

Web Scraping mit Azure Functions und Python
Serverless-Funktionen ermöglichen die automatisierte Datenanalyse im Internet, wie das Beispiel zum Web Scraping von COVID-19-Informationen verdeutlicht.

(Bild: PureSolution/Shutterstock.com)
- Vladimir Poliakov
Azure Functions sind – vergleichbar mit AWS Lambda oder Google Cloud Functions – eventbasierte Serverless-Funktionen, die sich bedarfsabhängig ausführen lassen. Auslöser für eine Azure Function kann ein HTTP-Request für die Web-API-Schnittstelle sein. Als Trigger kommen aber auch ein eingehender IoT-Stream, eine Datenbankänderung oder das Ausführen zu einer vorgegebenen Zeit infrage.
Was sind Azure Functions?
Je nach Anforderung stellt der Anbieter der Azure Functions (Microsoft) die zugrundeliegenden Ressourcen der Cloud-Infrastruktur dynamisch bereit und skaliert sie proportional zur Nachfrage. Bei dieser dynamischen, bedarfsgesteuerten Bereitstellung der Serverless-Funktionen bezahlen Nutzer im Verbrauchstarif (Consumption Plan Hosting) nur für die Anzahl der Ausführungen, die Ausführungszeit und den Speicherverbrauch. Welche Kosten dabei entstehen können, zeigt das praktische Beispiel am Ende des Artikels.
Entwicklerinnen und Entwickler profitieren beim Einsatz von Serverless-Funktionen davon, sich keine Gedanken mehr über die Infrastruktur, also das Bereitstellen und Warten von Servern, machen zu müssen – stattdessen können sie sich vollständig auf den Development-Prozess ihrer Applikation konzentrieren. Allerdings sollten sie darauf achten, den Code nicht zu komplex zu gestalten, damit die Serverless-Funktion auch jederzeit schnell auf den Trigger beziehungsweise das auslösende Ereignis reagieren kann.
COVID-19: Ein Beispiel aus der Praxis
In der Regel kommen Azure Functions im Zusammenspiel mit anderen Cloud-Diensten zum Einsatz. Sie empfehlen sich aber auch in zwei beispielhaften Szenarien im Soloeinsatz:
- Zeitgesteuertes Web Scraping und Persistieren der Informationen in einer Cloud-Datenbank wie Cosmos DB für die spätere Verarbeitung oder Darstellung auf einem Dashboard (s. Abb. 1)
- Web-API eines KI-Modells (Azure Function getriggert per HTTP-Request)

Die Azure-Dokumentation beschreibt ausführlich das Erstellen einer Azure Function im Command Line Interface (CLI) und in Visual Studio Code. Dieser Artikel greift die Dokumentation auf und zeigt, wie sich eine Azure Function mit dem HTTP-Trigger in ein paar Handgriffen zu einem Web Scraper erweitern lässt. Danach erfolgt das Anbinden an Cosmos DB, um ihn anschließend als eine zeitgesteuerte Azure Function in der Cloud bereitzustellen. Dort sammelt sie täglich automatisiert Informationen aus dem Internet.
Konfigurieren einer Umgebung
Eine Azure Function in der Cloud testen zu können, setzt eine Registrierung im Azure Cloud Portal sowie ein aktives Abonnement (Subscription) voraus. Die Registrierung ist grundsätzlich kostenlos, das komplette Angebot steht jedoch nur für einen Testzeitraum von 30 Tagen frei zur Verfügung. Dauerhaft kostenfrei bleiben nur einige Komponenten – für die Azure Functions und Cosmos DB fallen zugriffsabhängige Kosten an.
Zur Vorbereitung auf die Arbeit mit den Serverless-Funktionen gilt es, die lokale Entwicklungsumgebung zu konfigurieren und die folgenden Tools beziehungsweise Erweiterungen zu installieren:
- Visual Studio Code
- Azure Functions Core Tools, Version 3.x
- die von Azure Functions unterstützte Python-Version (Im vorliegenden Beispiel Python 3.8)
- Python- und Azure-Functions-Erweiterungen für Visual Studio Code
Erweitern des neuen Azure-Function-Projekts
Unterstützt durch den Azure Function Wizard lässt sich in der vorkonfigurierten lokalen Entwicklungsumgebung ein neues Projekt mit dem Function HTTP Trigger anlegen. Der Trigger lässt sich über einen HTTP-Request auslösen, sodass sich auch die Ergebnisse der Azure Function schneller überprüfen und gegebenenfalls anpassen beziehungsweise ändern lassen.
