Von Daten, Rollen und Modellen – ein Bauplan für KI-Anwendungen

(Bild: Machine Learning & Artificial Intelligence / Mike MacKenzie / cc-by-2.0))
Wer klassische Softwareentwicklung beherrscht, muss nicht zwangsweise auch erfolgreich datengetriebene Anwendungen entwickeln können. Der Ansatz des Engineering Data-Driven Applications will den Prozess der Entwicklung von KI-Anwendungen strukturieren.
Verfahren der Künstlichen Intelligenz (KI) beziehungsweise des Machine Learning (ML) bereichern die Softwareentwicklung um neue Möglichkeiten. Sie stoßen die Türen für neue Anwendungen und Lösungswege auf und erlauben einen anderen Umgang mit großen Datenmengen und komplexen Problemen. Die Folge: Klassische Softwareprojekte enthalten häufiger KI- oder ML-Komponenten. Dieses Miteinander müssen die Projektverantwortlichen in ihren Planungen von Beginn an berücksichtigen. Die frühe Projektphase spielt eine wichtige Rolle. Hier treffen die Beteiligten grundlegende Entscheidungen über die Technikauswahl, die den ganzen Projektpfad beeinflussen.
Der Ansatz der Engineering Data-Driven Applications (EDDA) wurde entwickelt am Lehrstuhl für Software Engineering der Universität Duisburg-Essen. Er strukturiert den Prozess der Entwicklung von KI-Anwendungen. Augenmerk legt das Vorgehensmodell auf die Interdependenzen zwischen dem übergeordneten Software- und dem Teilprojekt, das diese KI-Anwendungen entwickelt. Darüber hinaus beschreibt EDDA, welche Kompetenzen notwendig sind, um ein KI-Projekt erfolgreich auf- und umzusetzen.
Zu Beginn eines KI-Projekts ist es den Experten nur schwer möglich, Aussagen über geeignete Techniken und Verfahren zu treffen. Es ist noch nicht einmal sicher, ob ML-/KI-Anwendungen überhaupt zum gewünschten Ziel führen. Denn am Anfang haben die Beteiligten noch kein klares Bild davon, ob die Daten die notwendigen Informationen für das Entwickeln der Anwendungen enthalten.
Ziel des Vorgehensmodells ist es, die Unsicherheit zu reduzieren, die mit dem Entwickeln von ML-/KI-Anwendungen einhergeht. Klassische Softwareentwicklungsprojekte setzen auf regelbasierte Ansätze. Die Beteiligten folgen in weiten Teilen standardisierten Projektabläufen und arbeiten mit erprobten Techniken. Beim Entwickeln von ML-/KI-Anwendungen können sie auf wenige Erfahrungswerte zurückgreifen. Deshalb legt das EDDA-Konzept Wert auf eine intensive Auseinandersetzung mit Daten und Anforderungen zu Beginn des Projekts. Diese frühen Phasen stehen im Zentrum der folgenden Ausführungen.
Keine richtige Entwicklung ohne die richtigen Experten
Die Fachwelt ist weit von einer einheitlichen Definition von KI entfernt. Für das Beschreiben der EDDA-Idee reicht es aus, Machine Learning oder KI von klassischen Informationssystemen abzugrenzen: Während Experten Letztere auf Basis regelbasierten Wissens entwickeln, spielen bei Ersteren Daten die entscheidende Rolle. Ob gespeicherte oder Laufzeitdaten, interne oder externe, reale oder simulierte: ML- und KI-Anwendungen sind datengetrieben. Sie erkennen Muster, Zusammenhänge oder Anomalien. Diese Fähigkeiten sind die Grundlage für neue Anwendungen, andere Geschäftsmodelle oder verbesserte Prozesse.

