

DSGVO: Risiken beim Einsatz von Drittanbieter-Tools
Im Zuge der DSGVO ist der Einsatz externer Werkzeuge nicht einfacher geworden, denn es gibt einige Aspekte zu beachten, auch hinsichtlich Privacy.

(Bild: BeeBright / Shutterstock.com)
- Jan Thiel
Spätestens seit dem Einführen der DSGVO im Mai 2018, den wegweisenden Urteilen des EuGH sowie der jüngsten Entscheidung des BGH zur Opt-in-Pflicht für Cookies und Datenübertragungen an die Server von 3rd-Party-Providern, ist es für Entwicklerinnen und Entwickler webbasierter Anwendungen unvermeidbar zu wissen, was mit dem Code und den Daten passiert. Bußgelder und Abmahnungen durch Wettbewerber sind eine Drohkulisse, die inzwischen durchaus realistisch scheint, sobald sich die Datenschutzbehörden sortiert haben und tatsächlich in die aktive Prüfung übergehen.
Nachdem es viele Jahre ratsam und auch gängige Praxis war, externen Code aus stets verfügbaren und performanten Content Delivery Networks (CDNs) direkt von Software-as-a-Service-Anbietern zu laden, ist jetzt aufgrund der rechtlich verschärften Umstände die Zeit zum Umdenken gekommen.
Nachteile von CDNs
Während die vermeintlichen Vorteile der CDN-Einbindung Anwendern einfach zu vermitteln sind und auch Entwickler lediglich eine Referenz auf JavaScript, CSS oder auch Google-Web-Fonts zu integrieren brauchen, sind die Nachteile und Risiken auf den ersten Blick nur schwer ersichtlich.
Videos by heise
Die weitverbreitete und oftmals wenig kritisch hinterfragte Installation beliebiger Pakete aus öffentlichen Quellen, wie npm oder zentralen Maven-Repositories, sind weitere Beispiele für den Tanz auf Messers Schneide, den Entwickler tagtäglich für ihre Arbeitgeber eingehen. Stattdessen sollten sich Webentwickler vorab mit Risiken und passenden Vermeidungsstrategien auseinandersetzen, wenn sie sich auf fremden Code aus Drittanbieterquellen verlassen wollen.
Den Datenschutz im Auge behalten
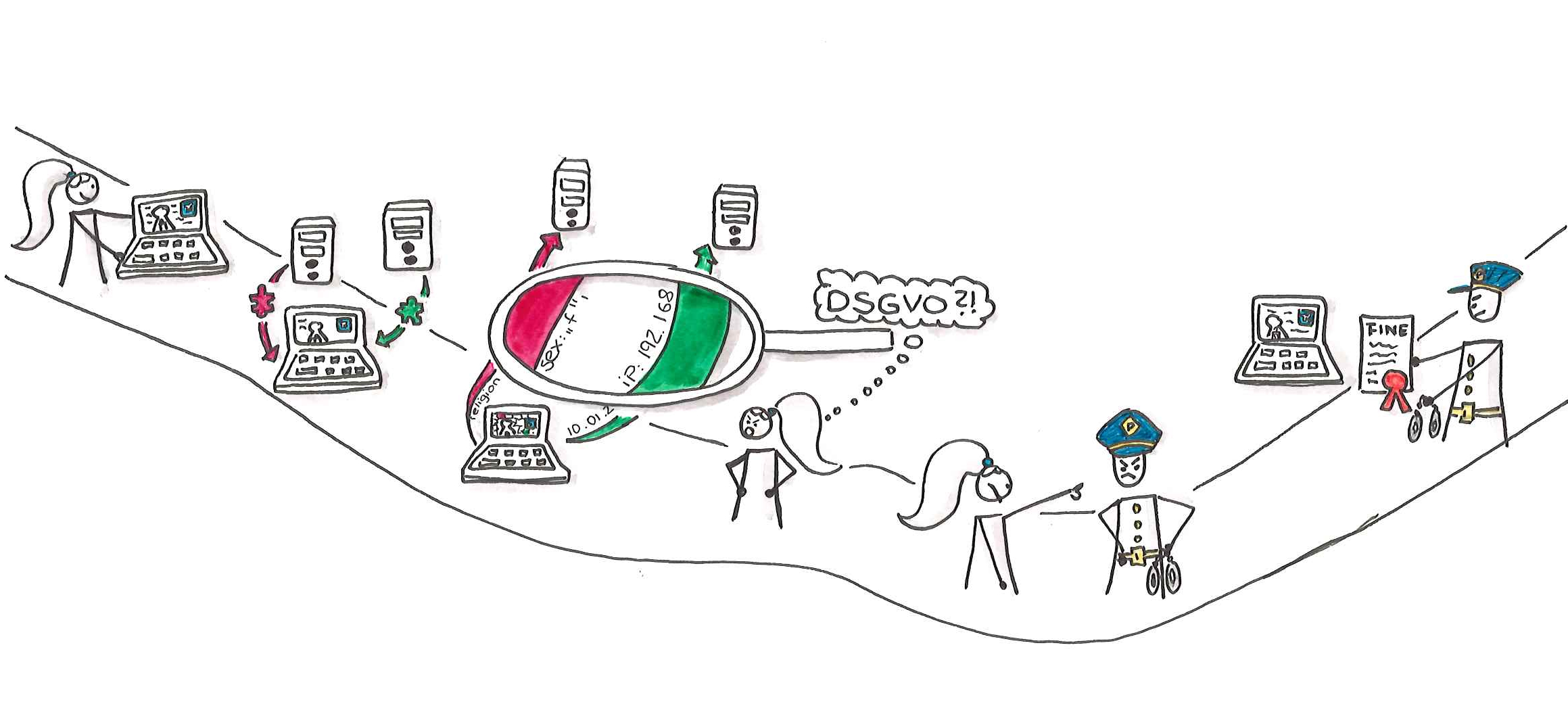
