

Data Mesh: Daten verantwortungsvoll dezentralisieren
Mit einer neuen Datenarchitektur und Denkweise soll das Data-Mesh-Paradigma den Weg ebnen, unternehmerischen Mehrwert zu generieren.

(Bild: Scott Prokop / Shutterstock.com)
- Prof. Arif Wider
Noch vor nicht allzu langer Zeit lag Data Mining voll im Trend. Unternehmen konnten buchstäblich nicht genug von Daten bekommen. Bald aber stellte sich die Frage, was man denn mit den ganzen Daten machen sollte. Viele erwarteten, dass aus all diesen ungeordneten Datenbeständen mittels Machine Learning (ML) und Künstlicher Intelligenz (KI) wertvolle Informationen extrahiert werden würden, die die Grundlage informierter Entscheidungen bilden sollten.
Aber es kam ganz anders: Die traditionellen Verfahren zur Gewinnung aussagekräftiger Erkenntnisse aus Big Data ließen Ernüchterung zurück. Die Gründe? Probleme mit der Datenqualität und beim Recruiting von Data Engineers, überlastete Datenplattform-Teams und kostspielige Dateninfrastrukturprojekte, die nicht zum Abschluss kommen wollten.
Die beiden derzeit meistverbreiteten Ansätze für das Datenmanagement basieren entweder auf Data-Warehouse- oder Data-Lake-Technologien. Data Warehouses speichern strukturierte Daten in abfragefähigen Formaten. Ein Data Lake dagegen speichert in seiner einfachsten Ausprägung Rohdaten aus unterschiedlichsten Quellen. Bei diesem Ansatz können die Daten bis zu dem Zeitpunkt, an dem die Analyse beginnen soll, das Schema beibehalten, das durch das Quellsystem vorgegeben wurde. Beiden Datenarchitekturen liegt häufig ein zentralisiertes IT-System mit zentraler Datenverantwortung zugrunde – so führen sie besonders in wachsenden IT-Organisationen schnell zur Silobildung.
Videos by heise
Das Potenzial von Daten voll ausschöpfen
Mit Data Mesh steht Entscheiderinnen und Entscheidern dagegen ein neues Paradigma zur Verfügung, das auf bewährten Software-Engineering-Prinzipien aufbaut. Data Mesh verfolgt einen dezentralen Datenarchitekturansatz. Es wendet Prinzipien an, die aus der modernen Softwareentwicklung stammen, aber in diesem Fall auf Daten angewendet werden, nämlich Domain-driven Design (DDD), produktorientiertes Denken, Self-Service-Infrastrukturplattformen und Federated Governance.
Nach diesen Prinzipien erstellen Unternehmen Datenprodukte im Sinne dezentraler Fachangebote für interne Datenkonsumierende, die sich auf eine Fachdomäne konzentrieren und die die Datenverantwortung und -nutzung aufeinander abstimmen. Diese Datenprodukte kooperieren und bauen aufeinander auf, wodurch ein Netzwerkeffekt entsteht. Aus dem daraus resultierenden Zyklus aus Daten, Analyse und Maßnahmen entwickelt sich kontinuierlich unternehmerischer Mehrwert.
Aufmerksame Beobachter könnten einwenden, dass es längst Datenarchitekturen gibt, die in der Lage sind, Daten zu erfassen und zu analysieren. Warum gelingt es damit nicht bereits, das Potenzial der Daten vollständig auszuschöpfen?

Die Symptome einer Big Data-Dysfunktion
Unternehmen, die Probleme mit der Datenqualität und der datengestützten Wertschöpfung haben, zeichnen sich in der Regel durch eine Reihe gemeinsamer Fehlerfaktoren aus: Zum einen kann ein missglückter Start vorliegen und die ins Auge gefassten Anwendungsfälle für Daten kommen nie in Gang. Möglich ist auch, dass es der Organisation nicht gelingt, mit den Bedürfnissen einer immer größer werdenden Anzahl von Datenkonsumierenden Schritt zu halten. Genauso kann es Probleme beim Skalieren von Quellen geben: Da der Umfang der Daten – und vor allem auch ihre Diversität – innerhalb wie außerhalb des Unternehmens rasant zunimmt, lassen sich die Quellen nicht so schnell integrieren wie sie sich vermehren. Schließlich erweist sich die Wertschöpfung aus den Daten schwierig bis unmöglich, wenn sich Datenproduzierende und Datenkonsumierende nicht abstimmen.
