Eine Einführung in die Azure Cosmos DB

Nicht immer eignen sich relationale Datenbanken zum dauerhaften Speichern von Daten. In den letzten Jahren sind verstärkt nichtrelationale Alternativen in den Fokus der (Enterprise-Anwendungs-)Entwicklung gerückt, darunter dokumentenbasierte Datenbanken, Key-Value-Stores und Graphdatenbanken.
Die Azure Cosmos DB ist ein noch junges NoSQL-Datenbankangebot in der Azure Cloud. Sie ist seit Mai 2017 als Service verfügbar und löst die seit 2014 von Microsoft bereitgestellte Azure DocumentDB ab. Sie erweitert deren Funktionsumfang deutlich, da ihr kontinuierlich neue Funktionen hinzugefügt werden. Beispielsweise ist die Cassandra API, eine von insgesamt fünf Zugriffsvarianten, erst in den vergangenen Monaten dem Preview-Status entwachsen, und auch die Möglichkeit, mehrere Schreibregionen anzulegen, ist erst seit wenigen Monaten verfügbar.
Die Datenbank zählt zu den sogenannten "foundational services" der Azure-Plattform und ist somit weltweit verfügbar. Die Cosmos DB lässt sich im Azure-Portal direkt auswählen.

Folgende zentrale Eigenschaften zeichnen Cosmos DB aus:
- weltweit verteilte Datenbank
- weitgehende Konsistenzgarantien
- ausgeklügeltes Partitionierungssystem
- Multi-Modell
- Schemafreiheit mit automatischer Indizierung
Im Folgenden beschreibt der Autor die Aspekte Verteilung, Konsistenzmodelle, Multi-Modell und automatische Indizierung.
Global und weltweit verteilt
Als weltweit verteilte Datenbank stellt Microsoft die Cosmos DB als Cloud-Dienst bereit. Hierfür bietet Azure Regionen an, in denen sich die Datenbank ausführen lässt. Wer eine neue Cosmos-DB-Instanz anlegt, muss eine Schreibregion (Write Region) angeben und kann mehrere Leseregionen (Read Region) definieren. Im Azure-Portal wird das für jede erzeugte Datenbank visualisiert:
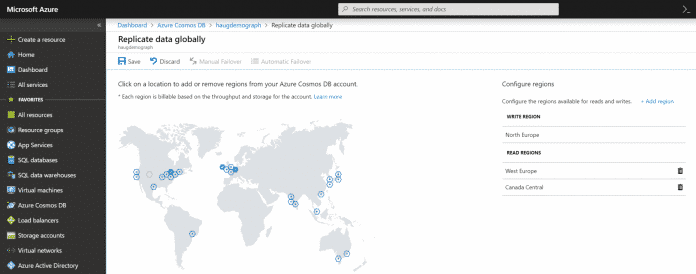
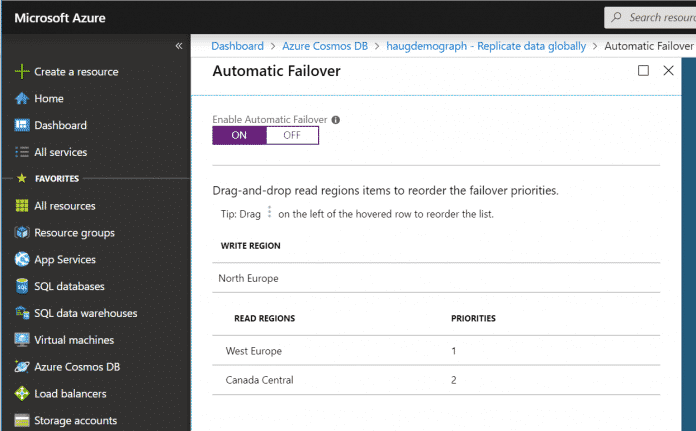
Abhängig von den Anwendungsbedürfnissen ist es möglich, die Daten so zu verteilen, dass sie nahe am Ort der Nutzung liegen. Cosmos DB verteilt gespeicherte Daten transparent in alle konfigurierten Regionen. Für den unwahrscheinlichen Fall, das die Write Region nicht verfügbar ist, gibt es in Cosmos DB die Option, einen automatischen Failover der Write Region auf eine Read Region durchzuführen, die im Folgenden für Schreiboperationen genutzt wird. Hierzu kann man im Portal den automatischen Failover aktivieren und die Reihenfolge der zu verwendenden Leseregionen festlegen.