Entwickler vergessen gerne, dass die IP-Adresse als personenbezogenes Datum gilt und damit eine Übermittlung an eine dritte Partei die explizite Zustimmung vorab erfordert. Binden Entwickler Ressourcen nun so ein, dass ein externer Server sie lädt, findet unvermeidbar eine Übertragung der IP-Adresse des Kunden statt.
Je nach Art der geladenen Ressourcen fällt es schwer, Besuchern zu erklären, warum sie für den Einsatz einer Schriftart seine IP-Adresse an Google oder andere Dienstleister außerhalb der EU übermitteln müssen, ohne vorher gefragt zu werden. Zumal der Kunde keinen unmittelbar erkennbaren Vorteil davon hat, dass die Dateien von einem fremden Server kommen. Die Pflicht, die Zustimmung des Kunden einzuholen, liegt wiederum bei Entwicklern und Betreibern der Webanwendung und wird bis heute in vielen Fällen rechtswidrig nicht erfüllt.
(Bild: Romina Borgardt)
Befindet sich Drittanbietercode jedoch integriert in der eigenen Webanwendung, und damit unabhängig von der Zustimmung der Kunden, hat der Code dieselben Rechte und Möglichkeiten wie der Code, der aus vertrauenswürdigen Quellen der Betreiber stammt. Können Entwickler lokalen Code vor einer Ausspielung vergleichsweise einfach prüfen, ist das mit Code aus externen Quellen komplizierter.
Wie bei jedem Risiko gilt es hinsichtlich einer möglichen Datenschutzverletzung, die konkrete Eintrittswahrscheinlichkeit sowie die etwaigen Folgen zu bewerten und einzuschränken. Kommen 3rd-Party-Provider aus der EU, ist die Wahrscheinlichkeit für die Unterstützung datenschutzkonformer Angebote um ein Vielfaches höher, da Anbieter aus der EU denselben rechtlichen Anforderungen unterworfen sind wie das eigene Unternehmen. Kommen die Anbieter aus Drittstaaten wie den USA, ist insbesondere nach dem (erneuten) Ende des Datenaustauschabkommens "Privacy Shield" umso mehr Vorsicht und Sorgfalt geboten. Im schlimmsten Fall holt man sich unwissentlich eine tickende "Datenschutz-Bombe" ins eigene Haus.