Die wichtigsten Komponenten einer Azure Function sind die Datei mit dem Code in einer der unterstützten Programmiersprachen – im vorliegenden Python-Beispiel mit dem Default-Namen __init__.py – und die Datei mit den Konfigurationsinformationen function.json. Letztere definiert den Namen der Code-Datei (sogenannter Einstiegspunkt), den Trigger, die Abhängigkeiten sowie weitere Konfigurationseinstellungen der Function.
Jede Function verfügt nur über einen einzigen Trigger. Anhand der Konfigurationsdatei ermittelt die Azure-Runtime-Engine, welche Ereignisse es zu überwachen gilt und wie die Daten in die Funktionsausführung zu übergeben beziehungsweise aus dieser zurückzugeben sind. Im Beispiel ist der Trigger ein HTTP-Request und die Ausgabe erfolgt via HTTP-Protokoll direkt im Browser:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}Wichtig für die Python Function ist darüber hinaus die Datei requirenments.txt, die eine manuell zu pflegende Liste der für das Deployment notwendigen Python-Pakete enthält:
# DO NOT include azure-functions-worker in this file
# The Python Worker is managed by Azure Functions platform
# Manually managing azure-functions-worker may cause unexpected issues
azure-functions
pandas
lxmlEin praxisnahes Beispiel ist das tägliche Ermitteln von Information aus dem Internet, die sich nicht oft ändern: Die deutsche Wikipedia-Seite zu COVID-19 sammelt Daten und Entwicklungen der COVID-19-Infektionen in den einzelnen Bundesländern sowie in ganz Deutschland (s. Abb. 2).

Für das Parsen der HTML-Seiten beim Web Scraping bieten sich verschiedene Vorgehensweisen und Methoden an, von regulären Ausdrücken bis zum Einsatz der Beautiful-Soup-Bibliothek. Im Beispiel kommt ein Web Scraper auf Basis der Python-Bibliothek pandas zum Einsatz. Das Parsen der HTML-Seite erfolgt direkt in der Datei __init__.py (s. Zeilen 20 und 21 in Listing 3).
import logging
import time
import datetime as dt
import pandas as pd
import json
import azure.functions as func
def main(req: func.HttpRequest, doc: func.Out[func.Document]) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
###########################
# Custom code BEGIN #
###########################
# just get the currently server time
ctime = time.ctime()
# get info from web site
df_COVID_Wiki = pd.read_html('https://de.wikipedia.org/wiki/COVID-19-Pandemie_in_Deutschland', decimal=',', thousands='.')
df_COVID_BUND = df_COVID_Wiki[3]
###########################
# Custom code END #
###########################
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
# make formatted string
response = (
#f"Hello, <b>{name}</b>. The currently server time is {ctime}. This HTTP triggered function executed successfully.\n\n"
f"Hello, {name}. The currently server time is {ctime}. This HTTP triggered function executed successfully.\n\n"
f"COVID-19 7-Tage-Inzidenz der Bundesl�nder:\n"
f"{df_COVID_BUND}"
)
#return func.HttpResponse(f"Hello, {name}. The currently server time is {ctime}. This HTTP triggered function executed successfully.\n\n {df_COVID_BUND}")
#return func.HttpResponse(f"{response}", mimetype="text/html")
return func.HttpResponse(f"{response}")
else:
return func.HttpResponse(
"This HTTP triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)Damit sind die beiden wesentlichen Anpassungen der Azure Function für das Web Scraping konfiguriert. Da sich die Azure-Plattform automatisch um die Infrastruktur kümmert, steht vor der Ausführung bei Azure lediglich ein lokaler Test an.
Lokales Testen der Azure Function
In Visual Studio Code lässt sich dazu die Applikation im Terminal mit F5 starten. Der lokal ausgeführte URL-Endpunkt ihrer über HTTP ausgelösten Funktion wird daraufhin im Terminal angezeigt (s. Abb. 3). Die URL lässt sich direkt im Browser oder in Postman ausführen, einer Collaboration-Plattform für die API-Entwicklung. Ist der Test erfolgreich abgeschlossen, lässt sich die Azure Function aus Visual Studio Code heraus in der Cloud bereitstellen.