Laut einer Studie von NewVantage Partners tun sich die meisten Unternehmen in Sachen Big Data weiterhin schwer. Der Umfrage zufolge geben nur 24 Prozent der befragten Firmen an, ihr Versuch, eine datengestützte Organisation zu bilden, sei tatsächlich von Erfolg gekrönt gewesen. Ein ähnlich geringer Anteil an Unternehmen bejaht die Aussage, erfolgreich eine Datenkultur in ihrer Organisation etabliert zu haben. Doch der Grund für das flächendeckende Scheitern ist keineswegs technologischer Natur: Über 90 Prozent der Befragten bezeichnen vielmehr Menschen und Prozesse als Ursache dafür, dass die datengestützte Transformation ihrer Organisation nicht gelingen will.
Warum bestehende Architekturen einer Transformation im Wege stehen
Die Schwierigkeiten, auf die Unternehmen bei der Implementierung von Data Warehouses und Data Lakes stoßen, haben ähnliche Ursachen, treten aber an unterschiedlichen Stellen auf.
Der Zweck eines Data Warehouse ist es, einen strukturierten Datenspeicher mit integrierter Rechenleistung bereitzustellen, der alle Anforderungen eines Unternehmens erfüllen soll. Doch je größer ein Unternehmen ist, desto unrealistischer ist die Erfüllung dieses Anspruchs. Abgesehen vielleicht von einfachsten Domänen sind in der Regel mehrere voneinander abgegrenzte Kontexte und die entsprechenden Datenmodelle nötig. Gleichzeitig erschwert der beträchtliche Overhead von Data-Warehouse-Technologien eine effiziente Anpassung an diese Kontexte. Selbst im günstigsten Fall, in dem eine Beschränkung auf ein einziges Datenmodell möglich wäre, leidet häufig die Datenqualität, da eine zentralisierte Qualitätskontrolle nicht mit den dezentral auftretenden Änderungen im Unternehmen Schritt halten kann.
Oft enthalten verschiedene Systeme innerhalb der IT-Organisation die gleichen Daten. Für ein zentrales Data-Team ist es deshalb im Zweifelsfall schwierig festzustellen, welche die beste Datenquelle für eine Analyse ist. Hinzu kommt: Die Analyseszenarien können hinsichtlich der erforderlichen Datenqualität variieren. Beim Data-Warehouse- wie beim Data-Lake-Modell ist die Datenqualität maßgeblich von Handlungen beeinflusst, die stattfinden, lange bevor Nutzerinnen und Nutzer ins Spiel kommen. Die Personen, die für die Datenerzeugung verantwortlich sind, gehören anderen Organisationseinheiten an als die Verwender derselben Daten.
Ein gigantisches Silo – und ein unüberwindlicher Engpass
Data Warehouses wie auch Data Lakes bilden häufig eine Art riesiges Silo, das Petabytes an Daten enthält. Natürlich sollen solche Architekturen den Zugriff auf alle Daten des Unternehmens ermöglichen. Aber anders als bei anderen Silos besteht das Problem hier nicht darin, dass Daten aufgrund technischer Beschränkungen unzugänglich wären; die Herausforderung ist vielmehr eine organisatorische. Die Teams, die diese monolithischen Daten-Repositories betreiben, müssen mit hochgradig spezialisierten Data Engineers besetzt werden.
Allerdings sind qualifizierte Data Engineers schwierig zu finden, und ihre Vergütung ist entsprechend hoch. Daher stellt die Rekrutierung der richtigen Personen für das Erstellen und den Betrieb eines Data Lake eine enorme Hürde dar. Doch selbst wenn ein Unternehmen in der Lage ist, genügend Fachkräfte für Aufbau und Betrieb seines Data Lake zu finden, enden die Probleme damit nicht. Denn diese Data-Fachleute müssen Daten von Personen und Teams aus dem gesamten Unternehmen beziehen. Letztere haben jedoch wenig Anreiz, sicherzustellen, dass sie nur korrekte, vertrauenswürdige und aussagekräftige Daten weitergeben.
