

Java-Anwendungen mit GraphQL, Teil 1
Alle reden von GraphQL: Dass die Abfragesprache auch mit Java-Anwendungen funktioniert, zeigt dieser Artikel.

- Nils Hartmann
Effizient Daten austauschen und gleichzeitig einfach in der Entwicklung sein – das verspricht die Abfragesprache GraphQL, die seit 2015 quelloffen zur Verfügung steht. Auch prominente Unternehmen wie Twitter, GitHub oder die New York Times setzen sie ein. Grund genug, einen genaueren Blick auf sie zu werfen.
GraphQL ist zunächst eine Spezifikation, in der die Definitionsweise von APIs beschrieben ist. Außerdem ist dort definiert, wie Clients Abfragen beschreiben und ausführen können und wie Server sie verarbeiten und beantworten müssen. Es handelt sich also nicht um ein fertiges Produkt oder Framework. Allerdings gibt es eine offizielle Referenzimplementierung, die in JavaScript geschrieben ist, und eine Reihe von Frameworks und Tools für eine Vielzahl von Sprachen, die es ermöglichen, GraphQL in eigene Anwendungen zu integrieren.
Die grundlegende Idee hinter GraphQL ist, dass ein Client immer genau die Daten abfragen kann, die er für einen Anwendungsfall, zum Beispiel eine Ansicht im UI, braucht. Das soll zum einen Netzwerk-Requests und Datenvolumen optimieren, da der Client weder zu viele noch zu wenige Daten lesen oder schreiben muss. Zum anderen soll es die Entwicklung einfach und flexibel halten. Der Server stellt beliebige Daten über eine API zur Verfügung. Dabei müssen müssen Entwickler allerdings nicht auf die konkreten Anforderungen eines Clients achten, da jeder Client individuell die für ihn relevanten Daten abfragen muss.
Ein Beispiel
Zur Veranschaulichung dazu dient eine kleine Beispielanwendung, in der Nutzer ihre Lieblingsbiere bewerten können. Der Quellcode ist auf GitHub verfügbar. Die Anwendung besteht clientseitig aus drei Ansichten (Seiten), die auf unterschiedliche Teile derselben Entitäten aus dem Domain Model zugreifen. Die Übersichtsseite zeigt nur den Namen der Biere (Entity Beer) und deren durchschnittliche Bewertung an. Die Detailansicht eines Biers stellt hingegen ebenfalls den Preis des Biers dar, aber zusätzlich auch dessen Bewertungen (Entities Rating und User) und die Namen der Geschäfte (Entity Shop), in denen es erhältlich ist. Die Geschäftsseite zeigt wiederum alle Informationen zu einem Geschäft, aber nur den Namen der dort erhältlichen Biere und nicht deren Bewertungen.

Abfragen mit GraphQL ausführen
Wie beschrieben ist die zentrale Idee von GraphQL, genau bestimmte Daten vom Server zu lesen. Dazu führt GraphQL Abfragen aus, die aus einer oder mehreren Operationen bestehen. Eine Operation kann das Lesen von Daten sein (Query), die Veränderung von Daten auf dem Server (Mutation) oder das Registrieren für Events, die der Server auslöst und an den Client schickt (Subscription).
Abfragen in GraphQL bestehen immer aus einer Menge an Feldern, die die GraphQL-Schnittelle auf dem Server liest. Darin können Anwender eine ganze Hierarchie von Feldern aus Objekten erfragen. Die Abfrage sieht ähnlich wie ein JSON-Objekt aus, ist aber ein regulärer String. Das folgende Beispiel zeigt die Query, die Namen und durchschnittliche Bewertung für alle Beer-Objekte lädt, um die Übersichtsseite der Anwendung darzustellen:
query OverviewPageQuery {
beers {
name
averageStars
}
}
Die Detailansicht eines Biers in der Anwendung benötigt andere Daten, beispielsweise die Bewertungen und von den Bewertungen wieder den Autor. Eine Query kann solche Informationen ebenfalls herausfinden. Neu ist im folgenden Listing, dass der Code Felder aus einer Hierarchie von Objekten abfragt. Außerdem erhält ein Feld (beer) ein Argument (ähnlich wie in Java bei Methoden).
