

GraphQL-Clients mit React und Apollo, Teil 2
React, Apollo, TypeScript: Drei zeitgemäße Techniken, um die im ersten Teil entwickelte Java-Anwendung auf Clientseite umzumünzen.
- Nils Hartmann
Der erste Teil der Artikelserie beschäftigte sich mit der Frage, wie sich mit Java GraphQL-Schnittstellen für serverseitige Anwendungen entwickeln lassen. Der zweite Beitrag zeigt, wie Entwickler einen Client für die API mit React und dem Apollo-Framework bauen können. Darüber hinaus kommt TypeScript bei der Entwicklung zum Einsatz, um die Vorzüge typsicherer Entwicklung nutzen zu können.

Ein einfacher GraphQL-Client
GraphQL-Abfragen werden überlichweise per HTTP Post Request an den Server geschickt. Die Abfrage (die GraphQL Query) als auch die Variablen dafür werden als Payload übergeben. Mit der fetch-API lassen sich somit einfach React-Komponenten bauen, die Daten von einer GraphQL-Schnittstelle abfragen und anzeigen. Das folgende Beispiel bedient sich der im ersten Teil der Serie vorgestellten BeerAdvisor-Anwendung, die auf GitHub zu finden ist.
Die Komponente führt eine Query aus, die die Daten für die Einstiegsseite der Anwendung lädt – eine Übersicht über alle im System vorhandenen Biere.
const QUERY = `
query BeerOverviewPageQuery {
beers {
id name averageStars
}
}
`;
class BeerOverviewPage extends React.Component {
state = {};
async componentDidMount() {
const response = await fetch("http://localhost:9000/graphql", {
method: "POST",
body: JSON.stringify({ query: QUERY })
});
const graphqlResult = await response.json();
this.setState({ beers: graphqlResult.data });
}
render() {
if (!this.state.beers) {
return <h1>Beers not loaded yet...</h1>;
}
return . . .; // Biere (this.state.beers) hier rendern
}
}
Sobald React die Komponente in den DOM gehängt hat, führt sie die definierte GraphQL Query aus. Das ist ein gängiges Muster beim Arbeiten mit jeglicher Art von asynchronen Daten in React. Sobald das Ergebnis geladen ist, setzt die Anwendung es in den State und rendert die Komponente neu. Die render-Methode kann die geladenen Daten nun anzeigen. Ruft React die Methode beim erstmaligen Rendern noch ohne die geladenen Daten auf, zeigt die Komponente einen Hinweis für den Benutzer an, das die Daten noch geladen werden. Auch das ist ein gewöhnliches Pattern in React-Anwendungen.
Obwohl die gezeigte Komponente funktioniert, fehlen ihr eine ganze Reihe Features, die eine Anwendung üblicherweise benötigt. Es gibt keinen Lebenszyklus des Requests (1. Request ist abgeschickt beziehungsweise wartet auf Antwort, 2. Daten sind erfolgreich geladen oder 3. es ist ein Fehler aufgetreten). Außerdem erhalten die geladenen Daten auch kein Caching außerhalb des UI. Wenn Anwender sich durch die App navigieren und dadurch die Komponente aus- und wieder einblenden, führt sie den Request beim erneuten Anzeigen der Komponente jedes Mal aus. Das kann zwar gewünschtes Verhalten sein, aber es gibt auch Fälle, in denen das nicht richtig ist und die Applikation die bereits geladenen Daten zeigen soll.
Eventuell benötigen Entwickler auch eine Mischung aus beiden Ansätzen. Zunächst zeigt die Applikation die geladenen Daten an, im Hintergrund läuft die Query aber erneut und aktualisiert mit Eintreffen des Ergebnisses die Daten in der UI. Oder es kann für die Anwendung relevant sein, dass sie die angezeigten Daten sogar dann aktualisiert, wenn der Anwender die Seite gar nicht verlässt.