Sind die Daten einmal erfasst, hat das Data-Engineering-Team die wenig beneidenswerte Aufgabe, sie für den Rest des Unternehmens nutzbar zu machen. Und zwar ohne jegliches Fachwissen zur jeweiligen Domäne und ohne Unterstützung durch eine immer größer werdende Anzahl von Datenkonsumierenden.
Ein Paradigmenwechsel, der nicht auf Technologie beschränkt ist
Um in der beschriebenen Situation Abhilfe zu schaffen, müssen Entscheiderinnen und Entscheider sich von den derzeitigen technologieorientierten Denkmustern lösen. Andernfalls bliebe die inhärente Trennung zwischen Datenproduzierenden und -konsumierenden ebenso bestehen wie das gigantische Silo, der Personalengpass und die damit einhergehenden Fehlermöglichkeiten.

Anstatt Daten weiterhin als Nebenprodukt anderer geschäftlicher Funktionen zu betrachten, ist es Zeit anzuerkennen, dass Daten schon lange ein eigenständiges Produkt sind. Dieser neue Blickwinkel ist nötig, damit Entscheiderinnen und Entscheider sich von monolithischen Systemen und linearen Pipelines lösen können. Spezifische Teams verantworten nunmehr die Daten. Ein solches Verständnis vermittelt nicht nur, wie die unterstützende Architektur, sondern auch die Organisation selbst zu strukturieren sind.
Die meisten Data Scientists verbringen mindestens 80 Prozent ihrer Zeit mit dem Erfassen und Extrahieren von Daten. Doch was wäre, wenn geschäftliche Aktivitäten von Grund auf datenorientiert gestaltet wären? Und wenn dieselben Data Scientists während des gesamten Lebenszyklus der Daten voll involviert wären?
Übergang zu domänenorientierten Datenprodukten
Indem Unternehmen ihre Daten anstelle eines Monolithen nach Domänen organisieren, können sie ihre Domänen-Expertise mit den technischen Fähigkeiten kombinieren, und so einen unternehmerischen Mehrwert generieren. Unter dem Kriterium der Domäne lassen sich Daten zu einem Portfolio diskreter Produkte bündeln. Jedes erfolgreiche Produkt muss seine Kunden begeistern, in diesem Fall die breitere Organisation: Data-Teams und alle anderen, die damit arbeiten müssen.

Wie aber gelingt es, Produkte zu erschaffen, die begeistern? Ganz einfach: Indem die Fülle an Wissen einfließt, die das Produktdenken bietet. Wenn Unternehmen außerdem verteilte Data-Teams mit entsprechendem Fachwissen ins Leben rufen, entfällt ein Großteil der bei Extraktion, Bereinigung und Analyse der Daten sonst üblichen Reibungsverluste.
Wie man den erfolgreichen Umgang mit Daten skaliert
Damit solch ein dezentraler und domänenorientierter Ansatz Erfolg haben kann, müssen Datenprodukte auffindbar, adressierbar, interoperabel, selbsterklärend, vertrauenswürdig und sicher sein. Sind alle diese Eigenschaften gegeben, lässt sich das Modell skalieren.
Der wichtigste Gradmesser für den Erfolg eines Datenprodukts ist die Zufriedenheit der Datenkonsumierenden. Dann kann es auch sinnvoll sein, den Erfolg des Produkts klar und messbar zu definieren. Ein naheliegender Leistungsindikator wäre zum Beispiel die Vorlaufzeit, die ein an Daten interessiertes Team benötigt, um die relevanten Daten zu finden und zu nutzen.