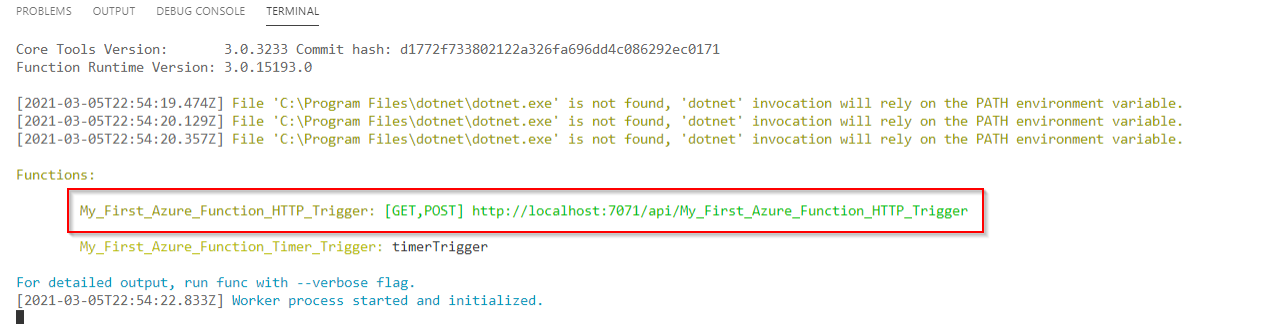
Deployment und Testen des Projekts in der Cloud
Für den produktiven Einsatz empfiehlt sich das Anlegen von Deployment-Pipelines über spezialisierte Continuous-Deployment-Tools. Der Einfachheit halber beschränkt sich das Beispiel aber auf das Bereitstellen der Serverless-Funktion durch Anstoß über den Azure Function Wizard aus Visual Studio Code heraus.
Das Deployment kann dabei in einer neuen oder in einer bereits bestehenden Azure Function erfolgen, deren Inhalt in einem solchen Fall überschrieben wird. Im Interesse der Flexibilität beim Benennen zusätzlicher Komponenten wie der Resource Group bietet sich das Anlegen im Vorfeld an (s. Abb. 4)

Steht die Azure Function bereit, lässt sie sich analog zum lokalen Test im Web-Browser oder in Postman aufrufen. Abbildung 5 zeigt die Ergebnisse des Web Scraper für die 7-Tage-Inzidenz aller Bundesländer.
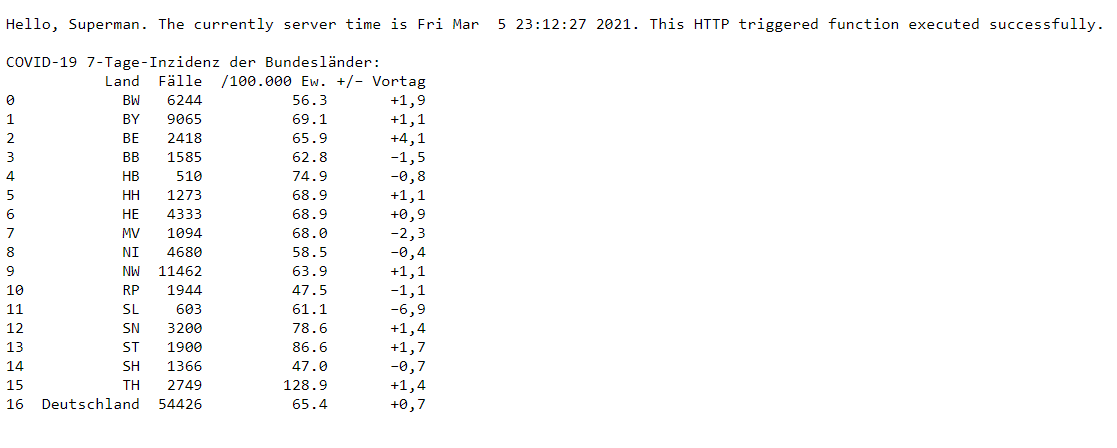
Das erste Ziel ist damit erreicht: Ein Web Scraper als Azure-Function-HTTP-Trigger, der auf einen HTTP-Request reagiert, sammelt automatisch die gewünschten Daten. Allerdings kann er die Information noch nicht dauerhaft vorhalten (persistieren). Dazu bedarf es eines Speichers wie Azure Blob Storage, Azure SQL oder der NoSQL-Datenbank Cosmos DB. Microsoft bietet Cosmos DB auf der Azure-Plattform zu einem Verbrauchstarif an (Consumption Plan Hosting), bei dem lediglich Datenbank-Operationen und die Datenhaltung zu bezahlen sind. Da der Web Scraper im Beispiel normalerweise nur einmal täglich Daten sammelt, bleibt die benötigte Speicherkapazität überschaubar. Daher bietet sich Cosmos DB für diesen Use Case durchaus an.
