Marke Eigenbau als Bremsklotz für KI-Entwicklertools

Im Bereich der ML-Plattformen herrscht derzeit Wildwuchs, der den produktiven Einsatz von KI im Unternehmen bremst.
Trotz der rasanten Entwicklung im Bereich Machine Learning (ML) fehlt ein einheitliches Design für ML-Plattformen. Dass sich die Entwickler-Community noch nicht darauf einigen konnte, führt zu einer Vielzahl unterschiedlich gestalteter Systeme mit undefinierten Schnittstellen. Infolgedessen hat es sich als schwierig erwiesen, eine geeignete Infrastruktur für KI-Entwicklertools auszuwählen.
Schließlich leidet die Art und Weise, wie Unternehmen die Werkzeuge nutzen, unter dem sogenannten IKEA-Effekt: das Phänomen, dass Menschen den Produkten, an deren Entstehung sie mitgewirkt haben, mehr Wert beimessen. Ein Ingenieursteam, das von Grund auf seine eigene ML-Plattform aufgebaut hat, wird sie unabhängig von potenziellen Fehlern mehr schätzen, als wenn es einfach etwas von einem Anbieter "out of the box" gekauft hätte.
Wildwuchs beim Design
Wenn neue Techniken entstehen, wächst in der Regel anfangs die Zahl der Ideen, und im Anschluss mangelt es häufig an sinnvollen Konzepten zur Umsetzung. Aller Voraussicht nach wird künstliche Intelligenz viele Industriezweige verändern – oft zu einem strategischen Vorteil. Sie wird sogar neue Geschäftsmodelle schaffen und Unternehmen werden auf "KI First" setzen. Infolgedessen häufen alle großen Cloud-Anbieter (und unzählige Start-ups) Rechenleistung an, um KI-Entwicklertools einem breiteren Publikum bereitzustellen – vor allem großen Unternehmen. Alle Anbieter versuchen im Großen und Ganzen, die gleichen Benutzerbedürfnisse zu erfüllen, aber mit deutlich unterschiedlichen Ansätzen und Ergebnissen. Die Diversität führt zu unterschiedlichen Designs.
Dieses Phänomen existiert auf jeder Ebene des Stacks und schreitet in der Regel "bottom-up" fort. Sobald die Benutzerakzeptanz eines Designs seine Konkurrenten deutlich genug übertrifft, wird es zu einem dominanten Design und damit zu einem De-facto-Standard.
Ein Beispiel dafür sind die zahlreichen ML-Frameworks wie TensorFlow und PyTorch, die mehrere Generationen von APIs zuerst in der Entwicklung eingeführt, aber kurz darauf wieder eingestellt haben. Die Projekte haben sich aber nun auf annähernd standardisierte APIs unter anderem mit Layers geeinigt. Die Notwendigkeit der Konvergenz in Bezug auf ein dominantes Design wird besonders deutlich bei Plattformprodukten, bei denen es teuer ist, unzählige konkurrierende Designs beizubehalten. Das ist bei ML-Frameworks der Fall, bei denen Data Scientists, ML Engineers, ISVs, Trainer und weitere Projektbeteiligte nicht mit Hunderten von überlappenden und inkompatiblen APIs zurechtkommen.
Design in ML-Plattformen
Der hochtrabende Begriff "KI-Entwicklertools für Unternehmen" bezeichnet in Wirklichkeit die Gattung der ML-Plattformen. Da ein vorherrschendes Design dafür fehlt, existiert keine allgemein akzeptierte Definition. Eine denkbare wäre: "Eine ML-Plattform ist eine horizontale Technik (d. h. nicht spezifisch für einen vertikalen Anwendungsfall), die alle Möglichkeiten bietet, um den gesamten Lebenszyklus von ML-Anwendungen abzudecken." Abbildung 1 veranschaulicht einige der Komponenten einer solchen Plattform.

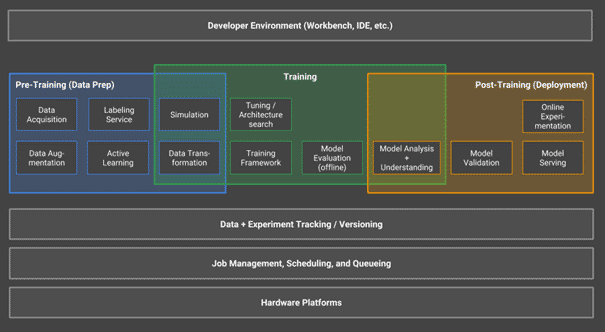
Derzeit mangelt es sogar an der Übereinstimmung über den Umfang der ML-Plattformen, von denen einige beispielsweise keine Funktionen für das Pre-Training (Data Prep) bieten.
