Data Science stellt sich in den Dienst der Mathematik

(Bild: Phonlamai Photo/Shutterstock.com)
Früher mussten Mathematiker aus komplexen Berechnungen mühsam Muster erkennen. Heutige Technik kann das viel schneller.
Bisher leistete Mathematik einen enormen Beitrag für Data Science, Machine Learning und das gesamte KI-Gebiet. Nun hat sich der Spieß teilweise umgedreht: Mathematik ist nicht mehr nur ein Mittel zum Zweck von Data Science, sondern Data Science stellt sich in den Dienst der Mathematik, und das gleich in drei Bereichen:
- Die topologische Datenanalyse geht der Frage nach, welches Wissen aus einer Stichprobe von Datenpunkten über die geometrische Form erlernbar ist.
- Die Codierungs- und Zahlentheorie hilft dabei, bestimmte zahlentheoretische Problemstellungen näher zu beleuchten, Zusammenhänge aufzudecken oder Hinweise für Beweise von Vermutungen – also unbewiesene mathematische Sätze – zu finden.
- Das symbolische Rechnen schließlich befasst sich mit dem Verstehen und Verändern von Formeln. ML ist mittlerweile in der Lage, selbst umfangreichere und komplexere mathematische Aufgaben zu lösen, beispielsweise symbolische Integration oder Differenzialgleichungen.
Data Science lässt sich praktisch für die Untersuchung von Zusammenhängen in der Codierungs- und Zahlentheorie einsetzen – Bereich Nummer zwei. Dieser Artikel demonstriert das explorative und programmatische Vorgehen mit Python und weist auf versteckte Fallstricke hin.
Explorative Datenanalyse
Im Rahmen von Data Science analysiert man die Daten üblicherweise explorativ, das heißt in einem stufenweisen Prozess: Man zieht Schlüsse aus den Ergebnissen, die dann wiederum zu neuen Analysen führen. So arbeitet man sich schrittweise zu einem Ergebnis vor. Als Skriptsprache ist Python sehr gut für diese Arbeitsweise geeignet [1].
Ein exploratives Arbeiten erfordert Werkzeuge, die sowohl das Erstellen und Ausführen der Python-Skripte als auch die Darstellung der Daten als Textausgaben und Grafiken ermöglichen. Hier haben sich Jupyter-Notebooks etabliert. Sie bieten eine Weboberfläche, in der man sowohl programmieren als auch Analyseergebnisse darstellen kann. Darüber hinaus sind für Python professionelle IDEs wie Visual Studio Code [2] und PyCharm verfügbar.
Einen Einblick, wie Data Science in den wissenschaftlich mathematisch geprägten Alltag eingebracht werden kann, bietet der Infokasten Bäume als Beispiel aus dem heutigen Forschungsalltag.
Bei den sogenannten Goal-Means-Bäumen, Entscheidungsbäumen und hierarchischen Organigrammen haben die explorative Datenanalyse und Visualisierungstechniken zu der überraschenden Einsicht geführt, dass sie um unerwünschte Nebeneffekte, unsichere Varianten und informelle Netzwerke ergänzt werden müssen.
In der Mathematik stellt man sich Bäume üblicherweise als eine Menge G=(V,E) von Knoten V und deren Kanten E vor, mit der Besonderheit, dass jedes Knotenpaar nur durch einen Pfad verbunden ist und alle Pfade nur einen Knoten gemeinsam haben: die Wurzel. Der Mathematiker Lothar Collatz kombinierte die Zahlen- mit der Graphentheorie und konstruierte einen Baum: Er hat einen mit einer natürlichen Zahl n beschrifteten Knoten mit einem weiteren Knoten n/2 verbunden – falls n gerade ist, anderenfalls mit einem Knoten 3n+1 – und dieses Spiel beliebig fortgesetzt.
Die Collatz-Vermutung besagt, dass – egal mit welcher Zahl n ein Knoten beschriftet ist – von diesem ein Pfad zum Wurzelknoten führt, der mit 1 beschriftet ist. Mit ML und Data Science konnten Mathematiker Bäume mit exorbitant hohen Zahlen aufbauen und ein Muster feststellen: Der Collatz-Baum weist die Struktur von Hilberts Hotels auf und hat dies dem Skolem-Noether-Theorem zu verdanken.