Security und fehlerhafter Code
Selbst wenn die eigene Webanwendung gut abgesichert ist, öffnen extern eingebundene Ressourcen einen zusätzlichen und für Angreifer lohnenden Angriffsvektor. Sie können davon ausgehen, dass bei einer erfolgreichen Infektion des externen Drittanbieterservers tendenziell alle Nutzer der dort bereitgestellten Ressourcen die infizierten Versionen beziehen und ausführen.
Da der Code mit denselben Rechten läuft wie der legitime der Entwickler der besuchten Webanwendung, stehen Angreifern alle Türen offen. Die Folgen sind hinlänglich bekannt und reichen vom "harmlosen" Cryptomining über die böswillige Manipulation der Webanwendung bis hin zum diskreten und unauffälligen Diebstahl monetär interessanter Daten. Das können Kreditkarteninformationen, aber auch Passwörter und andere sensible Daten sein.
Lässt man den bösen Vorsatz außen vor, bleibt noch immer das Risiko, dass der externe Code fehlerhaft ist oder falsche Abhängigkeiten mit ausliefert, die wiederum dazu führen, dass die eigene Webanwendung angreifbar oder schlimmstenfalls nicht mehr nutzbar ist. Der Fall von Google aus dem Jahr 2010, als Chrome einen Bug in der Datumsberechnung im produktiven Build enthielt und dadurch eine große Zahl von Date-Pickern "über Nacht" nicht mehr funktionierten, ohne dass ein Fehler auf Seiten der Entwickler und Webanwendungsbetreiber vorlag, macht dies deutlich. Ähnliche Erfahrungen hat sicher jeder Entwickler schon gemacht, der stundenlang nach Fehlern im eigenen Code sucht, die in der Release-Abnahme noch nicht vorhanden waren, nur um festzustellen, dass sie nicht aus dem eigenen Code stammen, sondern externer Code sie verursacht hat.
Performanceengpässe vermeiden
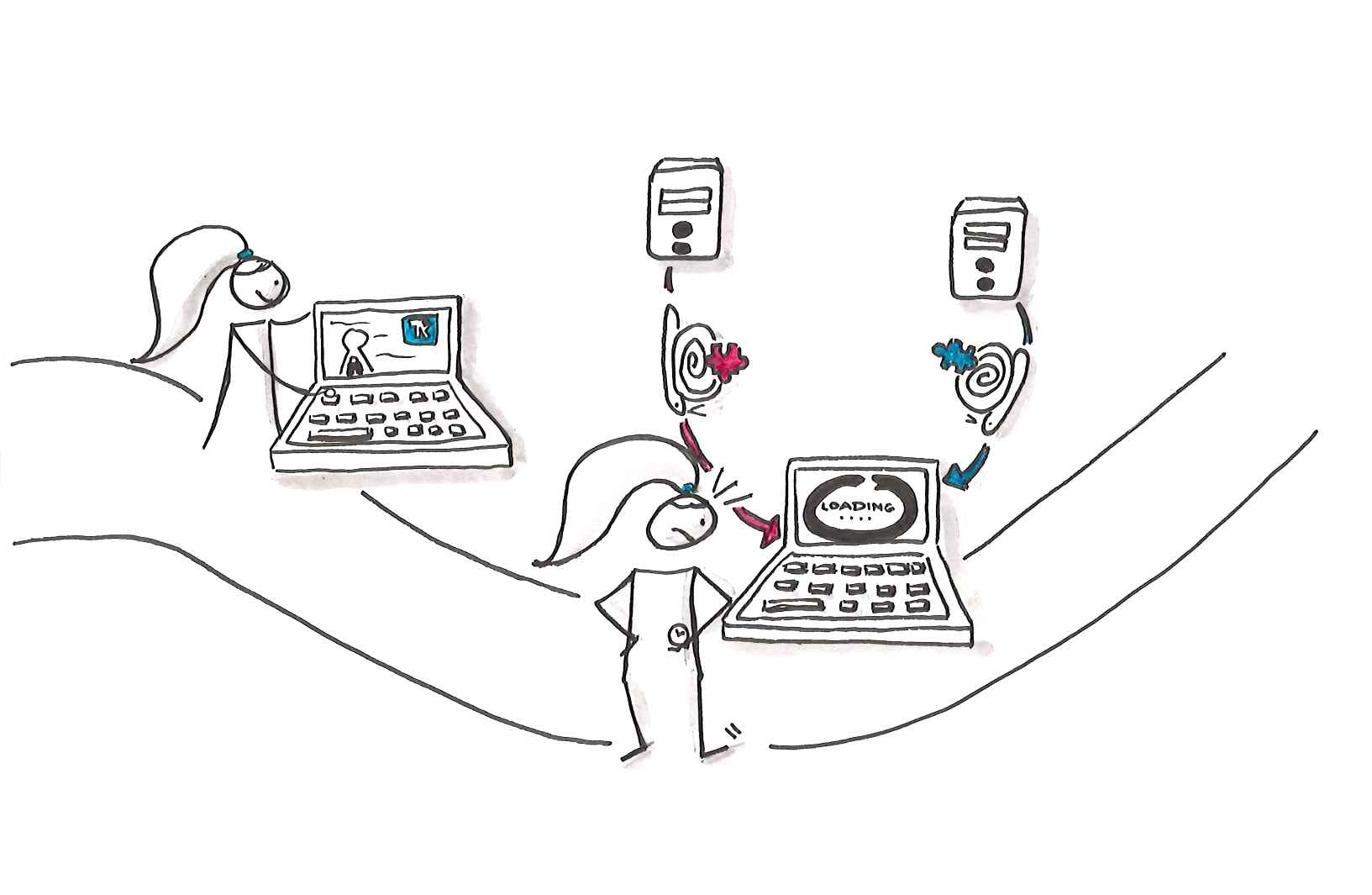
Ein weiterer, leicht zu übersehender Aspekt lautet "blockierende Abhängigkeit". Während lokal gehostete Ressourcen, Pakete, Skripte et cetera von der eigenen Infrastruktur abhängig sind, schaffen 3rd-Party-Ressourcen eine zusätzliche Abhängigkeit. Die kann sowohl den Entwicklungsprozess als auch den produktiven Betrieb beeinflussen.
(Bild: Romina Borgardt)
