Das Fork/Join-Framework in Java 7
Wann sollte man den neuen ForkJoinPool dem klassischen ThreadPoolExecutor vorziehen, und wann lässt man es besser bleiben? Dieser Artikel stellt die wichtigsten Neuerungen des Fork/Join-Framework aus Java 7 vor und vergleicht die Performance in zwei Anwendungsgebieten aus der Praxis.


Wann sollte man den neuen ForkJoinPool dem klassischen ThreadPoolExecutor vorziehen, und wann lässt man es besser bleiben? Dieser Artikel stellt die wichtigsten Neuerungen des Fork/Join-Framework aus Java 7 vor und vergleicht die Performance in zwei Anwendungsgebieten aus der Praxis.
Eine wesentliche Neuerung von Java 5 war der ExecutorService, eine Abstraktion zur asynchronen Ausführung von Tasks. Der ThreadPoolExecutor implementiert das Konzept mit einem intern verwalteten Thread Pool, dessen Worker Threads die anfallenden Tasks abarbeiten. Der ThreadPoolExecutor besitzt eine zentrale Eingangs-Queue für neue Tasks (Runnables oder Callables), die alle Worker Threads gemeinsam nutzen.
Ein Nachteil des ThreadPoolExecutor ist, dass es beim Zugriff der Threads auf die gemeinsame Eingangs-Queue zu Konkurrenzsituationen kommen kann und durch den Synchronisations-Overhead wertvolle Zeit für die Bearbeitung der Tasks verloren geht. Auch gibt es keine Unterstützung für die Zusammenarbeit mehrerer Threads bei der Berechnung von Tasks.
Seit Java 7 gibt es mit dem ForkJoinPool eine weitere Implementierung des ExecutorService: Er verwendet zusätzliche Strukturen, um die Nachteile des ThreadPoolExecutor zu kompensieren und gegebenenfalls eine effizientere Bearbeitung von Tasks zu ermöglichen. Das zugrunde liegende Konzept, das Fork/Join-Framework, wurde von Doug Lea bereits 2000 vorgestellt [1] (PDF) und seitdem weiter verfeinert und verbessert.
Wenn der ForkJoinPool in der Praxis zum Einsatz kommen soll, stellt sich leider oft Verunsicherung ein. Das liegt zum einen daran, dass viele Tutorials nur "Sandkastenbeispiele" verwenden. So entsteht schnell der Eindruck, der ForkJoinPool wäre nur für gekünstelte Fragestellungen oder ganz spezielle Anwendungen geeignet. Für Irritation sorgt außerdem, wenn der ForkJoinPool in scheinbar vielversprechenden Szenarien keinerlei Performancegewinn oder sogar eine Verschlechterung gegenüber dem ThreadPoolExecutor aufweist.
Dieser Artikel soll etwas Licht ins Dunkel bringen und anhand von Anwendungen aus der "echten" Praxis ein besseres Verständnis dafür schaffen, welche Szenarien sich für den ForkJoinPool eignen (und warum das so ist).
Arbeitsweise und Struktur
Genau wie der ThreadPoolExecutor verwendet der ForkJoinPool eine zentrale Eingangs-Queue und einen internen Thread Pool. Allerdings besitzt jeder Worker Thread zusätzlich eine eigene Task Queue, in die er selbst neue Tasks einplanen kann (siehe Abb. 1). So lange seine Task Queue noch Tasks enthält, arbeitet der Thread ausschließlich diese Tasks ab. Ist die eigene Queue leer, folgt der Thread einem Work-Stealing-Algorithmus: Er sucht in den Task Queues anderer Worker Threads nach einem verfügbaren Task und bearbeitet ihn. Sollte keiner zu finden sein, greift er auf die zentrale Eingangs-Queue zu.