Mithilfe von Mathematica, einem Programmpaket zum symbolischen Rechnen, kann man zeigen, dass die asymptotische Dichte im Collatz-Baum dadurch bestimmt ist, dass jede weitere Iteration der beiden inversen Collatz-Funktionen (n -> 2n, n -> (n-1)/3 eine höhere Periodizität aufzeigt. Unter Beibehaltung der Verzweigungen erzeugt man einen Binärbaum, der keine Knoten besitzt, die mit durch 2 und 3 teilbaren Zahlen beschriftet sind. Das iterative Beschneiden dieses Binärbaums kann man sich wie das Hilberts-Hotel-Paradoxon vorstellen. Dabei geht es darum, dass ein Hotel mit unendlich vielen Zimmern unendlich viele Gäste aufnehmen möchte. Die Zimmer des Hotels sind immer wieder von Nachkommen aus einer noch höheren inversen Collatz-Iteration belegt. Mit einem Python-Programm lässt sich bestätigen, dass dieses Prinzip auch bei exorbitant hohen Zahlen in der tausendsten Iteration funktioniert. Die zugehörige Bibliothek findet sich auf GitHub [3].
Der Linguistik-Professor Noam Chomsky stellte fest, dass alle Sätze in jeder Sprache eine gemeinsame grammatikalische Baumstruktur haben. Dank überwachten Lernens mit CoreNLP, Spacy oder UDpipe können Baumbanken (Textkorpusse) mit universellen Abhängigkeiten zur Identifikation von Satzstrukturen aus Nachrichten in unterschiedlichen Sprachen verwendet werden. Wandelt man die Bäume in ein semantisch-politisches Netz um, lassen sich überraschend sinnvolle Folgefragen generieren, an die Journalisten noch nicht gedacht haben. Diese datenwissenschaftliche Erforschung syntaktischer Baum-Analysen wird derzeit zur Extraktion semantischer Beziehungen aus niederländischen Zeitungsartikeln verwendet. Erste Ergebnisse liefert dieser Bericht [4].
Funktionale und mengenorientierte Programmierung
Anders als bei der Programmierung klassischer Apps steht bei Data-Science-Anwendungen nicht die zeilenweise, sondern die spaltenweise Verarbeitung von Daten im Vordergrund. Weit verbreitet sind mengenorientierte und datennahe Sprachen wie SQL und R. Auch funktionale Programmierung, die es erlaubt, eine Funktion auf eine Menge von Datensätzen anzuwenden, ist im Data-Science-Bereich von großem Nutzen. Diese Art der Programmierung spart das wiederholte Umsetzen von Schleifen im Code. Python bietet von sich aus nur funktionale Elemente. Erweiterungen wie NumPy und Pandas führen jedoch auch mengenorientierte Features in die Sprache ein. Diese Kombination ist eines der Erfolgsgeheimnisse von Python.
Zudem erlaubt Python die Verarbeitung beliebig großer Ganzzahlen – und dies in relativ großer Menge. Die einzige Einschränkung für die Größe von Integer-Zahlen ist die zugrundeliegende Hardware. Softwaretechnisch liegen keine Limitationen vor. Für codierungs- und zahlentheoretische Fragestellungen ist das von großem Vorteil, da manche Phänomene erst bei sehr großen Zahlen beobachtbar sind. Hiervon profitieren Forschungsfelder rund um Teilbarkeiten, Primzahlen, Primzahlpotenzen und Elliptische Kurven.
Warum Python?
Trotz ihrer Mengenorientierung ist Python nicht, wie beispielsweise SQL, stark von der zugrundeliegenden Hardware getrennt. Dies macht Python neben dem Einsatz im Data-Science-Umfeld zu einer beliebten Sprache für Hacker [6]. Python ist im Gegensatz zu Java skriptfähig und erlaubt daher ein exploratives Vorgehen. Gleichzeitig bietet die Sprache Zugriff auf Low-Level-APIs der ausführenden Maschinen. Standardmäßig wird die Variante CPython eingesetzt, die in C implementiert ist.
