

Flexibel programmieren mit dem Fluent Interface
In Kombination mit dem Fluent Interface hilft das Entwurfsmuster "Builder" Entwicklern, ihre Projekte zu strukturieren.
- Bernd Schiffer
- Kersten Auel

Diverse Paradigmen sollen Entwicklern helfen, große Projekte klar zu strukturieren und den Überblick zu bewahren. Nicht immer geht das einher mit Verständlichkeit und guter Lesbarkeit von Programmen. Das Entwurfsmuster Builder zusammen mit dem Fluent Interface können hier helfen.
Das Entwurfsmuster "Erbauer" (Builder) ist in die Jahre gekommen. Neue Möglichkeiten beim Erstellen komplexer Objektgeflechte ergeben sich bei der Implementierung einer sogenannten "flüssigen Schnittstelle" (Fluent Interface, siehe "Onlinequellen" [a]). Dieser Artikel beschreibt evolutionär in wenigen Schritten eine solche Schnittstelle, ausgehend von einer klassischen Objekterzeugung.
Bei großen Applikationen spielt fast immer die Anbindung externer Systeme eine Rolle. Hierbei werden Daten ausgetauscht, die ein Drittsystem meist in einem vorgegebenen Format übermitteln soll. In vielen Fällen handelt es sich dabei nicht um Standards wie XML, sondern um proprietäre Formate. Eins davon soll diesem Artikel als Beispiel dienen. Das Format besteht aus Abschnitten, von denen jeder eine Menge von Werten aufnimmt, die an bestimmten Stellen des Abschnitts notiert werden. Eine formale Spezifikation dieses Formats sieht so aus:
(Abschnitt($stelle:wert)*$)+
Zu lesen ist diese Notation wie folgt: "Mindestens ein Abschnitt nimmt beliebig viele Tupel von Stellen zu Werten auf, wobei vor jedem Tupel ein Dollarzeichen steht und jedem Abschnitt ein Dollarzeichen folgt." Ein Beispiel wäre:
abschnitt$1:wert$3:anderer_wert$anderer_ abschnitt$42:wieder_anderer_wert
Dieses Beispiel soll als Anschauungsobjekt für eine API dienen. Deren Code ist in einer für viele deutschsprachige Projekte typischen Mischform aus deutscher und englischer Sprache gehalten. Der Vorteil dabei ist, dass beim – zumindest national gesehen deutschsprachigen – Kunden Begriffe wie Abschnitt, Wert und Stelle zum Sprachgebrauch gehören und die Entwickler somit weniger Kontextwechsel durchführen müssen, als wenn sie diese Begriffe ins Englische übersetzten.
Flexibilität gewinnen
Feste API unterbindet Flexibilität
Eine klassische API für diesen Anwendungsfall besteht aus den zwei Klassen Abschnitt und AbschnittUtil. Listing 1 zeigt einen Ausschnitt der Testklasse AbschnittTest. Abschnitte können demnach Werte für Stellen aufnehmen, und man kann diese Werte für eine bestimmte Stelle wiederfinden. Um den Abschnitt zu erzeugen, erfolgt zunächst seine Instanziierung über einen Default-Konstruktor. Per Setter für die Instanzvariable name wird der Abschnittsname gesetzt. Schließlich werden zwei Werte an zwei verschiedene Stellen geschrieben.
Der Test benötigt eigentlich "einen Abschnitt mit Namen abschnittsname mit Wert a an Stelle 1 und mit Wert b an Stelle 2". Tatsächlich aber wurde ihm bislang etwas vorgesetzt, was zusammengefasst und ohne Variablen so aussieht:
Abschnitt abschnitt = new Abschnitt();
abschnitt.setName("abschnittsname");
abschnitt.add(1, "a");
abschnitt.add(2, "b");
Dies liest sich weitaus holpriger als im normalen Sprachgebrauch. Es ist faszinierend, zwei Programmierern dabei zuzuhören, wie sie sich gegenseitig beispielsweise beim Pair Programming Code dieser Art vorlesen. Anstatt so etwas zu sagen wie "Hier benötigen wir einen Abschnitt mit Namen abschnittsname mit Wert a an Stelle 1", was ein grammatikalisch korrekter deutscher Satz wäre, sagen sie etwa "Hier machen wir einen new Abschnitt und setzen danach den abschnittsnamen und dann adden wir noch 1 Komma a".