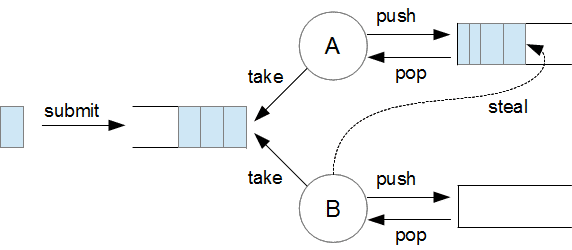
Das Verfahren hat zwei potenzielle Vorteile: Erstens arbeitet jeder Thread soweit möglich über einen längeren Zeitraum nur auf seiner eigenen Queue, ohne mit den anderen Threads in Kontakt zu kommen. Zweitens besteht für die Threads die Möglichkeit, sich gegenseitig Arbeit abzunehmen.
Um den Overhead durch die zusätzlichen Queues und das Work Stealing zu minimieren, wurde die Implementierung des ForkJoinPool stark in Bezug auf Performance verbessert. Zwei Aspekte sind hervorzuheben:
- Die Task Queues der Worker Threads verwenden als Datenstruktur eine Deque (double-ended queue), die effizientes Einfügen und Entfernen von Elementen an beiden Enden unterstützt. Der Worker Thread selbst arbeitet nur an einem Ende seiner Deque, analog zu einem Stack: Er legt neue Tasks auf die Spitze des Stacks (push) und holt sich von dort Tasks zur Bearbeitung (pop). Die anderen Threads hingegen greifen beim Work Stealing stets auf das andere Ende der Deque zu. Es kommt also beim Work Stealing in der Regel nur zu Konkurrenzsituationen zwischen Threads, die sich gleichzeitig aus derselben Task Queue bedienen möchten -- der "Eigentümer" der Queue ist nur selten involviert.
- Findet ein Thread beim Work Stealing keine verfügbaren Tasks, besteht die Gefahr, dass er fortwährend dieselben leeren Queues abklappert und so CPU-Zeit verbrennt. Um das zu vermeiden, gehen "arbeitslose" Worker Threads nach bestimmten Regeln in einen Ruhezustand über. Das Framework spricht sie gezielt an, sobald wieder Tasks verfügbar sind.
Fork und Join
Eine wichtige Beobachtung ist, dass die lokalen Task Queues und das Work Stealing nur zum Einsatz kommen (und daher auch nur dann einen Vorteil bringen), wenn die Worker Threads tatsächlich neue Tasks in die eigene Queue einplanen. Geschieht das nicht, reduziert sich das Verhalten des ForkJoinPool auf das eines ThreadPoolExecutor mit sinnlosem Overhead.
Der ForkJoinPool bietet daher eine explizite Schnittstelle an, mit der Tasks im Rahmen ihrer Ausführung neue Tasks einplanen können. Statt auf Runnables oder Callables arbeitet der ForkJoinPool auf sogenannten ForkJoinTasks. Ein ForkJoinTask besitzt während seiner Ausführung einen Kontext, innerhalb dessen neu erzeugte ForkJoinTasks automatisch in die lokale Task Queue eingeplant werden (fork). Benötigt der ursprüngliche Task die Ergebnisse der abgezweigten Tasks, kann er auf diese warten und sie zu einem Gesamtergebnis zusammenführen (join). Um die Anwendung von Fork und Join zu vereinfachen, gibt es zwei konkrete Implementierungen der ForkJoinTask: Der RecursiveTask liefert ein Ergebnis zurück, die RecursiveAction nicht.
Geeignete Szenarien für den ForkJoinPool
Ein Szenario, bei dem Tasks weitere Tasks einplanen, beruht auf dem Prinzip der Zerlegung: Ist der Berechnungsaufwand für einen Task sehr groß, lässt er sich rekursiv in viele kleine Subtasks zerlegen. Durch das Work Stealing beteiligen sich andere Threads ebenfalls an der Berechnung (und zerlegen ihre Subtasks wenn möglich erneut). Nur wenn ein Subtask nach bestimmten Kriterien klein genug ist und sich eine weitere Zerlegung nicht lohnt, wird er direkt berechnet. Besonders verlockend an dem Ansatz ist, dass zu Beginn einer rekursiven Zerlegung recht große Subtasks entstehen, die andere Threads dann unmittelbar stehlen können. Das begünstigt eine gleichmäßige Lastverteilung zwischen den Threads.