Die direkte und offensichtliche Abhängigkeit ist die Verfügbarkeit der benötigten 3rd-Party-Ressourcen. Dabei unterscheidet man zumeist binär: die Ressourcen sind entweder verfügbar oder nicht. Sind notwendige Ressourcen nicht vorhanden oder nicht abrufbar, kann das dazu führen, dass neben einem Funktionsverlust der produktiven Anwendung bei direkter Abhängigkeit auch die Entwicklungs- und Build-Prozesse scheitern und stillstehen.
Des Weiteren können langsam ladende Ressourcen, die im <head> extern synchron eingebunden sind, dazu führen, dass eine Webanwendung mehrere Sekunden zum Laden benötigt – mit der Gefahr, dass Anwender oder potenziell interessierte Kunden vorzeitig abspringen. Denn bei den Wartezeiten gilt die Grenze von zwei Sekunden nach wie vor als Schallmauer, die Kunden dazu bewegt, eine Webanwendung zu verlassen, egal wie vielversprechend sie ist.
Sensible Daten schützen
Als Mitarbeiter einer Krankenkasse und Körperschaft des öffentlichen Rechts steht der Autor dieses Beitrags häufig im Zentrum des Interessenkonflikts. Ist der Bestellverlauf im Amazon-Webshop möglicherweise nur bedingt schützenswert, sind Informationen über den Krankheitsverlauf oder auch nur der Verlauf der auf der Webseite einer Krankenkasse abgerufenen Krankheitsbilder hingegen hochgradig sensibel. Eine Übermittlung der Informationen in Kombination mit persönlichen Identifikationsmerkmalen wie der IP-Adresse an Dritte sollte in keinem Fall erfolgen.
Genau das ist jedoch der Fall, wenn 3rd-Party-Code unkontrolliert auf Webseiten eingebunden wird und damit auch Zugriff auf den gesamten Verlauf sowie die IP-Adresse der Besucher erhält.
Suchen Nutzer zum Beispiel auf der Webseite einer großen deutschen Direkt-Krankenkasse nach dem sensiblen Thema "Syphilis" wird die Information mit einer Reihe externer Anbieter geteilt – und zwar inklusive der IP-Adresse des Suchenden und aller relevanten Metainformationen, die ausreichen, um einen eindeutigen Fingerabdruck des Suchenden auch über die Grenzen von Cookies und Co. hinweg zu erstellen. Die Direkt-Krankenkasse teilt die Informationen, die im Rahmen einer Suche nach kritischen Gesundheitsthemen anfallen, zum Beispiel ohne Opt-in und ohne vorherige warnende Information mit den folgenden Anbietern: Google (Tag Manager), Typekit und Cookiebot.
