
Webentwicklung: Detaillierte Linkvorschauen von Websites automatisiert erstellen
Neben Bildern und Videos bieten soziale Medien auch Links — die so nur wenig Informationen preisgeben. Mithilfe einer Vorschau können Entwickler das ändern.

(Bild: Javier Brosch/Shutterstock.com)
- Lars Kölker
Wer kein Developer ist, versteht vermutlich nicht, wohin ihn folgender Link führt: https://open.spotify.com/track/4uLU6hMCjMI75M1A2tKUQC. Nutzer erkennen zwar, dass sie zu Spotify geleitet werden, wissen aber nicht, welche Musik, welcher Podcast oder welcher Interpret dadurch zu erwarten ist. Um dieses Problem zu beheben, erstellen Social-Media-Websites eine Linkvorschau, die Usern verständlichere Informationen wie den Titel, ein Vorschaubild und so weiter anzeigt. Dieser Prozess wird von Fachleuten als "unfurling" (zu Deutsch "Entfaltung") bezeichnet.
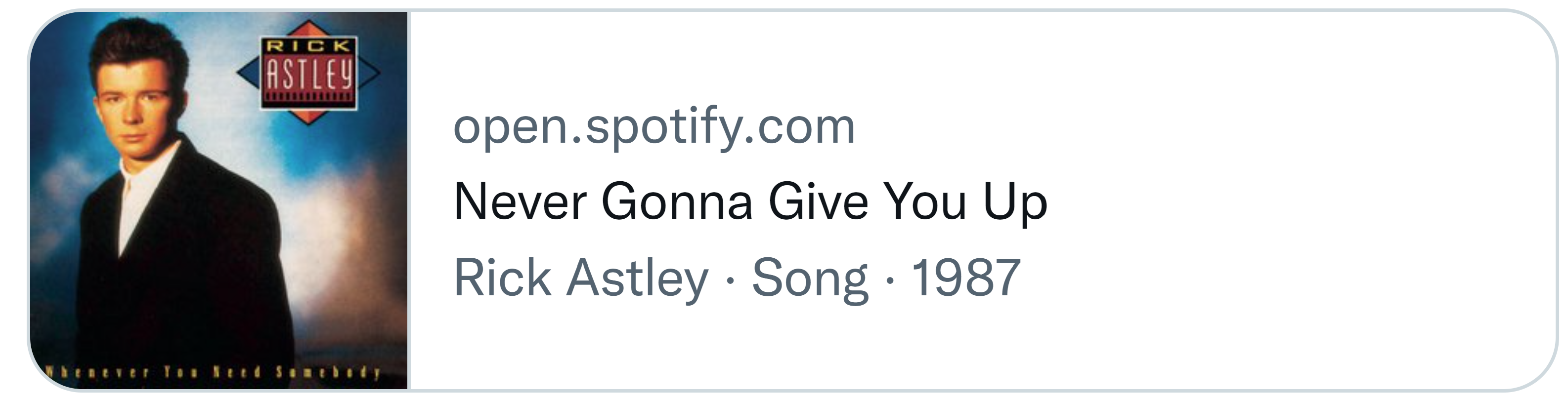
Die Linkvorschau von Spotify in Abbildung 1 zeigt den Titel, ein Vorschaubild, den Autor, das Jahr der Veröffentlichung sowie den Host an. Developer können durch das Angeben von Metadaten beeinflussen, wie die Linkvorschau in Social Media dargestellt wird. Zudem liest auch der Google-Bot einige der Metadaten aus, was die Darstellung in Suchergebnissen optimiert und die Suchmaschinenoptimierung (SEO) steigert.

Dieser Artikel zeigt, welche Metadaten Entwicklerteams angeben können, um eine bestmögliche Linkvorschau für Social Media zu erstellen. Dabei beschreibt er auch, welche Daten Developer aus Websites auslesen können, um eine Linkvorschau für (externe) Links auf der eigenen Website zu erzeugen. Neben generischen Attributen wie Titel, Vorschaubild und Beschreibung existieren weitere Informationen, die von Interesse sind:
- Autor
- Publikations-/Modifikationsdatum
- kostenpflichtig oder Registrierung erforderlich
- Kategorie beziehungsweise Genre
- Seitenname (statt "open.spotify.com" also "Spotify")
- Lesedauer
- Anzahl der Kommentare
- Live-Beitrag oder nicht
- … und gegebenenfalls Favicon sowie Farbschema
Zwei verschiedene Methoden zum Sammeln von Daten
Verschiedene Sammelmethoden stehen zur Datengewinnung für eine Linkvorschau zur Verfügung, von denen hier zwei Methoden näher betrachtet werden.