Ein neues Feature sind sogenannte Multi-region Writes, die bei der Anlage einer Cosmos-DB-Instanz zu aktivieren sind:
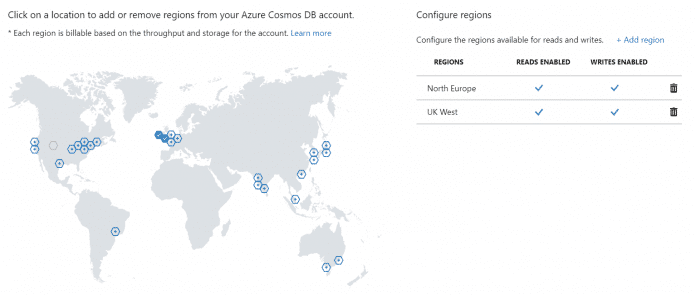
Ist das geschehen, lässt sich jede Region sowohl zum Lesen als auch zum Schreiben von Daten nutzen. Innerhalb des Portals wird nun bei der Hinzunahme einer Region angezeigt, dass diese Region read/write aktiviert ist (Abb. 5).
Ein manueller oder automatischer Failover ergibt in dieser Konfiguration keinen Sinn, da grundsätzlich mehrere Schreibregionen vorhanden sind.
Für Anwendungen, die eine geografisch verteilte Cosmos DB nutzen, sind Veränderungen dieser Verteilung transparent, da die sogenannten Multihoming APIs immer die geografisch am Nächsten gelegene Region wählt. Das Hinzufügen beziehungsweise Entfernen von Regionen lässt sich spontan durchführen. Das heißt, die Infrastruktur der Datenbank sorgt automatisch und transparent für die notwendigen Veränderungen.
Mehrere Konsistenzgarantien
Sind mehrere Read Regions konfiguriert, stellt sich automatisch die Frage, wie die Daten einer Schreiboperation in die vorhandenen Leseregionen propagiert werden. Hierfür bietet die Cosmos DB fünf Konsistenzstufen, die sich abhängig von der gewählten API nutzen lassen. Im Folgenden skizziert der Autor diese Stufen in absteigender Reihenfolge hinsichtlich ihrer Konsistenzgarantien:
- Strong: ist die stärkste Konsistenzstufe und garantiert, dass die Daten in allen Read-Regionen sichtbar sind. Das heißt, eine Schreiboperation wird direkt in alle Regionen repliziert. Diese Stufe entspricht den bekannten Eigenschaften von SQL-Datenbanktransaktionen [1] und garantiert sogenannte Linearizability [2].
- Bounded Staleness: spätestens nach n Operationen ("maximum lag") beziehungsweise nach einer maximalen Zeitspanne t sind die Daten einer Schreiboperation in allen Read-Regionen verfügbar. Die Reihenfolge der geschriebenen Daten bleibt erhalten.
- Session: garantiert, dass Daten, die innerhalb einer Session geschrieben wurden, in derselben Session in anderen Regionen in der identischen Reihenfolge gelesen werden (wie Strong). Andere Sessions sehen die gleiche Reihenfolge, aber gegebenenfalls zeitlich versetzt.
- Consistent Prefix: garantiert, dass keine Out-of-order-Leseoperationen stattfinden. Das heißt, die Reihenfolge der Schreiboperationen bleibt in allen Leseregionen erhalten. Jedoch kann zu einem Zeitpunkt t in den verschiedene Leseregionen die gleiche Abfrage unterschiedliche Ergebnisse liefern.
- Eventual: gewährleistet, dass unter Abwesenheit weiterer Schreiboperationen alle Daten in den Leseregionen sichtbar sind. Allerdings wird die ursprüngliche Reihenfolge nicht mehr garantiert (schlussendliche Konsistenz).