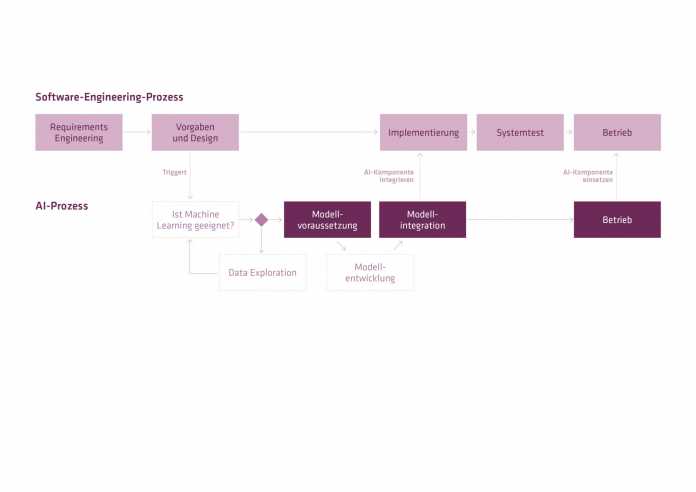
Der Blick in die Praxis zeigt: ML- beziehungsweise KI-Projekte in Reinkultur existieren kaum. Fast immer ist ein klassisches Softwareprojekt die Ursache (s. Abb. 1). Die Beteiligten stoßen auf einen Aspekt oder auf eine Anforderung, die auf den ersten Blick für den Einsatz einer datengetriebenen Lösung spricht. Das kann beispielsweise die Absatzprognose sein, die ein Element eines neuen Warenwirtschaftssystems ist. Ihr Ziel ist das Schätzen der Verkaufszahlen für einzelne Produkte in der nächsten Woche oder im nächsten Monat. Auf Basis dieser Schätzungen stößt das Warenwirtschaftssystem Bestell- und Logistikprozesse an. Zahlreiche Faktoren beeinflussen den Absatz in einem Zeitraum. Je nach Branche und Produkt sind das Aspekte wie Wetter, Jahreszeit, Kalenderwoche, historische Absätze, Großveranstaltungen, Preisentwicklung auf dem Rohstoffmarkt, oder Absatz von Komplementärgütern.
Die Reihe ließe sich beliebig lang fortsetzen. Diese kurze Auflistung zeigt: Ein Mensch kann diese Vielzahl von Faktoren und Zusammenhängen nicht analysieren. Für ihre Prognosen setzen Experten aus Vertrieb oder Einkauf auf das Beobachten einiger weniger Datensätze. Mit zunehmender Erfahrung entwickeln sie ein Bauchgefühl für ihre Planungen.
ML- und KI-Anwendungen fühlen sich in diesem Umfeld wohl. Je nach Unternehmenssituation setzen sie auf einer langen Reihe historischer Daten auf, die im bisherigen Warenwirtschafts- beziehungsweise ERP-System (Enterprise Resource Planning) erfasst sind. Die Vorteile datengetriebener Ansätze eröffnen sich Unternehmen aber nicht automatisch. Insbesondere ist ein breites Expertenwissen notwendig, um mit ML- beziehungsweise KI-Verfahren zu den gewünschten Ergebnissen zu kommen. EDDA setzt auf vier Rollen im Projekt. Diese Rollen entsprechen Fachwissen und Verantwortlichkeiten innerhalb der Entwicklung. Im Einzelnen sind das:
- Software Engineers: Sie sind für den gesamten Softwareentwicklungsprozess und das Implementieren der Anwendung verantwortlich. Sie integrieren den ML-/KI-Entwicklungsteil in das übergeordnete Softwareprojekt. Darüber hinaus verantworten sie das Einführen der finalen ML-/KI-Anwendung. Dafür sollten sie ein grundlegendes Verständnis für ML- und KI-Techniken mitbringen.
- Data Scientist: Sie haben die Datengrundlage im Blick und stellen die notwendigen Modelle und ML-/KI-Komponenten zur Verfügung. Data Scientists sind interdisziplinäre Experten. Zu ihrem Wissensgebiet gehören unter anderem Informatik und Statistik. Sie bringen Programmierkenntnisse ebenso mit wie Erfahrung im Umgang mit großen Datenmengen. Sie verstehen die Details der Anwendung und sind federführend bei der Auswahl der ML-/KI-Algorithmen.
- Domain Experts: Sie bringen das Wissen über die geschäftlichen Rahmenbedingungen der Anwendung ins Spiel. Gleichzeitig sind sie häufig auch Anwender. Zu ihrem Wissen gehören detaillierte Kenntnisse über Geschäftsprozesse, Anwendungsszenarien, gesetzliche Rahmenbedingungen oder die Wettbewerbssituation. Gegebenenfalls zieht das Projektteam für spezifische Fragen weitere Experten von Fall zu Fall hinzu.
- Data Domain Experts: Sie sind der richtige Ansprechpartner beim Umgang mit Daten und Datenquellen innerhalb des Unternehmens oder der Branche. Im Gegensatz zu den Domain Experts haben sie eher eine technische Sichtweise. Data Domain Experts kennen sich mit den Datenstrukturen und -speichern in der Anwendungsdomäne aus. Sie sind nicht an der Anwendungsentwicklung beteiligt, sondern stellen die Daten lediglich zur Verfügung. Darüber hinaus erarbeiten sie mit den Softwareentwicklern die detaillierten Schnittstellenspezifikationen.