Die Liste der Bewertungen eines Biers etwa wird automatisch aktualisiert, sobald eine neue Bewertung für das gerade angezeigte Bier auf dem Server eingegangen ist, ohne dass der Besucher der Seite etwas dafür tun müsste. Das ist von der gezeigten Beispiel-Komponente nicht implementiert. Wenn es sich um einen schreibenden Zugriff, also eine Mutation, handelt, kommen noch weitere Fragestellungen hinzu (etwa wie der Umgang mit dem Ergebnis der Mutation aussieht), sodass die aktualisierten Daten vom Server anwendungsweit konsistent aktualisiert dargestellt werden.
Der Einsatz von Apollo GraphQL
Eine Antwort auf die Problemstellungen verspricht die Plattform Apollo GraphQL. Apollo ist Open Source und stellt eine ganze Reihe an Frameworks und Tools zur Entwicklung von GraphQL-Server- und Clientanwendungen in JavaScript und TypeScript zur Verfügung. Der Apollo Client erschien ursprünglich für React, mittlerweile existiert er ebenfalls für andere Frameworks wie Angular und Vue.js. Er arbeitet mit jeder serverseitigen GraphQL API zusammen. Sie muss nicht mit Apollo und nicht in JavaScript implementiert sein.
Die Query-Komponente von Apollo führt GraphQL-Abfragen aus. Im simpelsten Fall erhält die Komponente lediglich eine GraphQL Query, die unmittelbar nach dem Rendern der Komponente ausgeführt wird . Entwickler können GraphQL Queries in separaten Dateien oder direkt im JavaScript Sourcecode mit der gql-Funktion notieren:
import gql from "graphql-tag";
const OVERVIEW_PAGE_QUERY = gql`
query BeerOverviewQuery {
beers {
id name averageStars
}
}
`;
Die GraphQL-Extension von Visual Studio Code kann übrigens die GraphQL Queries im Code erkennen und erlaubt es, sie direkt aus der IDE heraus auszuführen. Außerdem stellt die Extension Code Completion für die Queries auf Basis der Schema Beschreibung der abgefragten API zur Verfügung.

Zur Darstellung des Ergebnisses erhält die Komponente als Child eine Funktion übergeben ("Function as a Child"-Pattern, die in den verschiedenen Stadien der Query-Ausführung von Apollo mit unterschiedlichen Parametern aufgerufen wird. Während der Ausführung der Query setzt ist beispielsweise der loading-Parameter auf true gesetzt, wenn ein Fehler auftritt, der error-Parameter entsprechend befüllt. Wenn die Query erfolgreich ausgeführt wurde, erfolgt die Übergabe der gelesenen Daten mit dem data-Parameter.
Abhängig von den übergebenen Parametern liefert die Funktion eine dafür passende Komponente zurück. Das folgende Beispiel zeigt den Einsatz der Query-Komponente ebenfalls an Hand der Abfrage, die in der Anwendung die erste Seite darstellen soll.
function OverviewPage(props) {
return (
<Query query={OVERVIEW_PAGE_QUERY}>
{({ data, error, loading }) => {
if (error) {
return <h1>Error while loading Beers</h1>;
}
if (loading) {
return <h1>Please stay tuned - Beers are loading . . .</h1>;
}
return (
data.beers.map(beer => (
<BeerImage
key={beer.id}
name={beer.name}
stars={beer.averageStars}
beerId={beer.id}
/>
))
);
}}
</Query>
);
}
Sofern die ausgeführte GraphQL-Abfrage Variablen erwartet, werden diese mit der Property variables an die Query-Komponente übergeben.
Caching von Daten
Der Apollo-Client legt die gelesenen Daten in einem Cache außerhalb der React UI-Komponenten ab, sodass sie bei einem erneuten Rendern der Komponente zur Verfügung stehen und nicht erneut geladen werden müssen. Der Cache ist dabei komponentenübergreifend gültig. Wenn die Anwendung an anderer Stelle dieselbe Query ausführt, liefert Apollo die Daten ebenfalls aus dem Cache. Selbst wenn die Daten (Felder) aus unterschiedlichen Queries an mehreren Stellen der UI dargestellt werden, aktualisiert die Applikation sie ebenfalls an allen Stellen und nicht nur in der Komponente, in der man gerade die Query ausgeführt hat. Dadurch ist sichergestellt, dass die Daten in der UI anwendungsweit konsistent sind.
