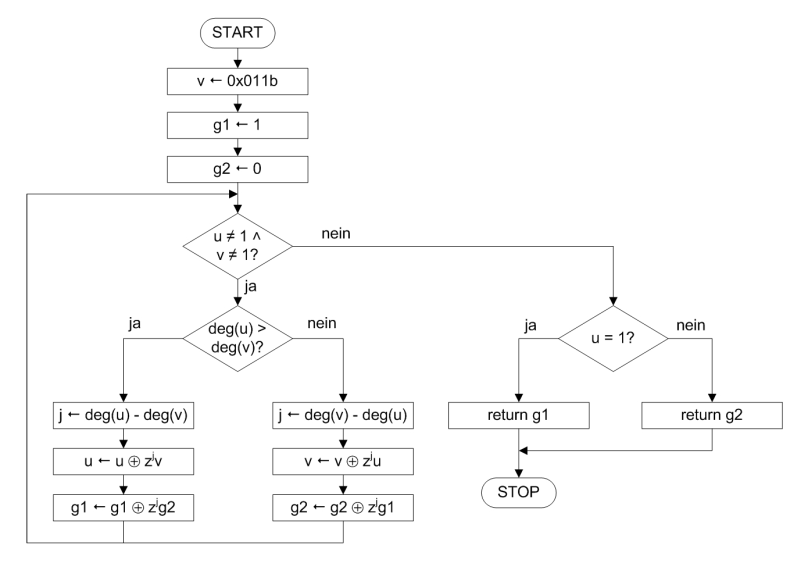
Erster markanter Punkt ist bei der ersten Anweisung nach dem START in Abbildung 1 zu sehen. Die Variable v erhält den Wert 0x011B. Das ist offensichtlich ein 16-Bit-Wert. Auf 8-Bit-Architekturen heißt das, sämtliche Operationen gesplittet auf zwei Bytes durchzuführen. Das ist pures Verschwenden von Taktzyklen und das für ein einziges Bit. Mal von Zwischenergebnissen von xtime() abgesehen, verwendet lediglich das irreduzible Polynom 0x011B dieses Bit Nr. 8. Hierfür lohnt sich das Verschwenden von Taktzyklen wohl kaum.
Ein weiterer Schwachpunkt sind die Operationen rund um deg() und die Variable j. Die j. Potenz der Variablen z ist trügerisch. z ist die Indeterminante der Polynome. z^j steht somit für den Wert des j. Bit des Polynoms. Der Algorithmus aus Abbildung 1 errechnet somit zunächst das höchste gesetzte Bit per deg() und ermittelt später das j. Bit. Mathematisch formal ist das nachvollziehbar und elegant. Für eine technische Realisierung ist das jedoch alles andere als wegweisend.
Optimierung für 8 Bit
Zunächst sind das zusätzliche Bit und damit die Notwendigkeit eines 16-Bit-Werts wegzubekommen. Hierbei hilft ein Trick, den der optimierte Algorithmus in Abbildung 2 verwendet. Der Trick beruht auf der Beobachtung, dass der Wert 0x00 per definitionem bezüglich der Multiplikation zu sich selbst invers ist. Des Weiteren ist auch der Wert 0x01 multiplikativ zu sich selbst invers. Die beiden Werte 0 und 1 sind jedoch die einzigen Werte, deren Grad vom ersten Bit abhängt. Alle anderen Werte haben ein höchstes gesetztes Bit größer als das Bit 0. Relevant für das Berechnen des Grads eines Polynoms ist dieses Bit also nur für 0 und 1, die selbst invers sind. Der Algorithmus aus Abbildung 2 sortiert die beiden Werte zu Anfang einfach aus. Das unterste Bit ist damit im Folgenden verzichtbar. Das "überzählige" achte Bit des Polynoms 0x011B wandert damit beim Bestimmen des Grads eine Position tiefer.