(Bild: Romina Borgardt)
Für diese 3rd-Party-Anbieter sind Nutzer dadurch transparent. Betreiber der Webanwendung begeben sich in eine Grauzone. In dem konkreten Beispiel sind lediglich einige der Anbieter in der Datenschutzerklärung erwähnt und sicherlich gibt es – nicht öffentlich einsehbare – Verträge, die den Einsatz der gesammelten Daten im Rahmen des "EU-US Privacy Shields" reglementieren. Was die Anbieter jedoch letztlich mit den Daten anfangen, kann kein Betreiber nachvollziehen oder dem Endkunden garantieren. Da selbst der EuGH das Schutzniveau der US-Anbieter nicht nachvollziehen kann und von einem unkontrollierten Datenabfluss an Sicherheitsbehörden ausgehen muss, wurde auch das Privacy-Shield als Grundlage zur Datenübertragung inzwischen "vom EuGH für nichtig erklärt (Schrems gegen Facebook)".
Wie können sich Betreiber einer Webanwendung nun absichern, wenn das Vertrauen in die Versprechen oder vertraglichen Regelungen nichts taugt? Die einfache Lösung ist der vollständige Verzicht auf externe Tools – zumindest auf solche von Anbietern, die außerhalb des europäischen Wirtschaftsraums ansässig sind. Da dieses Vorgehen jedoch häufig zu Unverständnis und Frust bei Marketing-Kollegen und Vorgesetzten im eigenen Unternehmen führen dürfte, muss eine echte technische Alternative her.
Einsatz eines Privacy Proxy
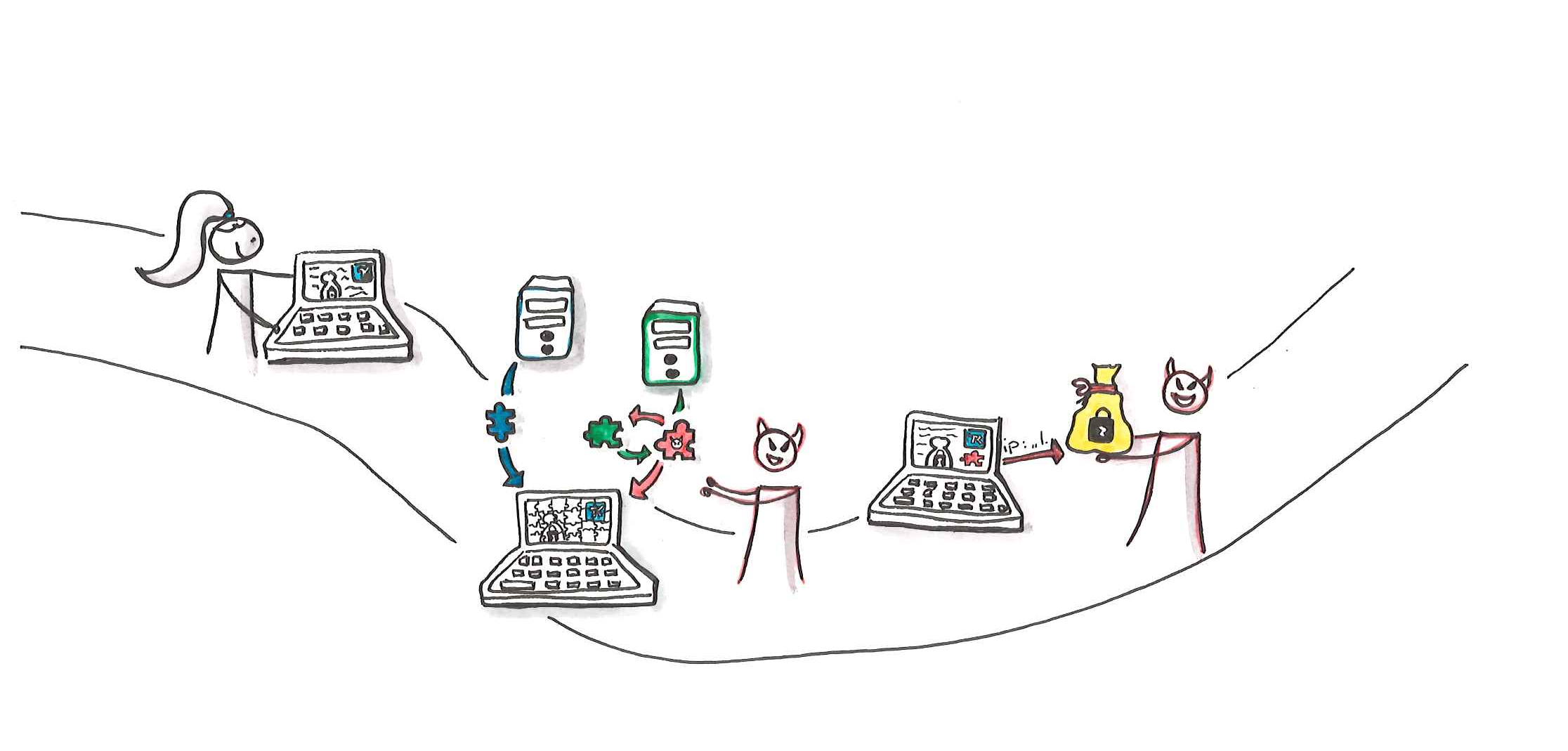
Ein Privacy Proxy ist eine relativ junge Technik, die sich am Markt noch nicht vollständig durchgesetzt hat. Primär liegt das daran, dass die meisten Cloud-Tool-Anbieter Entwicklern ausschließlich Ressourcen von ihren eigenen Servern anbieten wollen, die sie auch selbst kontrollieren. Die Motivation für dieses Vorgehen ist nachvollziehbar, wenn die Anbieter damit sicherstellen wollen, dass sie so kurze Releasezyklen