Persistieren der Daten in Cosmos DB
Als vollständig verwaltete NoSQL-Datenbank bietet Azure Cosmos DB verschiedene API-Modelle, von denen im Beispiel eine Core-(SQL)-API zum Einsatz kommt – wie es in der Azure-Dokumentation " Schnellstart: Erstellen einer Python-Anwendung mithilfe eines SQL-API-Kontos für Azure Cosmos DB" beschrieben ist.
Ist die Datenbank bereit, lassen sich die Out-Bindings für die Cosmos DB in der Datei function.json konfigurieren. Wie Listing 4 zeigt, sind für HTTP-Trigger zwei Out-Bindungen definiert: eine als HTTP-Response, die andere als Cosmos DB. Der letzte Konfigurationsschritt erfordert ein Anpassen der Datei local.settings.json, in deren Connection String ein AccountEndpoint und ein AccountKey definiert sind (s. Listing 5).
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "cosmosDB",
"direction": "out",
"name": "doc",
"databaseName": "webscraper_covid19",
"collectionName": "nummer",
"createIfNotExists": "true",
"connectionStringSetting": "AzureCosmosDBConnectionString"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "python",
"AzureCosmosDBConnectionString": "AccountEndpoint=https://xxxxxxxx.azure.com:443/;AccountKey=xxxxxxxx"
}
}Beide Parameter finden sich im Azure-Portal bei den Settings Keys der Cosmos DB (s. Abb. 6)

Ist die Cosmos DB erstellt und konfiguriert, lassen sich die Ergebnisse des Parsens in der Datenbank ablegen. Als id-Spalte dient im Beispiel das ins String-Format "YYYYMMDD" konvertierte Datum des Web Scrapings. Das Umwandeln der Daten ins JSON-Format übernimmt die to_json(…)-Routine von pandas. Mit zwei Zeilen Code lassen sich die Informationen nach dem Parsen der HTML-Seite in der Cosmos DB speichern (s. Listing 6, Zeile 44).
import logging
import time
import datetime as dt
import pandas as pd
import json
import azure.functions as func
def main(req: func.HttpRequest, doc: func.Out[func.Document]) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
###########################
# Custom code BEGIN #
###########################
# just get the currently server time
ctime = time.ctime()
# get info from web site
df_COVID_Wiki = pd.read_html('https://de.wikipedia.org/wiki/COVID-19-Pandemie_in_Deutschland', decimal=',', thousands='.')
df_COVID_BUND = df_COVID_Wiki[2]
day = (dt.datetime.now().strftime('%Y%m%d'))
df_COVID_BUND_JSON = df_COVID_BUND.to_json(force_ascii=False)
###########################
# Custom code END #
###########################
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
# write to CosmosDB --> test
# doc.set(func.Document.from_dict({"id":"3","bundesland":"BE","anzahl_gesamt":1973,"anzahl_100T":53.8,"tendenz_vortag": -0.9,}))
# put df_COVID_BUND into CosmosDB
doc.set(func.Document.from_json('{"id":"'+(day)+'",' + df_COVID_BUND_JSON[1:-1] +'}'))
# make formatted string
response = (
#f"Hello, <b>{name}</b>. The currently server time is {ctime}. This HTTP triggered function executed successfully.\n\n"
f"Hello, {name}. The currently server time is {ctime}. This HTTP triggered function executed successfully.\n\n"
f"COVID-19 7-Tage-Inzidenz der Bundesl�nder:\n"
f"{df_COVID_BUND}"
)
#return func.HttpResponse(f"Hello, {name}. The currently server time is {ctime}. This HTTP triggered function executed successfully.\n\n {df_COVID_BUND}")
#return func.HttpResponse(f"{response}", mimetype="text/html")
return func.HttpResponse(f"{response}")
else:
return func.HttpResponse(
"This HTTP triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)Über den Cosmos DB Data Explorer im Azure-Portal sind die Ergebnisse einsehbar (s. Abb. 7).

Sobald die Azure Function sich fehlerfrei per HTTP-Request ausführen lässt und die Ergebnisse des Web Scraping sich persistent in der Cosmos DB ablegen lassen, kann der letzte Schritt erfolgen: den Azure-HTTP-Trigger in eine zeitgesteuerte Azure Function umzuschreiben.