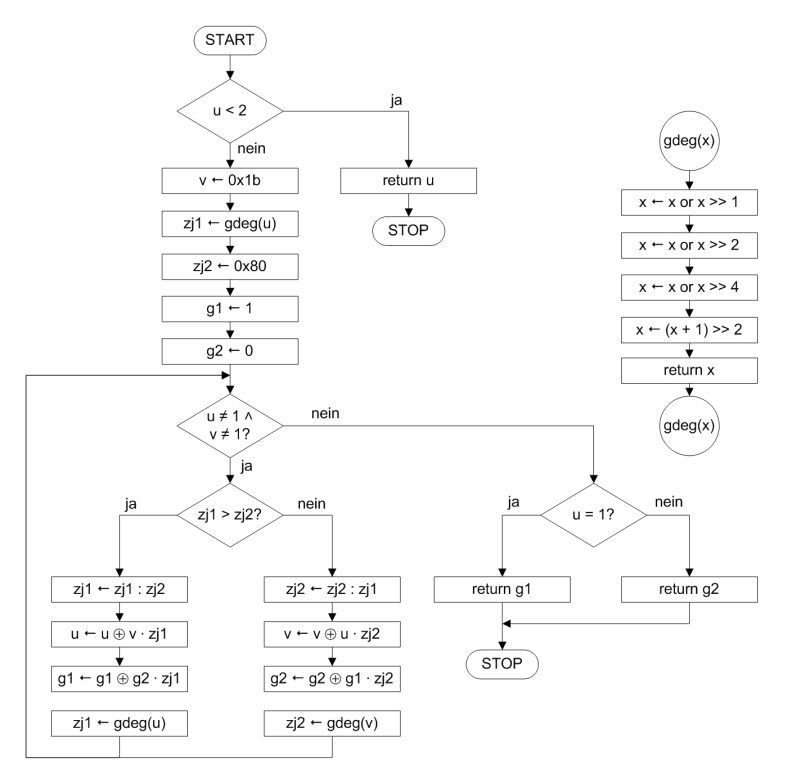
Statt nun die Polynome u und v durch einen 16-Bit-Wert zu repräsentieren, genügt es, die Polynome als 8-Bit-Wert aufzufassen. Das nullte Bit blendet die Darstellung einfach aus. Den zugehörigen Grad halten dann die Variablen zj1 für u und zj2 für v fest. Damit sind zwar immer noch 2 mal 8 Bit notwendig, aber nicht mehr 1 mal 16 Bit plus der Wert von deg().
Zudem kombiniert dieser optimierte Algorithmus die Funktion deg() mit dem Berechnen von z^j. Die Funktion gdeg() liefert von vornherein das höchste gesetzte Bit des Polynoms als seinen Wert, nicht als seine Position zurück. Das allerdings unter Einbeziehung des vorherigen Tricks, dass gdeg() lediglich die Bits 1 bis 8 betrachtet und Bit 0 streicht. Statt beispielsweise für 0x10 den deg()-Wert 4 zu liefern, gibt gdeg(0x10) das Ergebnis von 2^4 >> 1, also 0x08, zurück. Statt nun über den Wert j als Differenz der beiden deg()-Werte wie in ursprünglichen Algorithmus z^j zu ermitteln, verfügt der optimierte Algorithmus automatisch über den jeweiligen Wert von z^j. Die Differenz der Exponenten (deg(u) - deg(v)) weicht in dem Fall dem Quotienten (zj2 / zj1).
gdeg() errechnet über einfachste Schiebeoperationen das höchste gesetzte Bit. Es pflanzt das höchste gesetzte Bit dabei in alle niederen Bits. Eine Addition von 1 und das Rechtsschieben um zwei Positionen liefert das gewünschte – um Bit 0 – bereinigte Ergebnis. Dieser Algorithmus ist im Beispielprogramm in gmulinv() im Modul aes.c (Verzeichnis avr) implementiert (siehe hier). Um nun die S-Box-Werte zu berechnen, ist dem Ergebnis von gmulinv() nur noch stumpf die oben angesprochene affine Transformation aus AES (PDF) anzuhängen. Das geschieht in den Funktionen subByte() und invSubByte() aus aes.c. Damit ist das dynamische Berechnen der S-Box-Einträge 8-Bit-verträglich und effizient realisiert.