einhalten und schnelle Updates der Ressourcen vornehmen können. Sind hingegen die Metadaten der Verbindung der Endkunden wie IP-Adresse, Browserversion oder Fingerprint das eigentliche Ziel dieser Vorgehensweise, wird die Abneigung der Anbieter gegenüber Privacy Proxys nachvollziehbar.
Ein Privacy Proxy setzt auf das altbewährte Konzept einer Server-zu-Server-Verbindung. Daten der Endkunden gehen ausschließlich an einen vertrauenswürdigen Server des Webanwendungsbetreibers, der dann die Daten filtert und kontrolliert weiterleitet. Eine direkte Kommunikation zwischen Endkunden und 3rd-Party-Provider findet nur in absoluten Ausnahmefällen statt. Alle weitergeleiteten Daten sind durch die Betreiber der Webanwendung kontrollierbar und revisionssicher nachweisbar.
Ein dafür geeignetes Tool auf Basis von Java und Spring Boot hat beispielsweise die Techniker Krankenkasse als Open-Source-Projekt auf GitHub bereitgestellt. Eine Beispielkonfiguration, die die Basis-Library verwendet und für eigene Projekte dienen kann, findet sich ebenfalls auf GitHub. Java-Kenntnisse sind nicht zwingend erforderlich. Das Konzept sollte sich relativ einfach auch auf anderen Plattformen wie Node.js umsetzen lassen, sofern sie Scheduling- beziehungsweise Cron-Support anbieten.
Der Privacy Proxy stellt darüber hinaus beliebige Ressourcen von 3rd-Party-Providern lokal bereit und aktualisiert diese regelmäßig automatisch. Die Aktualität der Ressourcen ist damit auch ohne die direkte CDN-Einbindung gegeben. Somit bleibt auch die Auslieferung von 3rd-Party-Ressourcen ein Teil der originären Domain. 3rd-Party-Cookies bieten damit keine Möglichkeit, Daten unkontrolliert abfließen zu lassen. Sämtliche Daten werden als 1st-Party-Cookies gesetzt und sind nur durch Requests über den Privacy Proxy zugänglich.