Die Wahl der Konsistenzstufe ist sicherlich von den Bedürfnissen der Anwendung abhängig. Aber je strenger die Konsistenzstufe, desto höher die Latenz und niedriger die Verfügbarkeit und Skalierung der Lese-Operationen. Das ist eine Trade-off-Entscheidung. Cosmos DB gibt bei der Anlage einer Datenbank eine Default-Konsistenzstufe (zumeist Session) vor, die sich im Portal überschreiben lässt:

Zusätzlich ist zu beachten, dass die Auswahl der Konsistenzstufe von der gewählten API abhängt. Document SQL API, Table API und die Gremlin API unterstützen alle fünf Stufen, sowohl die MongoDB API als auch die Cassandra API jedoch nur einen Ausschnitt. Genauere Informationen zu MongoDB und Cassandra finden sich auf den Microsoft-Seiten [3]. Hierbei ist zu erwähnen, dass sich im Fall von MongoDB die Angaben auf WireProtocol 5 (MongoDB 3.4) beziehen. Diese Protokollversion ist aktuell für Cosmos DB noch im Preview-Stadium.
Fünf Speichermodelle zur Auswahl
Als Multi-Modell-Datenbank unterstützt die Cosmos DB fünf Speichermodelle. Der Zugriff erfolgt über APIs, welche die zugrunde liegenden Speichermodelle berücksichtigen. Neben Microsofts hauseigenen Document SQL und Table API unterstützt Cosmos DB mit der Gremlin-API den Zugriff auf Graphdatenbanken, die MongoDB-API und die Apache-Cassandra-API. Cosmos DB ist hierbei mitnichten einfach eine Hülle, die sich um Instanzen von MongoDB, Cassandra et cetera legt, vielmehr werden die genannten Strukturen und APIs auf die interne Struktur der Cosmos DB abgebildet.

Wurzelelement ist immer ein Azure Cosmos DB Account, der einer Azure Subscription und einer Ressourcengruppe zugeordnet ist. Bei der Anlage eines Accounts werden gleichzeitig eine Datenbank und der Typ (Table, Document, MongoDB, Cassandra oder Gremlin/Graph) festgelegt. Ist der Account erzeugt, lassen sich nachträglich weitere Datenbanken erzeugen, jedoch kann man den Typ nicht mehr ändern. Eine Datenbank besteht aus einer Menge sogenannter Container. Der Typ der Container ist abhängig vom gewählten Datenbankmodell, zum Beispiel werden im Fall einer Graphdatenbank die Container als Graphen realisiert.
In einem Container gibt es die folgenden Bereiche: Stored Procedures, Triggers und User Defined Functions. In ihnen legt man JavaScript-Skripte ab, die sich in der Datenbank beziehungsweise dem Container ausführen lassen. Der Zugriff auf diese geschieht über das Azure Portal. Interessant ist der Bereich Item. In ihm werden die über die APIs gespeicherten Daten abgelegt. Hierfür nutzt die Cosmos DB ein eigenes Modell, das drei Typen kennt:
- Atom
- Record
- Sequence
Ein Atom ist die kleinste Einheit und unterstützt primitive Datentypen wie Strings, Integer und Boolean. Ein Record ist ein aus Atomen zusammengesetzter Typ (struct). Eine Sequence enthält Atome, Records und Sequence-Objekte in Form eines Arrays. Mit diesem als ARS bezeichneten Kerndatenmodell lassen sich alle Objekte der genannten APIs abbilden. Als Datenformat kommt JSON zum Einsatz. Über REST-Schnittstellen kann man auf das Kerndatenmodell direkt zugreifen. Zwischen gewählter API und ARS findet abhängig von der gewählten API eine Projektion statt. So werden im Fall der Graph API Items als Knoten (vertices) und Kanten (edges) realisiert. Eine Aufstellung der Projektionen ist in der folgenden Tabelle gezeigt:
| API | Container-Projektion | Item-Projektion |
| DocumentDB SQL API | Collection | Document |
| Azure Table API | Table | Item |
| MongoDB API | Collection | Document |
| Gremlin API | Graph | Node und Edge |
Auch wenn ARS das Speichermodell aller angebotenen APIs ist, ist es zurzeit nicht möglich, von einer API auf eine andere innerhalb einer Datenbankinstanz zu wechseln oder einen Mischbetrieb in ihr zu fahren.
Alle genannten APIs nutzen zum Zugriff auf die Cosmos DB ihre eigenen Netzwerkprotokolle und -formate. Hiermit gewährt die Datenbank den Einsatz von Client-Bibliotheken, um eine möglichst große Zahl von Plattformen und Programmiersprachen zu unterstützen. Das ist insbesondere für die Open-Source-APIs (MongoDB, Casandra und Gremlin) von großem Vorteil. In der Cosmos DB werden diese Formate dann in das beschriebene ARS-Format umgewandelt.