query BeerViewQuery {
beer(beerId: "B1") {
name
ratings {
comment
author {
name
}
}
shops { . . . }
}
}
Damit der Client die Query für unterschiedliche Werte nicht jedes Mal neu zusammenbauen muss, kann die Query ebenfalls Argumente entgegennehmen und an ein oder mehrere Felder innerhalb der Abfrage weiterreichen. Im folgenden Beispiel erwartet die Query die Id eines Beer-Objekts, die an das beer-Feld weitergereicht wird. Dank der Verwendung von Argumenten muss der Client den Query-String nur einmal zusammenbauen, unabhängig davon, welche Werte die einzelnen Felder abfragen. Der Server erhält die Werte für die Query (im Beispiel unten: $beerId) in einem gesonderten Objekt. Somit sind auf dem Server Optimierungen denkbar – wie für das Parsen der Query.
query BeerViewQuery($beerId: ID!) {
beer(beerId: $beerId) {
... alles weitere wie oben ...
}
}
Eine Abfrage in GraphQL besteht folglich aus einer hierarchischen Struktur von Feldern. Ein GraphQL-fähiger Server erhält die Abfrage. Das erfolgt in der Regel per HTTP-POST-Request an einen zentralen Endpunkt. Dieser nimmt die Anfrage entgegen, verarbeitet sie und liefert das Ergebnis zurück. Das folgende Kommando zeigt beispielhaft, wie man mit dem Kommandozeilen-Tool curl eine GraphQL-Abfrage ausführen kann.
curl -X POST -H "Content-Type: application/json" \
-d '{"query":"{ beers { id name } }"}'
http://localhost:9000/graphql
Ergebnis der Abfrage
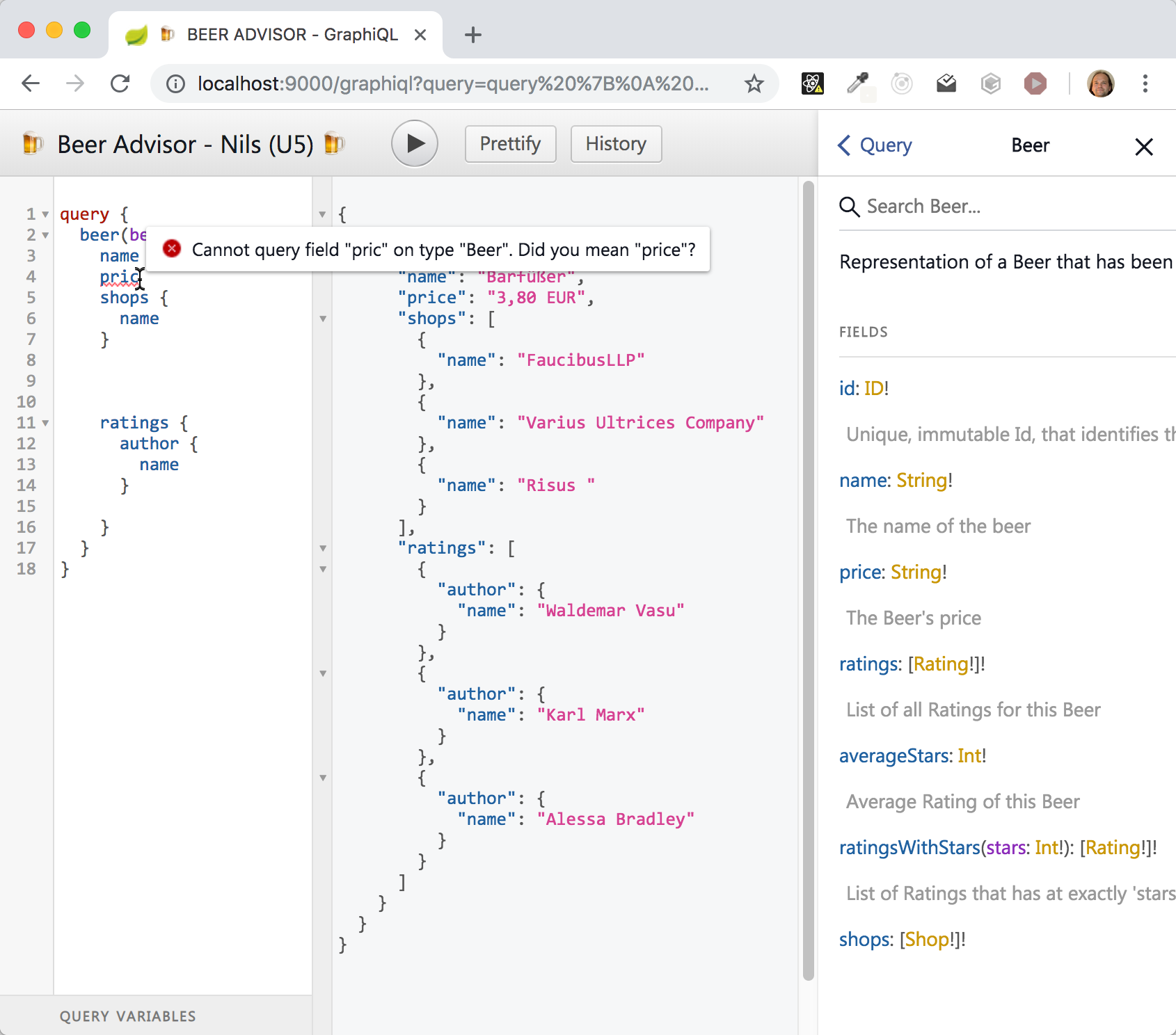