Ein naiver Ansatz zur Lösung dieses Lesbarkeitsproblems ist die Einführung eines entsprechenden Konstruktors, etwa:
public Abschnitt(String name, Abschnittseintrag eintrag...){
/* Implementierung */}
Hierbei ist ein Abschnittseintrag nur eine Hilfsklasse zur Aufnahme einer Stelle und eines dazugehörigen Wertes. Der Aufruf erfolgt dann so:
Abschnitt abschnitt =
new Abschnitt("abschnittsname",
new Abschnittseintrag(1, "a"),
new Abschnittseintrag(2, "b"))
Damit ist die Konstruktion eines Abschnitts auf eine Anweisung reduziert, allerdings auf Kosten der Flexibiliät: Für jede anderweitige Konstruktion eines Abschnitts müsste der Konstruktor respektive die Factory-Methode überladen werden, etwa wenn Abschnitte mit IDs, Validatoren, Konvertern, Typen und anderen für die Konstruktion nötigen Teilen gebaut würden. Da wäre die Übersicht bald nicht mehr gegeben, und ein armer Programmierer mag sich bald fragen, welchen der vielen Konstruktoren er aufrufen muss. Nicht gut.
Erforderlich ist zudem, dass der Programmierer weiß, ob das gerade gebaute Objekt konsistent ist. Eine kurze Definition für die Konsistenz eines Abschnitts besagt: "Ein Abschnitt muss immer einen Namen haben. Er darf keine bis beliebig viele Stelle-Wert-Paare haben." Diese Information steht jedoch nicht zum Konstruktionszeitpunkt – also beim Programmieren – zur Verfügung, sondern zeigt sich gegebenenfalls erst zur Laufzeit durch schwer nachvollziehbare Fehlermeldungen. Das heißt, Entwickler haben es mit einer unlesbaren, unflexiblen, unübersichtlichen und inkonsistenten – einer fest(gefahren)en – API zu tun.
Umgangssprache
Zartschmelzende API gefährdet Konsistenz
Stattdessen lässt sich ein Abschnitt auch folgendermaßen konstruieren:
Abschnitt abschnitt =
Abschnitt.mitNamen("abschnittsname").mitWert("a").anStelle(1).undMitWert("b").a
nStelle(2);
Diese Konstruktion liest sich wie die umgangssprachliche Formulierung oben, lediglich ein paar sprachbedingte Punktionen stören noch die freie Rede. Diese Art der Erzeugung gegen eine Schnittstelle, die solch eine flüssige Formulierung zulässt, nennt sich Fluent Interface. Es ermöglicht dem Entwickler den Sprung von einer API hin zu einer DSL, einer Domain Specific Language [b, c], die die Konstruktion von Objekten für den Anwender einer Schnittstelle stark vereinfacht. Martin Fowler und Eric Evans haben diesen Begriff geprägt und das Pattern herausgearbeitet. Die flüssigen Schnittstellen sind stark im Domain Driven Design [1] vertreten, ihre Wurzeln reichen jedoch deutlich weiter zurück: Smalltalker und Lispler sind in der Regel damit vertraut. Es gibt aber auch in modernen Programmiersprachen mittlerweile gute Beispiele für die Anwendung dieses Pattern, etwa Java-Bibliotheken wie JUnit, Easymock und JMock oder die Web-Frameworks Ruby on Rails und Grails.
