Machine Learning in der Entwicklung von Fahrerassistenzsystemen

(Bild: Machine Learning & Artificial Intelligence / Mike MacKenzie / cc-by-2.0))
Bei den vielen Berichten über autonomes Fahren in jüngster Zeit geht fast unter, dass Machine Learning längst in der Praxis der Automobilbranche angekommen ist und Fahrerassistenzsysteme verbessert.
Um die Anzahl der Verkehrsunfälle mit Fahrzeugen weiter zu reduzieren und die Folgen von Unfällen zu lindern, gibt es Entwicklungen in unterschiedlichen Bereichen: Sicherheitsmaßnahmen im Auto zum Schutz der Fahrinsassen, Verkehrsregeln und Fahrerassistenzsysteme. Derzeit nutzt der Automobilbereich Machine Learning in zahlreichen Anwendungen, und ein großer Anteil der Algorithmen kommt in der Forschung und Entwicklung von Fahrerassistenzsystemen zum Einsatz.
Dieser Artikel konzentriert sich auf den wichtigen Teilbereich kamerabasierter Fahrerassistenzsysteme in Kombination mit ML-Algorithmen. Da die Kamera als Sensor die gleichen Informationen liefern kann, die ein Mensch sieht, ist sie vielseitig einsetzbar. Doch Sensordaten einer Kamera besitzen eine hohe Komplexität und Varianz. Hinzu kommt, dass die möglichen Szenarien im Straßenverkehr neben Witterung, Beleuchtung und Verkehrssituation sowie die Anwendung in allen Ländern dieser Welt starken Variationen unterliegen. Entwickler müssen daher für Fahrerassistenzsysteme Methoden finden, die mit der Komplexität zurechtkommen. Ein wichtiger Bestandteil sind Bildverarbeitungsmethoden zur mathematischen Analyse des Bildinhaltes. Sie stoßen jedoch immer wieder an ihre Grenzen. Unter anderem hat bisher niemand eine Formel gefunden, um Menschen in allen Variationen in Bildern zu segmentieren.
Sonderheft iX Developer – Machine Learning
Weitere Artikel zum Themenfeld Machine Learning finden sich im Sonderheft "iX Developer – Verstehen, verwenden, verifizieren". Es ist am Kiosk sowie als PDF-Version im heise Shop erhältlich [1].
Daher kommt Machine Learning als weiterer Bestandteil der Entwicklung zum Einsatz, um den Algorithmus mit Trainingsszenen anzulernen und anschließend mit dem System unbekannten Szenen zu testen. Dabei handelt es sich nicht (nur) um Zukunftsmusik, sondern ML-Algorithmen sind in reale Systeme integriert, wie die folgende Schilderung von den Anfängen über die Gegenwart bis zu einer Ausschau in die Zukunft zeigt.
Künstliche Augen
Zu den ersten einfachen kamerabasierten Fahrerassistenzsysteme gehört die sogenannte Nachtsichtkamera [2], um Fahrern bei Dämmerung mit Infrarotsensoren eine bessere Beobachtung der Szenerie vor dem Fahrzeug zu ermöglichen. Der Einzug einer solchen Kamera ins Fahrzeug ebnete den Weg für Bildverarbeitungsalgorithmen im Automobil. Als Beispiel sind Spurhalteassistenten zu nennen, die die Straßenmarkierungen dank Bildverarbeitungsalgorithmen robust erkennen und Fahrer beim Verlassen der Spur warnen. Eine Weiterentwicklung der Systeme und eine Verbesserung der Robustheit der Verfahren erlaubten den aktiven Eingriff, um unter anderem das Verlassen der Spur zu verhindern. Des Weiteren ermöglichte die Fusion der Algorithmen mit Radardaten, aktiv auf die Quer- und Längsbewegung des Fahrzeugs einzuwirken [3].