Das Ergebnis der Abfrage ist ein JSON-Objekt, das laut Spezifikation auf Root-Ebene ein data-Feld und/oder ein errors-Feld enthalten muss. Fehler, die bei der Ausführung aufgetreten sind, landen im Feld errors. Das data-Feld enthält bei erfolgreicher Ausführung die abgefragten Daten, deren Hierarchie identisch mit der Abfrage ist. Der Client weiß daher durch die Formulierung seiner Abfrage, wie die Antwort vom Server strukturell aussieht. Eine exemplarische Antwort auf die oben gezeigte BeerViewQuery ist in der folgenden Abbildung zu sehen – die Hierarchie unterhalb von data entspricht genau der abgefragten Struktur der Query.

Möchte der Client Daten auf dem Server verändern (oder erzeugen oder löschen), führt er eine Mutation aus. Die Abfrage dazu ist fast identisch zu einer Query, nur dass sie als Operation-Typ mutation angibt. Der Client übergibt der Mutation alle Daten, die der Server benötigt, um die Aktion erfolgreich auszuführen. Aus dem spezifischen Ergebnis einer Mutation kann der Client wiederum – genau wie bei einer Query – einzelne Felder auswählen, die er vom Server als Antwort benötigt. Im Beispiel können Nutzer über eine Mutation eine neue Bewertung (Rating) für ein Bier abgeben. Dazu muss der Client Informationen wie den Kommentar und den Benutzer übergeben. Für die Antwort wählt der Client lediglich das id-Feld aus (das auf dem Server für das neue Rating-Objekt generiert wurde).