In einem anderen, gerne unterschätzten Szenario planen Tasks auch ohne Zerlegung weitere Tasks ein. Ein Task stellt dann zwar eine in sich abgeschlossene Aktion dar, löst aber trotzdem Folge-Aktionen aus, die durch zusätzliche Tasks dargestellt werden. Im Prinzip kann man so jede Form ereignisgesteuerter Abläufe modellieren. Im Extremfall könnte sich in einem solchen Szenario jeder Worker Thread fortlaufend selbst mit weiteren Tasks versorgen. Alle Threads wären beschäftigt, und trotzdem käme keine Konkurrenzsituation auf.
Im Folgenden wird an jeweils einem Praxisbeispiel untersucht, wie sich der ForkJoinPool in den beiden genannten Szenarien gegenüber dem ThreadPoolExecutor schlägt. Der komplette Quellcode der Beispiele ist auf GitHub [2] verfügbar.
MapReduce
Szenario 1: MapReduce
Die betrachtete Anwendung ist eine Dokumentenverwaltung, mit der Benutzer unter anderem Dokumente miteinander teilen und mit Tags versehen können. Jedes Dokument ist also mit einer Menge von Benutzern und einer Menge von Tags assoziiert. Eine mögliche Aufgabe wäre nun, für jeden Benutzer die Menge aller Tags zu berechnen, die sich an den für ihn sichtbaren Dokumenten befinden. Nützlich ist die Information zum Beispiel um jedem Benutzer eine Liste von Suchvorschlägen bestehend aus den Tags aller seiner Dokumente anzubieten.
Diese Aufgabenstellung ist ein typischer Anwendungsfall für MapReduce. Ein MapReduce-Job iteriert zunächst über die Eingabedaten (alle Dokumente) und extrahiert bestimmte Daten (deren Benutzer und Tags). Anschließend reduziert er diese zu einem Ergebnis (eine Tag-Menge pro Benutzer).
Für den ThreadPoolExecutor wird ein Threadpool fester Größe mit numThreads Worker Threads verwendet. Die Menge der Dokumente wird in numThreads gleich große Teilmengen aufgespalten, die als Tasks zur Bearbeitung einzuplanen sind. Jeder Task führt einen Teil des MapReduce-Jobs für seine Dokumente durch. Sobald der ThreadPoolExecutor alle Tasks fertiggestellt hat, werden deren Ergebnisse in einem abschließenden Schritt miteinander kombiniert.
Der ForkJoinPool wird ebenfalls mit numThreads Worker Threads initialisiert. numThreads beschreibt hier die ungefähre Anzahl an Worker Threads, die aktiv an Tasks arbeiten. Das zu beachten ist wichtig, da ein Thread gegebenenfalls erst auf die Ergebnisse abgezweigter Tasks warten muss, bevor er die ursprüngliche Task abschließen kann. Der Thread versucht dann zwar zunächst, ausgewählte Tasks von anderen Threads auszuführen, statt einfach nur zu warten. Sollte das allerdings nicht möglich sein, wird er in den Ruhezustand versetzt. In solchen Situationen behält sich der ForkJoinPool vor, den Ausfall durch einen zusätzlichen Worker Thread zu kompensieren. Daher lässt sich die Thread-Anzahl beim ForkJoinPool nur näherungsweise kontrollieren.