Der Rückkanal zum 3rd-Party-Provider erfolgt ebenfalls über den Privacy Proxy, vorausgesetzt der Anbieter stellt die Möglichkeit zur Verfügung, die Domain für Tracking- und Analytics-Requests zu verändern. Das ist zwar nicht selbstverständlich, Unternehmen können schlimmstenfalls jedoch immer eine Anpassung der 3rd-Party-Ressourcen selbstständig vornehmen. In der Praxis ist davon jedoch abzuraten, eine Konfiguration von außen ist generell vorzuziehen. Gerade nicht in der EU ansässige Anbieter sind dabei häufig unkooperativ, da sie keinen Bedarf für einen solchen Anwendungsfall sehen oder dieser den Unternehmenszielen widerspricht.
Sicherheit und Stabilität steigern mit Privacy Proxys
Ein Privacy Proxy bietet eine Reihe von Vorteilen, die jedoch erst die Grundlage für weitreichendere Maßnahmen wie Content Security Policies, Audits oder Qualitäts- und Sicherheitschecks sind, und die im Folgenden näher betrachtet werden sollen.
Content Security Policies (CSPs)
Erfolgt das Einbinden sämtlicher Ressourcen von der eigenen Domain (also lokal) und läuft die komplette Kommunikation zu den Drittanbietern über die lokale Domain, lassen sich CSPs relativ einfach konfigurieren. Die häufig aufwendige und lästige Arbeit der Analyse aller externen Quellen und Domains entfällt. Die einzig freizugebende Domain ist die eigene (= "self"). Jegliche Kommunikation mit anderen Domains sollten Entwickler vollständig unterbinden. Selbst bei Kompromittierung externer Ressourcen ist ein Datenabfluss erheblich erschwert und nahezu ausgeschlossen. Breit angelegte Angriffe auf einen globalen Anbieter haben bei der eigenen Webanwendung dann kaum Erfolg. Einzig maßgeschneiderte und gezielte Angriffe vermögen noch einen Weg vorbei an den CSPs zu finden.
Dennoch verbleiben nach wie vor Ressourcen, die ein externes Whitelisting erforderlich machen – darunter Karten- beziehungsweise Navigationsanwendungen und andere komplexe Funktionen mit zahlreichen externen Includes. Ist ein Privacy Proxy implementiert, betrifft dies nur noch wenige Ressourcen. Darüber hinaus unterbinden strikte CSPs auch das Nachladen (Piggy Backing) weiterer Skripte effizient. Wenn ein 3rd-Party-Provider nicht sauber und transparent arbeitet, ist sein Produkt in einer strikt konfigurierten CSP-Umgebung zum Scheitern verurteilt. Whitelisting ist gegenüber Blacklisting stets als sicherer zu bevorzugen.
Audits und Nachvollziehbarkeit
Legt man lokale Kopien von externen Ressourcen an, lassen sie sich versionieren und revisionssicher archivieren. In einem typischen 3rd-Party-CDN-Szenario ist es hingegen unmöglich nachzuweisen, welcher Code-Stand zu welchem Zeitpunkt deployt war. Ein lokales Archiv ist dabei eine große Hilfe.
Qualitäts- und Sicherheitschecks
Auch Drittanbieter machen Fehler. Liefern sie Ressourcen aus, die für den Betrieb der Webanwendung notwendig, jedoch fehlerhaft sind, erweist sich das in den meisten Fällen als Blocker mit externer Abhängigkeit – ein Worst-Case-Szenario. Liegen die vorangegangenen Versionen der Ressourcen jedoch in einem lokalen Archiv vor, lässt sich ein Rollback wie mit eigenem Code vergleichsweise einfach umsetzen – in der Regel sogar ohne, dass der externe Dienstleister reagieren muss.
Etwaige Fehler oder anderweitig negative Auswirkungen durch 3rd-Party-Provider lassen sich auf diese Weise auch einfach dokumentieren und nachweisen, ohne dass der Anbieter potenzielle Beweise durch ein Update seiner CDN-Ressourcen entfernen könnte.