Während die ersten drei Rollenbilder aus anderen Projektvorgehensmodellen bekannt sind, ist der Data Domain Expert ein EDDA-spezifisches Konzept. Diese Rolle ist der überragenden Bedeutung von Daten für den gesamten ML-/KI-Entwicklungsprozess geschuldet. Ohne diese Brücke zwischen Daten und Geschäft drohen Projekte in die falsche Richtung zu laufen oder sich unnötig in die Länge zu ziehen. Denn ohne die Rolle des Data Domain Expert fallen die Aufgaben des Verstehens der unternehmensinternen Datenstrukturen und des Zusammenstellens der benötigten Daten dem Data Scientist zu. Er ist dafür aber nur eingeschränkt geeignet. Diese Experten machen sich gemeinsam daran, Schritt für Schritt die ML-/KI-Komponenten in einem Softwareprojekt zu entwickeln. Abbildung 1 beschreibt die einzelnen Phasen.
Am Anfang steht die Frage: Sollen Experten überhaupt auf ML-/KI-Techniken setzen?
Ohne Daten keine datengetriebenen Anwendungen
Der Auslöser für die Überlegungen in Richtung ML-/KI-Techniken ist häufig ein übergeordnetes Softwareprojekt. Die Beteiligten vermuten zunächst, dass sich für einen Teilaspekt des Projekts datengetriebene Anwendungen eignen. Ein Stück weit ist diese Phase des Prozesses zufallsgetrieben. Es gibt Indikatoren, die Hinweis auf ein mögliches ML-/KI-Potenzial geben. Beispielsweise wenn das zu lösende Problem aufgrund seiner Komplexität mit einem klassischen regelbasierten System nicht abzubilden ist.
Um bei der Absatzprognose zu bleiben: Die große Anzahl von Einflussfaktoren lässt sich händisch kaum zu einem Regelwerk zusammenzufassen. Ein weiterer Indikator sind wirtschaftliche Aspekte des Problems. Eventuell waren für die Absatzprognose bisher zahlreiche Experten wie Statistiker oder Mathematiker notwendig. Die Fachleute analysierten das Datenmaterial und sprachen daraufhin Handlungsempfehlungen aus. In dieser Konstellation kann ein ML-/KI-Business-Case stecken, der sich aufgrund des Automatisierungspotenzials der Prognose rechnet.
Am Anfang steht das Gefühl, dass ML-/KI-Anwendungen für eine Aufgabe geeignet sein können. Aber Gefühle können täuschen. Deswegen folgt eine intensive Analysephase. Hinter der schlichten Frage "Sind ML-/KI-Techniken geeignet?" steckt eine ganze Reihe an Fragestellungen und Entscheidungen. Die Projektbeteiligten investieren in diese Analyse viel Zeit und Energie. Hier stellen sie die Weichen für das gesamte Projekt. Eine Garantie für eine erfolgreiche Umsetzung gibt es nicht. Ein Scheitern des Projekts nach der positiven Datenanalyse durch die entsprechenden Experten ist jedoch unwahrscheinlich. Ziel ist es, möglichst früh ein detailliertes Bild über Inhalt, Qualität und Konsistenz der Datenbasis zu haben. Die dafür notwendigen Schritte lassen sich wie in Abbildung 2 dargestellt beschreiben.
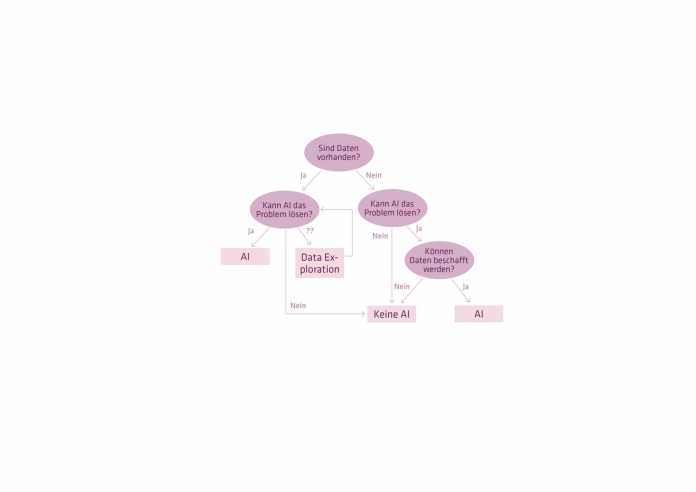
Der Ausgangspunkt ist die Frage nach der Verfügbarkeit von Daten – ohne sie keine datengetriebenen Anwendungen. Sind sie vorhanden, prüft der Data Scientist, ob ML- oder KI-Techniken die Ansätze sind, um die Aufgabenstellung zu lösen. Stecken beispielsweise in den historischen Daten über die Absatzzahlen der Vergangenheit Informationen, die dazu geeignet sind, die Entwicklung zu erklären? Dieses Prüfen der Daten kann zu drei Ergebnissen führen: Die Daten sind geeignet, dann geht es weiter in die Phase des Model Requirement.
