

Istio: Das Service-Mesh für verteilte Systeme
Verteilte Systeme und insbesondere Microservices bieten gegenüber einem Monolithen eine höhere Flexibilität, haben aber auch zusätzliche Anforderungen.

- Heiko W. Rupp
Jeder, der schon mal ein System implementiert hat, das aus mehreren Einzelteilen besteht, kennt das Problem: Die eine Komponente muss die andere finden, sie muss auf Fehler im Kommunikationsnetzwerk reagieren und zu guter Letzt sollte die Kommunikation über das Netzwerk auch noch verschlüsselt erfolgen.
In der Java-Welt hat sich dafür der Netflix-Stack etabliert, der einige der technischen Anforderungen erfüllt. Entwickler fügen ihn jeder Anwendung hinzu, sodass sich ein Szenario wie in der nächsten Abbildung ergibt.

Allerdings ist es nun so, dass zum einen alle Dienste den Stack mitbringen und aktuell halten müssen. Zum anderen funktioniert das nur so lange gut, wie alle Dienste in Java oder anderen Umgebungen implementiert sind, für die es einen vergleichbaren Stack gibt. Populäre Sprachen wie Shell-Skripte oder Perl haben es schwer.
Das Projekt Istio geht einen anderen Weg. Jede Anwendung verfügt über ein Proxy Envoy, über den die Kommunikation erfolgt. In Umgebungen wie Kubernetes läuft er in einem eigenen Container im selben Pod wie die Anwendung. Es ist aber auch möglich, Envoy direkt als Prozess auf einer (virtuellen) Maschine laufen zu lassen, um damit eine Anwendung in das Mesh einzubinden.
Istio auf der ContainerConf
Auf der vom 13. bis 16. November stattfindenden ContainerConf in Mannheim ist das Service-Mesh Istio ebenfalls ein Thema. Sowohl in einem Vortrag des Artikelautors als auch in einem ganztägigen Workshop erfahren Teilnehmer alles, was sie über Istio wissen müssen. Bis zum 21. September ist die Anmeldung zu Frühbucherkonditionen möglich.
Die Kommunikation zwischen den Diensten erfolgt zwischen den beteiligten Proxies. In einer Anwendung müssen Entwickler die technischen Aspekte (fast) nicht mehr berücksichtigen, da der Proxy das erledigt – dazu aber später mehr. Im Moment stellt sich nur noch die Frage, wie die Proxies wissen, mit welchem anderen Proxy sie reden müssen und ob die Kommunikation verschlüsselt sein soll.
Istio bedient sich dafür einer so genannten Controlplane, die aus mehreren Komponenten besteht. Der Pilot verteilt die Konfiguration auf die Proxies, der Mixer nimmt Telemetriedaten entgegen und Citadel sorgt für die Verteilung der TLS-Zertifikate an die einzelnen Proxies. Wie vielleicht vermutet, ist nur der Pilot zwingend notwendig, Mixer und Citadel können Nutzer in einem kleinen Setup weglassen. Neben dem Kern an Diensten bietet Istio noch eigene Ingress- und Egress-Gateways für die Kommunikation mit der Welt außerhalb des Meshes. Und schließlich sorgt Galley für die Validierung der übergebenen Konfiguration. Darauf geht der Artikel später noch ein. Damit gibt sich das folgende Bild der Komponenten:

Anfragen der Nutzer gehen (idealerweise) über das Ingress-Gateway und dann zum Proxy im Ziel-Pod, in diesem Fall zu Alice. Möchte ein Dienst wie Bob ein externes System (zum Beispiel einen entfernten Webdienst) kontaktieren, kann er diesen über das Egress-Gateway ansprechen. Damit Istio die Kontrolle über den Verkehr im Netz regeln kann, ist bei der Installation in Kubernetes noch sicherzustellen, dass es keine anderen Gateways gibt, die ihrerseits eingehende Daten direkt an Services leiten und das Ingress-Gateway umgehen.
Wie lassen sich Dienste in Istio aufnehmen?
Wie kann man nun einen Dienst in Istio aufnehmen? Wie bereits beschrieben, läuft Envoy in einem separaten Container im Pod. Damit muss also der Pod mit dem Proxy angereichert werden. Das kann auf zwei Arten geschehen.