Um die Formulierung von MapReduce-Jobs für den ForkJoinPool allgemein halten zu können, lässt sich im vorliegenden Beispiel eine Abstraktion durch die Definition von zwei Interfaces erreichen:
public interface Input<T> {
boolean shouldBeComputedDirectly();
Output<T> computeDirectly();
List<MapReduceTask<T>> split();
}
public interface Output<T> {
Output<T> reduce(Output<T> other);
T getResult();
}
Der Typparameter T steht für den Ausgabetyp des gesamten MapReduce-Jobs. Input<T> stellt die Eingabedaten für einen Task dar und kann Auskunft darüber geben, ob der Task weiter zu zerlegen oder direkt zu berechnen ist (shouldBeComputedDirectly()). Entsprechend kann Input<T> sich direkt berechnen (computeDirectly()) oder in neue Tasks zerlegen lassen (split()). Output<T> repräsentiert das Ergebnis eines Tasks und unterstützt, neben dem Zusammenführen mehrerer solcher Ergebnisse zu einem gemeinsamen (reduce()), das Abfragen des Gesamtergebnisses (getResult()).
Mit den beiden Interfaces lässt sich eine Klasse MapReduceTask<T> definieren. Da sie ein Ergebnis zurückliefern soll, ist sie von RecursiveTask abgeleitet.
public class MapReduceTask<T> extends
RecursiveTask<Output<T>> {
private final Input<T> input;
public MapReduceTask(Input<T> input) {
this.input = input;
}
@Override
protected Output<T> compute() {
if (input.shouldBeComputedDirectly()) {
return input.computeDirectly();
}
List<MapReduceTask<T>> subTasks = input.split();
for (int i = 1; i < subTasks.size(); i++) {
subTasks.get(i).fork();
}
Output<T> result = subTasks.get(0).compute();
for (int i = 1; i < subTasks.size(); i++) {
result = result.reduce(subTasks.get(i).join());
}
return result;
}
}
Sobald ein Worker Thread ein Task ausführt, wird die compute()-Methode aufgerufen. Während der Abarbeitung wird zunächst überprüft, ob der Task direkt zu berechnen ist. Andernfalls ist die Eingabe in neue Tasks aufzuteilen. Alle bis auf einen werden mit fork() in die lokale Task Queue eingeplant, wo sie anderen Threads zum Bearbeiten zur Verfügung stehen. Der verbleibende Task wird durch den Aufruf von compute() ausgeführt (was zu einem weiteren Zerlegen führen kann). Abschließend wartet das Programm mit join() auf die Ergebnisse der abgezweigten Tasks, die es zusammenführt und als Gesamtes zurückgibt.
Die eigentliche "Business-Logik" (die Berechnung der Tags) befindet sich in den Implementierungen von Input<T> und Output<T>, für die auf das GitHub-Repository verwiesen sei.
Benchmark
Aufbau des Benchmarks
Es werden Szenarien mit 2.000.000 Dokumenten betrachtet, von denen jedes mit maximal drei Benutzern und Tags assoziiert ist. Ein Task ist direkt zu berechnen, falls er maximal 10.000 Dokumente umfasst. Andernfalls wird er in zwei neue Tasks mit jeweils der Hälfte der Dokumente zerlegt.
Performance-Ergebnisse des Benchmarks werden im Folgenden durch Speedup-Werte in Abhängigkeit der Anzahl verwendeter Worker Threads dargestellt (siehe Abbildung 2, 3 und 6). Der jeweilige Wert ergibt sich aus der Laufzeit des Benchmarks unter Verwendung des ThreadPoolExecutor beziehungsweise ForkJoinPool, ins Verhältnis gesetzt zur Laufzeit einer sequenziellen Berechnung mit nur einem Thread (ohne einen Pool). Jede dieser Laufzeiten berechnet sich wiederum als Mittelwert aus 20 Läufen desselben Szenarios.
Um den Einfluss des Just-In-Time-Compilers zu minimieren, wurden jedem Benchmark zehn Warm-up-Läufe in derselben JVM vorgeschaltet. Durch das Verwenden einer festen Heap-Größe von 4 GByte ließ sich der Anteil der Garbage Collection an der Gesamtlaufzeit durchweg unter 5 Prozent halten. Alle Benchmarks liefen auf einem Rechner mit 32 virtuellen Prozessoren (in Form von 16 physikalischen Cores plus Hyperthreading).