Entsprechend finden APIs auch beim Web Scraping Anwendung. Dabei ist es von Vorteil, dass APIs eine einheitliche Syntax sowie häufig eine Schnittstellendokumentation aufweisen, wodurch das Lesen der Ergebnisse berechenbar ist.
Videos by heise
Web Scraping (auch Screen Scraping, Data Mining oder Web Harvesting) beschreibt das automatisierte Sammeln von Daten aus dem Internet durch ein dafür entwickeltes Programm. In Gegensatz zu den APIs gibt es keine Schnittstellendokumentation, auf die sich ein Entwickler oder eine Entwicklerin verlassen können. Ryan Mitchell fasst es in ihrem Buch "Web Scraping with Python" verständlich zusammen: "The internet is one giant API with a somewhat poor user interface."
Quellcode in Document Object Model umwandeln
Bevor es an das "Scrapen" geht, sind einige Bibliotheken nötig, um das Markup in ein Document Object Model (DOM) umzuwandeln. Durch die Umwandlung in ein DOM können Entwickler dessen Knoten, bei denen es sich um HTML-Elemente handelt, abfragen. Bibliotheken existieren für die aktuellen Programmiersprachen. In diesem Beitrag kommt exemplarisch Node.JS zum Einsatz. Eine Portierung der durchgeführten Abfragen in andere Sprachen können Entwickler ebenfalls leicht umsetzen. Nach der Installation von Node.JS kann das Entwicklerteam ein Testprojekt aufsetzen. Dazu erstellt es einen Ordner, öffnet ihn in der Kommandozeile und führt den Befehl npm init -y aus, um das Projekt zu initiieren. Anschließend installieren die Entwickler die Pakete "JSDOM" und "Axios": npm install jsdom axios
Mit deren Hilfe fragt das Programm den Inhalt einer Website an und wandelt ihn in ein DOM um, wie folgendes Listing zeigt:
const axios = require('axios');
const { JSDOM } = require('jsdom');
(async () => {
const url = 'https://open.spotify.com/track/4uLU6hMCjMI75M1A2tKUQC';
const response = await axios.get(url);
const body = response.body;
const { document } = (new JSDOM(html)).window;
})(); Listing 1: Anfragen und Einlesen des HTML-Quellcodes eines Spotify-Songs mittels "Axios"
Im weiteren Verlauf ist es dann möglich, über document-Anfragen an das DOM stellen.
Wichtige und verbreitete Meta-Tags im Einsatz
Metainformationen werden in HTML unter anderem in meta-Elementen gespeichert. Diese befinden sich für gewöhnlich im Head eines HTML-Dokuments und weisen folgenden Aufbau auf: <meta name="author" content="Lars Kölker">.
Die HTML-Spezifikation gibt dabei lediglich folgende im weiteren Verlauf interessanten Werte für das name-Attribut vor:
- application-name
- description
- author
- theme-color und
- color-scheme
Eine wichtige Rolle spielt das title-Element, das nach der Spezifikation ebenfalls unter Metadaten fällt. Will eine Entwicklerin etwa alle Autoren in einem HTML-Dokument abfragen, kann sie die DOM-Abfrage aus dem folgenden Listing mittels document ausführen.