Die Implementierung einer flüssigen Schnittstelle ist ungleich anspruchsvoller als die einer klassischen, festen. Ein naiver Ansatz, der – euphemistisch gesehen – eher zartschmelzend als flüssig daherkommt, sähe aus wie Listing 2.
Damit kann ein Benutzer einen Abschnitt schon flüssig konstruieren. Es fällt zunächst auf, dass Setter-Methoden einen Rückgabewert haben können, hier jeweils das zu konstruierende Objekt. Erst diese Eigenschaft der Setter einer flüssigen API ermöglichen eine Aneinanderreihung von Methodenaufrufen und damit einen grammatikalisch korrekten Satzbau.
Hinzu kommt, dass diese Notation von der in Java verbreiteten Konvention abweicht, für Methoden Befehle in Form von Imperativen zu verwenden, etwa initialisiere(), add() oder getFoo(). Der Vorteil der Konvention ist, dass beim Blick auf die an einem Objekt aufzurufenden Methoden anhand des Methodennamens klar wird, welche Befehle das Objekt entgegennehmen kann.
Bei einem flüssigen Interface gibt es viele Methoden, deren Namen wenig Aussagekraft über ihre Verwendbarkeit haben. Beispiele dafür sind mit, in, undMit oder anStelle. Diese Methoden sind nur aus dem Kontext, also dem Satzbau, heraus interpretierbar. Es ist zwar recht einfach, flüssige Schnittstellen als solche aufgrund der Methodennamen zu identifizieren und sich als Programmierer von der vorgegebenen Grammatik leiten zu lassen, jedoch steigt der Schwierigkeitsgrad mit der Größe der Schnittstelle.
Lesbarer ist die Objektkonstruktion mittlerweile und flexibler ebenfalls: Die Methoden lassen sich beliebig miteinander verknüpfen. Neue Attribute am Objekt kann man quasi sofort bei der Konstruktion verwenden und muss sie nicht erst in die Konstruktoren einarbeiten. Allerdings schießt diese Flexibilität weit übers Ziel hinaus, denn wenn die Methoden beliebig miteinander verknüpfbar sind, ist keine Konsistenz des konstruierten Objekts zu gewährleisten:
Abschnitt abschnitt =
Abschnitt.mitNamen("abschnittsname").mitWert("a").mitWert("b").anStelle(2);
Offensichtlich hat der Konstrukteur hier vergessen, den Wert a an die Stelle 1 zu schreiben. Das Verhalten dieses halbfertigen Objekts ist nicht ersichtlich, ohne den Quellcode der Abschnittsklasse zu studieren. Dies jedoch sollte wiederum für eine gute API unnötig sein; selbsterklärende Schnittstellen erhöhen ihre Benutzbarkeit enorm.
Leider konnte die zartschmelzende Variante die Unübersichtlichkeit der festen API nicht beseitigen. Hierzu ein Blick auf die Code-Vervollständigung: Eine IDE bietet bei der Code Completion auf eine Tastenkombination hin all die Codestücke wie Variablen, Methoden und Klassen an, die an der Stelle, an der sich der Cursor befindet, sinnvoll sind. Insbesondere dient dies dazu, an Objekten diejenigen Methoden ausfindig zu machen, die an ihm aufgerufen werden können. So lässt sich schnell durch eine API navigieren und Code niederschreiben.
Abschnitt mitNamen(String name) ist die einzige statische Methode, die durch Code-Vervollständigung an der Abschnittsklasse angeboten wird, sodass der Benutzer nichts falsch machen kann. Die zur Konstruktion von Abschnitten gedachten Objekt-Methoden dagegen sind Abschnitt mitWert(String wert), undMitWert(String wert) sowie Abschnitt anStelle(int stelle). Es ist jetzt für den Benutzer nicht ersichtlich, welche Methoden er aufrufen darf (mitWert() sowie undMitWert()) und welche nicht (anStelle()). Selbst die Reihenfolge der Code-Aufrufe könnte vertauscht werden: Statt .mitWert("a").anStelle(1) könnte der Entwickler .anStelle(1).mitWert("a") schreiben – und sich zu Recht wundern, warum er keinen brauchbaren Abschnitt erzeugen konnte. Hier hilft ihm auch die deutsche Grammatik nicht weiter, denn die Sätze "Abschnitt mit Wert a an Stelle 1" und "Abschnitt an Stelle 1 mit Wert a" folgen beide einem legitimen Satzbau.