Mit dem Algorithmus aus Abbildung 2 beziehungsweise gmulinv() schließt der Artikel nun die Lücke aus dem ersten Beitrag. Exakt hiermit lässt sich das Inverse p^-1 eines beliebigen Werts p aus GF(2^8) berechnen. Multipliziert man dieses Inverse p^-1 mit einem anderen Wert q aus GF(2^8), kommt das einer Division durch p in GF(2^8) gleich. Es gilt also für alle p in GF(2^8) die folgende Aussage:
q / p = q * p^-1 = q * gmulinv(p)
Problem Schlüsselexpansion
Das zweite Problem ist die Schlüsselexpansion. Wie angesprochen kann der für die Runden expandierte Schlüssel zwischen 176 und 240 Bytes belegen. Die einzige Möglichkeit, das Belegen dieses Speichervolumens zu vermeiden, ist die Expansion des Schlüssels "on the fly" während der Ver- beziehungsweise Entschlüsselung. Statt die Rundenschlüssel in einem Array vorzuhalten, würde während der jeweiligen Runde der passende Schlüssel berechnet. Somit bräuchte man lediglich nur noch einen Speicherbereich von 16 (AES128), 24 (AES192) beziehungsweise 32 Bytes (AES256), der den jeweiligen Rundenschlüssel aufnimmt. Das Problem hierbei ist jedoch der Geschwindigkeitsverlust. Wo der Zeitaufwand bei der Expansion in ein Array nur einmal auftritt, tritt er bei der "On the fly"-Variante pro Block jeweils erneut auf. Gerade bei längeren – und daher aus mehreren Blöcken bestehenden – Nachrichten schlägt das negativ zu Buche. Bei niedrig getakteten Systemen oder Mikrocontrollern mit aktiviertem Prescaler führt das zu merklichen Verzögerungen bei Ver- und Entschlüsselung.
Die andere Variante ist, den expandierten Schlüssel in einen Festwertspeicher wie in das interne oder ein externes EEPROM auszulagern. Pro Runde ist dann der jeweilige Rundenschlüssel aus dem EEPROM in den Speicherbereich von 16 bis 32 Bytes im RAM zu laden. Das kann je nach EEPROM ebenfalls einiges an Taktzyklen kosten. In jedem Fall ist darauf zu warten, dass das EEPROM zum Lesen bereit ist (siehe Funktion eeprom_busy_wait() der AVR libc). Bei einem externen EEPROM kommt noch der zeitliche Aufwand für das Ansteuern und Synchronisieren eines externen Bus, wie I2C beziehungsweise TWI, hinzu.
Wer all das nicht will, sondern höchste Performance wünscht, kommt nicht umhin, die 176 bis 240 Bytes RAM für den expandierten Schlüssel zu opfern. Die Expansion des Schlüssels kann bei Systemstart erfolgen, oder der expandierte Schlüssel lässt sich auch komplett in einem Festwertspeicher halten und initial beim Booten beladen. In der Regel bietet sich jedoch die Expansion bei Systemstart an, da man hierdurch den nicht minder kostbaren Festwertspeicher entlasten kann. Die Schlüsselexpansion verlängert zwar die Boot-Phase des Systems, liegt aber in der Regel noch im vertretbaren Rahmen. Die Beispielimplementierung setzt daher auf diesen Ansatz. Diese Implementierung in C ist Thema des nächsten Teils. Die Simulation des AVR-Systems auf dem PC sowie eine Anregung zur Implementierung auf echter Hardware werden dort ebenfalls beleuchtet werden.
Oliver Müller
ist freiberuflicher IT-Berater und -Trainer mit den Schwerpunkten Software Engineering, Kryptografie, Java EE, Linux, Unix, z/OS und OpenVMS.
Literatur
- National Institute of Standards (Hrsg.); Announcing the Advanced Encryption Standard (AES); Federal Information Processing Standards Publication 197: November 26, 2001
- Alfred J. Menezes, Paul van Oorschot, Scott Vanstone; Handbook of Applied Cryptography; CRC Press 1997
- Darrel Hankerson, Alfred J. Menezes, Scott Vanstone; Guide to Elliptic Curve Cryptography; Springer 2004
- Florian Schäffer; AVR: Hardware und C-Programmierung in der Praxis; Elektor 2. Aufl. 2008
(ane)