Bis zu einem gewissen Grad lässt sich das Verhalten mit Redux vergleichen. Dort liegt der globale Anwendungszustand in einem zentralen Store außerhalb der Komponentenhierarchie. In Apollo liegen zumindest die vom Server geladenen Daten an zentraler Stelle außerhalb der UI-Komponenten, im Cache (es gibt sogar die Möglichkeit, auch clientseitigen Zustand in den Apollo Cache zu schreiben und daraus zu lesen und darauf über "lokale" GraphQL Queries zuzugreifen).
Der Inhalt des Caches sowie alle ausgeführten Queries lassen sich zur Laufzeit mit den Apollo Developer Tools inspizieren, einer Chrome-Erweiterung. In ihr ist ebenfalls der Explorer GraphiQL integriert, sodass man darüber auch direkt Queries, etwa zum Testen, absetzen kann.

Daten aktualisieren
Gelesene Daten sollen oftmals zu bestimmten Zeitpunkten eine Aktualisierung erhalten. Im Fall der Bierübersicht könnte es sinnvoll sein, die Liste der Biere jedes Mal erneut zu laden, wenn der Benutzer wieder auf die Übersichtsseite zurückkehrt, damit er stets die neusten Daten sieht. Dafür könnte man die fetch-Policy verändern, sodass die Daten nicht mehr aus dem Cache geliefert, sondern jedes Mal erneut vom Server gelesen werden. Sollen die Daten aktuell bleiben, wenn der Benutzer auf der Seite verweilt, gibt es die Möglichkeit, ein Poll-Intervall als Property zu übergeben. Die Query erfolgt dann periodisch im eingestellten Intervall.
Eine weitere Option wäre, Benutzern einen "Aktualisieren"-Knopf in der UI anzubieten, damit sie selbst bestimmen können, wann sie die dargestellten Daten erneut laden möchten. Um das zu ermöglichen, übergibt die Query-Komponente neben den oben gezeigten