Für das Fehlen eines vorherrschenden Designs für ML-Plattformen gibt es mehrere Gründe:
- Die zugrundeliegenden Techniken sind noch nicht ausgereift. Viele Methoden, die innerhalb einer ML-Plattform zum Einsatz kommen, befinden sich noch in einem frühen Stadium ihres Lebenszyklus. Es ist schwierig, eine Plattform aufzubauen, die kontinuierlich aktualisierte ML-Modelle bereitstellt, wenn das für diese Modelle verwendete ML-Framework inkompatible Änderungen an seinem Checkpointing-Format vornimmt. Eine Analogie wäre eine Benutzeroberfläche für eine Webanwendung, zu der anfangs keine Backend-APIs definiert sind. Entwickler müssten dabei stets Code anpassen, während sich die Schnittstellen weiterentwickeln. Im Bereich des Machine Learning verändern sich die APIs äußerst schnell, was viele Anpassungen zur Folge hat.
- Die Entwickler von ML-Plattformen wissen nicht, was sie nicht wissen. Viele Data Engineers haben anfangs große Pläne für den Aufbau einer umfassenden ML-Plattform. In den meisten Fällen ist ihr Vorstellungsvermögen für deren Umfang jedoch zu begrenzt. Letztlich unterschätzen sie damit die Adaption und Umsetzung für ihr Unternehmen. Die meisten ML-Plattform-Projekte beziehen nur Module zum Trainieren von ML-Modellen sowie eine oder mehrere Optionen für deren Anwendung ein. Oft fehlen wichtige Module wie automatische Tests für ML-Modelle oder Simulationen.
- Die Nutzer der ML-Plattformen wissen ebenfalls in der Regel nicht, was sie nicht wissen. Viele Unternehmen kaufen ML-Plattformen ein, ohne zu wissen, welche Funktionen sie erwarten oder welche Fragen sie stellen sollten. Es ist für Unternehmen nahezu unmöglich, die Angebote zu bewerten, da die Beschreibungen ähnlich klingen, aber die Plattformen äußerst unterschiedliche Ansätze verfolgen. In Folge dieses Äquivalenzproblems erkennen sie die Unterschiede erst, wenn es zu spät ist (s. Abb. 2).
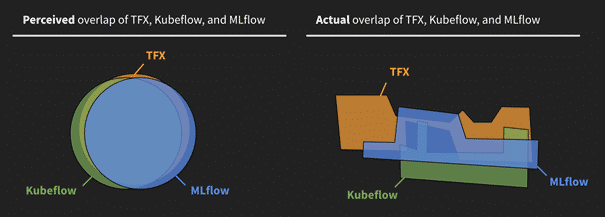
Formfaktor als Problem
Gewöhnlich bezieht sich der Begriff Formfaktor entweder auf elektronische Komponenten wie Hauptplatinen oder auf unterschiedliche Technik-Inkarnationen und deren Verpackung für die Nutzer. Das erste iPhone hat beispielsweise den vorherrschenden Formfaktor für Smartphones definiert. Im Folgenden soll dieser Begriff alles zusammenzufassen, was in Betracht zu ziehen ist, wenn von Produktoberfläche, Benutzererfahrung oder Entwicklererfahrung die Rede ist. Es steht für alle Bereiche, in denen Entwickler mit einer ML-Plattform interagieren.
Derzeit unterscheiden sich die KI-Entwicklungstools auch hinsichtlich ihrer APIs deutlich. Diese Aussage lässt sich gut an einem Beispiel veranschaulichen: Ein minimaler Satz an Techniken für das Trainieren und Implementieren eines ML-Modells, könnte wie folgt aussehen:
- Ein Data-Engineering-Produkt wie Spark für den richtigen Umgang mit Daten,
- eine Bibliothek wie TensorFlow für das Training des ML-Modells,
- Docker für das Verpacken von Modellen sowie
- Kubernetes, um die Docker-Container zu orchestrieren
Es ließe sich argumentieren, dass es in diesem Fall eine Arbeitsteilung geben sollte: Dateningenieure sollten die Datenpipelines schreiben, Data Scientists die Modelle trainieren und Softwareingenieure die Deployment-Systeme schreiben. Dabei könnte wohl keine ML-Plattform alle gewünschten Funktionen bieten. Jedoch stellen Unternehmen immer wieder fest, dass diese künstliche Trennung der Belange, die das Ergebnis von Technologiegrenzen ist, die lange vor dem Entstehen der ML-Plattformen gezogen wurden, zu einer erheblichen Verlangsamung, kostspieligen Fehlern und insgesamt zu höheren Ausfallraten von ML-Projekten führt.