Verflüssigung
Flüssige API muss Aufgaben delegieren
Diese beiden Einschränkungen – inkonsistente Objekterzeugung und unzureichende Vorgabe der Grammatik durch Code Completion – lassen diese Implementierung eines Abschnittes nicht flüssig, sondern eher zartschmelzend erscheinen.

Ein vollständiger Übergang in den flüssigen Aggregatzustand lässt sich durch eine Grammatik erreichen. Dies bedeutet, die Reihenfolge der erlaubten Methodenaufrufe zu analysieren und die Stellen zu identifizieren, die das zu konstruierende Objekt in einem inkonsistenten und damit unbrauchbaren Zustand hinterlassen. Ein Zustandsdiagramm hilft da weiter (Abbildung 1).
Der Einstieg in die Konstruktion erfolgt direkt bei der Klasse Abschnitt. Von hier aus kann die Methode mitNamen() aufgerufen werden und liefert einen konsistenten Abschnitt ohne Werte zurück. Die Methoden mitWert() sowie undMitWert() hingegen dürfen keinen Abschnitt zurückliefern. Bei ihrem Aufruf ist der Abschnitt in einem inkonsistenten und unfertigen Zustand. Erst ein weiterer Methodenaufruf von anStelle() liefert einen konsistenten Abschnitt.
Es kann viele unfertige Zustände während der Konstruktion eines Objektes mittels eines Fluent Interface geben. Sie zu identifizieren ist aber nur die halbe Miete; unfertige Zustände werden in sogenannten Deskriptoren implementiert. Durch den Einsatz eines Deskriptors muss die Abschnittsklasse nicht mehr sich selbst zurückgeben, wenn mitWert() oder undMitWert() an ihr aufgerufen wird. Der Benutzer erhält statt eines Objekts vom Typ Abschnitt eins vom Typ des Deskriptors. In diesem Fall soll er WertZuStelleDescriptor heißen. Der Benutzer kann jetzt nur noch die Methoden aufrufen, die der Deskriptor bereitstellt. Code wie der folgende würde nun nicht mehr kompilieren:
Abschnitt abschnitt =
Abschnitt.mitNamen("abschnittsname").mitWert("a").mitWert("b").anStelle(2);
Der erste Aufruf von mitWert() liefert einen Deskriptor zurück, an dem ein erneuter Aufruf von mitWert() nicht erlaubt ist. Somit kann das Programm nur noch konsistente Objekte erzeugen.
Zwar ist die Arbeit mit dem Descriptor-Entwurfsmuster gewöhnungsbedürftig, aber dafür flexibel ausbaubar. Deskriptoren können andere Deskriptoren zurückgeben und somit Grammatiken beliebiger Komplexität realisieren.
Ebenfalls gelöst durch den Einsatz von Deskriptoren ist die unzureichende Vorgabe der Grammatik durch Code Completion: Überall im Quellcode werden bei der Erzeugung des Abschnittes nur die Methoden angeboten, die der definierten Grammatik entsprechen. Den um den Einsatz von Deskriptoren modifizierten Abschnitt zeigt Listing 3.
Die deutlichste Änderung ist in der Methode mitWert() zu sehen: Durch einen Callback-Aufruf mit dem Interface WertZuStelleAddierer wird anstelle eines Abschnitts ein AbschnittWertZuStelleDescriptor zurückgegeben. Die Frage ist, warum hier eine anonyme Klasse zum Einsatz kommt, statt dass der Abschnitt dem Deskriptor gleich eine Referenz des zu konstruierenden Abschnitts, also sich selbst, übergibt. In der klassischen Implementierung eines Abschnitts gibt es eine Methode add(String wert, int stelle), die der Deskriptor direkt aufrufen könnte.