Der Deployment-Deskriptor für den Pod muss die Daten für den Proxy erhalten. Das geht beim Deployen der Anwendung mit dem istioctl-Werkzeug:
----
$ istioctl kube-inject -f original.yaml | kubectl apply -f -
----
Alternativ ist es denkbar, Kubernetes so zu konfigurieren, dass die Projekte bei Namespaces automatisch ein Proxy erhalten, wenn sie ein bestimmtes Label haben:
----
$ kubectl label namespace myproject istio-injection=enabled
----
Nach dem Deployment sollte kubectl get pods zwei aktive Container im Pod anzeigen.
----
$ kubectl get pods
NAME READY STATUS
bob-deployment-b878ff5b5-5js9c 2/2 Running
$ kubectl describe pod bob-deployment-b878ff5b5-5js9c
Name: bob-deployment-b878ff5b5-5js9c
[...]
Init Containers:
istio-init:
[...]
Containers:
bob:
[...]
istio-proxy:
----
Es gibt streng genommen noch einen weiteren Container im Pod, der sofort nach getaner Arbeit wieder terminiert. Mit dem Init-Container lassen sich die die Routing-Regeln im Pod (via iptables) so ändern, dass die Kommunikation über den Proxy geleitet wird. Hierzu benötigt er aktuell (noch) erweiterte Privilegien. Das sorgt in vielen Unternehmen für Stirnrunzeln: Normalerweise versucht man dort, die Privilegien möglichst einzuschränken.
Namen bitte ...
Um die Istio-Welt für Benutzer etwas spannender zu machen, haben die Macher neue Konzepte und Namen eingeführt (das Problem ist wohl eher, dass die Kubernetes-Welt sich bisher noch nicht auf einheitliche Wege geeinigt hat, Labels anzuwenden, um zum Beispiel eine Applikation zu kennzeichnen). Eine "Workload" bezeichnet einen oder mehrere Pods, die alle dieselben Labels haben. Üblicherweise ist das ein Deployment, das skaliert worden sein kann.
"Services" können auf eine oder mehrere Workloads zeigen und sie als Workload(s) für Clients zur Verfügung stellen. "Applikationen" sind Workloads, die dasselbe "app"-Label haben. Sie können durchaus unterschiedliche Versionen haben (beispielsweise für ein A/B-Deployment).
Ein Weg von A nach B
Wie kann man nun Istio für Content-Based-Routing, Load-Balancing oder Canary-Deployments nutzen?
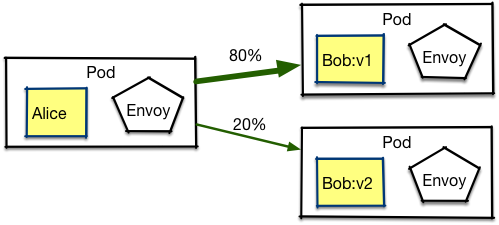
Zunächst muss man die beiden Ziele mit DestinationRules definieren:
.DestinationRule für den BobService
----
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: BobService
spec:
host: BobService
subsets:
- name: Bob1
labels:
version: v1
- name: Bob2
labels:
version: Bob
----
Die beiden Subsets in der Definition bestimmen je eine Workload, die via Name (BobService) und Label (v1, v2) zu identifizieren sind. Im nächsten Schritt dienen die Regeln als Ziele für einen VirtualService:
.Asymetrisches Loadbalancing
----
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: Balance-Bob
spec:
hosts:
- BobService
http:
- route:
- destination:
host: BobService
subset: Bob1
weight: 80
- destination:
host: BobService
subset: Bob2
weight: 20
----
Die Dokumente kann man wie gewohnt via kubectl apply -f <datei> an Kubernetes senden, wo der Pilot sie aufgreift und die entsprechenden Proxies konfiguriert. Allerdings ist es dadurch auch möglich, eine ungültige Konfiguration zu erzeugen. Im obigen Beispiel ist das der Fall, wenn die Gewichte der einzelnen Routen nicht 100 Prozent ergeben. Nutzt man hingegen istioctl create oder istioctl replace um die Konfiguration zu übergeben, hilft Galley beim Validieren und gibt eine Fehlermeldung aus (seltsamerweise wird die ungültige Konfiguration aktuell trotzdem akzeptiert).