Durch Verknüpfung interoperabler Daten einen intelligenten Datenkreislauf entwickeln
Eines der zentralen Merkmale des Data Mesh ist sein Federated-Governance-Modell, das Interoperabilität durch Standards erreicht. Nur mit interoperablen Daten können Analysen unter Einbeziehung mehrerer Datenprodukte zu nützlichen Erkenntnissen und Handlungen führen. Sie jedoch beeinflussen bereits die nächste Datenverwendung. So entsteht ein zusammenhängender intelligenter Datenkreislauf.

Umstellung auf eine dezentrale Datenverantwortung
Unabdingbar ist darüber hinaus, dass sich die Datenproduzierenden für ihre eigenen Daten verantwortlich fühlen. Auch sind Entscheidungen darüber zu treffen, welche Daten zu speichern sind. Denn Daten zu extrahieren und zu transformieren, die niemand je nutzt, verursacht unnötige Kosten. Nach der Entscheidung, welche Daten den Stakeholdern zugänglich sein sollen, obliegt fachlichen Teams die Verantwortung, sie zu pflegen und zu analysieren. Der Datenqualität fällt damit die Rolle eines Vertrags zu zwischen Datenkonsumierenden und -produzierenden.
In der Umstellung von zentraler Datenverantwortung auf ein dezentrales Modell kann auch eine Lösung für den Engpass im Bereich Data Engineering liegen. Allerdings ist diese Lösung im Wesentlichen eine organisatorische. Während es vorher vielleicht niemanden gegeben hatte, der die uneingeschränkte Verantwortung für die Domänendaten trägt, sind die neuen Datenprodukte quellenbezogen und die Verantwortung verbleibt nun für den gesamten Lebenszyklus des Datenprodukts bei der Domäne.
Und wie sieht es mit bestehenden Infrastrukturen aus?
Bei der Evaluierung des Data-Mesh-Konzepts könnten Entscheiderinnen und Entscheider befürchten, dass etwaige kürzlich getätigte Investitionen – beispielsweise in einen Data Lake – sich als überflüssig erweisen, oder dass in einem verteilten System jedes Datenprodukt seine eigene separate Infrastruktur benötigen würde.
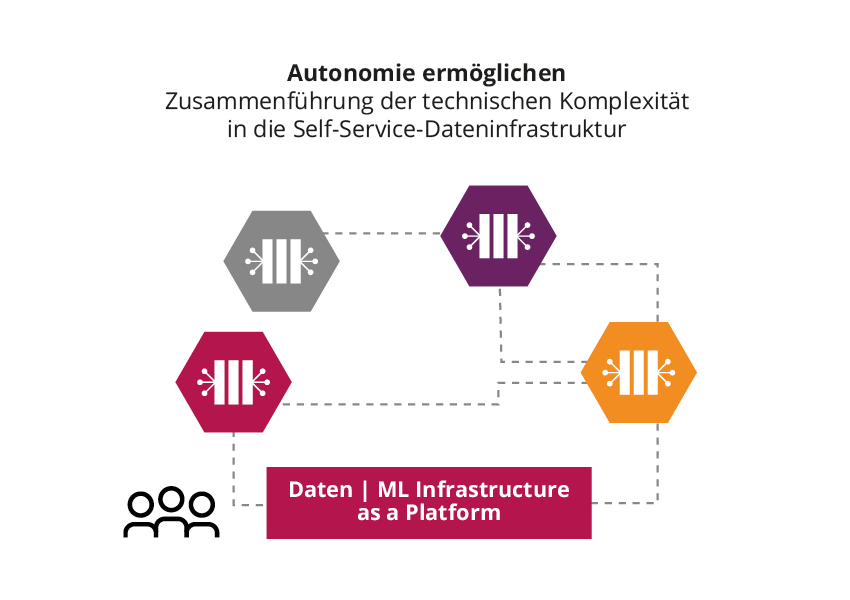
Data Mesh löst diese Probleme, indem es die Dateninfrastruktur als Plattform anbietet. So muss nicht jedes Domänen-Team seine eigene Datenplattform entwickeln, die notwendige Infrastruktur steht in Form einer Self-Service-Plattform bereit. Den Teams gibt das ein hohes Maß an Autonomie und es ermöglicht gleichzeitig die Integration zentraler Assets wie eines bestehenden Datenkatalogs.