Informationen (loading, error, data) als weiteren Parameter eine refetch-Funktion an die Child-Komponente. Diese verwendet dann die übergeben Funktion, um zum Beispiel beim Drücken eines Knopfes die Daten erneut zu laden. Das folgende Listing illustriert das:
<Query query={OVERVIEW_PAGE_QUERY}>
{({ data, error, loading, refetch }) => {
if (error) { . . . }
if (loading) { . . . }
return (
<>
{data.beers.map(beer => (
<BeerImage . . . />
))}
<button onClick={refetch}>Aktualisieren</button>
</>
);
}}
</Query>
Aktualisieren durch Server Events
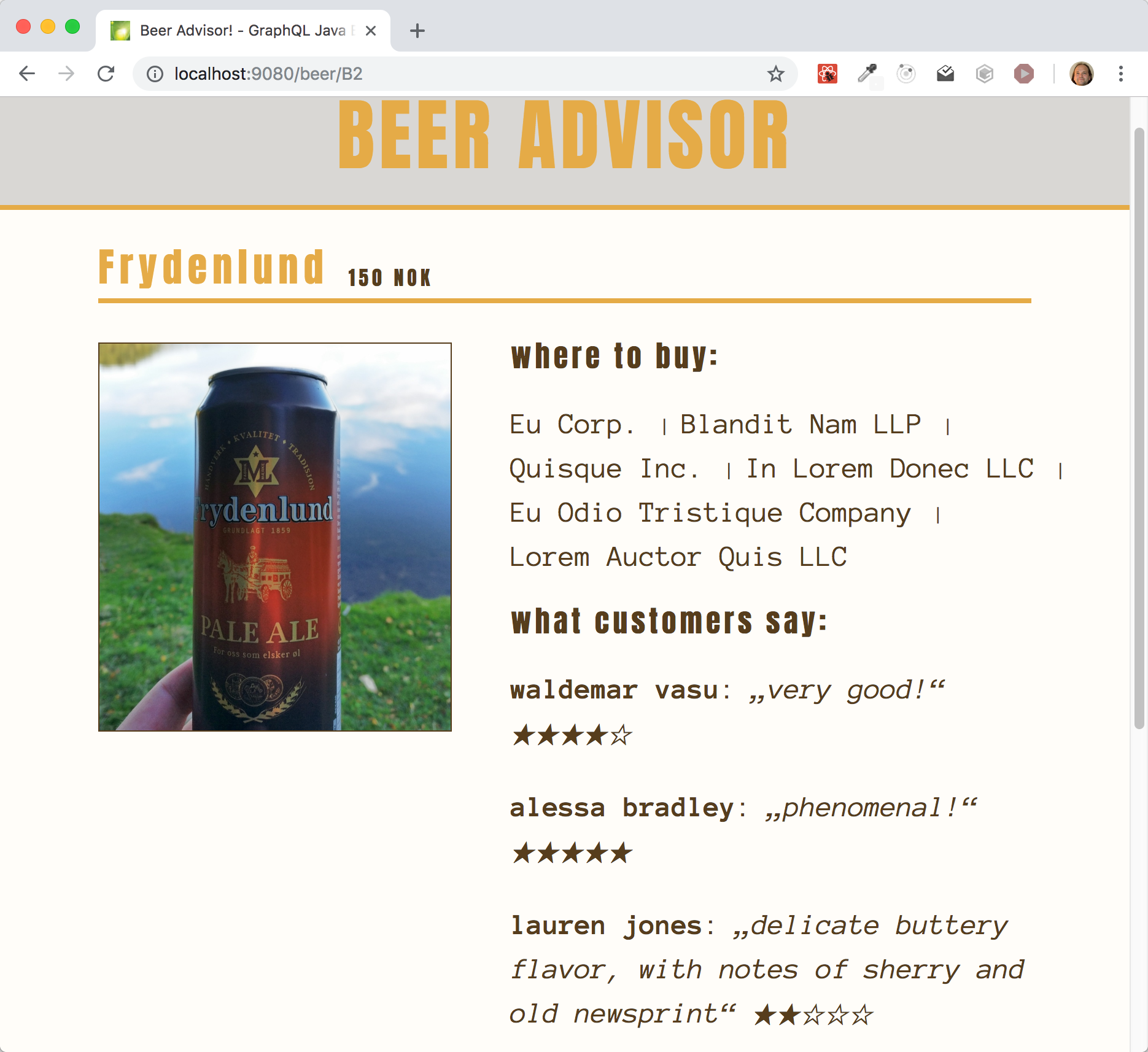
Je nach Anwendungsfall ist es erforderlich, dass der Client die Daten nach einem Event automatisch aktualisieren soll, sobald sie sich auf ihm geändert haben. Das passende Beispiel in der BeerAdivsor-Anwendung dazu ist die Einzelansicht eines Biers.
Sie stellt unter anderem die Bewertungen zu einem Bier dar. Sobald eine neue Bewertung für das angezeigte Bier auf dem Server eingeht, sehen alle Nutzer sie sofort, wenn sie die Einzelansicht im Browser geöffnet haben. Voraussetzung für die Option ist, dass die GraphQL API auf dem Server eine Subscription zur Verfügung stellt, an der der Client sich anmelden kann, um Informationen zu neuen Daten zu erhalten. Entwickler können die Subscription mit der subscribeToMore-Property an der Query-Komponente angeben. Sie kann neben der eigentlichen Subscription eine updateQuery-Funktion erhalten, um Daten, die über die Subscription reinkommen, direkt in den Apollo-Cache zu schreiben. Das ist insbesondere notwendig, wenn die Subscription neue Daten liefert (im Gegensatz zu Veränderungen bereits geladener Daten).