Oder die Daten sind nicht die richtigen. Dann ist der Weg in Richtung ML-/KI-Anwendung versperrt. Die Aufgabe geht wieder zurück in den übergeordneten Softwareentwicklungsprozess. Eventuell prüfen die Beteiligten hier regelbasierte Ansätze. Oder die Beteiligten versuchen, die Aufgabe anders zu schneiden, um so den Einsatz von ML-/KI-Ansätzen doch noch zu ermöglichen. Die dritte Antwortoption: Der Data Scientist kann die Frage nach Eignung der Daten mit seinem Kenntnisstand nicht eindeutig beantworten. Dann folgt die Phase "Data Exploration", dazu später mehr.
Zunächst geht es im Entscheidungsbaum der Analysephase mit dem Strang "Es sind keine Daten vorhanden" weiter. Diese Situation bedeutet nicht das Ende der ML-/KI-Pläne. Um zu entscheiden, ob die Techniken auch bei dieser Ausgangslage zum Einsatz kommen können, prüft das Projektteam zunächst, welche Informationen notwendig wären. Um beim Beispiel der Absatzprognose zu bleiben: Wenn das Unternehmen Absatzzahlen und mögliche Einflussfaktoren bislang nicht systematisch nachverfolgt hat, können die Verantwortlichen zu dem Schluss kommen, dass diese in Zukunft gemessen werden sollen. In der Regel führt das dazu, dass es zunächst wieder eine regelbasierte Umsetzung gibt, die die Datengrundlage für die spätere ML-/KI-Anwendung schafft. Alternativ kann das Unternehmen fehlende Daten hinzukaufen, beispielsweise Rohstoffpreise oder Wetterdaten.
Auf Basis dieses Verfahren bewertet das Projektteam die Eignung von ML-/KI-Techniken. Ist die abschließende Beurteilung positiv, prüft der Data Domain Expert im nächsten Schritt, ob die Beteiligten die notwendigen Daten beschaffen können, sei es aus internen oder externen Quellen. Wenn ja, dann gelangt das Projekt in die Model-Requirements-Phase. Andernfalls geht die Aufgabenstellung auch hier zurück ins übergeordnete Softwareprojekt.
Exkurs Data Exploration
Diese Phase ist der Besonderheit des Umgangs mit Daten in ML-/KI-Projekten geschuldet. Wenn die Unsicherheit bezüglich Datenqualität und -aufbereitung in der frühen Projektphase zu groß ist, steigen die Experten tiefer in die Analyse der vorhandenen Daten ein. EDDA sieht dafür die sogenannte Data Exploration vor. Der iterative Prozess sorgt dafür, dass alle Beteiligten ein besseres Verständnis für die Daten entwickeln. Ein Verständnis, von dem der ganze Folgeprozess profitieren soll.
Data Scientists analysieren zunächst die Struktur und Muster in den Daten. Sie überarbeiten sie und visualisieren Zusammenhänge. Ziel ist, dass die Data-Domain- und Domain-Experten eine genaue Vorstellung von der Datenbasis gewinnen. In einem wöchentlichen Meeting – in Anlehnung an die Begriffe aus der agilen Softwareentwicklung als "weekly data scrum" bezeichnet – erörtert das Team die neuen Erkenntnisse. Den Fortschritt [–] das kann neuer Programmcode, aber auch das Prüfen weiterer Hypothesen sein – hält es im sogenannten Data Report fest. In ihm dokumentieren sie Daten, Cluster oder Verbindungen, aber auch das Fehlen von Datensätzen. Auf der Basis dieser Erkenntnisse und des besseren Datenverständnisses konkretisieren die Domain-Experten die Anforderungen an die zu entwickelnde ML-/KI-Anwendung. Die Ziele halten sie in einem Backlog fest. Auch das ist ein aus der agilen Entwicklung bekanntes Instrument.