Radarsysteme kommen auch zum Einsatz, um den Abstand zum vorausfahrenden Fahrzeugs zu ermitteln. Durch die Kombination mit kamerabasierten Systemen lässt sich hier eine höhere Auflösung erreichen: Stereokamerasysteme ermöglichen die Berechnung des Abstands zu Objekten im Fahrzeugumfeld. Vergleichbar zum menschlichen Sehsystem nehmen sie die Szene aus zwei unterschiedlichen Perspektiven auf [4] (linkes und rechtes Auge). Anhand der beiden Bilder lässt sich durch Triangulation [5] der Abstand der Objekte zur Kamera berechnen – die Tiefe der Objekte. In den letzten Jahrzehnten wurden zahlreiche Methoden vorgestellt, um eine solche Tiefenkarte anhand eines Stereobildpaares zu ermitteln. Die Benchmarks von Middlebury [6] und dem Karlsruhe Institute of Technology [7] geben hierzu einen guten Überblick. Als Resultat kann eine solche Tiefenkarte als robuste Eingangsgröße für komplexere Fahrerassistenzsysteme und voll automatisiertes Fahren dienen.
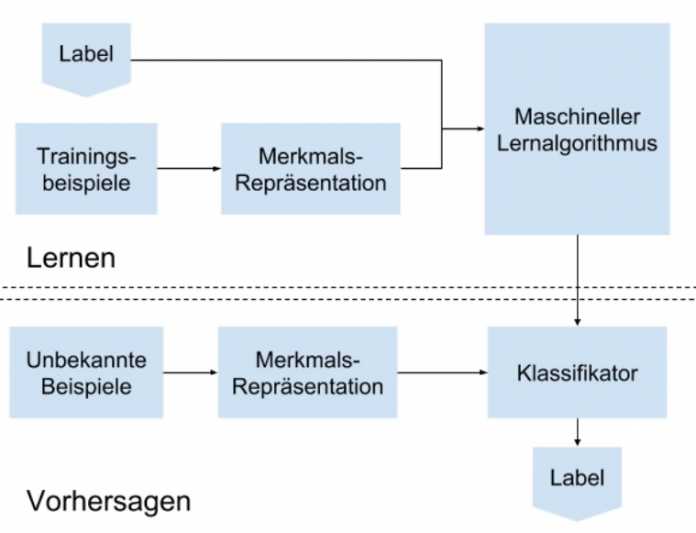
Um die Jahrtausendwende schlugen einige Wissenschaftler die ersten ML-Algorithmen mit einer ausreichenden Komplexität vor, um Muster und Charakteristiken aus größeren Datenmengen zu extrahieren. Die Methoden fallen in den Bereich des überwachten Lernens (Supervised Learning) und benötigen neben dem Algorithmus zusätzlich Trainingsbeispiele, Labels und eine Merkmalsrepräsentation. Abbildung 1 zeigt beispielhaft einen Lernprozess mit der anschließenden Anwendung des Klassifikators auf unbekannte Bilder.

Positiv- und Negativbeispiele
In der Forschung und Entwicklung kamerabasierter Fahrerassistenzsysteme sind die Trainingsbilddaten unterteilt in Positivbeispiele, die das zu erwartende Objekt enthalten, und Negativbeispiele, die es nicht erhalten. Eine Merkmalsrepräsentation ist ein mathematisches Mittel, Charakteristiken aus Bildern zu extrahieren und das Objekt möglichst genau und robust gegenüber Veränderungen in der Gestalt, Witterung, Beleuchtung und der Verkehrssituation zu beschreiben.
Der Algorithmus erhält folglich als Eingabe Trainingsbeispiele, Labels und Merkmale, um Charakteristiken aus den Bildern zu extrahieren (s. Abb. 2).

Als Rückgabe liefert er einen sogenannten Klassifikator. Letzterer enthält die bestmögliche Charakteristik, um die gewünschten Objekte erkennen zu können.
Überwachtes und unüberwachtes Lernen
Stuart Russel teilt Machine Learning in zwei Kategorien ein: überwachtes Lernen, auch "Lernen mit einem Lehrer" genannt, und unüberwachtes Lernen, "Lernen ohne einen Lehrer".