Zeitgesteuerte Azure Function
Analog zum Erstellen einer Azure Function mit dem HTTP-Trigger hilft der Azure Function Wizard dabei, alle Dateien zu generieren, die für Azure Function Timer Trigger notwendig sind. Der bereits getestete HTTP-Trigger-Code zum Parsen der HTML-Seite lässt sich ohne Modifikation in den Time Trigger übertragen (s. Listing 7). Darüber hinaus muss das Zeitintervall als CHRON-Expression in der Datei function.json definiert sein. Zum Testen ist es sinnvoll, den Timer jede Minute laufen zu lassen ("0 1 * * * *"). Im Produktivbetrieb passt dann besser eine tägliche Ausführung – beispielsweise um 22:00 Uhr ("0 0 22 * * *"). Wichtig dabei ist, die Ausführungszeit vom Server abzurufen. Nur so lässt sich sicherstellen, dass eine Azure Function, die auf einem Server in den USA läuft, dann auch um 22:00 Uhr lokaler Zeit in den USA ausgeführt wird.
import logging
import datetime as dt
import pandas as pd
import azure.functions as func
def main(mytimer: func.TimerRequest, doc: func.Out[func.Document]) -> None:
utc_timestamp = dt.datetime.utcnow().replace(
tzinfo=dt.timezone.utc).isoformat()
###########################
# Custom code BEGIN #
###########################
# get info from web site
df_COVID_Wiki = pd.read_html('https://de.wikipedia.org/wiki/COVID-19-Pandemie_in_Deutschland', decimal=',', thousands='.')
# parse HTML and convert the data into JSON-String
day = (dt.datetime.now().strftime('%Y%m%d'))
df_COVID_BUND_JSON = df_COVID_Wiki[2].to_json(force_ascii=False)
# finalize the JSON-String and put the result into CosmosDB
doc.set(func.Document.from_json('{"id":"'+(day)+'",' + df_COVID_BUND_JSON[1:-1] +'}'))
###########################
# Custom code END #
###########################
if mytimer.past_due:
logging.info('The timer is past due!')
logging.info('Python timer trigger function ran at %s', utc_timestamp)
Der letzte manuelle Eingriff betrifft das Bekanntmachen der Out-Binding für die Cosmos DB in der Datei function.json. Diese Konfiguration lässt sich aus der HTTP-Trigger-Datei kopieren (s. Listing 8). Anschließend erfolgt der lokale Test der Serverless-Funktion, und bei erfolgreichem Abschluss kann man sie in der Cloud bereitstellen. Sofern der Connection String zur Cosmos DB noch nicht erstellt ist, kann das auch noch nach dem Deployment erfolgen (s. das Anpassen der Datei local.settings.json und Abb. 8). Anschließend ist der zeitgesteuerte Web Scraper einsatzbereit.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "mytimer",
"type": "timerTrigger",
"direction": "in",
"schedule": "0 0 22 * * *"
},
{
"type": "cosmosDB",
"direction": "out",
"name": "doc",
"databaseName": "webscraper_covid19",
"collectionName": "nummer",
"createIfNotExists": "true",
"connectionStringSetting": "AzureCosmosDBConnectionString"
}
]
}
Günstig, aber nicht ganz kostenlos
Laut Azure-Dokumentation fallen beim Verbrauchstarif zwar nur die Kosten für die Anzahl der Ausführungen, die Ausführungszeit und den Speicherverbrauch an, allerdings treten daneben noch geringe, versteckte Kosten auf. Dazu zählen die Kosten für das Speicherkonto (Storage Account) zum Aufbewahren des Codes der Azure Function und des Deployment-Pakets (im Beispiel ca. 36 MByte). Dafür fallen wenige Cent pro Monat an. Auch für weitere Services wie die Log Analytics bei der Fehlersuche oder -auswertung sind Kosten zu berücksichtigen. Im vorgestellten Use Case summierten sich die Kosten bei täglichem Ausführen über einige Wochen auf wenige Cent (s. Abb. 9).