Es wäre naiv, davon auszugehen, dass Werkzeuge und Prozesse, die vor Jahrzehnten für das Software Engineering geschaffen wurden, auf magische Weise auf ML übertragbar sind. Beispielsweise ist es wenig sinnvoll, ML-Modellartefakte, die ziemlich groß sein können und sensible Daten enthalten, einfach in für Sourcecode vorgesehene Versionskontrollsysteme zu überführen. So hat beispielsweise Databricks die MLflow Model Registry aufgebaut, um den Versionierungs- und Bereitstellungs-Lebenszyklus von ML-Modellen zu verwalten. Außerdem existiert das Open-Source-Projekt DVC [1] zum Versionieren.
Wenn Data Scientists oder Softwareingenieure in der Lage sein sollen, den gesamten ML-Lebenszyklus zu managen, müssen die Werkzeuge einem breiten Benutzerkreis zugänglich sein und nicht nur DevOps-Experten. Bei Unternehmen wie Google ist es nicht ungewöhnlich, dass eine einzelne Person den gesamten Lebenszyklus von der Datenpipeline bis zur Modelleinführung überwacht. Andere sind zu der gleichen Erkenntnis gelangt und schaffen genau deshalb eine breiter angelegte ML-Engineer-Rolle.
Versuche für konsistentere Formfaktoren
Einige Anbieter haben erkannt, wie begrenzt das Zielpublikum für Anwendungen ist, die technische Kenntnis von Spark, TensorFlow, Docker und Kubernetes erfordern. Sie haben versucht, unterschiedliche Formfaktoren zu schaffen, die die Komplexität abstrahieren. Die meisten von ihnen scheitern jedoch dabei.
Ein Ansatz ist das SQL-basiertes Machine Learning: Einige Hersteller behaupten, dass ihre Produkte Machine Learning so einfach machen wie das Schreiben von SQL-Abfragen. Um das zu erreichen, lassen sie die Anwender jedoch einen Schnipsel Python-Code als Prozedur registrieren, oder sie spiegeln einfach dieselben Python-APIs in SQL wider, um beispielsweise die Schichten eines neuronalen Netzes in einer SQL-Abfrage zu definieren. Der Ansatz ist nicht neu und erschwert häufig sogar langfristig den Umgang mit dem Werkzeug, wenn es beispielsweise um das Debuggen des Python-Codes geht. Sobald Hardwarebeschleuniger wie GPUs ins Spiel kommen, zeigt sich häufig, was mit der Verletzung der Grundprinzipien der Abstraktionsebenen gemeint ist: Eine SQL-Abfrage löst Fehler aus, die spezifisch für die Hardware sind, auf der der Python-Code läuft. Oder sie schlägt im schlimmeren Fall einfach stillschweigend fehl, und die Verantwortlichen müssen sich auf die Jagd nach Protokolldateien begeben.
Das UI-basiertes Machine Learning bezeichnet eine Klasse von Produkten, die versucht, No-Code-Ansätze für sogenannte Citizen Data Scientists anzubieten. UI-basierte Workflows sollen die Benutzer durch die typischen Schritte beim Aufbau von Data- Science- und ML-Modellen führen. Es können zwei übliche Fehlermodi für diese Art von Produkten beobachtet werden:
- Bei einem oder mehreren Schritten im Arbeitsablauf, üblicherweise dem Modellierungsschritt, fordert das Tool von den Benutzern die Angabe von Low-Level-Parametern wie der L1-Regularisierung an. Letztere trägt dazu bei, ein Modell über die bekannten Datenpunkte hinaus zu generalisieren oder zumindest zu bestimmen, wie sich ein guter Wert dafür wählen lässt. Wer sich damit auskennt, wird kaum auf ein UI-basiertes ML-Produkt setzen.
- In zahlreichen Fällen bieten die Werkzeuge nur Umsetzungen für die höchste Abstraktionsebene und keine weiteren Optionen für den Fall, dass Benutzer an die Grenzen der Tools stoßen. Infolgedessen stellen viele Unternehmen fest, dass UI-basierte ML-Tools nicht ausreichen, um Anwendungsfälle aus dem wirklichen Leben zu lösen.
Die beiden Gründe führen zu einem typischen Ungleichgewicht zwischen Produkt und Marktanforderung, und die meisten UI-Tools für Machine Learning sind nicht viel mehr als Demos und Proofs of Concept.
Vermeiden des IKEA-Effekts
Viele Unternehmen, die weder über ein dominantes Design noch über einen angemessenen Formfaktor verfügen, kämpfen mit der Einführung von ML-Plattformen. Sie verzweifeln schließlich am Umbau ihrer Unternehmen zu einem "KI-First"-Geschäftsmodell. Diejenigen, die es versuchen, leiden oft unter dem IKEA-Effekt.