Theoretisch lassen sich durch lokale Kopien auch kompromittierte Skriptversionen scannen und vor dem Ausspielen herausfiltern. Leider gibt es bislang kein dem Autor bekanntes Tool, das zuverlässig Webressourcen wie JavaScript und Web Fonts heuristisch auf Schadsoftware scannen kann. Der „klassische Virenscanner“ für Webressourcen existiert leider noch nicht. NPM-Pakete auf Basis ihrer Versionen auf bekannte Schwachstellen zu scannen, ist zwar möglich, basiert jedoch lediglich auf der Pflege einer zentralen Datenbank sowie Versionsabgleichen. Einen zielgerichteten Angreifer hält das nicht davon ab, kompromittierten Code aufzuspielen.
Herausforderungen beim Einsatz eines Privacy Proxy
Besteht dennoch die Notwendigkeit Daten zurück zu den Anbietern übertragen zu müssen, beispielsweise zum Zwecke des Trackings und der Analyse, sollte zumindest die URL des Rückkanals konfigurierbar sein. Darüber hinaus muss klar festgeschrieben sein, welche Metadaten der Anbieter benötigt. Neben den Query-Parametern muss definiert sein, ob Methoden wie GET, POST, PUT oder andere notwendig sind. Darüber hinaus sind Header und Cookies festzulegen, die man übergeben muss.
Alle weiteren Metadaten müssen manuell im Privacy Proxy konfiguriert sein. Dieses formale Whitelisting stellt sicher, dass auch in Zukunft nicht stillschweigend zusätzliche Daten erhoben und ausgewertet werden können. Auffällige Daten können Entwickler darüber hinaus blacklisten oder manipulieren. Als Beispiel sei eine anonymisierte IP-Adresse genannt, die das Werkzeug zumindest mit zwei Oktetten (1.2.xxx.xxx) DSGVO-konform übermittelt, oder die es vollständig unterdrücken kann.
Fazit: Ein Privacy Proxy schafft Kontrolle und Vertrauen
Der Einsatz eines Privacy Proxy verschafft Webanwendungsbetreibern und IT-Verantwortlichen die zwingend erforderliche Kontrolle darüber, nicht nur DSGVO-konform zu arbeiten, sondern auch zu wissen, welche Daten überhaupt an externe Anbieter abfließen. Die Fachabteilung muss dank Privacy Proxy dennoch nicht auf Funktionen externer Anbieter verzichten. Sie kann auch in Verbindung mit Werkzeugen für das Consent Management deutlich mehr 3rd-Party-Tools rechtssicher einsetzen, die ansonsten eine IP-Adresse als personenbezogenes Datum übermitteln würden und damit Consent-pflichtig wären.
Weigern sich Drittanbieter das Konzept des Privacy Proxy zu akzeptieren, sollte man kritisch hinterfragen, ob die Zusammenarbeit mit einem solchen Partner das Risiken wert ist. Beim Einsatz eines Privacy Proxy gibt es keine technischen Beschränkungen (Ausnahmen bestehen ausschließlich bei komplexen Anwendungen wie Maps und Co.), Grenzen sind dem Konzept daher primär durch den Unwillen extern Beteiligter gesteckt. Im Zweifelsfall müssen dafür aber die Betreiber der Webanwendung die Zeche zahlen – entweder in Form von Strafen oder durch verloren gegangenes Vertrauen der Benutzer, das sich in reduzierten Conversions, Kundenbesuchen und so weiter niederschlägt.
Webanwendungsbetreiber, die sich das Leben noch einfacher machen wollen, können den Privacy-Proxy-Ansatz mit einem Tag-Management kombinieren. Im Zusammenspiel von Tag-Management und Privacy Proxy lassen sich der IT-Aufwand auf ein Minimum reduzieren und die Ressourcen kooperationsunwilliger 3rd-Party-Provider selbstständig umzusetzen. Auch das Verwalten und zentralisierte Managen der übertragenen Daten gelingt übersichtlicher – im Idealfall sogar ohne die Beteiligung der IT.
Jan Thiel
ist regelmäßiger Speaker auf Konferenzen und Meetups und treibt beruflich die Web-Frontend-Architektur bei der Techniker Krankenkasse voran – mit Fokus auf technischen Datenschutz, Barrierefreiheit und das Handling von 3rd-Party-Providern. Als Datenschutzenthusiast gerät er häufig ins Kreuzfeuer zwischen den Anforderungen von Fachabteilungen, der Datensparsamkeit und der DSGVO.
(map)