const elements = document.querySelectorAll('meta[name="author"]');
const authors = Array.from(elements)
.map(element => element.getAttribute('content')); Listing 2: Abfragen aller Autoren eines HTML-Dokuments
Das Open Graph Protocol als de-facto-Standard
Neben den standardisierten Metadaten gibt es das Open Graph Protocol (OGP), die "de facto Standard-Erweiterung". Dieses Protokoll ergänzt die Angabe von Vorschaubildern, Videos und Audiodateien, ermöglicht das Festlegen eines Typen (wie Artikel, Musik oder Website) sowie weiterer Metadaten für das HTML-Dokument. Dabei überschneidet sich das OGP mit einigen vereinheitlichten Metadaten. Es unterscheidet zwischen den verpflichtenden Metadaten og:title, og:type, og:image, og:url und folgenden optionalen Metadaten
og:audioog:descriptionog:determinerog:localeog:locale:alternateog:site_nameog:video
Die Deklaration der OGP-Daten weicht minimal von den standardisierten Metadaten ab:
<meta property="og:title" content="Never Gonna Give You Up">
<meta property="og:type" content="music.song">
<meta property="og:image"
content="https://i.scdn.co/image/ab67616d0000b273255e131abc1410833be95673">
<meta property="og:url"
content="https://open.spotify.com/track/4cOdK2wGLETKBW3PvgPWqT">Listing 3: Angabe der erforderlichen Open-Graph-Metadaten für einen Spotify-Song
Anstelle des name-Attributs verwendet das OGP in Listing 3 das property-Attribut. Abhängig vom Typ og:type können weitere grundlegende OGP-Metadaten nötig sein. Für einen Song wären dies zum Beispiel:
music:durationmusic:albummusic:album:discmusic:album:trackmusic:musician
Gesonderte Metadaten folgen Open Graph Protocol
Die Angabe der gesonderten Metadaten für einen Song folgt dem Schema des Open Graph Protocol:
<meta name="music:duration" content="214">
<meta name="music:album"
content="https://open.spotify.com/album/6N9PS4QXF1D0OWPk0Sxtb4">
<meta name="music:album:track" content="1">
<meta name="music:musician"
content="https://open.spotify.com/artist/0gxyHStUsqpMadRV0Di1Qt">Listing 4: Gesonderte OGP-Metadaten zur Deklaration eines Songs
Der einzige Unterschied zum OGP-Standard in Listing 4 besteht darin, dass das Präfix og durch eine dem Typ entsprechende Alternative (hier music) ausgetauscht wird. Entwicklerinnen und Entwickler sollten dabei jedoch beachten, dass sich nicht jede Website strikt an die OGP-Vorgaben hält. Beim dargestellten Song von Spotify fehlt etwa die Angabe des Albums (music:album:disc), da sie aus Sicht von Spotify vermutlich irrelevant ist.
Neben dem Song gibt es weitere Typen:
music.albummusic.playlistmusic.radio_stationvideo.movievideo.episodevideo.tv_showvideo.otherarticlebookprofilewebsite
Zudem dokumentiert die offizielle Seite nicht alle OGP-Metadaten. So dokumentiert Meta/Facebook etwa die Eigenschaft article:content_tier, die auf ogp.me nicht erwähnt wird. Wer die Vorschau testen möchte, kann dazu den LinkedIn Post Inspector heranziehen, der jedoch nicht alle Eigenschaften des Open Graph Protocol betrachtet. Die Twitter Cards ähneln dem OGP stark. Hier existieren jedoch einige zusätzliche Meta-Tags wie das Twitter-Handle. Die Angabe von Metadaten erfolgt mit dem Präfix twitter. Die Angabe des Twitter-Handles für die Twitter Card eines Spotify-Songs hat dann die folgende Form: <meta name="twitter:site" content="@spotify">
Weitere Angaben wie twitter:title, twitter:description sind für das Erstellen einer eigenen Linkvorschau redundant, können jedoch als Fallback verwendet werden, falls korrespondierende Metadaten (description oder og:description) nicht gesetzt sind.
Twitter Card steuert Linkvorschau
Die Eigenschaft twitter:card wird von Twitter verwendet, um die Darstellung der Card (Linkvorschau) zu beeinflussen. Auch Dritte können sie interpretieren. So verwendet Slack die Angaben in Verbindung mit den Metadaten twitter:label1, twitter:data1, twitter:label2 und twitter:data2 für die eigene Linkvorschau. Entwicklerinnen können die Label/Data-Paare für die eigene Vorschau heranziehen. Sie enthalten benutzerdefinierte Angaben, wie etwa den Preis eines Produkts:
<meta name="twitter:label1" content="Preis">
<meta name="twitter:data1" content="€42"> Listing 5: Angabe des Produktpreises durch Twitter-Label
Inhalte erhalten über das Format oEmbed
Das oEmbed-Format weicht vom OGP und den Twitter Cards ab. Statt meta-Elemente auszulesen, spricht dabei ein Konsument ("consumer") die API-Schnittstelle des Anbieters ("provider") an, um Inhalte über die anzufragende Seite zu erhalten. Auch für den Spotify-Song gibt es eine oEmbed-Schnittstelle, die entweder ein Link-Element im Quellcode, die Angabe des Link-Headers oder ein Lookup in der Provider-Liste anfragen kann. Letztere Methode ist nicht empfehlenswert, da sie nur eine begrenzte Anzahl an Providern (aktuell 296) enthält und so nicht sichergestellt ist, dass der oEmbed-Endpunkt gefunden wird.
