Schlauer Zwerg: ML mit dem Raspberry Pi Pico, Teil 2: Modelltraining

(Bild: Gerd Altmann, gemeinfrei)
Der Raspi Pico kann zwar keine ML-Modelle trainieren, aber trainierte Modelle nutzen.
Der Raspberry Pi Pico eignet sich gut für Machine-Learning-Anwendungen. Im Rahmen dieser dreiteiligen Artikelserie entsteht als Beispielanwendung eine einfache XOR-Schaltung (Exklusiv Oder) mit zwei Tastern und einer Leuchtdiode. Nach der Beschreibung des Schaltungsaufbaus im ersten Teil geht der zweite auf das Training ein und zeigt, wie sich das trainierte Modell als C-Code in die Anwendung integrieren lässt. Der Sourcecode für das Training und für die Anwendung steht auf GitHub zur Verfügung [1].
Die Beispielanwendung im ersten Teil [2] hat gezeigt, dass eine einzige if-else-Anweisung beziehungsweise eine Ungleich-Abfrage ausreicht, um ein XOR (exklusiv oder) zu implementieren. Für das Machine Learning (ML) bleibt damit das Modelltraining einfach. Es benötigt lediglich zwei Eingaben und eine Ausgabe. Trotzdem bietet das Modell die Option, durch Parameter das Ergebnis zu optimieren und die Modellgröße zu beeinflussen. Damit wird sich der letzte Teil der Artikelserie beschäftigen.
Bei TensorFlow Micro für TinyML-Anwendungen liegt das Augenmerk auf einer schlanken Anwendung. Daher bringt das TensorFlow-Micro-Projekt keinen Code mit, um das Modell auf dem Raspberry Pi Pico zu trainieren.
Das Exklusive-Oder-Modell ist einfach aufgebaut und benötigt für die Trainingsdaten lediglich die vier möglichen Zustände der Ein- und Ausgabe. Dadurch lässt sich das Modell lokal auf einer Workstation trainieren. Wer einen Google-Account besitzt, kann das Training auf Google Colab [3] durchführen und auf die im Folgenden beschriebene Installation der Software und Bibliotheken auf dem lokalen Rechner verzichten.
Lokale Installation
Für das Zusammenspiel mit Google Colab und die lokale Installation kommt dasselbe Jupyter Notebook zum Einsatz. Damit beschreiben Entwicklerinnen und Entwickler innerhalb einer Browser-Anwendung ein Modell mit Python-Code und führen das Training interaktiv aus. Dafür ist ein aktueller Python-Interpreter [4] auf dem Rechner erforderlich.
Damit sich unterschiedliche Python-Projekte nicht gegenseitig beeinflussen, empfiehlt sich ein sogenanntes virtuelles Verzeichnis. Dadurch bleibt jedes Projekt in seiner Umgebung und überschreibt bei der Installation neuer Bibliotheken keine Libraries aus anderen Projekten. Letztere haben wiederum keine Auswirkungen auf das virtuelle Verzeichnis. Im Folgenden sind die Schritte aufgeführt, um das Verzeichnis unter Linux und macOS anzulegen:
mkdir PicoML
cd PicoML
python3 -m venv venv
. ./venv/bin/activate
Unter Windows erfolgt die Einrichtung folgendermaßen:
mkdir PicoML
cd PicoML
python -m venv venv
.\venv\Scripts\activateIn dem neuen Directory PicoML, das sich innerhalb eines belieben Verzeichnisses befinden kann, legt der Python-Aufruf in der jeweils dritten Zeile das virtuelle Verzeichnis venv an. Der Befehl activate aktiviert schließlich die virtuelle Umgebung. Zu beachten ist, dass sich unter Linux und macOS zwischen den zwei Punkten ein Leerzeichen befindet, um die Umgebungsvariablen innerhalb des aktuellen Terminal-Fensters auf die virtuelle Umgebung zu setzen. Der Aufruf which python unter Linux oder macOS zeigt auf das Python-Programm im virtuellen Verzeichnis.