mutation AddRatingMutation {
addRating(beerId: "B1", userId: "U2", comment: "tasty", stars: 3) {
id
}
}
Auch der dritte Operation-Typ, die Subscription, arbeitet nach dem gleichen Muster. Die Besonderheit ist, dass der Server nicht einmalig Daten an den Client zurückschickt, sondern, solange die Verbindung besteht beziehungsweise die Subscription nicht abgebrochen wird, dem Client immer neue Daten liefert, sobald sie auf dem Server zur Verfügung stehen. Der Vollständigkeit halber zeigt das nächste Listing noch eine Subscription, mit der sich ein Client über neue Bewertungen informieren lassen kann. Der Client kann wählen, welche Felder er beim Eintreffen eines Events benötigt, sodass er nur die Daten erhält, die für ihn relevant sind:
subscription RatingSubscription($beerId: ID!) {
rating: newRatings(beerId: $beerId) {
id
stars
beer {
id
}
author {
name
}
comment
}
}
Das Schema: Beschreibung der API
Woher weiß der Client nun, welche Objekte und Felder es auf dem Server überhaupt gibt? Welche Queries er ausführen kann und welche Mutations mit welchen Parameter vorhanden sind? Dazu muss man die GraphQL API, die der Server zur Verfügung stellt, mit einem Schema beschreiben.
Das ist zwingend erforderlich. Je nach eingesetzter Programmiersprache und Framework gibt es dazu mehrere Möglichkeiten. Der gängigste Weg zur Beschreibung des Schemas ist mittlerweile die Schema Definition Language (SDL), die im Juni 2018 auch den Weg in die GraphQL-Spezifikation geschafft hat.
Ein Schema beschreibt die Objekte (in GraphQL Object Types genannt) mitsamt ihren Feldern, die Entwickler über die API abfragen können. Da GraphQL eine typsichere Sprache ist, muss man die Felder mit Typen versehen. Es gibt einige eingebaute skalare Typen, wie ID, String, Int, Boolean und außerdem Arrays beziehungsweise Listen. Die Definition eines eigenen, fachlichen Object Types könnte wie folgt aussehen:
type Rating {
id: ID!
beer: Beer!
author: User!
comment: String!
stars: Int!
}
Das Listing definiert zunächst den Typ Rating, der aus fünf Feldern besteht. Jedes Feld erfordert neben dem Namen den jeweiligen Typ. Dazu gehört auch, ob das Feld ein Pflichtfeld ist oder nicht (gekennzeichnet mit einem Ausrufezeichen) oder ob es sich um ein Array handelt (dann wäre der Feld-Typ mit eckigen Klammern umschlossen). Die Felder beer und author zeigen auf weitere Objekttypen.
Neben den Objekttypen besteht ein Schema noch aus Operationen, die Anwender über die API ausführen können – das sind die Queries, Mutations und Subscriptions.
In einem GraphQL-Schema heißen die Operationen Root Operation Types, die syntaktisch genauso wie Object Types in der SDL beschrieben sind und ebenfalls aus einer Menge an Feldern bestehen:
type Query {
beer(beerId: ID!): Beer
beers: [Beer!]!
}
type Mutation {
addRating(ratingInput: AddRatingInput): Rating!
login(username: String!): LoginResponse!
}
type Subscription {
onNewRating(beerId: ID!): Rating!
}
Am Query Type ist ein Feld beer definiert. Daran ist die Beschreibung von Argumenten für Felder zu sehen. Für Argumente müssen Entwickler einen Namen und den Typ angeben und festlegen, ob die Angabe des Arguments Pflicht ist.
Während Mutation und Subscription in einem Schema optional sind, ist zumindest die Definition des Query Type notwendig. Genau genommen können die drei Typen übrigens andere Namen tragen, in der Praxis ist es aber eine gute Idee, sich an die Namenskonventionen zu halten.
Die Root Operation Types sind bei einer Abfrage der Einstiegspunkt in eine API. Sie geht immer von einem Feld aus, das innerhalb eines der Root Operation Types definiert ist. Von dort aus kann dann weiter transitiv über alle referenzierten Types gewandert werden.
Bei der Ausführung einer Query stellt die GraphQL-Laufzeitumgebung sicher, dass Queries, die ein Client versendet, mit dem Schema kompatibel sind. Queries, die ungültig sind, weil sie zum Beispiel nicht existierende Felder abfragen, die gar nicht existieren, führt die Anwendung nicht aus. Ähnlich verhält es sich mit dem Ergebnis der Query: Der Client bekommt die Daten nur zurückgeschickt, wenn die Antwort dem Schema entspricht. Ebenfalls wird überprüft, ob Pflichtfelder wirklich befüllt sind und ob die zurückgegebenen Felder den erwarteten Typen entsprechen. Dadurch können sowohl Server als auch Client sicher sein, dass sie es nur mit syntaktisch korrekten Daten zu tun haben.