<link
rel="alternate"
type="application/json+oembed"
href="https://open.spotify.com/oembed?url=https%3A%2F%2Fopen.spotify.com%2Ftrack%2F4cOdK2wGLETKBW3PvgPWqT"
> Listing 6: Angabe der oEmbed-Schnittstelle für einen Spotify-Song
Die Anfrage des Endpunktes erfolgt durch document mit folgender Eingabe: document.querySelector('link[rel="alternate"][type="application/json+oembed"]')?.href;
Das JSON-Ergebnis – wie folgendes Listing es zeigt – ermöglicht das Abrufen des Endpunktes:
{
"html": "<iframe>...</iframe>",
"width": 456,
"height": 152,
"version": "1.0",
"provider_name": "Spotify",
"provider_url": "https://spotify.com",
"type": "rich",
"title": "Never Gonna Give You Up",
"thumbnail_url": "https://i.scdn.co/image/ab67616d00001e025755e164993798e0c9ef7d7a",
"thumbnail_width": 300,
"thumbnail_height": 300
} Listing 7: Resultat der Abfrage der oEmbed-Schnittstelle
Das Resultat aus Listing 7 enthält die optionalen Angaben Anbieter (provider_name), Titel (title), Thumbnail (thumbnail_url) sowie eine dynamische Vorschau (html). Die Vorschau existiert, wenn der Typ auf rich gesetzt ist, alternativ kann er die Werte photo, video und link enthalten. Die Angaben über den Autor (author_name, author_url) sowie die Cache-Dauer (cache_age) sind weiterhin optional. Grundsätzlich können Programmierer die oEmbed-Schnittstellen ohne Autorisierung abrufen. Allerdings verlangt Meta/Facebook zusätzlich einen API-Key, der über den Anfrage-Parameter access_token gesetzt wird.
Strukturierte Daten für bestimmte Teile der Webseite
Schließlich stehen den Entwicklern auch noch die strukturierten Daten zur Verfügung, bei denen die Implementierung durch Resource Description Framework in Attributes (RDFa), Mikrodaten oder JSON for Linked Data (kurz JSON-LD) erfolgt. Google empfiehlt JSON-LD, weshalb dieses Format hier genutzt wird. Im Gegensatz zu meta-Elementen oder dem oEmbed-Format beschreiben strukturierte Daten nicht zwangsläufig die komplette Website oder eine Unterseite, sondern können sich auch auf bestimmte Teile beschränken, etwa auf den Autor des Artikels oder das Unternehmen. Für die Angabe strukturierter Daten mittels JSON-LD verwenden Entwickler das script-Element als Container mit den strukturierten Daten als Inhalt:
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "MusicRecording",
"@id": "https://open.spotify.com/track/4cOdK2wGLETKBW3PvgPWqT",
"url": "https://open.spotify.com/track/4cOdK2wGLETKBW3PvgPWqT",
"name": "Never Gonna Give You Up",
"description": "Listen to Never Gonna Give You Up on Spotify. Rick Astley · Song · 1987.",
"datePublished": "1987-11-12",
"potentialAction": {
"@type": "ListenAction",
"target": [...],
"expectsAcceptanceOf": {
"@type": "Offer",
"category": "free",
"eligibleRegion": []
}
}
}
</script> Listing 8: script-Element mit JSON-LD Inhalt
Die Eigenschaften des Objekts entstammen dabei der korrespondierenden Schema-Seite, in diesem Fall MusicRecording. Dabei muss ein Programmierer immer sowohl @context als auch @type angeben. Neben diesen beiden und weiteren Eigenschaften aus Listing 8 lässt sich dann beispielsweise noch die Attribute duration oder byArtist hinzufügen (siehe Abb. 2). Die Eigenschaften übergeordneter Objekte können Entwicklerinnen und Entwickler ebenfalls nutzen. Bei MusicRecording wären dies CreativeWork und Thing.

In den geschilderten Fällen beschränken sich JSON-LD-Objekte nicht auf jeweils ein Objekt pro HTML-Dokument, sodass Entwicklerinnen auch weitere Objekte wie Organisation verwenden können. Zum Validieren können sie den Dienst Google Validation für strukturierte Daten verwenden.