- Überwachtes Lernen: Der Algorithmus lernt mit gelabelten Trainingsbeispielen. Er versucht, aus allen Trainingsbeispielen Gesetze und Muster zu extrahieren und das resultierende Wissen auf neue Daten zur Vorhersage des Labels anzuwenden. Typische Methoden sind Support Vector Machines, Naive Bayes, Neuronale Netze, Random Forest und Boosting-Algorithmen.
- Unüberwachtes Lernen: Der Algorithmus lernt mit nicht gelabelten Trainingsbeispielen. Das Hauptziel ist es, eine Struktur zu finden, die die Trainingsdaten optimal beschreibt und in verschiedene Teilmengen kategorisiert. Typische Methoden sind die Hauptkomponentenanalyse und der Expectation-Maximization-Algorithmus.
Daneben existieren weitere Kategorien wie teilüberwachtes Lernen, bei dem eine Mischung aus Trainingsdaten mit und ohne Labels vorliegt. Eine weitere Unterscheidungsmerkmal von ML-Algorithmen sind generative und diskriminierende Modelle:
- Generative Methoden lernen die gemeinsame Wahrscheinlichkeitsverteilung P(x,y) und basieren auf einem Wahrscheinlichkeitsmodell, das aus Trainingsdaten geschätzt wird.
- Diskriminierende Methoden lernen die bedingte Wahrscheinlichkeitsverteilung P(y|x) und bauen einen Klassifikator auf, der zwischen zwei oder mehreren Klassen unterscheidet.
Gestiegene Anforderungen
In den letzten Jahren und im Hinblick auf das autonome Fahren haben die Anforderungen an Fahrerassistenzsysteme stark zugenommen. Ein autonom fahrendes Fahrzeug benötigt eine Vielzahl von Kameras, mehrere Laserscanner und Radarsensoren, Ultraschallsensoren, Differentielles Globales Positionierungssystem (DGPS) und eine inertiale Messeinheit (IMU), um genug Informationen über die Verkehrssituation zu erhalten. Sämtliche Sensordaten werden komplexer, und Fahrzeuge müssen in der Lage sein, in sämtlichen Ländern dieser Welt unter jeglichen Bedingungen autonom und sicher zu fahren. Dabei fällt eine riesige Menge an Daten an, und klassische Algorithmen sowie Methoden aus dem Gebiet des maschinellen Lernens stoßen hierbei an ihre Grenzen.
Die Automobilindustrie und Wissenschaft wenden sich daher verstärkt dem Deep Learning zu, einem weiteren Werkzeug aus dem Machine-Learning-Repertoire, das auf künstliche neuronale Netze setzt. Letztere sind ähnlich wie das menschliche Gehirn aufgebaut: Neuronen sind untereinander verbunden und zu einem Netz zusammengeschaltet. Beim Training der Netze kommt statt des traditionellen ML-Ansatzes ein hierarchischer zum Einsatz. Der Algorithmus lernt wichtige Charakteristiken selbständig und extrahiert sie stufenweise. Das Anlernen mit Trainingsbeispielen bleibt bestehen aber die Definition einer passenden Merkmalsrepräsentation entfällt.
Dadurch ist kein detailliertes Wissen der Daten im Vorfeld notwendig, und die Merkmalsrepräsentation muss nicht über mehrere Iterationen verfeinert, angepasst und getestet werden. Der implementierte, hierarchische Prozess von Deep Learning lernt eine implizite Repräsentation von Daten und bildet sie über mehrere Layer ab. Das beispielhafte Training der ersten Schicht dient dem Erkennen unterschiedlicher Objekte auf der Basis von Bildpunkten. Ein zweiter Layer kann die Pixel zu höherwertigen Strukturen wie Linien zusammenschalten, bevor anschließend ein dritter Layer die Linien zu ganzen Objekten kombinieren kann. Dabei ist die Anzahl von Layern beliebig.