Introspection und Tooling
Das Schema einer GraphQL API kann zur Laufzeit eine reguläre GraphQL Query vom Server abfragen. Die Query heißt Introspection Query und ist mit der Reflection API von Java vergleichbar.
Die Möglichkeit, das Schema zur Laufzeit abzufragen, ermöglicht eine Vielzahl von Tools für das Arbeiten mit GraphQL APIs. Es gibt mit GraphiQL einen Browsereditor, mit dem Nutzer GraphQL Abfragen schreiben und ausführen können. GraphiQL fragt das jeweilige Schema einer API ab und bietet mit den Informationen Features wie Code-Completion und Syntax-Highlighting und -Validierung an. Den Editor können Entwickler übrigens in die eigene GraphQL-Anwendung integrieren, um zum Beispiel zur Entwicklungszeit Queries auszuprobieren.
Neben dem Editor gibt es unter anderem ein GraphQL-Plug-in für IntelliJ IDEA sowie eine GraphQL-Erweiterung für Visual Studio Code. Mit beiden ist das Schreiben und Ausführen von Queries direkt in der IDE möglich – Code-Completion und Syntax-Checking im eigenen Sourcecode inklusive.

GraphQL-Backends in Java
Um GraphQL-Abfragen zu verarbeiten, bedarf es eines Servers, der eine GraphQL API zur Verfügung stellt. Entwickler verwenden für Java-basierte GraphQL-Anwendungen die Projekte java-graphql-tools und graphql-java-servlet oder graphql-spring-boot, wenn im eigenen Projekt Spring Boot zum Einsatz kommt. Diese Projekte abstrahieren ihrerseits das graphql-java-Projekt, das die eigentliche GraphQL Funktionalität implementiert und auch direkt verwenden werden kann.
Das java-graphql-tools-Projekt stellt die grundlegenden Mittel zu Verfügung, um eine GraphQL-API im eigenen Projekt zu implementieren. Dafür muss man zunächst das Schema der API wie oben gezeigt mit der SDL beschreiben und im Projektverzeichnis ablegen, sodass das GraphQL-Framework es zur Laufzeit einlesen kann. Das vollständige Schema der Anwendung befindet sich im GitHub-Repository.
Implementierung von Resolvern
Im nächsten Schritt müssen Entwickler Resolver implementieren. Das sind Java-Klassen, die sich um das Laden der Daten für ein Feld aus dem Schema kümmern. Für jeden Root Object Type (also Query, Mutation und Subscription), der im Schema vorhanden ist, ist die Implementierung einer eigene Klasse notwendig, die ein Marker-Interface (zum Beispiel GraphQLQueryResolver) implementiert. Innerhalb der Klasse müssen Entwickler für jedes Feld des jeweiligen Root Object Type eine Methode implementieren, die den Wert für das Feld bei einer Anfrage zurückliefert. Sind für ein Feld im Schema Argumente definiert, muss die Methode für jedes der Argumente einen Parameter definieren. Der Rückgabe-Typ der Methode muss ebenfalls dem Schema entsprechen, also ein Objekt zurückliefern, dessen Properties zumindest grundsätzlich den Feldern aus dem Object Type entsprechen.