Um Python skriptfähig zu halten, wird der Code nicht nach C übersetzt, sondern interpretiert. Der Zugriff auf die Sprache C ist durch Python allerdings jederzeit möglich. Darüber hinaus steht das Framework Cython zur Verfügung, mit dessen Hilfe einzelne in C entwickelte Code-Fragmente in Python integriert werden können. Cython fügt somit Erweiterungen zur Sprache hinzu und erlaubt das Kompilieren und Nutzen von selbst erstelltem C-Code. Darüber hinaus ermöglichen Frameworks wie TensorFlow und PyTorch das Trainieren von Machine Learning Modellen mit sogenannten Graphics Processing Units (kurz: GPUs). Im Gegensatz zu CPUs ermöglichen sie eine hochgradig parallele Datenverarbeitung. Insgesamt bietet die Hardwarenähe von Python Möglichkeiten zur Umsetzung sehr performanter Algorithmen.
Für Python stehen unzählige kostenlose Pakete und Bibliotheken zur Verfügung, die für wissenschaftliche Zwecke entwickelt und optimiert sind. Zu den Einsatzgebieten zählen Statistik, geometrische Datenverarbeitung, Visualisierungen, Analysis, Algebra, maschinelles Lernen und Quantencomputing. Programmierer können Module über die zentralen Repositories, PyPI und Conda bequem herunterladen und verwalten. Beispiele beliebter Bibliotheken sind Pandas, NumPy, TensorFlow, Scikit-learn, SimPy und Cirq.
Genauigkeitsverlust beim Rechnen mit großen Zahlen
Beim Einsatz von Python in der mathematischen Forschung gibt es einige Fallstricke, die man vermeiden sollte. So ist es bei der Verarbeitung großer Ganzzahlen notwendig, durchgängig den Datentyp int zu verwenden. Sobald eine Zahl in den Datentyp float konvertiert wird, geht die unbegrenzte Genauigkeit verloren und die Ergebnisse können sich verfälschen. Führt man beispielsweise eine Division mit nur einem Schrägstrich durch (siehe Listing 1), findet eine implizite Typkonvertierung in eine Fließkommazahl statt. Hierbei kommt es zum Genauigkeitsverlust. Richtig ist die Anwendung einer ganzzahligen Division mit zwei Schrägstrichen. Der passende Code dafür findet sich auf GitHub [7].
# Falscher Divisor verwendet
valid = 5**205 == (5**205 / 5) * 5
print("Division (Falsch):", valid)
# Richtiger Divisor verwendet
valid = 5**205 == (5**205 // 5) * 5
print("Division (Richtig):", valid) Listing 1: Ganzzahlige Division
Der gleiche Effekt tritt auf, sobald Fließkommazahlen in Berechnungen einfließen (siehe Listing 2). Auch hier findet im Ergebnis eine Typkonvertierung mit Genauigkeitsverlust statt. Der Programmierer kann dies umgehen, indem er darauf achtet, nur Ganzzahlen (ohne Komma) in Berechnungen einzubeziehen.
# Falsch: Berechnung mit float
valid = 5**205 + 1 == 5**205 + 1.0
print("Weitere Berechnungen (Falsch):", valid)
# Richtig: Berechnung mit int
valid = 5**205 + 1 == 5 ** 205 + 1
print("Weitere Berechnungen (Richtig):", valid)Listing 2: Berechnungen mit Typkonvertierung
Verarbeitung großer Ganzzahlen in Pandas
Auch das beliebte Framework Pandas erlaubt den Umgang und Berechnungen mit beliebig großen Ganzzahlen. Hierbei ist aber auch die Wahl des korrekten Datentyps wichtig. Im Gegensatz zu Pythons Datentyp int ist Pandas Datentyp int64 in seiner Größe begrenzt. Somit muss ein Programmierer verhindern, dass Python-Ganzzahlen in das Pendant von Pandas konvertiert werden.