Die Phase Data Exploration endet, wenn das Team zur Übereinkunft kommt, dass es die Anforderungen an die ML-/KI-Anwendung mit der Datenbasis erfüllen kann – oder eben nicht. Im letzten Fall geht die Aufgabe, wie bereits bekannt, zurück ins übergeordnete Softwareprojekt.
Anforderungen müssen klar sein
Wollen die Beteiligten den Weg in Richtung ML-/KI-Anwendung weiter beschreiten, geht es im nächsten Schritt um die Anforderungen an das Modell und um erste Architekturskizzen. Typische Fragestellungen in dieser Phase sind:
- Was ist das konkrete Ziel der ML-/KI-Anwendung?
- Wie wird es exakt spezifiziert?
- Welche Aspekte müssen die Beteiligten vor der Entwicklung und dem Betrieb klären?
- Welche Zielsetzung soll das System erfüllen beziehungsweise welche Benchmark gilt es zu übertreffen? Eine Anwendung für die Absatzprognose ist beispielsweise akzeptabel, wenn sie die Prognose der Experten aus Einkauf und Vertrieb übertrifft.
- Welche Genauigkeit muss das Modell liefern?
- Akzeptieren die Verantwortlichen bei der Prognose eine durchschnittliche Abweichung vom Ist-Wert von zehn Prozent?
- Oder muss das System die echten Absätze auf fünf Prozent genau treffen, damit die verbesserte Prognose betriebswirtschaftliche Auswirkungen hat?
Viele dieser Themen fallen in den Aufgabenbereich der Software Engineers. Gerade für das Definieren von Metriken fehlt den Experten des Fachbereichs häufig das Fachwissen. Diese Punkte lösen IT- und Fachabteilung nur in enger Abstimmung.
Das Requirements Engineering in klassischen Softwareprojekten legt den Fokus ausschließlich auf Funktionen und ignoriert zunächst technische Aspekte. Im Gegensatz dazu setzt sich das Team beim Model Requirement datengetriebener Anwendungen auch mit technischen Fragen auseinander. So stellen die Verantwortlichen sicher, dass die Architekturen der übergeordneten Anwendungen und die der ML-/KI-Komponenten zueinander passen.
Im EDDA-Vorgehensmodell stehen dem Team zum Lösen dieser Aufgaben zwei Artefakte zur Verfügung: die sogenannten Data Stories und Architecture Sketches. Data Stories dienen dazu, die Anforderungen an die ML-/KI-Anwendung mit den vorhandenen beziehungsweise notwendigen Daten zu verknüpfen. Das Team erfasst in den Data Stories Zusammenhänge und Korrelationen in den Daten, die für die Domäne relevant sind. Darüber hinaus helfen sie dabei, die Akzeptanzkriterien für Daten, beispielsweise Anforderungen an Genauigkeit und Signifikanz, im Blick zu behalten.
In den Architecture Sketches definieren die Beteiligten einerseits die ML-/KI-Komponentenarchitektur. Andererseits beschreiben sie die Verbindung der datengetriebenen Komponente mit der übergeordneten Anwendungsarchitektur. Themen sind darüber hinaus Abhängigkeiten mit Komponenten oder Datenquellen, Rückfallmechanismen bei Problemen der Anwendung oder ihre Lernfähigkeit.
Am Ende dieser Phase sollten alle Beteiligten ein klares Bild der Anforderungen und der technischen Zusammenhänge haben. Mit diesem Kenntnisstand geht es an das Bauen des ersten Modells.
Ärmel hochkrempeln und bauen
Was folgt, ist klassisches Prototyping: Die bisher gewonnen Erkenntnisse sind die Grundlage für das Entwickeln des Modells. Die verantwortlichen Teammitglieder bewerten und testen mögliche Algorithmen. Sie definieren die Datensätze wie Trainings- und Testdaten. Darüber hinaus arbeiten sie an Features beziehungsweise Labels, die dem Algorithmus die Arbeit mit den Daten ermöglichen.
Ein wichtiger Aspekt der Arbeit ist das sogenannte Feature Engineering. Hier entscheiden die Experten, welche Informationen ein Algorithmus braucht, um arbeiten zu können. Je nach Anwendungsfall und gewählter KI-Methode ist es nicht zielführend, alle Daten in das Modell einfließen zu lassen – nach dem Motto "viel hilft viel". Die Gefahr besteht, dass der Algorithmus sonst Zusammenhänge erkennt, die in der Realität nicht von Bedeutung sind.