Das folgende Beispiel zeigt den entsprechenden Ausschnitt aus der Beer-Seite. Die BEER_PAGE_QUERY liefert alle Daten für das angezeigte Bier (Name, Preis etc.) sowie alle Bewertungen. Die RATING_SUBSCRIPTION, die die Anzeige aktualisiert, liefert hingegen nur Bewertungen vom Server. Die updateQuery-Funktion fügt deswegen dem Bier im Cache die neue Bewertung hinzu.
const BEER_PAGE_QUERY = gql`
query BeerPageQuery($beerId: ID!) {
beer(beerId: $beerId) {
id name price
ratings {
id stars comment
author { name }
}
}
}
`;
const RATING_SUBSCRIPTION = gql`
subscription RatingSubscription($beerId: ID!) {
rating: newRatings(beerId: $beerId) {
id stars comment
author { name }
beer { id }
}
}
`;
function BeerPage(props) {
return (
<Query query={BEER_PAGE_QUERY} variables={{ beerId }}>
{({ loading, error, data, subscribeToMore }) => {
if (loading) { . . . }
if (error) { . . . }
return (
<Beer
beer={data.beer}
subscribeToNewData={() =>
subscribeToMore({
document: RATING_SUBSCRIPTION,
variables: { beerId },
updateQuery: (prev, { subscriptionData }) => {
// Add received Rating to the Beer that is
// already in the Apollo Cache
const newRating = subscriptionData.data.rating;
return {
beer: {
...prev.beer,
ratings: [...prev.beer.ratings, newRating]
}
};
}
})
}
/>
);
}}
</Query>
);
}
Die Beispiel-Komponente reicht die subscribeToMore-Funktion an die Beer-Komponente weiter, die für die Darstellung der Bewertungen zuständig ist und sich demnach für neue Bewertungen interessiert. Die Beer-Komponente startet dann die Subscription sobald sie gerendert ist (componentDidMount) und beendet sie wieder, sobald die Komponente aus dem DOM wieder entfernt wird (componentWillUnmount). Das sorgt dafür, dass Serverzugriffe nur erfolgen, wenn die Komponente tatsächlich sichtbar ist und die Daten wirklich benötigt werden.
Schreiben von Daten
Über eine GraphQL-Schnittstelle lassen sich nicht nur Daten lesen, Mutations können sie ebenfalls verändern. Analog zur vorgestellten Query-Komponente gibt es die Mutation-Komponente, die ebenfalls nach dem "Function as a Child"-Pattern implementiert ist. Sie erwartet die auszuführende Mutation ebenfalls als Property. Die Mutation wird allerdings nicht unmittelbar nach dem Rendern der Komponente ausgeführt. Stattdessen bekommt die Child-Komponente eine Callback-Funktion übergeben, mit der die Mutation gestartet werden kann. Somit kann die Komponente die Mutation ausführen, sobald es fachlich passt, zum Beispiel bei einem Klick auf einen "Speichern"-Knopf.
Im Beispiel können Nutzer über ein Formular neue Bewertungen für ein Bier eintragen. Eine Mutation schickt die erfasste Bewertung (bestehend aus User-Id, Kommentar und Bewertung in Sternen) an den Server, sobald der Benutzer auf "Bewertung abgeben" im Formular klickt. Die Komponente sieht vereinfacht wie folgt aus:
const ADD_RATING_MUTATION = gql`
mutation AddRatingMutation($input: AddRatingInput!) {
newRating: addRating(ratingInput: $input) {
id comment stars author { name }
}
}
`;
function Beer(props) {
return <div>
// . . .
<Mutation mutation={ADD_RATING_MUTATION}>
{addNewRating => {
<AddRatingForm onSubmit={(userId, stars, comment) => {
addNewRating({
variables: {
input: { userId, stars, comment, beerId: props.beerId }
}
})
}} />
}
</Mutation>
</div>;
}
Das Formular zur Eingabe der Bewertung ist in der Komponente AddRatingForm implementiert. Sie erwartet eine Callback-Funktion (onSubmit), die Benutzer durch einen Klick auf "Bewertung abgeben" aufrufen. Die AddRatingForm übergibt der Callback-Funktion die im Formular eingegebenen Daten, sodass sie diese über die addNewRating-Funktion an die umschließende Mutation-Komponente weitergeben kann. Die Mutation-Komponente sorgt schließlich dafür, dass die entsprechende Abfrage (die per mutation-Property übergeben wurde) mit den übergebenen Variablen (hier: den Werten aus dem Formular) ausgeführt wird.