Auf eine ähnliche Weise kann der Verkehr für angemeldete Besucher oder einen bestimmten Browser an eine Version eines Dienstes geleitet werden und der restliche Verkehr an eine andere Version. Damit kann man beispielsweise Anfragen von Internet Explorer 6 an eine andere (alte) Version der Anwendung senden als den Verkehr von zeitgemäßen Browsern.
Die Fähigkeiten des Routing hören hier noch lange nicht auf. Es ist außerdem denkbar, den Datenverkehr zu duplizieren, um eine neue Version einer Applikation mit den (Live-)Daten zu testen.
Allerdings ist das auf Inhalten basierende Routing davon abhängig, was Envoy unterstützt. Aktuell sind das unter Anderem HTTP, HTTP/2, gRPC, Redis, MongoDB und DynamoDB. Es steht zu erwarten, dass in Zukunft noch mehr Protokolle hinzukommen.
Fehlertoleranz
Wie bereits erwähnt, müssen verteilte Systeme auf Ausfälle einzelner Komponenten oder des Verbindungsnetzwerks reagieren können.
Es ist möglich, über eine HTTP-Retry-Regel Istio anzuweisen, dass der Aufruf im Fehlerfall erneut geschehen soll:
.Retry-Logik in Istio
----
kind: VirtualService
metadata:
name: Bob-Retry-Service
spec:
hosts:
- BobService
http:
- route:
- destination:
host: BobService
retries:
attempts: 3
perTryTimeout: 2s
----
Das Beispiel versucht, den BobService bis zu drei Mal aufzurufen, jedes Mal mit einer Wartezeit von bis zu zwei Sekunden. Ebenso kann man über eine Circuit-Breaker-Regel Istio anweisen, Versuche das Backend zu erreichen für eine Zeit zu unterbinden, wenn bei vorherigen Aufrufen zu viele Fehler vorkamen.
Absichtlich Fehler machen
Istio bietet die genannten Mechanismen zum Schutz gegen Ausfälle an, aber letztlich muss die Anwendung doch darauf reagieren können. Um diese Reaktionen testen zu können, bietet Istio die Funktion an, Fehler in den Datenstrom zu injizieren.
.Injection von 25 Prozent 404-Fehlern
----
kind: VirtualService
metadata:
name: Bob-Fehler-Service
spec:
hosts:
- BobService
http:
- fault:
abort:
percent: 25
httpStatus: 404
route:
- destination:
host: BobService
----
Man sieht, dass der aufrufende Service sich nicht alle Funktionen zur Fehlervermeidung sparen kann. Liefert der aufgerufene Dienst einen Fehler zurück, den Istio nicht korrigieren konnte, ist es trotzdem notwendig auf den 404-Code zu reagieren und entsprechenden Fallback-Code auszuführen (oder man reicht den Fehlercode an den Aufrufer durch).
Observability
Wie oben beschrieben, erfolgt nun die Kommunikation über die Proxies. Diese können nun mitloggen, wie viele Requests über sie erfolgen, welche Latenz vorliegt und wie viele Bytes transferiert werden. Diese Daten liefern die Proxies an den Mixer, der sie in einer Prometheus-Datenbank speichert. Istio bietet einige Grafana-Dashboards an, die einen Überblick über den Traffic geben können.
Ebenso ermöglicht es die Nachverfolgung der Aufrufe durch das Mesh. In einem Monolithen nimmt man dafür gerne einen Profiler und lässt sich den Call-Graph anzeigen. Die Funktionen in Istio entsprechen einem verteilten Profiler, auch bekannt als Distributed Tracing. Schön ist dabei, dass die Plattform das Tracing fast direkt bereitstellt. Damit ist es nicht notwendig, die Anwendung zu modifizieren. Die Runtime muss allerdings, wie im Artikel beschrieben, die Tracing-Header weiterleiten, damit das Tracing von Ende zu Ende funktioniert. Es ist aber möglich, in der Anwendung zusätzliche Trace-Informationen zur Verfügung zu stellen, die man in die Traces von Istio einbaut.
Da Routinginformationen dynamisch sein können, lässt sich allein durch die Konfiguration nicht immer nachvollziehen, welchen Weg ein Aufruf genommen hat, und wo welche Latenz aufgetreten ist. Istio bietet, wie auch bei den Metriken, keinen eigenen Server für die Verarbeitung der Tracing-Daten, sondern erlaubt es, Daten im Zipkin- oder Jaeger-Format an die entsprechenden Systeme zu senden.
Und was tut nun das Mesh?