Im Folgenden skizziert der Autor am Beispiel von C# den Zugriff auf Teile der APIs. Selbstverständlich lässt sich auch mit anderen gängigen Programmiersprachen wie Java, Python und C/C++ auf Cosmos-DB-Instanzen zugreifen. Insbesondere bietet die Datenbank für die unterschiedlichen APIs bereits im Portal einfache sogenannte Quick-Start-Beispiele an:

Um auf eine Cosmos-DB-Instanz zuzugreifen, ist grundsätzlich eine HTTPS-Verbindungaufzubauen. Die folgenden Beispiele zeigen exemplarisch den Verbindungsaufbau:
// Cassandra API
var options = new Cassandra.SSLOptions(SslProtocols.Tls12, true,
ValidateServerCertificate);
options.SetHostNameResolver((ipAddress) => "xyz.cassandra.cosmosdb.azure.com");
Cluster cluster = Cluster.Builder()
.WithCredentials("xyz", "osX...2dQ==")
.WithPort(10350)
.AddContactPoint("xyz.cassandra.cosmosdb.azure.com")
.WithSSL(options)
.Build();
// MongoDB API
string connectionString = @"mongodb://xyz:oH…b1KQ==
@aaa.documents.azure.com:10255/?ssl=true&replicaSet=globaldb";
var settings = MongoClientSettings.FromUrl(new MongoUrl(connectionString));
settings.SslSettings = new SslSettings() {EnabledSslProtocols=SslProtocols.Tls12};
var mongoClient = new MongoClient(settings);
// Document SQL und Gremlin API
var client = new DocumentClient(new
Uri(ConfigurationManager.AppSettings["endpoint"]),
ConfigurationManager.AppSettings["authKey"]);
Die benötigten Verbindungsdaten kann man über das Azure Portal beziehen, wobei der Menü-Punkt abhängig von der gewählten API unterschiedlich benannt ist (Connection String bei Cassandra und MongoDB bzw. Keys bei Document SQL, Gremlin und Table):


Wie in den Screenshots zu erkennen, gibt es grundsätzlich zwei Schlüsselarten, um Zugriffsarten zu steuern: Read-write und Read-only Keys. Über sie lässt sich eine Vorauswahl der Zugriffsmöglichkeiten eines Clients vornehmen. Die Gremlin API wartet mit einer zusätzlichen Spezialität auf. Wie im obigen Beispiel zu erkennen, wird für Document SQL und Gremlin der gleiche Code bei C# verwendet, da Microsoft eine eigene Gremlin-Client-Implementierung bereitstellt. Im Fall anderer Programmiersprachen ist aber eine andere URL zu verwenden, die natives Gremlin unterstützt.
Sobald eine Verbindung steht, lassen sich die API-spezifischen Klassen und Schnittstellen nutzen. An dieser Stelle sollen einfache CRUD-Operationen am Beispiel von MongoDB und Document SQL API gezeigt werden. Die Abfrage mit den übrigen APIs sei dem Leser überlassen.
Beispiel mit MongoDB CRUD und Document SQL API
Im obigen Beispiel wurde ein MongoClient-Objekt erzeugt. Mit dieser Instanz lädt man die entsprechende Datenbank und in dieser die gewünschte Collection, zum Beispiel:
IMongoDatabase database = client.GetDatabase("TaskDB");
IMongoCollection<MyTask> collection = database.GetCollection<MyTask>("TasksList");
Um Objekte in der Mongo Collection zu bearbeiten, sind die zu persistierenden C#-Objekte (Entitäten) mit den Bson*-Attributen zu versehen, beispielsweise:
public class MyTask
{
[BsonId(IdGenerator = typeof(CombGuidGenerator))]
public Guid Id { get; set; }
[BsonElement("Name")]
public string Name { get; set; }
...
Nun kann man folgende einfache CRUD-Operationen ausführen:
// Create
MyTask task = new MyTask() {Name = "Arbeiten"};
collection.InsertOne(task);
// Read
IFindFluent<MyTask, MyTask> result = collection.Find(m => m.Id == task.Id);
MyTask t = result.First<MyTask>();
// Update
UpdateDefinition<MyTask> update = Builders<MyTask>.Update
.Set(m => m.Name, "Kochen");
UpdateResult ruResult = collection.UpdateOne(m => m.Id == task.Id, update);
// Delete
DeleteResult dResult = collection.DeleteOne(m => m.Id == task.Id);
Im obigen Beispiel wurde ein Document-SQL-Client-Objekt erzeugt. Über dieses lassen sich die CRUD-Operationen ausführen. Klassen, die per Document SQL API verwaltet werden sollen, müssen JSON-Attribute an ihren persistenten Eigenschaften besitzen, etwa:
public class Item
{
[JsonProperty(PropertyName = "id")]
public string Id { get; set; }
[JsonProperty(PropertyName = "name")]
public string Name { get; set; }
...