Nach der Ausführung der Mutation versucht Apollo mit den zurückgelieferten Daten den Cache zu aktualisieren. Wenn als Rückgabewert der Mutation ein im Cache vorhandenes Objekt vorliegt, aktualisiert die Applikation es im Cache und passt die Darstellung in der UI an. Im Beispiel verändert das kein bestehendes Objekt, sondern erzeugt ein neues.
Ähnlich wie bei der für Queries gezeigten subscribeToMore-Funktion ist deswegen nach der Ausführung der Mutation eine Aktualisierung des Apollo-Caches manuell notwendig. Dazu erhält die Mutation-Komponente noch eine update-Funktion. Sie bekommt die Daten übergeben, die die Mutation als Antwort vom Server erhält. In der Anwendung ist das die neue Bewertung, die der Server in die Datenbank gespeichert hat. Das Rating-Objekt muss dem im Cache befindlichen Beer-Objekt hinzugefügt werden, wie das folgende Listing zeigt. Der Zugriff auf Einträge im Cache kann übrigens ebenfalls mit einem GraphQL-artigen Query erfolgen. Wie in React üblich sind bestehende Objekte als unveränderlich angesehen und neue Objekte ersetzen sie folglich.
function updateCacheWithNewRating(beerId, cache, newRating) {
// Query, um bestehendes Beer-Objekt aus Cache zu lesen
const fragment = gql`
fragment ratings on Beer {
id ratings { id }
}`;
const existingBeer = cache.readFragment({
id: `Beer:${props.beerId}`,
fragment
});
// Beer aus Cache um neue Bewertung erweitern
const newBeer = {
...existingBeer,
ratings: [...existingBeer.ratings newRating]
}
// Verändertes Beer-Objekt in den Cache schreiben
cache.writeFragment({
id: `Beer:${props.beerId}`,
fragment,
data: newBeer
});
}
function Beer(props) {
return <div>
// . . .
<Mutation mutation={ADD_RATING_MUTATION}>
update={(cache, result) => updateCacheWithNewRating
(props.beerId, cache, result.data.newRating)} >
// siehe oben
</Mutation>
</div>;
}
Durch das Verfahren ist sichergestellt, dass der Client nach Ausführung einer Mutation die neusten Daten hat und sie konsistent in allen Bereichen der Anwendung darstellen kann, ohne die jeweiligen Queries neu ausführen zu müssen. Sofern die manuelle Verwaltung des Caches zu aufwändig ist, ist es ebenfalls möglich, über eine Property anzugeben, welche Queries Apollo nach der Ausführung der Mutation neu ausführen muss, um den Cache zu aktualisieren.
Wenn die Ausführung der Mutation mit hoher Wahrscheinlichkeit erfolgreich ist beziehungsweise das Ergebnis der Mutation sicher vorhersagbar ist, können Entwickler das Verfahren weiter optimieren. Dazu müssen sie der Funktion, die von der Mutation-Komponente an deren Child-Komponente übergeben wurde, beim Aufruf noch einen zweiten Parameter übergeben (im Beispiel der addNewRating-Funktion).
Der erste Parameter übergibt die Daten, die zum Server gelangen sollen. Mit dem zweiten Parameter (optimisticResponse) kann man ein Objekt übergeben, dass der erwarteten Antwort entspricht. Dieses Objekt verwendet die Mutation-Komponente, um während der Ausführung der Mutation den Cache und damit die Darstellung aktualisieren zu können, ohne auf das Ergebnis der Mutation vom Server zu warten. Der Benutzer erhält somit unmittelbares Feedback.