Die benötigten Python-Bibliotheken lassen sich einzeln installieren oder idealerweise in einer requirements.txt-Datei auflisten, in der neben dem Namen die Version der jeweiligen Library stehen kann:
notebook==6.4.4
tensorflow==2.6.0
tinymlgen==0.2
Da sich Schnittstellen durchaus innerhalb von Minor Releases ändern können, sollte requirements.txt Bestandteil des Projekts sein und klar die Versionen definieren. Dadurch lässt sich das Training zu einem späteren Zeitpunkt mit den passenden Bibliotheken wiederholen.
Für das Training kommt ein Jupyter Notebook und TensorFlow zum Einsatz. Die Library tinymlgen wandelt das trainierte Modell in C-Code um.
Mit folgendem Aufruf installiert pip die in requirements.txt definierten Bibliotheken:
pip install -r requirements.txt
Die pip-Anwendung ist Bestandteil der virtuellen Umgebung und für die Installation der Python-Bibliotheken zuständig.
jupyter notebook
Der Befehl jupyter notebook startet den Jupyter-Notebook-Server und öffnet automatisch im Browser unter http://localhost:8888 ein neues Fenster. Es zeigt den Inhalt des Projektverzeichnisses an, in dem sich das Jupyter Notebook befindet, das sich mit einem Klick öffnen lässt. Die Startseite bietet zudem die Möglichkeit, ein Notebook hochzuladen oder ein neues anzulegen.
Google Colaboratory
Google Colab ist ein zumindest derzeit kostenfreier Service des Internetriesen, um Jupyter Notebooks im Browser auszuführen. Damit entfällt die lokale Installation. Zudem bietet Google Colab die Option, das Training auf einer Graphics Processing Units (GPU) oder sogar einer Tensor Processing Units (TPU) auszuführen. Für das Exklusive-Oder-Modell sind beide jedoch überdimensioniert.
Wer Colab verwenden möchte, benötigt einen Google-Account. Auf der Hauptseite [5] erfolgt die Anmeldung über den Button Sign in. Das Jupyter Notebook für das Training lässt sich mit File | Upload hochladen und anschließend ausführen.
Training des Modells
Bei der lokalen Installation sind alle benötigten Python-Bibliotheken enthalten. Die Definition steht in requirements.txt. Alternativ lassen sich die Bibliotheken im Jupyter Notebook mit dem Paketmanager pip installieren. Alle Kommandos, die mit einem Ausrufezeichen beginnen, führt die darunterliegende Konsole beziehungsweise das Terminal aus. Im Folgenden installiert pip die Library tinymlgen, die später das Modell in C-Code umwandelt. Über den Menüpunkt Cell | Run Cells führt das Jupyter Notebook den jeweiligen Code in einer Zelle aus.
#!pip install tensorflow==2.6.0
!pip install tinymlgen==0.2
Sollte die Bibliothek bereits installiert sein, weist eine Mitteilung darauf hin, sofern es sich um dieselbe Version handelt. Unterscheidet sie sich hingegen, entfernt pip die Bibliothek und installiert die gewünschte Version.
Hinweis: Innerhalb von Google Colab ist die jüngste stabile TensorFlow-Version vorinstalliert. Wurde das Jupyter Notebook für eine ältere Version entwickelt, zeigt es womöglich beim Ausführen ein paar Warnungen an. Sollte sich die Schnittstelle geändert haben, funktioniert das Notebook ohne eine Anpassung allerdings nicht mehr.
In dem Fall kann pip die ältere, vom Jupyter Notebook verwendete Version installieren. Dafür lässt sich hinter dem Bibliotheksnamen und einem doppelten Gleichzeichen die Versionsnummer angeben. Im oberen Code ist das beispielhaft als auskommentierter Code für TensorFlow 2.6.0 aufgeführt. Dabei ist zu beachten, dass nach dem Austausch der TensorFlow-Version ein Neustart der Runtime des Jupyter Notebooks erforderlich ist.