Implementierung und organisatorischer Wandel
Im Data Mesh sollten Datenproduzierende und -konsumierende so eng wie möglich zusammenarbeiten. Im organisatorischen Idealfall verwendet ein datenproduzierendes Team die Daten selbst, ist also auch Konsument, sodass Datenverantwortung und Kompetenz vereint sind. Oftmals jedoch erfordern die vielen Aufgaben datenproduzierender Teams eine Aufteilung der Rollen auf zwei Teams – Produzierende und Konsumierende –, die fortlaufend direkt miteinander kommunizieren.
Es ist also nicht nur der Technologie-Stack, der sich ändern muss, auch Zuständigkeiten und Strukturen müssen sich verschieben. Dieser Wandlungsprozess erfordert die Zustimmung der obersten Führungsebenen im Unternehmen. Durch eine Implementierung in kleinen Schritten lässt sich der Wandel inkrementell umsetzen. In der Übergangsphase – also vor Fertigstellen einer Infrastructure-as-a-Service-Plattform (IaaS) – bilden sich Teams um Domänen herum, die bei Bedarf ein Data Warehouse oder einen Data Lake als Zwischenquelle nutzen.
Zwar erfordert die Erstellung der IaaS-Plattform die gleichen Data-Engineering-Fähigkeiten, die häufig zum Engpass in einer Data-Warehouse- oder Data-Lake-Architektur führen. Jedoch sind Domänenwissen und Infrastruktur voneinander entkoppelt, sobald die Plattform etabliert ist. Zentrale Data-Teams müssen sich nachfolgend nicht mehr mit dem Domänenwissen auseinandersetzen, um ihre Arbeit zu erledigen. Das reduziert den Druck, der beim Betrieb monolithischer Systeme entsteht.
Fazit: Das Data Mesh eröffnet neue Perspektiven
Die Implementierung traditioneller Ansätze für das Datenmanagement fühlt sich häufig so an, als gelte es fortlaufend neue Brandherde zu löschen: Qualitätsprobleme sollen mit mehr Qualitätskontrolle gelöst, Engpässe der Datenplattform mit mehr Data-Teams beseitigt und die Zunahme der Datenquellen mit einer leistungsfähigeren Infrastruktur in den Griff bekommen werden. Die Besonderheit des Data Mesh liegt darin, dass es eine neue Perspektive auf das Problem ermöglicht. Ein Data Mesh funktioniert umso besser, je mehr Datenquellen und Datenkonsumierende es gibt. Ein sauber aufgesetztes Data Mesh schafft keine zusätzlichen Probleme, sondern bringt umso mehr geschäftliche Erkenntnisse ans Licht, je stärker die Zusammenarbeit rund um die Daten intensiviert wird.
Die Implementierung einer neuen Datenarchitektur kann beim Wachstum eines Unternehmens einen Wendepunkt markieren. Bisher schränkte jedoch die Herangehensweise an Big Data als rein technologisches Problem den Mehrwert deutlich ein. Dabei hängt der Erfolg vielmehr von einer Anpassung der Organisationsstruktur ab, die die Anreize für Datenproduzierende mit denen der Datenkonsumierenden in Einklang bringt.
Durch produktorientiertes Denken erhalten Unternehmen alle Tools, die sie brauchen, um überzeugende Datenprodukte herzustellen, mit denen sich das wahre Potenzial von Big Data erschließen lässt. Für die Implementierung des Data Mesh ist keine Big-Bang-Migration erforderlich. Auch muss man den vorhandenen Data Lake nicht sofort trockenlegen. Die Einführung kann vielmehr in kleinen Schritten erfolgen, die aufeinander aufbauen und deren gewonnene Erkenntnisse zum jeweils nächsten Schritt beitragen.
Prof. Dr. Arif Wider arbeitet als Fellow Technology Consultant bei ThoughtWorks Deutschland, wo er als Head of Data & AI tätig war, bevor er wieder in die Wissenschaft zurückkehrte. Er ist außerdem Software-Engineering-Professor an der HTW Berlin.
(map)