Betrachtung der Ergebnisse
Wie Abbildung 2 zeigt, können sowohl der ThreadPoolExecutor als auch der ForkJoinPool die Berechnung gegenüber der sequenziellen Variante beschleunigen. Allerdings erzielt der ThreadPoolExecutor bis zur Anzahl verfügbarer Prozessoren durchweg einen höheren Speedup. Genau solche Ergebnisse führen oft zu Verwunderung – denn das Szenario sollte eigentlich gut für Fork/Join geeignet sein.

Die Erklärung für die Ergebnisse ist, dass alle Eingabe-Tasks einen ähnlichen Berechnungsaufwand mit sich bringen. Die rekursive Zerlegung und das Work Stealing des ForkJoinPool sind folglich unnötig. Im Vergleich zum ThreadPoolExecutor bleibt nur der Overhead für die Erstellung zusätzlicher Tasks. Obwohl MapReduce also eine gut geeignete Anwendung für den ForkJoinPool ist, muss das nicht heißen, dass der ForkJoinPool auch immer die beste Lösung ist. Lässt sich ein Problem zuverlässig in gleichgroße Teile partitionieren, ist der ThreadPoolExecutor (oder sogar das explizite Starten und Zusammenführen eigener Threads) oft vorzuziehen.
Man kann sich jedoch nicht unbedingt darauf verlassen, dass die Rechenlast gleichmäßig auf die Eingabe-Tasks verteilt ist. So können zum Beispiel manche Dokumente von mehr Benutzern geteilt werden oder weit mehr Tags besitzen als andere. In einer zweiten Betrachtung des Beispiels soll deshalb ein Viertel aller Dokumente mit bis zu viermal so vielen Benutzern und Tags assoziiert sein.

Wie Abbildung 3 zeigt, erledigt der ForkJoinPool die Berechnung unverändert schnell – der Speedup ist sogar etwas höher, weil die Rechenlast insgesamt gestiegen ist. Der ThreadPoolExecutor hingegen leidet erheblich unter dem Ungleichgewicht. Der Grund hierfür ist, dass der ForkJoinPool durch Work Stealing automatisch für einen Lastausgleich zwischen den Threads sorgt, während der ThreadPoolExecutor keinerlei Mechanismus dafür bereitstellt.
Zum Beleg veranschaulicht Abbildung 4 die Zustände der Worker Threads während der Berechnung der Benchmarks durch den ThreadPoolExecutor mit vier Threads (gemessen mit VisualVM; grün heißt "lauffähig", gelb heißt "wartend"). Ein Thread hat stets den Großteil der Rechenlast alleine zu tragen. Das erklärt, warum der ThreadPoolExecutor bei steigender Anzahl Threads wieder etwas besser abschneidet: Das Ungleichgewicht verteilt sich dann auf mehrere Threads.

im Ruhezustand sind (Abb. 4).
Zum Vergleich zeigt Abbildung 5, dass die Threads beim ForkJoinPool dank des Work-Stealing-Verfahrens wesentlich besser ausgelastet sind. Es lässt sich beobachten, dass zusätzliche Worker Threads gestartet werden, wenn bereits aktive Threads auf die Ergebnisse anderer Tasks warten müssen. Trotzdem sind zu jeder Zeit nur vier Worker Threads tatsächlich lauffähig, die anderen befinden sich im Ruhezustand.

Insgesamt lässt sich festhalten: Der ThreadPoolExecutor ist vorzuziehen, wenn die Rechenlast gleichmäßig auf die Worker Threads verteilt ist. Um das zu garantieren, ist allerdings eine genaue Kenntnis der Eingabedaten nötig. Der ForkJoinPool hingegen zeigt unabhängig von den Eingabedaten eine gute Performance und stellt damit die deutlich robustere Lösung dar.
