

LATTE3D: Nvidia-Forschungsprojekt erzeugt 3D-Objekte fast in Echtzeit
Nvidia Research hat mit LATTE3D einen Text-zu-3D-Generator vorgestellt, der verspricht, deutlich schneller und besser zu arbeiten als vergleichbare Modelle.

Ein Nividia-Forschungsprojekt kann 3D-Objekte fast in Echtzeit erstellen.
(Bild: Nvidia)
Das Toronto AI Lab von Nvidia Research hat das Forschungsprojekt Large-scale Amortized Text-To-Enhanced3D Synthesis (LATTE3D) vorgestellt, ein KI-Modell zur Erzeugung von texturierten 3D-Objekten aus Text-Prompts. Nvidia verspricht, dass LATTE3D Textbeschreibungen besser und schneller in dreidimensionale Objekte umwandeln kann als vergleichbare Ansätze.
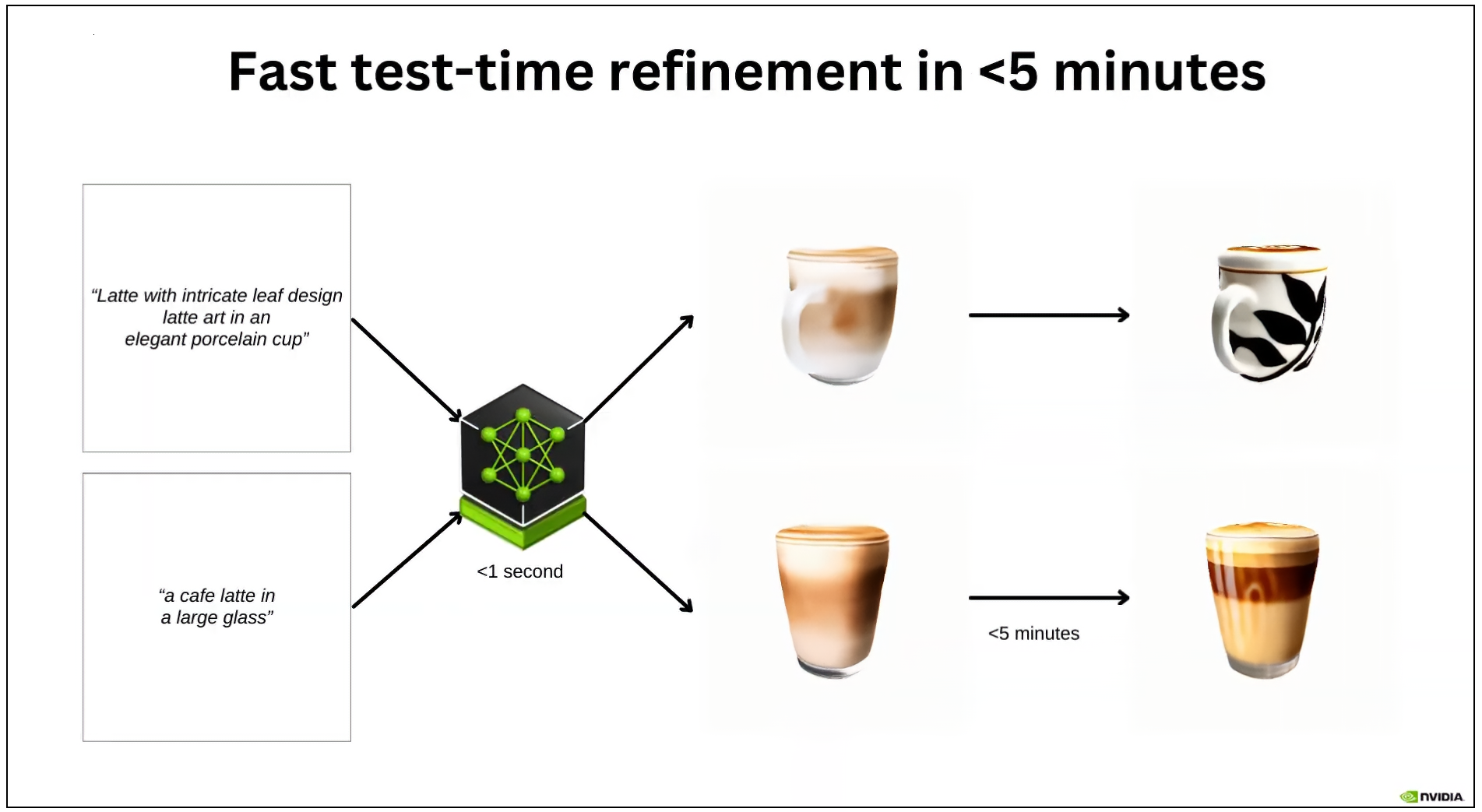
(Bild: Nvidia)
Der Kern von LATTE3D ist laut der Forschungsarbeit ein textbasierter 3D-Renderingprozess, der eine Textbeschreibung entgegennimmt und ein vollständiges 3D-Objekt liefert. Der Prozess ist in zwei Hauptphasen unterteilt: das anfängliche volumetrische Rendering, um die Textur und Geometrie des Objekts zu trainieren, und das anschließende Oberflächen-Rendering, um die Texturqualität zu verbessern. Auf diese Weise ließen sich hochwertige 3D-Assets in nur 400 Millisekunden erzeugen, schreiben die Forscher in ihrem Paper.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden. Damit können personenbezogene Daten an Drittplattformen (Google Ireland Limited) übermittelt werden. Mehr dazu in unserer Datenschutzerklärung.
Technische Grundlagen
LATTE3D verwendet zwei spezialisierte Netzwerke: ein Texturnetzwerk und ein Geometrienetzwerk, das auf einer Kombination von Triplanes (Abbildung von 3D-Strukturen durch die Projektion auf drei orthogonale Ebenen) und U-Nets (Convolutional Neural Networks zur Bildsegmentierung) basiert. Zunächst teilen sich die Encoder beider Netze die gleichen Gewichte, während in einer späteren Phase das Geometrienetz eingefroren und das Texturnetz aktualisiert wird. Die Effizienz der Triplanes wird laut Nvidia durch ein Multi-Layer-Perzeptron (MLP) erhöht, das Texteinbettungen als Eingabe verwendet.
Videos by heise
LATTE3D wurde mit 100.000 Texteingaben trainiert, die durch die Erweiterung von Bildunterschriften des LVIS-Objaverse-Subsets mittels ChatGPT generiert wurden. Laut Nvidia Research zeigt das System eine ausgeprägte Generalisierungsfähigkeit sowohl für neue, in der Distribution erweiterte Beschriftungen als auch für unbekannte, außerhalb der Distribution liegende Prompts.
Im Vergleich mit anderen Text-zu-3D-Generatoren wie MVDream, 3DTopia, LGM und ATT3D soll LATTE3D in Bezug auf Geschwindigkeit und Qualität der 3D-Objektgenerierung überlegen sein. Die Ergebnisse werden in Echtzeit auf einer A6000-GPU generiert, wobei laut Nvidia bis zu vier Samples für jeden Prompt möglich sind.
Die Einsatzmöglichkeiten solcher Text-zu-3D-Generatoren reichen vom schnellen Design ganzer Szenen bis hin zur Iteration von Objektdesigns. Bisher gibt es jedoch nur die Forschungsarbeit und Demovideos von LATTE3D, ausprobieren kann man den Text-zu-3D-Generator derzeit nicht.



(vza)