Falsch ist beispielsweise die Berechnung großer Zahlen direkt in einem Series- oder DataFrame-Objekt wie in Listing 3. Richtig dagegen ist die Erzeugung großer Zahlen außerhalb des Pandas-Frameworks. Berechnet man Zahlen extern, werden sie bei der Erzeugung der Series oder des DataFrames im Datentyp object gespeichert. Die Genauigkeit bleibt in diesem Fall erhalten. Alternativ können Entwickler aber auch Zahlen mithilfe einer Lambda-Funktion im DataFrame berechnen (siehe Listing 4).
# Imports
import pandas as pd
# Falsch: Berechnung in Pandas
my_numbers = pd.Series([5, 6])
my_exponents = pd.Series([205, 206])
my_powers = my_numbers ** my_exponents
valid = list(my_powers) == [5**205, 6**206]
print("Berechnung in Pandas (Falsch):", valid)
print("Datatype:", my_powers.dtype)
# Richtig: Externe Berechnung
my_powers = pd.Series([5**205, 6**206])
valid = list(my_powers) == [5**205, 6**206]
print("Berechnung in Pandas (Alternative 1):",valid)
print("Datatype:", my_powers.dtype)Listing 3: Verarbeitung großer Zahlen in Pandas
# Richtig: Berechnung mit Lambda-Funktion
my_numbers = pd.Series([5, 6])
my_exponents = pd.Series([205, 206])
my_frame = pd.DataFrame({
"number": my_numbers, "exponent": my_exponents})
my_frame["power"] = my_frame.apply(
lambda x: int(x["number"]) ** int(x["exponent"]), axis=1)
valid = list(my_frame["power"]) == [5**205, 6**206]
print("Berechnung in Pandas (Alternative 2):", valid)
print("Datatype:", my_frame["power"].dtype) Listing 4: Nutzung einer Lambda-Funktion in Pandas
Verarbeitung vieler Zahlen in Pandas
Pandas DataFrames können mit relativ vielen Zahlen umgehen. Will man eine effiziente Verarbeitung erreichen, gilt es, Fallstricke zu vermeiden. So ist es beispielsweise nachteilig, iterativ einzelne Zahlen in einen DataFrame einzufügen (siehe Listing 5). Pandas aktualisiert bei diesem Vorgehen in jeder Iteration zahlreiche Attribute des Frames. Dies führt zum exponentiellen Anstieg der Verarbeitungszeit: Mit jeder Schleife wird das Programm langsamer. Das umgeht man durch ein iteratives Einfügen der Zahlen in eine Python-Liste, die man zum Schluss beim Erzeugen eines DataFrames als Ganzes übergibt (siehe Listing 5). Dieses Vorgehen benötigt einen Bruchteil der Verarbeitungszeit.
#Imports
import time
import pandas as pd
# Falsch: Iteratives Einf�gen
print("Einfuegen (Falsch) Start:", time.asctime())
my_numbers = pd.DataFrame({
"number": []
})
for i in range(10000):
my_numbers = my_numbers.append(pd.DataFrame({"number": [i]}), ignore_index=True)
my_numbers.reset_index(drop=True)
print("Einfuegen (Falsch) Ende:", time.asctime())
print(my_numbers.head())
# Richtig: Einf�gen als Liste
print("Einfuegen (Richtig) Start:", time.asctime())
my_list = []
for i in range(10000):
my_list.append(i)
my_numbers = pd.DataFrame({
"number": my_list
})
print("Einfuegen (Richtig) Ende:", time.asctime())
print(my_numbers.head())Listing 5: Viele Zahlen mit Pandas DataFrames verarbeiten
Über die Rotation von Binärzahlen
Data Science kann schneller und effizienter Ergebnisse für die Mathematik und die Kryptografie liefern als man es mit Bleistift und Papier schaffen würde. Im Folgenden dient als Beispiel die Rotation von Binärzahlen.