Actor Scheduling
Szenario 2: Actor Scheduling
Actors ziehen derzeit großes Interesse auf sich, da sie leichtgewichtiger als Threads sind und dank der ausschließlich über Nachrichten laufenden Kommunikation ein robustes Programmiermodell bieten. Hinter den Kulissen verwenden viele Actor-Frameworks jedoch Thread Pools, deren Worker Threads diejenigen Actors ausführen, die Nachrichten in ihrer Mailbox haben. Der ForkJoinPool ist demzufolge besonders für Actor-Frameworks auf der JVM relevant.
Verwendung findet eine kleine Actor-Scheduling-Implementierung, die im Kern ähnliche Mechanismen wie das Akka-Framework [3] nutzt. Es wird an dieser Stelle nur die Definition des Tasks gezeigt, der Rest lässt sich im Code im GitHub-Repository nachvollziehen.
public class ActorForkJoinTask extends RecursiveAction {
private final AbstractDispatcher dispatcher;
private final Mailbox mailbox;
public ActorForkJoinTask(AbstractDispatcher dispatcher,
Mailbox mailbox) {
this.dispatcher = dispatcher;
this.mailbox = mailbox;
}
@Override
protected void compute() {
int counter = 0;
Message message;
while (counter++ < ActorBenchmarkConfig.MAX_CONSUME_BURST
&& (message = mailbox.pollMessage()) != null) {
mailbox.getActor().receive(message);
}
mailbox.setScheduled(false);
if (!mailbox.isEmpty()) {
dispatcher
.scheduleUnlessAlreadyScheduled(mailbox
.getActor().getId());
}
}
}
Der ActorForkJoinTask leitet sich von RecursiveAction ab, da er keinen Rückgabewert benötigt. Bei Ausführung des Tasks werden Nachrichten aus der Mailbox des Actors genommen und dem Actor zur Verarbeitung übergeben. Enthält die Mailbox bei Erreichen einer Obergrenze noch weitere Nachrichten, wird der Actor erneut zur Ausführung vorgemerkt. Der Dispatcher fügt hierzu einen neuen ActorForkJoinTask in die lokale Task Queue des Worker Threads ein.
Die Implementierung des Tasks für den ThreadPoolExecutor ist praktisch identisch, leitet sich aber von Runnable ab. Ist ein Actor auszuführen, plant der Dispatcher einen neuen Task in die zentrale Eingangs-Queue ein.
Sowohl beim ForkJoinPool als auch beim ThreadPoolExecutor achtet der Dispatcher intern darauf, keinen Actor doppelt einzuplanen. So ist gewährleistet, dass niemals zwei Threads gleichzeitig denselben Actor ausführen, und die Implementierung des Actors selbst muss sich nicht um Thread-Synchronisation kümmern.
Betrachtung der Ergebnisse
Der Benchmark an sich ist genauso aufgebaut wie beim MapReduce-Szenario. Im Folgenden werden Ergebnisse aus einem Szenario mit 1000 Actors gezeigt. In den Mailboxen von 200 Actors befindet sich zu Beginn eine Nachricht, von der jede in der Folge 100.000-mal an einen zufällig bestimmten Actor weitergeleitet und zum Schluss gelöscht wird. Während dem Ausführen eines Actors arbeitet dieser immer nur eine Nachricht auf einmal ab.

Abbildung 6 zeigt, dass der ThreadPoolExecutor für dieses Szenario überhaupt nicht geeignet ist. Die gemeinsame Eingangs-Queue führt zu einer erheblichen Menge von Konkurrenzsituationen, was Abbildung 7 durch die Thread-Zustände veranschaulicht.

Der ForkJoinPool hingegen kann die Berechnung dank der lokalen Task Queues bis zur Anzahl der virtuellen Prozessoren beschleunigen. Jeder Worker Thread füllt seine eigene Task Queue fortwährend mit neuen Actor Tasks, sodass es keine Konkurrenzsituationen auf den Queues gibt.