Nachdem alle Bibliotheken installiert sind, beginnt das Jupyter Notebook mit dem Import der Bibliotheken, um deren Methoden zu verwenden.
import tensorflow as tf
from tensorflow.keras import layers
TensorFlow ist ein Framework für Machine Learning, das den Aufbau künstlicher neuronaler Netze (KNN) ermöglicht. Im Gegensatz zu der Lite- und Micro-Variante enthält das reguläre TensorFlow-Framework zusätzlich den Code für das Training. TensorFlow Lite und Micro können das trainierte Modell im Anschluss direkt übernehmen, wenn sie die verwendeten Operatoren kennen.
Die Keras-Bibliothek dient als Schnittstelle zu TensorFlow und vereinfacht den Aufbau des Modells. Keras abstrahiert bei einer neuronalen Schicht die Parameter für die Gewichtung und den Bias. Ebenso erkennt Keras die vorhergehende und nachfolgende Schicht. Dadurch lässt sich eine neue neuronale Schicht einfach in das Modell integrieren.
model = tf.keras.Sequential()
model.add(layers.Dense(8, input_dim=2,
activation='sigmoid'))
model.add(layers.Dense(1, activation='sigmoid'))
Durch den sequenziellen Aufbau lassen sich die Schichten (Layers) mit der add-Methode hinzufügen. Die erste Schicht heißt Eingangsschicht und besitzt eine Eingangsdimension (input_dim) von zwei. Sie repräsentiert die beiden Taster, die der Graph mit zwei Knoten anzeigt.


Abbildung 1 zeigt eine mittlere Schicht (Hidden-Layer) mit acht Knoten. Da es sich um eine Schicht vom Typ dense (kompakt) handelt, sind alle Nodes miteinander verbunden. Die letzte Schicht ist die Ausgangsschicht. Sie besitzt lediglich einen Knoten für die Steuerung der Leuchtdiode. Die Angabe der Eingabedimension entfällt, da Keras sie von der vorherigen Schicht übernimmt. Das vereinfacht das Experimentieren mit dem Modell. Keras passt es automatisch an, wenn sich beispielsweise die Zahl der inneren Schichten ändert. Der kommende letzte Teil der Artikelserie betrachtet dessen Auswirkung.
Beide Schichten benutzen als Aktivierungsfunktion (activation) eine Sigmoidfunktion. Sie kennzeichnet sich durch eine S-Form aus: Werte um Null haben eine größere Auswirkung als solche, die von Null entfernt sind. Dort flacht die Funktion ab.
Die jeweiligen Werte der Gewichtungen liegen auf den Kanten zwischen den Knoten. Um den Wert eines Knoten zu berechnen – mit Ausnahme der Eingangsknoten – multipliziert TensorFlow zunächst alle Gewichte zu einem Knoten mit den Werten der vorherigen Nodes und summiert alle Ergebnisse. Mit der Summe berechnet die Aktivierungsfunktion das Ergebnis des Knotens. Beim Training kommt die sogenannte Back-Propagation zum Einsatz und die Umkehrfunktion der Aktivierungsfunktion. Dabei spielt zusätzlich die Loss-Funktion (Verlustfunktion oder Fehlerfunktion) eine Rolle.
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=1),
metrics=['accuracy'])
Die compile-Methode definiert die Fehlerfunktion und den Optimizer. Beim Training startet das Modell zunächst mit zufälligen Werten für die Gewichte. Das Modell berechnet damit das Ausgabeergebnis und vergleicht es mit dem tatsächlich erwarteten Wert. Die Fehlerfunktion berechnet die Differenz. Da lediglich eine Ausgangsschicht vorhanden ist und nur die Zustände 1 und 0 möglich sind, eignet sich binary_crossentropy als Fehlerfunktion.