Die Methode eignet sich hervorragend, um große und komplexe Datenmengen ohne manuelles Erstellen einer Merkmalsrepräsentation zu analysieren, es existieren noch nicht gelöste Herausforderungen: Deep Learning ist eine Blackbox, nicht linear und sehr komplex. Derzeit ist es noch nicht möglich zu verstehen, welcher Eingangsparameter genau welche Auswirkung auf den Ausgang vom Netz hat. Neue Ansätze orientieren sich daher meist an bekannten und erprobten Netzwerkstrukturen und Parametrisierungen.
Das Trainieren des Netzes wird durch die Optimierung der Ausgabeschicht auf Basis aller Parameter und Verknüpfungen im gesamten Netz durchgeführt. Da dabei viele Parameter zu optimieren sind, benötigt der Trainingsvorgang eine immense Menge an Rechenressourcen und damit den Einsatz von GPUs, die schnell parallel rechnen können. Zu beachten ist, dass der Trainingsvorgang einmalig und während der Entwicklung von Fahrerassistenzsystemen durchgeführt werden muss. Zur Serienreife und laufend im Fahrzeug, benötigen auf Deep Learning basierte Algorithmen keine großen Rechenressourcen mehr.
Fazit
Deep Learning hat zu einem regelrechten Paradigmenwechsel im Bereich des maschinellen Lernens geführt. Trotz aller technischen und auch juristischen Hürden, ist abzusehen, dass Deep Learning Einzug in die Serienentwicklung von Fahrerassistenzsystemen findet. Der heutige Erfolg von Deep Learning lässt sich vor allem durch das Zusammenspiel folgender Punkte erklären:
- Verfügbarkeit einer Vielzahl an Sensordaten, mit denen der Algorithmus antrainiert werden kann,
- neuartige Hardware, wie GPUs, die das Lernen großer Netzwerke ermöglicht,
- Fortschritte in der Erforschung neuer Methoden.
Um den robusten Serieneinsatz im Automobil zu gewährleisten, wird eine Kombination von in der Praxis bereits bewährter Machine-Learning-Algorithmen sowie neuartiger Deep-Learning-Methoden ein wichtiger – vielleicht sogar entscheidender – Faktor sein.
Dr. Florian Baumann
ist Technischer Direktor der ADASENS Automotive GmbH. Er lenkt die technische Forschung und Entwicklung und ist für die strategische Ausrichtung der Firma verantwortlich. Florian Baumann promovierte im Forschungsbereich Maschineller Lernverfahren und hat über 20 Publikationen in diesem Themengebiet verfasst.
Dr. David Hafner
promovierte im Bereich der mathematischen Bildverarbeitung an der Universität des Saarlandes. Seit 2016 ist er Mitarbeiter bei der ADASENS Automotive GmbH und dort als Technical Lead für den Bereich Computer Vision tätig.
Robin Lehmann
arbeitet als Machine Learning Ingenieur bei der ADASENS Automotive GmbH. Er entwickelt Algorithmen mit und ohne Machine Learning für Spiegelersatz-Systeme und Rückfahrkameras. In seiner Freizeit arbeitet er an Services für den dezentralen Machine-Learning-Marktplatz der Zukunft – SingularityNET.
(rme [8])
URL dieses Artikels:
https://www.heise.de/-4279432
Links in diesem Artikel:
[1] https://shop.heise.de/katalog/ix-developer-machine-learning-pdf
[2] https://www.meinauto.de/lp-nachtsichtassistent-autosicherheit
[3] https://www.mercedes-benz.com/de/mercedes-benz/innovation/distronic-plus-mit-lenk-assistent-video/
[4] https://www.poster-drucken.de/3d-poster/stereoskopie.php
[5] http://novavision.de/raeumlich-sehen/
[6] http://vision.middlebury.edu/stereo
[7] http://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=stereo
[8] mailto:rme@ix.de
Copyright © 2019 Heise Medien