Wenn der Deskriptor eine Referenz auf Abschnitt setzt, bedeutet das allerdings eine zyklische Abhängigkeit zwischen ihm und dem Abschnitt, ergo schlechtes Design. Aus Sicht des Fluent Interface gibt es noch einen pragmatischen Grund, dies zu vermeiden. Bei der Konstruktion des Objekts sollen keine Methoden mitwirken, die außerhalb der definierten Grammatik sind. add() wäre genau solch eine Methode. Ihren Aufruf verhindert das Interface WertZuStelleAddierer. Listing 4 zeigt den Code des Addierers und des Deskriptors.
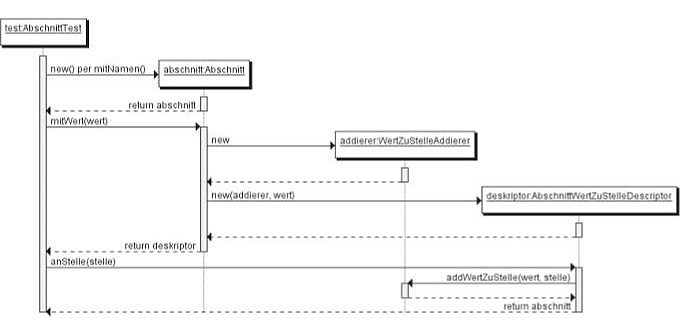
Das Sequenzdiagramm in Abbildung 2 soll das verdeutlichen. Zunächst wird ein Abschnitt vom Test mitNamen() erzeugt. Für den Addierer gibt das Interface nur die Schnittstelle vor, und die dazugehörige anonyme Klasse bestimmt die Implementierung anhand des Entwurfmusters "Befehl" (Command). Der Deskriptor nimmt den Addierer auf und ruft ihn zusammen mit dem Wert auf, sobald der Konstrukteur an der Abschnittsklasse mitWert() aufruft. Der Aufrufer hat dann nur noch die Möglichkeit, die öffentlichen Methoden des Deskriptors aufzurufen, also die nächsten grammatikalisch validen Schritte zu gehen. In diesem Fall ist dies die Methode anStelle() und der Rückgabewert ist wieder Abschnitt.
Dank der flüssigen Schnittstelle ist die Lesbarkeit des Codes nach wie vor gegeben, und die definierte Grammatik garantiert Flexibilität und Konsistenz. Darüber hinaus ist die API jetzt übersichtlich – allerdings nur für die Konstruktion. Nicht so gut steht es mit der weiteren Verwendung im Lebenszyklus des Objekts, denn an einem fertig konstruierten Objekt können nun folgende Methoden aufgerufen werden:
static Abschnitt mitNamen(String name)AbschnittWertZuStelleDescriptor mitWert(String wert)AbschnittWertZuStelleDescriptor undMitWert(String wert)String findeWertAnStelle(int stelle)boolean hatWert(String wert)String getName()
Die ersten drei Methoden – die des Fluent Interface – dienen zur Konstruktion eines Abschnitts und werden am fertig gebauten Objekt nicht mehr benötigt. Hier sind Methoden mit entsprechender Logik gefragt, wie sie bei den beiden nächsten Methoden gegeben ist, oder abfragende Methoden wie die letzte. Schließlich bleibt die Frage offen: Wie kann man einem fertigen Objekt später ein weiteres Stelle-Wert-Paar hinzufügen? Das wäre über die Methoden des Fluent Interface möglich, allerdings drücken solche Satzfetzen nicht mehr aus, was sie tun:
abschnitt.mitWert("weiterer wert").anStelle(5);
Methoden zur Konstruktion eigenen sich nicht zur späteren Manipulation eines Objekts. Hinzu kommt, dass die Abschnittsklasse zwei Aufgaben gleichzeitig übernimmt: die Konstruktion eines komplexen Datentyps (sich selbst) sowie die Datenhaltung samt Logik. Dies aber widerspricht dem Prinzip des "Separation of Concerns" (SoC) [d], das besagt, dass eine Klasse nur eine Aufgabe erfüllen sollte.