Für den oben gezeigten Root Object Type Query, der zwei Felder (beer und beers) enthält, könnte der dazugehörige Resolver wie folgt implementiert sein:
public class BeerQueryResolver implements GraphQLQueryResolver {
private final BeerRepository beerRepository;
public BeerAdvisorQueryResolver(BeerRepository beerRepository) {
this.beerRepository = beerRepository;
}
public Beer beer(String beerId) {
return beerRepository.getBeer(beerId);
}
public List<Beer> beers() {
return beerRepository.findAll();
}
}
Wenn der Server eine Anfrage entgegennimmt, delegiert er die Anfrage zunächst an die Methode in der Resolver-Klasse. Die Klasse ermittelt, welches Objekt (oder Objekte) etwa durch eine Datenbankabfrage zurückgeliefert werden muss. Hat der Client vom zurückgelieferten Objekt Felder abgefragt, sucht eine Reflection am Objekt entsprechende Felder und liefert sie zurück. Die Beer-Klasse kann daher zum Beispiel ein reguläres POJO oder, wie im Beispiel, eine JPA Entity sein.
Resolver für Mutations und Subscriptions implementiert man analog, nur dass sie andere Marker-Interfaces implementieren. Bei Subscriptions ist zu beachten, dass als Rückgabewert der Methode ein Reactive-Streams-Publisher-Objekt zurückgeliefert werden muss.
Das folgende Listing zeigt exemplarisch einen Ausschnitt aus dem Mutation-Resolver, der ein neues Rating entgegen nimmt und in der Datenbank speichert:
public class BeerAdvisorMutationResolver implements GraphQLMutationResolver {
private final BeerRepository beerRepository;
public BeerAdvisorMutationResolver(BeerRepository beerRepository) {
this.beerRepository = beerRepository;
}
public Rating addRating(AddRatingInput addRatingInput) {
Beer beer = beerRepository.getBeer(addRatingInput.getBeerId());
Rating rating = beer.addRating(
addRatingInput.getUserId(),
addRatingInput.getComment(),
addRatingInput.getStars()
);
beerRepository.saveBeer(beer);
return rating;
}
}
Über die gezeigten Root-Resolver findet der Einsprung im Objektmodell statt. Der Root-Resolver liefert ein Objekt zurück, das – wie gezeigt – zum Beispiel eine JPA Entity sein kann. Auf die im Objekt abgefragten Felder greift eine Reflection zur Laufzeit zu (vergleichbar etwa mit dem Verhalten von Template- oder Expression-Languages, bei denen häufig eine Punktnotation die Navigation über Objektgraphen ermöglicht).
Mit Field-Resolvern Daten vom Domain Model ermitteln
Um das Verhalten zu verändern, lassen sich für einzelne Felder sogenannte Field-Resolver schreiben. Sie liefern den Wert für ein Feld an einem konkreten Object Type aus dem Schema. Das ergibt beispielsweise Sinn, wenn das POJO nicht über ein Feld verfügt, dass im Schema definiert ist oder das Feld von einem anderen (Java-)Typen als im Schema ist.
Field-Resolver kann man ähnlich wie Root-Resolver implementieren. Zunächst ist dafür das Interface GraphQLResolver hinzuzufügen. Das Interface erwartet als Type-Parameter die Java-Klasse, für die es Felder auflösen soll. Die Methoden in der Klasse müssen wieder den Feldnamen aus dem Schema entsprechen. Als Parameter übergibt das Framework zunächst das Objekt, auf dem das Feld ermittelt werden soll. Als weitere Parameter kommen die im Schema definierten Argumente hinzu.
Im Beispiel gibt es das Feld averageStars zwar im Schema am Object Type Beer, aber nicht an der entsprechenden Java-Klasse. Um das Feld über GraphQL anzubieten, implementiert man dafür einen Field-Resolver.
public class BeerFieldResolver implements GraphQLResolver<Beer> {
public int averageStars(Beer beer) {
return (int)
Math.round(
beer.getRatings().
stream().mapToDouble(Rating::getStars).
average().getAsDouble()
);
}
}
Der BeerQueryResolver liefert zur Laufzeit zunächst eine Instanz des Beer-Objekts zurück (Einstiegspunkt des Query, entweder über das Feld beer oder beers). Wenn der Client daraufhin das Feld averageStars abfragt, ruft das die gleichnamige Methode BeerFieldResolver auf. Die vom Root-Resolver zurückgelieferte Beer-Instanz ist der erste übergebene Parameter, der zweite der vom Client angegebene Parameter stars. Auch der Resolving-Prozess funktioniert auf jeder Ebene der Abfrage. Wenn entweder das Beer-Objekt oder der BeerResolver ein weiteres POJO zurückliefert (zum Beispiel Rating), können Entwickler hierfür wieder individuelle Field-Resolver schreiben. Gibt es für ein Feld keinen Field Resolver, liest die Anwendung den Wert per Reflection aus dem Objekt.