Anschließend lassen sich Instanzen dieser Klasse per Document SQL API verarbeiten:
string DatabaseId ="Test";
string CollectionId ="Item";
Item item = new Item() {... };
Item updatedItem = new Item() {... };
//create
Document createdDocument = await client.CreateDocumentAsync(
UriFactory.CreateDocumentCollectionUri(DatabaseId, CollectionId), item);
String id = createdDocument.Id;
//read
Document readDocument = await client.ReadDocumentAsync(
UriFactory.CreateDocumentUri(DatabaseId, CollectionId, id));
// update
Document updatedDocument = await client.ReplaceDocumentAsync(
UriFactory.CreateDocumentUri(DatabaseId, CollectionId, id), updatedItem);
// delete
Document deletedDocument = await client.DeleteDocumentAsync(
UriFactory.CreateDocumentUri(DatabaseId, CollectionId, id));
Die beiden Beispiele verdeutlichen, dass sich die Zugriffsmechanismen der APIs deutlich unterscheiden.
Automatische Indizierung
Die Cosmos DB setzt auf zwei Mechanismen, um Abfragegeschwindigkeiten von unter 10 Millisekunden im 99-Prozent-Perzentil zu garantieren:
- Partitionierung
- Indizierung von Daten
Bei der Partitionierung werden die Daten, sofern die Voraussetzungen wie das Vorhandsein eines Partitionsschlüssels erfüllt sind, auf physikalische und logische Partitionen aufgeteilt. Eine gute Einführung findet sich in der Dokumentation der Cosmos DB (Dokument 1 [4], Dokument 2 [5]).
Die Cosmos DB ist grundsätzlich schemafrei. Das ermöglicht eine Evolution der Datenbestände ohne aufwendige Schemaanpassungen. Um Performanceanforderungen bei der Abfrage von Daten befriedigen zu können, werden standardmäßig alle Daten eines Cosmos-Containers indiziert. Jedoch muss man bedenken, dass die Indizierung von Daten in die Kosten der Cosmos DB einfließen. Deshalb ist es möglich, die sogenannte Indexing-Policy des Containers anzupassen. Das geschieht durch Einschließen beziehungsweise Ausschließen von JSON Properties (sogenannte Paths). Bindet man Properties in den Index ein, werden ihm Index-Typ und -art zugewiesen. Der Typ legt fest, ob es sich beispielsweise um einen Zahlenwert oder eine Zeichenkette handelt, und die Index-Art bestimmt, welche Form der Index besitzt. Zusätzlich wird die sogenannte Precision gesetzt, welche die Genauigkeit des Index und damit auch dessen Größe und Berechnungsaufwand festlegt.
Im Azure Portal wird das über den Eintrag "Scale & Settings" ermöglicht:

Zusätzlich lässt sich der Index eines Containers programmatisch setzen. Im folgenden Beispiel geschieht das für eine Document-SQL-Datenbank. In diesem Fall wird der Container auf eine DocumentCollection abgebildet und entsprechend parametrisiert. Das geschieht, indem man auf der IndexingPolicy-Eigenschaft den Include- und ExcludePaths-Collections-Regeln hinzufügt.
var collection = new DocumentCollection() {Id = "rangeSinglePathCollection"};
// Title mit RangeIndex
collection.IndexingPolicy.IncludedPaths.Add(
new IncludedPath
{
Path = "/Title/?",
Indexes = new Collection<Index>
{
new RangeIndex(DataType.String) {Precision = 20}
}
});
// Alles andere Default
collection.IndexingPolicy.IncludedPaths.Add(
new IncludedPath
{
Path = "/*",
Indexes = new Collection<Index>
{
new HashIndex(DataType.String) {Precision = 3},
new RangeIndex(DataType.Number) {Precision = -1}
}
});
Standardmäßig werden Zahlen und Zeichenketten mit dem RangeIndex indiziert. Dieser Typ ermöglicht Abfragen mit Vergleichsoperatoren wie =, !=, >, aber auch "ORDER BY"-Abfragen. Zusätzlich gibt es den HashIndex, der früher für Zeichenketten genutzt wurde und insbesondere Join-Operationen unterstützt. In Cosmos DB wurde jedoch das Index-Layout geändert, sodass dieser Typ mittlerweile ignoriert wird.