Rettender Erbauer
Flüssiger Erbauer trennt Belange
Die Rettung naht in Form des Erzeugungsmusters "Erbauer" (Builder). Ein Erbauer trennt die Repräsentation eines Objekts von seiner Konstruktion, in diesem Falle die konstruierenden Methoden (und wofür sie stehen) vom Rest des Abschnitts. Ein Erbauer in Kombination mit einer flüssigen Schnittstelle, von Fowler "Expression Builder" [e] genannt, ist eine deutliche Bereicherung im Hinblick auf die Lesbarkeit:
Abschnitt abschnitt =
ErzeugeAbschnitt.mitNamen("abschnittsname").mitWert("a").anStelle(1).undMitWert
("b").anStelle(2).jetzt();
Zuerst fällt auf, dass der Erbauer selbst mit einem Verb statt mit einem Nomen benannt ist. Dieser Kniff [f] lässt nun einen vollständigen Satz im Imperativ entstehen:
"Erzeuge Abschnitt mit Namen abschnittsname mit Wert a an Stelle 1 und mit Wert b an Stelle 2, jetzt!"

Zurück gibt der Flüssige Erbauer ein Objekt vom Typ Abschnitt, der keine konstruierenden Methoden mehr hat und sich ganz um die Repräsentation seiner selbst kümmern kann. Abbildung 3 zeigt die API der Klassen ErzeugeAbschnitt und Abschnitt.
An dieser Stelle lässt sich einwenden, dass noch kein Separation of Concerns stattgefunden hat. Immerhin gibt es ja noch Methoden wie setName(String name) und put(int Stelle, String wert). Doch hier ist zu unterscheiden zwischen konstruierenden und verändernden Methoden. Alle konstruierenden sind jetzt am Builder verankert. Ob das Objekt nach der Konstruktion noch veränderbar sein darf, ist eine Designentscheidung, die unabhängig von der Konstruktion ist. In diesem Fall ist die Entscheidung für ein veränderliches Objekt gefallen; unveränderliche Objekte hätten keine solchen modifizierenden Methoden.
Eine Besonderheit stellt die Methode jetzt() an der Erbauer-Klasse ErzeugeAbschnitt dar. Prinzipiell könnte man einem Abschnitt beliebig viele Werte hinzufügen. Hierzu muss stets der Erbauer herhalten, und so gibt jede Methode, die einen Wert für eine Stelle aufnimmt, letztendlich ein Objekt vom Typ ErzeugeAbschnitt zurück. Will man jedoch keinen Wert mehr hinzufügen, soll der Rückgabewert ein Abschnitt sein. Dies erreicht der Aufruf von jetzt(), der den Verantwortungsbereich des flüssigen Erbauers terminiert. Von hier an ist der Abschnitt auf sich allein gestellt. Ein lauffähiges Beispiel steht auf dem iX-Listingserver bereit.
Fazit
Fazit
Durch evolutionäres Design getriebenen entwickelte sich aus einer "festen API", die unlesbar, unflexibel, unübersichtlich und inkonsistent war, zunächst eine "zartschmelzende API". Diese war jedoch unübersichtlich aufgrund eines naiven Entwurfes, der keine Grammatik berücksichtigte, und ermöglichte eine inkonsistente Objekterzeugung. Hieraus entwickelte sich ein Objekt mit einer "flüssigen Schnittstelle", das eine Grammatik vorgegeben hat und damit eine konsistente Objekterzeugung gewährleistete. Lediglich die Übersichtlichkeit bei der Betrachtung der Objektschnittstelle war noch verbesserungsbedürftig. Hierfür sorgte der letzte Schritt in der Evolution des Beispiels: der "flüssige Erbauer".