Auf einer Binärzahl B der Länge l mit dem Hamming-Gewicht U wird eine Linksrotation ausgeführt. Dadurch lässt sich eine minimale Binärzahl Bmin und maximale Binärzahl Bmax ermitteln. Als Beispiel dient die Binärzahl B = 10110101 = 181. Das Minimum davon ist Bmin = 01011011 = 91 und das Maximum Bmax = 11011010 = 218.
Das Maximum Bmax erreicht man durch drei Linksrotationen des Minimums Bmin. Die Zahl 3 steht hierbei für die Linksrotations-Distanz (Formelzeichen r) zwischen dem Minimum und Maximum. Grundsätzlich gilt also: Bmin = (Bmin*2r)mod(2l - 1).
Für dieses Beispiel [8] bedeutet das 218 = (91 * 23)mod(255). Eine wichtige Eigenschaft ist die Teilbarkeit der Formel:

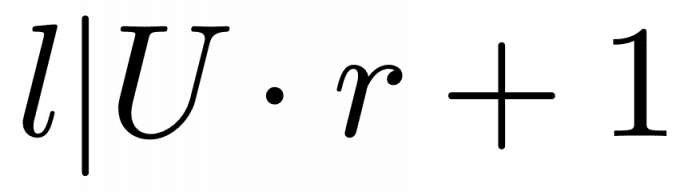
Sobald die Teilbarkeit gegeben ist, kann man periodische Sequenzen generieren. In diesem Fall ist es korrekt. Denn die Länge 8 der Binärzahl B teilt das Hamminggewicht 5 * Rotationsdistanz 3 + 1.
Diese Teilbarkeit stimmt auch für andere Fälle. Weitere Zusammenhänge kann man mithilfe von Data Science identifizieren, untersuchen und visualisieren. So dient als Ausgangspunkt für das vorliegende Problem folgende Funktion, die eine Binärzahl B mit einem Hamming-Gewicht U als Input bekommt.
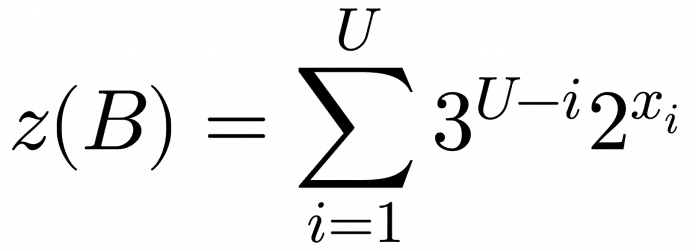
In der nachstehenden Ungleichung sind die x-Werte die mit 1 belegten Positionen der Binärzahl B:

In diesem Beispiel bedeutet das also z(Bmax)= z(11011010) = 319. Für die fünf mit 1 belegten Positionen gilt (x1, x2, x3, x4, x5) = (0,1,2,3,4,6). Korrekt heißt das also 319 = 34 * 20 + 33 * 21 + 32 * 23 + 31 * 24 +30 * 26.
Auf gleiche Weise erhält man z(Bmin)=842. Beide Zahlen, die 319 und die 842, gehören der periodischen Sequenz 3n + 13 an, die durch folgende Funktion gegeben ist:
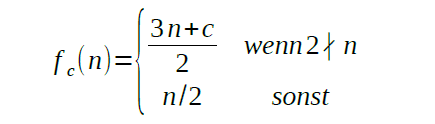
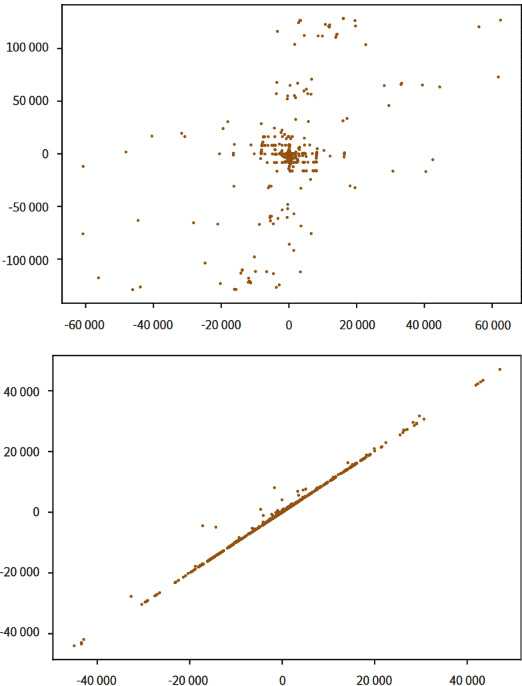
Der Parameter c ergibt sich aus der Differenz c=2l-3U und beträgt in diesem Beispiel 13. Die periodische Sequenz lautet 319, 458, 734, 367, 557, 824, 421, 638. So scheint die zu untersuchende Teilbarkeit immer für solche periodischen Sequenzen gegeben zu sein. Solche Sequenzen lassen sich in Python schnell als Pandas Dataframe erzeugen (siehe Abbildung 1).
