Machine Learning: Datensätze finden und nutzen mit Croissant von Google und Co.

(Bild: Rainald Menge-Sonnentag)
Das ML-Metadatenformat Croissant liegt in Version 1.0 vor. Neben der Spezifikation gibt es eine Library und einen visuellen Editor zum Verarbeiten der Inhalte.
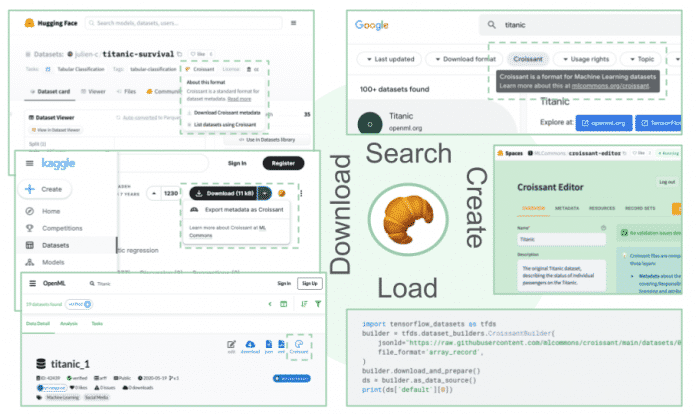
Google hat in seinem Research-Blog ein neues Metadatenformat für Machine Learning vorgestellt: Croissant beschreibt Datensätze, um sie für ML-Anwendungen einzusetzen.
Das Format dient sowohl dazu, Datensätze beim Veröffentlichen zu beschreiben, als auch passende Datensätze zu finden und in ein ML-Framework einzulesen.

(Bild: Google)
Croissant ist aus einer Zusammenarbeit mehrerer Forschungseinrichtungen und Firmen im MLCommons-Konsortium entstanden.
Mehr als klassische Datenbeschreibung
Das Metadatenformat baut auf die Datensatzbeschreibung von Schema.org [1] auf und erweitert sie um spezielle Beschreibungen für ML-Anwendungen, um beispielsweise strukturierte und unstrukturierte Daten zu kombinieren.
Spezifisch für den Einsatz zum Trainieren von Machine-Learning-Modellen ist die Option, festzulegen, welche Datensätze für das Training, welche zum Testen und welche zum Validieren gedacht sind.
Croissant für Menschen und Maschinen
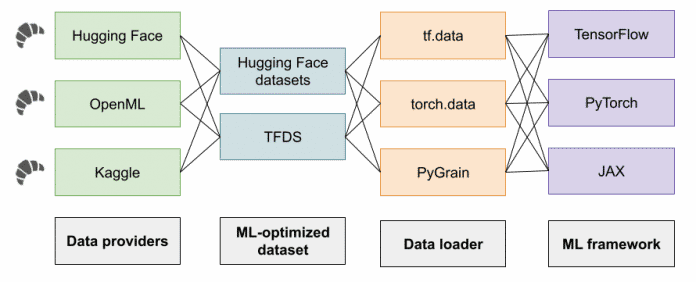
Croissant dient dazu, dass einerseits unterschiedliche Frameworks und andere ML-Tools die Daten einheitlich verarbeiten können, und andererseits, dass Data Scientists eine Beschreibung der Inhalte erhalten.
(Bild: MLCommons)
Das Thema Responsible AI (RAI) steht von Anfang an im Fokus. Das Croissant-RAI-Vokabular [2] zielt auf unterschiedliche Anwendungsfälle, um unter anderem die Sicherheit und Fairness von KI zu bewerten, die Daten rückverfolgen zu können und sicherzustellen, dass Compliance-Vorgaben eingehalten werden.
Spezifikation, Beispiele und Tools
Mit der frischen Version 1.0 von Croissant ist die vollständige Spezifikation des Formats erschienen [3]. Croissant-Metadaten werden im JSON-LD-Format abgelegt.

Am 24. und 25. April 2024 findet in Köln die Minds Mastering Machines [4] statt. Die von iX und dpunkt.verlag ausgerichtete Fachkonferenz jenseits des KI-Hypes richtet sich an Data Scientists, Data Engineers und Developer, die Machine-Learning-Projekte in die Realität umsetzen.
Das Programm der Konferenz [5] bietet an zwei Tagen gut 30 Vorträge in drei Tracks unter anderem zu folgenden Themen:
- Einführung in Large Language Models
- Mehr Nachvollziehbarkeit dank Explainable AI
- Federated Learning in Theorie und Praxis
- Automatische Codemigration mit LLMs
- Vektordatenbanken-Optimierung
- Spagat zwischen Bias und Fairness
- AI Act & Co.
Noch bis zum 12. März sind Tickets für die Minds Mastering Machines [6] zum Frühbucherpreis von 969 Euro (alle Preise zzgl. MwSt.) erhältlich.
Die quelloffene Python-Library mlcroissant [7] kann die Metadaten generieren, validieren und einlesen. Außerdem existiert ein visueller Editor [8] zum Erstellen, Laden und Betrachten der Inhalte.
Plattformen und Werkzeuge
Zum Release der Version 1.0 starten die Plattformen Kaggle, Hugging Face und OpenML damit, Datensätze im Croissant-Format anzubieten.
Bei den Frameworks sind TensorFlow, PyTorch und JAX angebunden. Auf GitHub finden sich Beispieldatensätze [9], und ein interaktives Jupyter Notebook auf Google Colab [10] bietet ein Tutorial für die Arbeit mit der Python-Library mlcroissant.
Weitere Details lassen sich der Ankündigung im Google-Research-Blog [11] und dem GitHub-Repository von Croissant [12] entnehmen.
(rme [13])
URL dieses Artikels:
https://www.heise.de/-9648458
Links in diesem Artikel:
[1] https://schema.org/Dataset
[2] https://mlcommons.github.io/croissant/docs/croissant-rai-spec.html
[3] https://mlcommons.github.io/croissant/docs/croissant-spec.html
[4] https://www.m3-konferenz.de/
[5] https://www.m3-konferenz.de/programm.php
[6] https://www.m3-konferenz.de/tickets.php
[7] https://github.com/mlcommons/croissant/tree/main/python/mlcroissant
[8] https://github.com/mlcommons/croissant/tree/main/editor
[9] https://github.com/mlcommons/croissant/tree/main/datasets
[10] https://colab.research.google.com/github/mlcommons/croissant/blob/main/python/mlcroissant/recipes/introduction.ipynb
[11] https://blog.research.google/2024/03/croissant-metadata-format-for-ml-ready.html
[12] https://github.com/mlcommons/croissant
[13] mailto:rme@ix.de
Copyright © 2024 Heise Medien