Eigene Vorschau generieren
Die bisher in diesem Beitrag vorgestellten Daten wie Autor, Publikationsdatum und Genre sind grundsätzlich interessant für eine Linkvorschau. Nachdem in den vorangegangenen Abschnitten einzelne Methoden zur Datengewinnung erläutert wurden, geht es nun daran, diese zu einer Vorschau zusammenzusetzen. In den Codebeispielen überschneiden sich diverse Eigenschaften wie das Publikationsdatum oder die Beschreibung. Dies ist insbesondere für die Absicherung von Vorteil, da so die Wahrscheinlichkeit sinkt, dass ein Wert für die Vorschau nicht gefüllt ist. Für die Vorschau aus Abbildung 1 benötigen Entwickler Host, Titel, Beschreibung sowie ein Vorschaubild. Folgendes Listing zeigt, wie die Vorschau auf diese Werte zugreift:
function getMeta(name) {
const attribute = name.toLowerCase().startsWith('og:')
? 'property' : 'name';
const element = document.querySelector(`meta[${attribute}="${name}"]`);
if (element) {
return element.getAttribute('content');
}
}
const { hostname } = new URL(url);
const titleTag = document.querySelector('title');
const titleMeta = getMeta('og:title') || getMeta('twitter:title');
const title = titleTag ? titleTag.textContent : titleMeta;
const img = getMeta('og:image') || getMeta('og:image:url')
|| getMeta('og:image:secure_url') || getMeta('twitter:image');
const description = getMeta('description')
|| getMeta('og:description') || getMeta('twitter:description'); Listing 9: Datensammlung für die Linkvorschau mittels Node.js
Strukturierte Daten kommen in Listing 9 nicht zum Einsatz, da sie zur Replikation der Linkvorschau aus Abbildung 1 nicht nötig sind und Twitter lediglich die Beschreibung anzeigt. Grundsätzlich kann die Vorschau auch Autoren, Lesezeit und die Anzahl an Kommentaren ebenfalls anzeigen. Dies ist insbesondere bei Zeitungsartikeln und Blogbeiträgen von Interesse. So nutzt heise.de das Schema NewsArticle auf Artikelseiten, das unter anderem author und commentCount isAccessibleForFree enthält. Wer einen Überblick über verwendete JSON-LD-Schemata einer Website erhalten möchte, kann nachfolgenden Befehl in der Browser-Konsole ausführen: $$("script[type='application/ld+json']").map(x => JSON.parse(x.textContent))
Fazit: Drei Prominente Möglichkeiten zum Einbinden
Entwickler und Entwicklerinnen stehen für das Einbinden von Metadaten drei prominente Möglichkeiten zur Verfügung:
meta-Elemente,- das oEmbed-Format sowie
- strukturierte Daten.
Neben den Standardmetadaten der HTML-Spezifikation gibt es Ergänzungen durch das Open Graph Protocol und die Twitter Cards. Die Erweiterungen stellen detaillierte Informationen über die Website bereit. Im Gegensatz zu den meta-Elementen arbeitet das oEmbed-Format mit einer fixen Schnittstelle, die eine Webseiten-URL als Parameter entgegennimmt und dafür eine maschinenlesbare Vorschau im Format JSON oder XML zurückgibt. Die Schnittstelle ist entweder im Quellcode in einem Link-Element, im Link-Header oder in einer Provider-Liste enthalten.
Strukturierte Daten sind besonders gut für die Suchmaschinenoptimierung geeignet, lassen sich jedoch auch für das Erstellen einer Linkvorschau verwenden. Dabei betten Entwickler sie meistens in script-Elemente in einer Website ein und orientieren sich an vordefinierten Schemata wie dem Schema für einen Musiksong, für einen Zeitungsartikel oder für ein Unternehmen.
Für das Erstellen einer Linkvorschau von externen Seiten und für das Anreichern des eigenen HTML-Dokuments sollten Entwicklungsteams nach Möglichkeit alle drei genannten Varianten auslesen oder implementieren. Der dargestellte Quellcode dient lediglich der Veranschaulichung. Für den produktiven Einsatz sollten Entwickler dedizierte Bibliotheken wie den openGraphScraper oder oembed.js verwenden. Bei strukturierten Daten sollten sie zudem nicht nur JSON-LD auslesen, da einige Seiten noch Mikrodaten einsetzen. An dieser Stelle ist die Verwendung eines Mikrodaten-Parsers am sinnvollsten.
Zuletzt noch ein Experiment: Mit folgendem Code lässt sich eine Liveansicht der Metadaten dieses Artikels betrachten:
....
<pre>
<code id="live-structured-data">
</code>
</pre>
<script>
const output = document.getElementById('live-structured-data');
const jsonLd = JSON.parse(document.querySelector('script[type="application/ld+json"]').textContent);
output.textContent = JSON.stringify(jsonLd, null, 2);
</script>
....Das Ergebnis könnte dann wie folgt aussehen:

(Bild: Lars Kölker)


Lars Kölker
hat Wirtschaftsinformatik an der Hochschule Weserbergland (HSW) studiert. Er arbeitet als Full Stack Developer bei der AMCON Software GmbH, ist im Bereich der Softwareentwicklung selbstständig und freiberuflicher Lehrbeauftragter an der HSW. Sein Techstack umfasst vor allem Webtechnologien wie TypeScript, React, HTML, CSS, aber auch objektorientierte Programmiersprachen wie C#.
(sih)