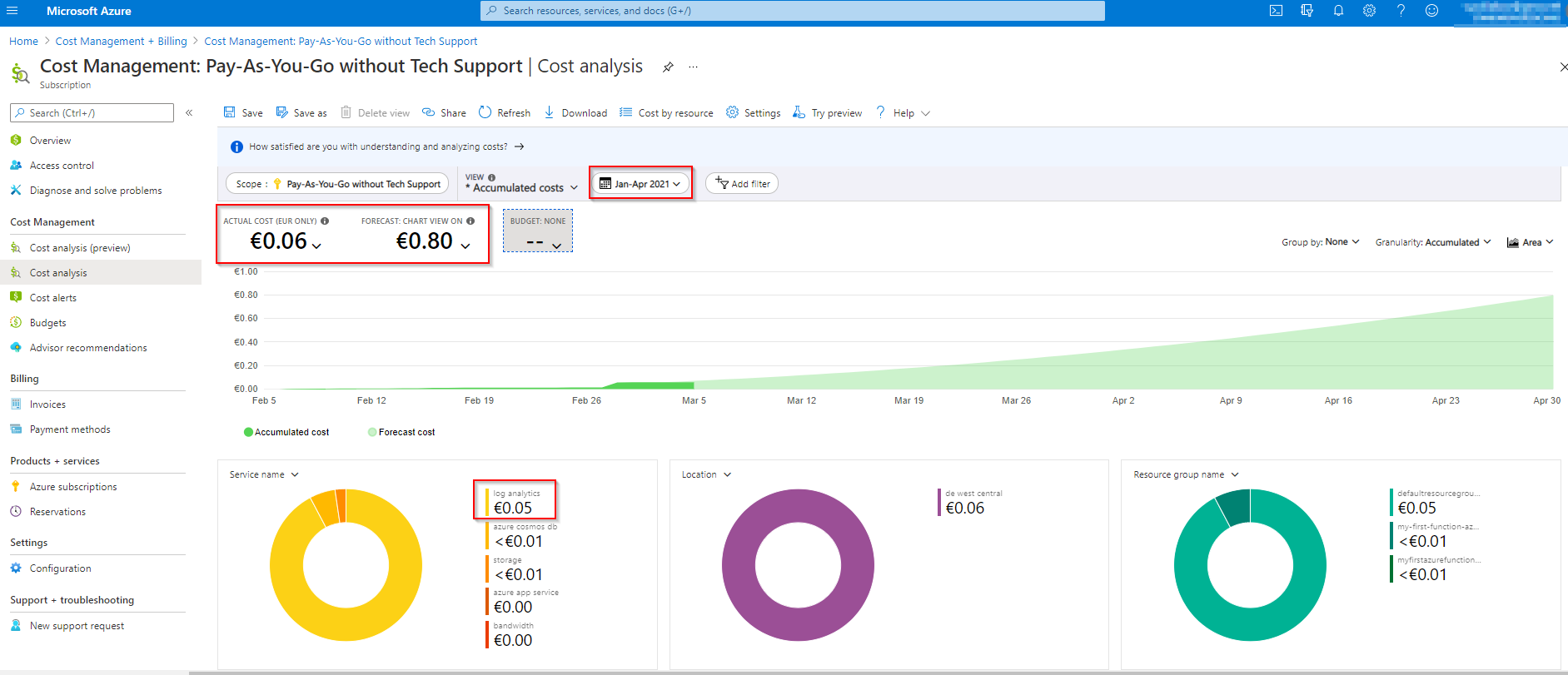
Zusammenfassung und weitere Schritte
Das Beispiel zeigt, dass sich mit wenig Aufwand schnell eine Azure Function für einen praktischen Use Case erstellen lässt. Dabei sind weitere Anpassungen denkbar, beispielsweise sind Alternativen zur Core (SQL) API bei der Cosmos DB oder für die Azure Table API beim Dashboard für andere Anwendungsszenarien womöglich besser geeignet. Im Auge behalten sollten Entwicklerinnen und Entwickler auch die Kosten bei der ausgehenden Datenübertragung, weil diese von der Azure-Region und dem Datenvolumen abhängig sind.
Azure Functions vereinfachen in jedem Fall den ersten Schritt in die Cloud. Im produktiven Einsatz gilt es dann jedoch, weitere Themen zu beachten wie Security, Abrechnung und automatisches Deployment.
Vladimir Poliakov
absolvierte 1995 das Studium an der Russian State Hydrometeorological University (RSHU) in St. Petersburg und arbeitete im Forschungsinstitut für Arktis und Antarktis. Nach seiner Auswanderung nach Deutschland war er seit 1998 in der IT-Branche als Entwickler, DBA, System-Architekt, BI- und Big Data-Spezialist aktiv und ist zurzeit hauptberuflich als Data Engineer bei der TeamBank AG tätig.
Videos by heise
(map)