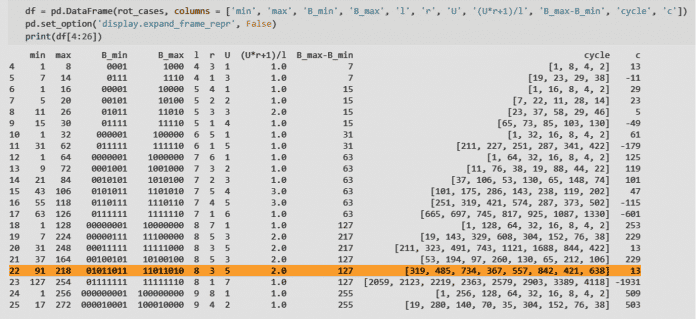
Den Differenzquotienten berechnet man mit DataFrame.diff(). Die Funktion diff berechnet die Differenz eines DataFrame-Elements im Vergleich zum Element in der vorherigen Zeile des DataFrames. Im vorliegenden Fall nutzt man diese Funktion, um die Differenzen aufeinanderfolgender Bmin-Werte (ΔBmin) und aufeinanderfolgender Bmax-Werte (ΔBmax) zu ermitteln. Ordnet man nun dem ΔBmin das entsprechende ΔBmax einer jeden Zeile des DataFrames zu, entstehen zwei Diagramme (siehe Abbildung 2). Auf der linken Seite sind die Daten sortiert nach der Rotationsdistanz r und auf der rechten Seite nach der Differenz Bmax - Bmin.
Quadratzahlen und elliptische Kurven
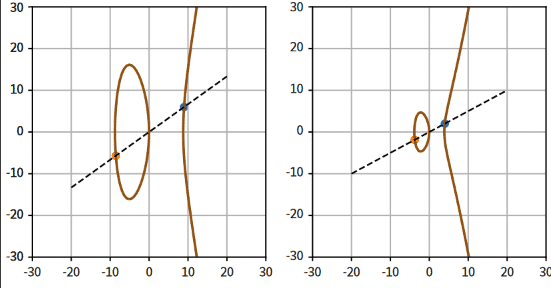
Ein weiteres Beispiel arbeitet mit elliptischen Kurven, die sich durch die Gleichung y2 = x3 + ax + b beschreiben lassen. Elliptische Kurven kommen in der Public-Key-Kryptografie zum Einsatz, da sie die Implementierung asymmetrischer Krypto-Verfahren ermöglichen. Mathematiker stellen sich hierbei die Frage, ob eine Kurve rationale oder gar natürliche Punkte besitzt und ob man anhand der Koeffizienten a und b Aussagen über die Existenz solcher Punkte treffen kann. Auch in diesem Fall kann Data Science helfen. Dafür sind mehrere Rechenschritte notwendig. Ein wichtiger Teil dabei ist das Prüfen, ob eine Zahl eine Quadratzahl ist. Der naheliegende Test wie im oberen Teil von Listing 6 liefert dabei nicht immer korrekte Resultate.