Die binäre Kreuzentropie (binary crossentropy) ist eine Verlustfunktion, die bei binären Klassifizierungsaufgaben Anwendung findet. Das ist der Fall, wenn nur zwei Auswahlmöglichkeiten zur Verfügung stehen. Beim Exklusive-Oder-Modell sind es die Zustände 0 und 1. Die E-Mail-Spam-Klassifizierung ordnet eine E-Mail in Spam oder Nicht-Spam ein.
Die Back-Propagation reguliert die Abweichung, indem sie die einzelnen Gewichte anpasst. Den Grad der Abweichung berechnet die mit dem optimizer definierte Methode – in diesem Fall Stochastic Gradient Descent (SGD). Die Differenz für die neuen Gewichtungen ergibt sich durch den Grad der Abweichung und die Umkehrfunktion der Aktivierungsfunktion. Die Berechnung und Anpassung erfolgt für jedes Gewicht.
Nachdem die Anpassungen abgeschlossen sind, berechnet das Modell im nächsten Schritt das Ausgabeergebnis mit neuen Eingabewerten. Die Fehlerfunktion bestimmt die Differenz und die Back-Propagation, um wiederum die Werte der Gewichte anzupassen. Dieses Vorgehen wiederholt sich wieder und wieder. Die Zahl der Durchläufe ist entweder fest vorgegeben oder abhängig von einem bestimmten Schwellwert bei der Fehlerfunktion.
Da das Exklusive-Oder-Modell äußerst einfach ist, reichen für die Trainingsdaten die vier Zustände der Taster mit den zugehörigen Ausgabewerten aus.
training_data = [[0,0], [0,1], [1,0], [1,1]]
target_data = [ [0], [1], [1], [0]]
Üblicherweise verwendet das Training deutlich mehr Trainingsdaten, insbesondere bei Modellen für die Bilderkennung. Die übliche Aufteilung des Datensatzes in ungefähr 80 % Traingsdaten, 10 % Testdaten und nochmals 10 % Validierungsdaten entfällt für das simple Exklusive-Oder Modell.
Die fit-Methode startet das Training mit den Trainings- und Zieldaten.
epochs = 500
model.fit(training_data, target_data, epochs=epochs)
epochs gibt die Zahl der Schritte vor. Der Wert hängt von mehreren Faktoren wie dem Modellaufbau, dem in der compile[code]-Methode verwendetem Optimizer und der Lernrate ([code]learning_rate) ab. Bei einer Lernrate von 1,0 erreicht die Genauigkeit (accuracy) den Wert 1,0 bei ungefähr 320 Epochs. Bei einer Lernrate von 2,0 erreicht die Genauigkeit den Wert 1,0 bereits unterhalb von 200 Epochs. Der beim Training ausgegebene Verlustwert (loss) ist bei einer Vorgabe von 2,0 ebenfalls niedriger. Ist die Lernrate jedoch zu hoch angesetzt, sind die Anpassungen bei der Back-Propagation zu groß und das Training findet nicht den optimalen Wert.
Nachdem das Training abgeschlossen ist, kann die predict-Methode das Ergebnis vorhersagen. Da aber alle Zustände in das Training eingeflossen sind, handelt es sich um keine Vorhersage. Vielmehr lernt das Exklusiv-Oder-Modell die Trainingsdaten lediglich auswendig – und zwar nicht besonders gut.
model.predict(training_data)
array([[0.03646076],
[0.9611139 ],
[0.9406228 ],
[0.06128317]], dtype=float32)
Kein Ergebnis liefert eine eindeutige Null oder Eins. Es ist lediglich die Tendenz zu erkennen, dass der erste und letzte Wert in Richtung Null zeigen und die anderen beiden sich der Eins annähern. Eine höhere Lernrate verringert zwar die Abstände, letztlich ist das Ergebnis jedoch berechnet und keine logische Operation.