Die Stärke eines Service-Mesh ist zugleich seine größte Schwachstelle: Die hohe Flexibilität und Fülle an Aufgaben führt zu einer erhöhten Komplexität in der Konfiguration. Probleme lassen sich nicht mehr einfach in einem einzelnen Logfile finden, sondern die verteilte Natur macht es notwendig, mehrere Stellen zu observieren, um Probleme oder Flaschenhälse zu erkennen. Das bereits genannte Tracing und die Metriken können helfen, allerdings ist das nicht genug. Ein Werkzeug wie Kiali kann weiterhelfen, da es die vorhandenen Daten zusammenfasst, die Topolologie des Meshes visualisiert und Fehler direkt in der Topologie darstellt.

Wo Sonne ist, ist auch Schatten
Istio 1.0 wurde am 31. Juli 2018 freigegeben. Das Entwicklerteam bezeichnet die Version als "reif für die Produktion". Jakub Pavlik hat diese Aussage einem Härtetest unterzogen und listet einige Probleme auf. Manche davon sind sicherlich für viele Anwendungsfälle weniger problematisch (zum Beispiel dass die Möglichkeit, mehrere Kubernetes-Cluster zu überspannen, eher rudimentär ist).
Andere Kritikpunkte sind schwerwiegender, allen voran die 51 neuen API-Objekte, die für die Konfiguration zur Verfügung stehen. Natürlich erlauben sie eine ungeahnte Flexibilität, aber zum Preis einer hohen Komplexität und initial hohen Lernaufwands. Es steht zu erwarten, dass Werkzeuge wie Kiali in Zukunft mit Wizards und anderen grafischen Elementen beim Erstellen und der Pflege der Konfigurationen helfen werden.
Auch ist man gewohnt, dass Kubernetes-Health-Checks via HTTP auf spezielle Endpunkte im (Applikations-)Container zugreifen, um zu überprüfen, ob die Anwendung gesund ist oder neu gestartet werden muss. Nutzt man Istio mit TLS zwischen den Pods, funktioniert das nicht mehr, da das Kubelet, das diese Checks durchführt, nicht Teil des Meshes ist und damit auch nicht am mTLS teilnimmt.
Ein Health Check via TCP/http ist nicht möglich. Kubernetes kann auch Skripte ausführen und deren Return-Code auswerten. Dafür muss man aktuell auf einen anderen Mechanismus zurückgreifen. Der Container muss ein Skript/Programm zur Verfügung stellen, dessen Aufruf die Information über den Gesundheitszustand der eigentlichen Applikation im Container gibt. Kubernetes ruft dann regelmäßig das Programm im Ziel-Container auf und wertet den Exit-Code aus. Das zieht leider eine erhöhte Last im Anwendungscontainern nach sich.
Und zu guter Letzt erkauft man sich die Leistungsfähigkeit von Istio durch einen erhöhten Einsatz von Ressourcen. Zum einen fügt jeder Proxy in der Kette etwas Latenz hinzu. Zum Anderen benötigt er zusätzliche CPUs und Speicherplatz. In der Praxis werden die letzten Punkte sicherlich davon aufgewogen, dass die Applikation die von Istio mitgebrachten Funktionen nicht benötigt und dadurch schlanker wird.
Fazit
Istio ist eine sehr spannende Technik, die auf der Plattformebene viele Funktionen auf deklarative Weise anbietet, für die sonst eine Menge an Programmierung und diskreter Konfiguration notwendig sind. Das Interesse ist groß und erste Frameworks wie Knative nutzen Istio bereits als Basis. Diese Kraft erkauft man sich durch einen hohen Lernaufwand und einen etwas erhöhten Ressourceneinsatz. Das Istio-Team bezeichnet die Version 1.0 als reif für die Produktion. Es scheint allerdings angebracht, sich dem Thema erst in einem Testbed zu nähern und auf die ersten Bugfix-Releases zu warten.
Heiko Rupp
ist seit langer Zeit ein Open-Source-Enthusiast und arbeitet seit mehr als einem Jahrzehnt bei Red Hat im Bereich Middleware-Monitoring und -Management. Aktuell hilft er, die nächste Generation von Java Microservices mit seiner Arbeit in Eclipse MicroProfile, zu definieren. Parallel dazu arbeitet er an Kiali, einer Lösung zur "Observability" im Istio Service Mesh.
(bbo)