Für die Variablen p=7 und q=11 auf der Kurve y2 = x3 + 77x funktioniert die Implementierung, allerdings nicht für die Variablen p=3 und q=5 auf der Kurve y2 = x3 + 15x. In diesem Beispiel ermittelt die zweite Kurve eine Quadratzahl, die aber keine ist. Das hängt mit dem oben beschriebenen Genauigkeitsverlust zusammen. Die korrekte Implementierung weist keinen Genauigkeitsverlust auf und liefert keine falschen Ergebnisse (siehe Listing 6).
# Falsche Pr�fung:
def find_rational_point(p, q, max_iter):
for a in range(max_iter):
D=a**4/4+p*q
sqrtD = math.sqrt(D)
if sqrtD.is_integer():
�
return None
# Richtige Pr�fung:
def find_rational_point2(p, q, max_iter):
for a in range(max_iter):
D=a**4+4*p*q
sqrtD = math.isqrt(D)
if sqrtD*sqrtD == D:
�
return NoneListing 6: Prüfung, ob eine Zahl eine Quadratzahl ist
Die Python-Bibliothek matplotlib ermöglicht es, Kurven zu visualisieren:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2, figsize=(8,4), dpi=100)Das Gitter für den Plot erzeugt man mit:
y, x = np.ogrid[-30:30:100j, -30:30:100j]
ax[0].contour(x.ravel(), y.ravel(), y**2 - ec_1(x), [0])
ax[0].grid()Das Einzeichnen der zwei Punkte erledigen zwei Anweisungen: Zunächst definiert man die Punkte P[9,6] und Q[-77/9,-154/27] und fügt sie anschließend dem Plot an per ax[0].scatter(*P) und ax[0].scatter(*Q) (siehe Abbildung 3).
Fazit
Die Beispiele im Artikel zeigen, dass Data Science einen wichtigen Beitrag zur mathematischen Forschung leisten kann. Python ist als Skriptsprache mit funktionalen und mengenorientierten Elementen hierfür erste Wahl – auch wenn man bei der Programmierung einige Stolpersteine vermeiden muss.
Wird der Fortschritt an dieser Stelle enden? Nein. Mit Deep Learning und Quantencomputing steht bereits der nächste Entwicklungsschritt bevor. Ziel dieser kommenden Etappe ist es, mathematische Beweise direkt durch eine künstliche Intelligenz zu erstellen. KI wäre dann keine Unterstützung für Mathematiker mehr, sondern würde selbst als solcher fungieren. Schien die Entwicklung vor einigen Jahren noch utopisch, zeigen sich heute erste Systeme dieser Art, unter anderem bei Google. Das Thema bleibt also spannend. Wer sich für die neuesten Frameworks aus diesem Bereich interessiert, kann einen Blick auf TensorFlow Quantum und Cirq werfen.
Eldar Sultanow
ist Architekt bei Capgemini. Seine Schwerpunkte sind moderne Softwarearchitekturen, Data Science und Unternehmensarchitekturmanagement.
Christian Koch
ist Datenarchitekt bei der TeamBank AG und Dozent an der Technischen Hochschule Nürnberg Georg Simon Ohm. Seine Spezialgebiete umfassen Datenarchitekturen, Data Science und Machine Learning.
(mdo [9])
URL dieses Artikels:
https://www.heise.de/-6161436
Links in diesem Artikel:
[1] https://www.heise.de/news/Python-Studie-Die-meisten-Entwickler-nutzen-Python-zur-Datenanalyse-4717269.html
[2] https://www.heise.de/news/Visual-Studio-Code-jetzt-mit-Data-Science-Features-fuer-Python-4217563.html
[3] https://github.com/c4ristian/collatz
[4] https://rdrr.io/cran/rsyntax/
[5] https://arxiv.org/abs/2008.13643
[6] https://www.heise.de/news/Python-Jubilaeum-30-Jahre-und-kein-bisschen-leise-5062143.html
[7] https://github.com/c4ristian/collatz/blob/master/misc/pitfalls.py
[8] https://www.slideshare.net/Sultanow/data-science-for-number-and-coding-theory-246114021
[9] mailto:mdo@ix.de
Copyright © 2021 Heise Medien