Weicht das später vom Server erhaltene Ergebnis von der optimisticResponse ab, aktualisiert die Anwendung den Cache und damit die UI ein zweites Mal, sodass danach in jedem Fall die korrekten Daten vorliegen. Da im Beispiel neue Objekte beziehungsweise Entitäten (Bewertungen) auf dem Server angelegt werden, deren IDs beim Absenden der Mutation nicht bekannt sind, scheidet die Variante allerdings aus.
Alternativen zu komponentenbasierten Abfragen
Die deklarative Programmierung mit Query- und Mutation-Komponenten entspricht zwar der React-Philosophie, kann aber in der Benutzung gewöhnungsbedürftig sein. Außerdem können die Komponentenhierarchien unübersichtlich sein, beispielsweise wenn eine Komponente mehrere Queries absetzen möchte. Als Alternative dazu kann man diegraphql-Higher-Order-Component (HOC) verwenden, mit der Nutzer Queries und Mutations samt ihrer Konfiguration aus der fachlichen Komponente herausziehen können, sodass sie sich auf die reine Darstellung der geladenen Daten konzentrieren können.
Eine weitere Alternative ist die withApollo HOC, die ein ApolloClient-Objekt in die ummantelte Komponente übergibt. Über dieses hat die Komponente Zugriff auf query- und mutation-Funktionen, die man nutzen kann, um GraphQL-Abfragen programmatisch auszuführen. Die oben geschilderten Features etwa hinsichtlich des Cachings bleiben weiterhin gültig, sodass alle gezeigten Ansätze innerhalb einer Anwendung beliebig kombiniert und gemeinsam genutzt werden können.
Typsichere Queries mit TypeScript
Eine GraphQL API ist immer mit einem Schema hinterlegt, aus dem hervorgeht, welche Queries und Mutations zulässig sind, welche Objekte die Operationen zurückgeben, und wie sie selber strukturiert sind. Das Schema einer API können Anwender mit einer standarisierten Query von der Schnittstelle abfragen. Aufbauend auf dem Feature gibt es die Möglichkeit, durch den Einsatz von TypeScript typsicher mit GraphQL-Schnittstellen zu arbeiten. Das bedeutet, dass zur Entwicklungszeit sichergestellt ist, dass eine Query mit den korrekten Variablen aufgerufen wird und deren Ergebnis eine gültige Verwendung findet (also zum Beispiel nicht auf Felder zugreift, die gar nicht abgefragt wurden).
Um es mit Typescript zu nutzen, müssen Entwickler zunächst Typen für die Queries beziehungsweise deren Variablen und Ergebnisse definieren. Die Typen kann man von Hand schreiben oder mit dem Apollo-Code-Generator automatisch erzeugen. Der Code-Generator liest zunächst das aktuelle Schema der API ein und generiert darauf aufbauend für alle Queries und Mutations der Anwendung die passenden Typen. Sie bestehen in der Regel aus einem Typen, der die Input-Variablen der Abfrage beschreibt sowie mehreren Typen, die das Ergebnis der Abfrage beschreiben. Eine generierte Typ-Definition sieht beispielsweise wie folgt aus:
interface BeerPageQuery_beer_ratings { . . . }
interface BeerPageQuery_beer_shops { . . . }
interface BeerPageQuery_beer {
id: string;
name: string;
price: string;
ratings: BeerPageQuery_beer_ratings[];
shops: BeerPageQuery_beer_shops[];
}
export interface BeerPageQuery {
beer: BeerPageQuery_beer | null;
}
export interface BeerPageQueryVariables {
beerId: string;
}
Die BeerPageQuery liefert ein Feld mit dem Namen beer zurück, dass vom Typ BeerPageQuery_beer oder null sein kann. Das BeerPageQuery_beer-Objekt ist ebenfalls auf Basis der Schemainformationen entstanden, ebenso alle weiteren abgefragten (Unter-)Objekte. Die generierten Typen passen immer genau zu einer konkreten Query, das heißt sie enthalten nur die Felder, die die API tatsächlich abfragt, und nicht alle Felder, die die Schnittstelle für ein Objekt grundsätzlich bereitstellt. Da die generierten Typen die Dokumentation aus der Schemabeschreibung enthalten, kann man sie in der IDE zum Beispiel über Code-Completion ebenfalls anzeigen.