Zusätzlich kann man die Indexgenauigkeit (Precision) angeben. Früher ging es, das Indizierungsverhalten mit diesem Parameter zu steuern. Mit der Einführung des neuen Index-Layouts ist die Precision jedoch immer auf Maximum definiert und Cosmos DB ignoriert einen geänderten Wert einfach. Datentypen wie Point, Polygon und LineString benötigen einen Spatial-Index.
Neben Indexpfaden und -typen lässt sich der Modus der Indizierung beeinflussen, und zwar den Zeitpunkt der Indexaktualisierung. Cosmos DB kennt hierfür drei Arten:
- Consistent: Index wird synchron mit Dateneintrag aktualisiert
- Lazy: Index wird asynchron aktualisiert
- None: kein Index (nur bei Key-Value Store mit ID-Zugriff sinnvoll)
Ändert sich bei einem Cosmos-Container der Index, geschieht das asynchron im laufenden Betrieb. Hierbei wird er mit der neuen Indexing-Policy transformiert. Diese Transformation geschieht auf dem bestehenden Index. Das heißt, es wird keine Schattenkopie oder Ähnliches genutzt. Cosmos DB garantiert trotz laufender Transformation die Konsistenz aller Lese- und Schreiboperationen.
Fazit
Cosmos DB ist eine interessante Alternative zu SQL-Datenbanken, aber auch zu einigen NoSQL-Datenbanken. Die Integration in die Azure-Plattform ermöglicht ein schnelles Aufsetzen und Verwalten entsprechender Cosmos-DB-Instanzen. Die aufgezeigten Eigenschaften einfache weltweite Verteilung, verschiedene Konsistenzmodelle und automatische Indizierung bringen viele Vorteile mit sich. Mit der Multi-Modell-Eigenschaft bietet Cosmos DB die Möglichkeit, entsprechend den Anwendungsbedürfnissen eine API auszuwählen. Microsoft hat mit Cosmos DB nicht versucht, eine neue API zu definieren, die auf der Übermenge der genannten APIs basiert.
Der Autor spricht sich für Microsofts Weg aus, die genannten APIs nativ anzubieten. Allerdings zeigt sich auch, dass Microsofts eigene APIs gut unterstützt werden, während Open-Source-APIs wie MongoDB und Gremlin in der Implementierung API-spezifischer Features noch hinterherhinken. Damit ist es aktuell auch fraglich, ob eine bestehende MongoDB-, Gremlin- oder auch Cassandra-Anwendung in Richtung Cosmos DB migriert werden sollte. Hier ist eine gewisse Zurückhaltung anzuraten. Bei Green-Field-Projekten lässt sich sicherlich etwas mutiger entscheiden.
Im Artikel wurden einige Aspekte wie Sicherheit, Benutzerverwaltung, Partitionierung aber auch Kosten nicht betrachtet. Vor einem Projekteinsatz sind diese sinnvollerweise zu bewerten.
Thomas Haug
arbeitet als CTO für die MATHEMA Software GmbH und Redheads Ltd. Sein Schwerpunkt liegt auf verteilten Java- und .NET-Enterprise-Systemen. Daneben hält er regelmäßig Vorträge auf Fachkonferenzen und schreibt Artikel in Fachmagazinen. In seiner Freizeit arbeitet er an einem Codeanalyse- und Visualisierungswerkzeug.
(ane [6])
URL dieses Artikels:
https://www.heise.de/-4446403
Links in diesem Artikel:
[1] https://de.wikipedia.org/wiki/ACID
[2] https://de.wikipedia.org/wiki/Konsistenz_(Datenspeicherung)#Linearizability
[3] https://docs.microsoft.com/de-de/azure/cosmos-db/consistency-levels-across-apis
[4] https://docs.microsoft.com/de-de/azure/cosmos-db/global-dist-under-the-hood
[5] https://docs.microsoft.com/de-de/azure/cosmos-db/partitioning-overview
[6] mailto:ane@heise.de
Copyright © 2019 Heise Medien