Wie erwähnt dient das Modell lediglich als einfaches Beispiel. Die unterschiedlichen Ergebniswerte für die jeweiligen Eingaben eignen sich ideal zur Orientierung. Der Raspberry Pi Pico berechnet mit dem trainierten Modell für jede Eingabe exakt dieselben Werte. Damit lassen sich die Zustände der Taster dem berechneten Ergebnis zuordnen und nachvollziehen.
from tinymlgen import port
import os
c_code = port(model, pretty_print = True)
path = os.getcwd()
#path = os.getcwd() + "/../pico-tflmicro/examples/xor"
open(path + "/model.cpp", "w").write(
'#include "model.h"\n' + c_code)
Nach dem Training enthält das Modell sowohl den Aufbau als auch die berechneten Werte der Gewichte. Üblicherweise lässt es sich in eine Datei speichern, um es anschließend mit einer Anwendung zu laden und auszuführen. Der Raspberry Pi Pico bietet jedoch keinen direkten Weg, um Dateien zu laden. Die Library tinymlgen wandelt das Modell in C-Code um. Die port-Methode überführt das Modell in ein Array, das es einer Variable zuweist. Das Ergebnis der Umwandlung speichert das Jupyter Notebook in der Datei model.cpp, die Bestandteil der Anwendung ist.
Python legt die Datei in dem Verzeichnis ab, indem sich das Jupyter Notebook befindet. Aus Google Colab lässt sich die Datei über das linke Menü unter Files herunterladen und in die XOR-Beispielanwendung übertragen. Um die Datei nicht nach jedem Trainingslauf händisch verschieben zu müssen, kann das lokal laufende Jupyter Notebook die Datei direkt in das C-Projekt speichern. Dafür muss die Variable path den Pfad zur XOR-Beispielanwendung enthalten. Dies ist beim obigen, auskommentierten Code zu sehen. Damit sind das Training und die Umwandlung des Modells abgeschlossen.
Umsetzung in C++
Das GitHub-Projekt zum Artikel enthält die komplette XOR-Beispielanwendung. Sie basiert auf dem Raspberry-Pi-Projekt pico-tflite. Das example-Verzeichnis enthält die Anwendung. Im src-Verzeichnis befindet sich der TensorFlow-Micro-Sourcecode mit den benötigten Bibliotheken, die ebenfalls als Quellcode vorliegen. Um die Beispielanwendung übersichtlich zu halten, sind Tests und die ursprünglichen Beispiele nicht mehr im Projekt vorhanden.
Visual Studio Code fragt beim ersten Öffnen zunächst nach einem Compiler. Zusätzlich gilt es den PICO_SDK_PATH in den Settings für Cmake: Build Environment und Cmake: Configure Environment zu konfigurieren. Anschließend lässt sich mit Build die XOR-Anwendung erstellen und auf den Raspberry Pi Pico übertragen.
Im Verzeichnis example/xor befindet sich die Datei CMakeList.txt, die das Projekt für CMake definiert. Die Datei main_functions.cpp und der zugehörige Header enthalten die Methoden setup und loop. In main.cpp findet sich wie im ersten Teil des Artikels die main-Funktion. Sie ruft einmalig die setup-Methode auf und anschließend in einer Endlosschleife loop. Daneben existiert die model.cpp-Datei. Wie oben beschrieben, erstellt das Jupyter Notebook diese Datei.
Die setup-Methode besteht nach wie vor aus der Definition der Taster und der Leuchtdiode. Zusätzlich dient ein umfangreicher Codeabschnitt der Initialisierung von TensorFlow. Zwei Codestellen sind hervorzuheben:
model = tflite::GetModel(model_data);GetModel lädt die Modelldaten, die in dem model_data-Array in model.cpp definiert sind. Es bietet den Aufbau des Modells und die berechneten Gewichtungen.
input = interpreter->input(0);
output = interpreter->output(0);
Diese beiden Aufrufe setzen die Ein- und Ausgabe als Pointer in ihre jeweiligen Variablen. Dadurch lassen sich innerhalb der loop-Methode die beiden Werte der Taster setzen und das Ergebnis lesen.