Zur Verwendung der Typen können Entwickler sowohl die Query- als auch die Mutation-Komponente von Apollo in TypeScript mit Typinformationen anreichern. Das folgende Listing zeigt exemplarisch die BeerPage-Komponente, die die BeerPageQuery samt der generierten Typen verwendet:
function BeerPage(props: BeerPageProps) {
return <div>
<Query<BeerPageQueryResult, BeerPageQueryVariables>
query={BEER_PAGE_QUERY}
// TS kennt hier den Typ von 'variables':
variables={{ beer: props.beerId }}>
{({ loading, error, data }) => {
if (loading) { . . . }
if (error) { . . . }
// TS kennt die 'data'-Struktur und erzwingt null Prüfung
if (!data || data.beer === null) {
return <h1>Beer Not found</h1>;
}
// TS kennt die Struktur des Query Ergebnisses ('data')
// z.B. dass es dort ein 'beer'-Property gibt und wie dieses aussieht
return <Beer beer={data.beer} />
}}
</Query>
</div>;
}
Durch die Angabe der Typen weiß der Compiler nun genau, wie das variables-Objekt aussehen muss, sodass zur Build-Zeit sichergestellt ist, dass alle erforderlichen Variablen gesetzt und auch vom korrekten Typ sind. Außerdem kennt der Compiler den Typ des Ergebnisses und stellt sicher, dass beim Arbeiten mit dem Ergebnis-Objekt in der Anwendung nur Felder zur Verwendung kommen, die tatsächlich abgefragt wurden, und dass sie vor der Verwendung gegebenenfalls auf null geprüft sind. Die Verwendung der Mutation-Komponente erfolgt analog.

Sofern sich das Schema oder die Queries ändern, können Entwickler die Typen jederzeit neu generieren und die Anwendung erneut kompilieren, um sicherzustellen, dass die Queries weiterhin zum Schema passen und die Anwendung die Queries korrekt verwendet.
Fazit
Mit dem Apollo-Framework steht ein GraphQL-Framework für React und andere Web-Frameworks zur Verfügung, das eine Vielzahl von Anwendungsszenarien abbildet, inklusive Typisierung mit Typescript. Das Framework ist insbesondere bei React-Anwendungen weit verbreitet und gilt derzeit als Standard.
Apollo ist modular, sodass Entwickler nur die wirklich benötigten Teile daraus zur eigenen Anwendung hinzufügen müssen. Allerdings ist die Weiterentwicklung von Apollo schnell und durch die Modularisierung bringt es einen mitunter hohen organisatorischen Aufwand mit. Zum Beispiel wenn es darum geht, welche Versionen der einzelnen Module zusammenpassen oder welches Modul dafür verantwortlich ist, wenn etwas nicht funktioniert, welcher Bug-Tracker dafür der richtige ist oder auch wo die Dokumentation verortet ist.
Über die gezeigten Features hinaus enthält Apollo Funktionen zur Verwaltung des von GraphQL unabhängigen globalen Anwendungszustandes, ähnlich wie aus Redux bekannt. Ob das eine gute Idee und für das eigene Projekt sinnvoll ist, muss man im Einzelfall kritisch evaluieren, ebenso, ob einem der deklarative Programmierstil gefällt oder ob einer der anderen Ansätze gewählt wird.
Neben Apollo existieren einige weitere GraphQL-Frameworks für React, die zwar nicht die Verbreitung und das Feature-Set von Apollo haben, für eigene Anwendungen je nach Anforderung aber durchaus ausreichend sein können. Als Beispiele seien Relay oder urql genannt.
Nils Hartmann
ist Softwareentwickler und -architekt aus Hamburg. Er programmiert sowohl in Java als auch in JavaScript beziehungsweise TypeScript und beschäftigt sich mit der Entwicklung von React-basierten Anwendungen. Nils bietet dazu Schulungen und Workshops an.
(bbo)