Während des Model Development bauen und bewerten die Experten eine ganze Reihe von Prototypen. Diesen Zyklus durchlaufen sie so lange, bis sie die definierte Zielsetzung bezüglich der angestrebten Ergebnisqualität erreichen. Dabei spielen auch Fragen der Wirtschaftlichkeit eine Rolle: Die Lernkurve eines Algorithmus sieht aus wie eine typische Sättigungskurve. Am Anfang geht es steil nach oben, danach verflacht sie. Jedes weitere Prozent Genauigkeit erkaufen sich die Beteiligten mit überproportional viel Aufwand. Hier zahlt sich aus, dass das Team früh im Prozess eine genaue Vorstellung der Zielvorgaben entwickelte. Mit dem fertigen Modell geht es in die letzten Phasen der Entwicklung.
Am Ende wird es noch einmal ernst
Das Projektteam integriert den finalen Prototypen in die übergeordnete Software und die IT-Infrastruktur. Ab jetzt arbeitet die ML-/KI-Anwendung mit echten Daten. Für die Integration sind häufig Anpassungen notwendig, beispielsweise um Anforderungen an Benutzeroberflächen oder Schnittstellen zu genügen. Das erfordert ein erneutes Testen der Komponente.
Wenn alles wie gefordert funktioniert, geht die ML-/KI-Anwendung in die Phase Operations. Auch das kann anders ablaufen als der Betrieb klassischer Softwareanwendungen. Die Komponenten sammeln und verarbeiten im Laufe der Zeit ständig neue Daten. Falls die Anwendung ihre Entscheidungen an die neuen Daten anpasst – also lernt –, müssen die Experten regelmäßig beobachten, ob das Ergebnis dieses Lernprozesses mit den ursprünglichen Anforderungen übereinstimmt.
Fazit
Die Ausführungen zeigen: Wer klassische Softwareentwicklung beherrscht, muss nicht zwangsweise auch erfolgreich datengetriebene Anwendungen entwickeln können. Die Unterschiede zwischen den Konzepten müssen die Beteiligten bei ihren Planungen berücksichtigen. Das EDDA-Vorgehensmodell dient als Grundlage für die schlüssige Projektorganisation. Ein Rest Unsicherheit, darüber müssen sich die Verantwortlichen klar sein, wird bei der Entwicklung von ML-/KI-Anwendungen aber bleiben.
Prof. Dr. Volker Gruhn
gründete 1997 die adesso AG mit und ist heute Vorsitzender des Aufsichtsrats. Er ist Inhaber des Lehrstuhls für Software Engineering an der Universität Duisburg-Essen. Sein Forschungsschwerpunkt in diesem Bereich liegt auf der Auseinandersetzung mit den Auswirkungen der digitalen Transformation. Er beschäftigt sich insbesondere mit der Entwicklung und dem Einsatz von Cyber-Physical Systems und datengetriebenen KI-Anwendungen.
Nils Schwenzfeier
hat Informatik studiert und promoviert aktuell an der Universität Duisburg-Essen am Lehrstuhl für Software Engineering insbesondere mobile Anwendungen. An der Schnittstelle von Forschung und Praxis bringt er als Gründer und Geschäftsführer der TamedAI GmbH aktuelle Forschungsergebnisse mit wirtschaftlichen Lösungen zusammen und bietet Unternehmen eine technologische Plattform für die Umsetzung und den Betrieb von KI-Anwendungen.
Ole Meyer
hat Informatik studiert und promoviert aktuell an der Universität Duisburg-Essen am Lehrstuhl für Software Engineering insbesondere mobile Anwendungen. An der Schnittstelle von Forschung und Praxis bringt er als Gründer und Geschäftsführer der TamedAI GmbH aktuelle Forschungsergebnisse mit wirtschaftlichen Lösungen zusammen und bietet Unternehmen eine technologische Plattform für die Umsetzung und den Betrieb von KI-Anwendungen.
Dr. Marc Hesenius
ist Postdoc am Lehrstuhl für Software Engineering der Universität Duisburg-Essen. Seine Forschungsschwerpunkte liegen im Bereich der Entwicklungsprozesse und -Werkzeuge für datengetriebene Anwendungen sowie den technischen Aspekten von Mensch-Maschine-Interaktion.
(ane [1])
URL dieses Artikels:
https://www.heise.de/-4586595
Links in diesem Artikel:
[1] mailto:ane@heise.de
Copyright © 2019 Heise Medien