Literatur
[1] Eric Evans; Domain-driven Design; Tackling Complexity in the Heart of Software; Addison-Wesley, 2004
Bernd Schiffer
ist Senior-Softwareentwickler bei der akquinet it-agile GmbH Hamburg.
Listings
Listing 1
@Test
public void nimmtWerteFuerStellenAuf() throws Exception {
Abschnitt abschnitt = new Abschnitt();
abschnitt.setName("abschnittsname");
final String ersterWert = "a";
final int ersteStelle = 1;
final String zweiterWert = "b";
final int zweiteStelle = 2;
abschnitt.add(ersteStelle, ersterWert);
abschnitt.add(zweiteStelle, zweiterWert);
assertThat(ersterWert, is(abschnitt.findeWertAnStelle(ersteStelle)));
assertThat(zweiterWert, is(abschnitt.findeWertAnStelle(zweiteStelle)));
}
Ausschnitt aus AbschnittTest
Listing 2
public class Abschnitt {
Map werteZuStellen = new HashMap();
private String letzterWert;
private String name;
public Abschnitt mitWert(String wert) {
return setLetzterWert(wert);
}
private Abschnitt setLetzterWert(String wert) {
letzterWert = wert;
return this;
}
public Abschnitt undMitWert(String wert) {
return setLetzterWert(wert);
}
public Abschnitt anStelle(int stelle) {
werteZuStellen.put(stelle, letzterWert);
return this;
}
public String getName() {
return name;
}
public static Abschnitt mitNamen(String name) {
final Abschnitt abschnitt = new Abschnitt();
abschnitt.name = name;
return abschnitt;
}
/* weitere Methoden */
}
Erster Schritt zum Fluent Interface
Listing 3
public class Abschnitt {
private final Map werteZuStellen = new HashMap();
private String name;
public static Abschnitt mitNamen(String name) {
Abschnitt abschnitt = new Abschnitt();
abschnitt.name = name;
return abschnitt;
}
public AbschnittWertZuStelleDescriptor mitWert(String wert) {
final Abschnitt abschnitt = this;
final WertZuStelleAddierer addierer = new WertZuStelleAddierer() {
public Abschnitt addWertZuStelle(String wert, int stelle) {
werteZuStellen.put(stelle, wert);
return abschnitt;
}
};
return new AbschnittWertZuStelleDescriptor(addierer, wert);
}
public AbschnittWertZuStelleDescriptor undMitWert(String wert) {
return mitWert(wert);
}
public String getName() {
return name;
}
/* weitere Methoden */
}
Erweiterung um einen Deskriptor
Listing 4
public class AbschnittWertZuStelleDescriptor {
private WertZuStelleAddierer addierer;
private String letzterWert;
public AbschnittWertZuStelleDescriptor(WertZuStelleAddierer addierer, String
letzterWert) {
this.addierer = addierer;
this.letzterWert = letzterWert;
}
public Rueckgabe anStelle(int stelle) {
return addierer.addWertZuStelle(letzterWert, stelle);
}
}
public interface WertZuStelleAddierer {
Rueckgabewert addWertZuStelle(String wert, int stelle);
}
Addierer und Deskriptor
Onlinequellen
Onlinequellen (ka)
- (a) Martin Fowler: FluentInterface
- (b) Martin Fowler: DomainSpecificLanguage
- (c) Martin Fowler: Language Workbenches; The Killer-App for Domain Specific Languages?
- (d) Wikipedia: Separation of Concerns
- (e) Martin Fowler: ExpressionBuilder
- (f) Anders Norås: I'm coming down with a serious case of the DSLs!