Auffällig ist, dass der Speedup insgesamt eher gering ist, beim ThreadPoolExecutor sogar stets deutlich kleiner als 1 (das heißt die sequenzielle Berechnung ist schneller). Der Grund hierfür ist zum einen die oben beschriebene Anforderung, beim parallelen Scheduling keinen Actor gleichzeitig von mehreren Threads ausführen zu lassen. Das bringt einen spürbaren Synchronisations-Overhead mit sich, der bei der sequenziellen Berechnung nicht anfällt. Zum anderen erzeugen die Actors im beschriebenen Beispiel beim Empfang von Nachrichten kaum Rechenlast (die Nachricht wird lediglich an einen anderen Actor weitergeleitet), sodass es wenig zu parallelisieren gibt.
Was den Durchsatz betrifft, hat der ForkJoinPool beim Actor Scheduling klar die Nase vorn. Allerdings wirft ein solches Szenario auch die Frage nach der Fairness auf. Da ein Worker Thread immer den zuletzt eingefügten Task aus seiner Task Queue nimmt, kann es passieren, dass ein Actor über einen längeren Zeitraum in der Task Queue wartet, während andere Actors wiederholt ausgeführt werden. Für solche Fälle stellt der ForkJoinPool deshalb einen Parameter, asyncMode, zur Verfügung. Wird der gesetzt, arbeitet jeder Worker Thread die lokale Task-Queue in der Reihenfolge der Einplanung ab. Er riskiert damit zwar Konkurrenzsituationen mit anderen Threads, sorgt aber für mehr Gerechtigkeit. In den gezeigten Beispielen ist der Overhead durch den asyncMode relativ gering, sodass er sich zugunsten der Fairness lohnt.
Der asyncMode hilft leider nicht bei neuen Tasks, die von außerhalb eingeplant werden. Solche Tasks können in der Eingangs-Queue "verhungern", wenn die Worker Threads laufend neue Tasks für sich selbst generieren. Nicht zuletzt aufgrund dieses Problems verwenden aktuelle Weiterentwicklungen des ForkJoinPool keine zentrale Eingangs-Queue mehr, sondern verteilen auch die von außerhalb eingeplanten Tasks direkt an die Task Queues der Threads. Den aktuellen Stand der Implementierung kann man von Doug Leas Concurrency JSR-166 Interest Site [4] herunterladen und ausprobieren. Dort finden sich zudem verschiedene Klassen, die nicht in Java 7 aufgenommen wurden oder erst für Java 8 geplant sind.
Fazit
Die wesentliche Neuerung des ForkJoinPool sind die Task Queues der Worker Threads sowie das Work-Stealing-Verfahren. Dadurch eignet sich der ForkJoinPool prinzipiell für alle Szenarien, in denen Tasks bei ihrer Ausführung weitere Tasks einplanen. Der Praxistest hat gezeigt, dass der ForkJoinPool für Szenarien mit Zerlegung (wie zum Beispiel MapReduce) gute Ergebnisse erzielt und robuster als der ThreadPoolExecutor ist. Großes Potenzial hat der ForkJoinPool außerdem in ereignisgesteuerten Szenarien (wie zum Beispiel Actor Scheduling), in denen allerdings auf die Fairness zu achten ist. Aktuelle Weiterentwicklungen des ForkJoinPool enthalten zusätzliche Optimierungen, sodass es spannend sein wird zu beobachten, wohin die Reise geht.
Dr. Patrick Peschlow
ist Experte für die Java Virtual Machine und hat langjährige Erfahrung in der Entwicklung paralleler und verteilter Java-Anwendungen. Er arbeitet als Performance Engineer bei der codecentric AG und ist aktuell an der Realisierung einer hochskalierbaren Cloud-Anwendung beteiligt.
(jul [5])
URL dieses Artikels:
https://www.heise.de/-1755690
Links in diesem Artikel:
[1] http://gee.cs.oswego.edu/dl/papers/fj.pdf
[2] http://github.com/peschlowp/ForkJoin
[3] http://akka.io/
[4] http://g.oswego.edu/dl/concurrency-interest/
[5] mailto:jul@heise.de
Copyright © 2012 Heise Medien