Ingenieure lieben es, Produkte zu erfinden und sich neue Fähigkeiten anzueignen. Infolgedessen belegen viele Ingenieure Online-ML-Kurse auf zu niedrigem Niveau. Ermutigt durch ihr neu erworbenes Wissen, das häufig nur winzige Details von ML abdeckt, versuchen sie die konkreten Herausforderungen ihres Unternehmens anzugehen. An dieser Stelle kommt der IKEA-Effekt ins Spiel.
Dabei würde wohl kein Team sagen: "Lasst uns unsere eigene Datenbank von Grund auf aufbauen". Da bei ML-Plattformen ein vorherrschendes Design und ein gemeinsamer Formfaktor fehlt, ist es für ein Team aus wenigen Entwicklern unmöglich, eine passende ML-Plattform zu entwickeln. Dass ihnen Daten und Erfahrungswerte fehlen, kommt erschwerend hinzu.
Blick in die Kristallkugel
Das wirft die Frage auf, wie KI-Entwicklertools in zehn Jahren aussehen werden. Tatsächlich ist in einer idealen Welt der gesamte Prozess des Erstellens datengesteuerter Anwendungen nur ein üblicher Teil der Arbeit von Softwareingenieuren, ohne dass sie einen Doktortitel in KI oder einen Master für Kubernetes erwerben müssen.
Der Autor erwartet für die nächsten zehn Jahre folgende Entwicklungen:
- Die Hersteller werden sich auf einen dominanten Entwurf für ML-Plattformen einigen. Heutzutage konzentrieren sich viele Anbieter nur auf das Trainieren von ML-Modellen und vergessen dabei, dass bei Machine Learning viel Zeit für die Datenverarbeitung anfällt. Wahrscheinlich wird ein Produkt an Zugkraft gewinnen und den Weg zur Definition der Kategorie weisen. Viele Anbieter werden aus dem Markt ausscheiden, während andere sich dem vorherrschenden Design anpassen.
- Es wird einige wenige sinnvolle Formfaktoren für unterschiedliche Zielgruppen geben. Ein einziger Formfaktor ist nicht sinnvoll, aber unterschiedliche Abstraktionsebenen durchaus wünschenswert. Jede Schicht muss gut definiert sein, und Abstraktionen sollten nicht zwischen den Schichten durchsickern. Bislang gibt es noch kein gutes Beispiel für die höchste Abstraktionsebene in Form von Tools wie den genannten SQL- oder UI-basierten ML-Werkzeugen mit ihren derzeitigen Schwächen.
- Unternehmenskunden werden erkennen, dass der Aufbau eigener ML-Plattformen nicht zu ihrem Vorteil ist. Wenn ein vorherrschendes Design vorhanden ist, wird es offensichtlicher sein, wie sinnlos dieser Aufwand ist und dass es nicht in die Kernkompetenz der Unternehmen fällt. Für die meisten von ihnen ergibt sich der Wert aus der Anwendung von ML-Plattformen auf ihre Geschäftsprobleme, nicht aus dem Aufbau und der Instandhaltung eigener ML-Plattformen.
Nur gemeinsam ans Ziel
Die Hersteller von KI-Entwicklertools müssen sich über die nächsten Jahre auf ein vorherrschendes Design einigen und zusammen mit Unternehmensanwendern die richtigen Formfaktoren finden. Nur auf die Weise können Unternehmenskunden bei der Auswahl einer ML-Plattform Äpfel mit Äpfeln vergleichen und diejenige mit den benötigten Funktionen auswählen.
Bis dahin bleibt die Kategorie der KI-Entwicklertools ein Thema für Forschungsinstitute und die Open-Source-Community. Ihnen ist die Geschwindigkeit der Innovation wichtiger als Stabilität. Für diejenigen, die gerne ihre Möbel selber zusammenbauen und mit dem Ergebnis zufrieden sind, auch wenn der Tisch wackelt, bleibt die Kategorie von ML-Plattformen vorerst ein Bastelprojekt.
Clemens Mewald
ist Produkt Management Direktor bei Databricks, verantwortlich für Data-Science- und Machine-Learning-Produkte. Zuvor war er ein Produkt Manager im Google Brain Team und unter anderem verantwortlich für TensorFlow und TensorFlow Extended (TFX).
(rme [2])
URL dieses Artikels:
https://www.heise.de/-4978528
Links in diesem Artikel:
[1] https://www.heise.de/hintergrund/Verwaltung-und-Inbetriebnahme-von-ML-Modellen-4911723.html
[2] mailto:rme@ix.de
Copyright © 2020 Heise Medien