int button1 = gpio_get(BUTTON1_PIN);
int button2 = gpio_get(BUTTON2_PIN);
input->data.f[0] = button1;
input->data.f[1] = button2;
TfLiteStatus invoke_status = interpreter->Invoke();
printf("%f\n", output->data.f[0]);
if (output->data.f[0] > 0.5)
{
gpio_put(LED_PIN, true);
}
else
{
gpio_put(LED_PIN, false);
}
Die loop-Methode liest die Werte der Taster und setzt mit ihnen die beiden Eingabewerte für das Modell. Invoke führt die Berechnung aus. Das Ergebnis ist über die output-Variable erreichbar, die printf ausgibt. Eine if-Abfrage prüft den Wert: Liegt er über 0,5, schaltet der Code die Leuchtdiode ein, sonst schaltet er sie aus.
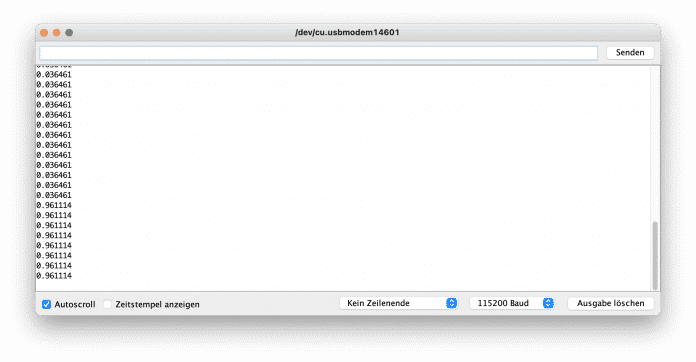
Abbildung 2 zeigt den Übergang beim Drücken des ersten Tasters. Dabei sind dieselben krummen Werte zu sehen, die beim Training entstanden sind.
Einfaches Modell mit Ausbaufähigkeit
Das im zweiten Teil der Artikelserie erstellte und trainierte Modell zeigt die grundlegende Arbeit von Machine-Learning-Anwendungen anhand eines einfachen neuronalen Netzes inklusive dem Übertragen in C++-Code für den Rasperry Pi Pico. Die Anwendung arbeitet zuverlässig, das Modell hat aber Verbesserungspotenzial.
Der dritte Teil beschäftigt sich mit der Änderung des Modells und des Trainings. Dabei stehen die Auswirkungen auf die Genauigkeit, Größe und Geschwindigkeit im Mittelpunkt.
Der Autor beantwortet gerne Fragen im Forum zu diesem Artikel. Auf GitHub freut er sich über Verbesserung zum Jupyter Notebook und Code. Ansonsten ist er auf Twitter unter @choas [6] per DM erreichbar.
Lars Gregori
arbeitet als Technology Strategist bei SAP CX im Customer Experience Umfeld. Innerhalb des SAP CX Labs Teams im CX CTO Office betrachtet er neuste Technologien und beschäftigt sich mit Machine Learning, Embedded Devices, dem Internet der Dinge, Daten und vielem mehr. Er ist Sprecher auf nationalen und internationalen Konferenzen, Buchautor zum Thema Machine Learning und bringt seine Erfahrung im Elektronikumfeld in Lernvideos ein.
(rme [7])
URL dieses Artikels:
https://www.heise.de/-6214354
Links in diesem Artikel:
[1] https://github.com/choas/pico-xor
[2] https://www.heise.de/hintergrund/Schlauer-Zwerg-Maschinelles-Lernen-mit-dem-Raspberry-Pi-Pico-Teil-1-6143330.html
[3] https://colab.research.google.com/
[4] https://www.python.org/downloads/
[5] https://colab.research.google.com/
[6] https://twitter.com/choas
[7] mailto:rme@ix.de
Copyright © 2021 Heise Medien