Das GraphQL-Servlet
Wenn Schema und Resolver definiert sind, kann der Server GraphQL Abfragen ausführen. Dazu muss man zunächst eine Instanz eines "ausführbaren" Schemas (ExecutableSchema) erzeugen, die aus der Schema-Beschreibung (SDL) und den Resolvern besteht. Mit dem Schema können Entwickler GraphQL-Abfragen innerhalb des Servers ausführen, wie das folgende Listing zeigt:
// Beispiel: GraphQLSchema erzeugen
GraphQLSchema graphQLSchema = SchemaParser.newParser() //
.file("beeradvisor.graphqls")
.resolvers(beerAdvisorQueryResolver,
beerAdvisorMutationResolver,
beerAdvisorSubscriptionResolver,
beerFieldResolver)
.build().makeExecutableSchema();
// Beispiel: Ausführen einer Query per API
GraphQL graphQL = GraphQL.newGraphQL(schema).build();
ExecutionInput executionInput = ExecutionInput.newExecutionInput()
.query("query { beers { id name ratings { stars } } }").build();
ExecutionResult executionResult = graphQL.execute(executionInput);
Object data = executionResult.getData();
Um die GraphQL-API per HTTP-Endpunkt zu veröffentlichen, verwendet man das GraphQLServlet aus dem Projekt graphql-java-servlet. Das Servlet erwartet die oben gezeigte ausführbare Schemainstanz und stellt dafür einen Endpunkt (üblicherweise "/graphql") zur Verfügung, an den Clients GraphQL-Abfragen schicken können. Das Servlet gibt die Abfrage an das ausführbare Schema weiter und liefert das Ergebnis an den Client zurück. Das Erzeugen und Registrieren des Servlet ist abhängig vom eingesetzten Servlet-Container beziehungsweise Application Server.
Spring Boot
Für Spring-Boot-Anwendungen steht mit graphql-spring-boot ein eigenes Starter-Modul zur Verfügung, das das Arbeiten mit dem GraphQL-Framework vereinfacht. Bindet man das Modul in die eigene Anwendung ein, erzeugt es beim Start der Anwendung automatisch eine ausführbare Schemainstanz, die aus allen im Klassenpfad gefundenen SDL-Dateien sowie allen gefunden Resolver-Klassen besteht (diese muss man beispielsweise mit @Component als Spring Bean kennzeichnen). Dafür wird dann automatisch auch das GraphQL Servlet registriert. Auf Wunsch kann man zusätzlich den GraphiQL-Explorer für die eigene API aktivieren.
Fazit
Mit GraphQL lassen sich Abfragen an eine GraphQL-API schicken, wobei der Client grundsätzlich selber bestimmen kann, welche Daten er lesen möchte. Das Prinzip ist allerdings nicht beliebig flexibel: Die entsprechenden Felder müssen vom Server bereitgestellt und die Logik dafür implementiert werden. Zum Einbinden von GraphQL in eigene Anwendungen gibt es mit dem Open-Source-Projekt graphql-java-tools ein Framework, das ein guter Ausgangspunkt für die serverseitige Implementierung ist.
Der zweite Teil der Artikelserie zeigt am Beispiel einer React-Anwendung, wie man GraphQL clientseitig zum Lesen von Daten einsetzen kann.
Nils Hartmann
ist Softwareentwickler und -architekt aus Hamburg. Er programmiert sowohl in Java als auch in JavaScript beziehungsweise TypeScript und beschäftigt sich mit der Entwicklung von React-basierten Anwendungen. Nils bietet dazu Schulungen und Workshops an.
(bbo)
