

Nvidia bringt künftig jedes Jahr neue GPU-Architekturen
Die KI-Milliarden machen sich bei Nvidia bemerkbar. Ab 2024 kommen jedes Jahr GPUs mit neuer Architektur. Spieler könnten profitieren.

Nvidias Server-GPU L40.
(Bild: Nvidia)
Nvidia will künftig doppelt so viele GPU-Rechenbeschleuniger vorstellen wie bisher. Die Topmodelle sollen nicht mehr mit einem Abstand von zwei Jahren, sondern jährlich erscheinen. Auch Gaming-Grafikkarten könnten von den verkürzten Zyklen profitieren.
Seit der Volta-Generation hat Nvidia die Entwicklung zwischen Gaming-Grafikkarten und GPU-Beschleunigern für Server aufgeteilt: 2018 erschien die serverexklusive V100, 2020 folgte die A100 und 2022 die H100.
Im Rahmen einer Investorenpräsentation hat Nvidia kürzlich eine GPU-Roadmap veröffentlicht, die den neuen Jahresrhythmus zeigt. Nächstes Jahr erscheint demnach die Blackwell-Generation, angeführt von der B100. Ab 2025 beginnt dann die Umstellung mit zusätzlichen GPU-Architekturen. Nvidia nennt das Topmodell "X100", vermutlich ein Platzhalter-Präfix.
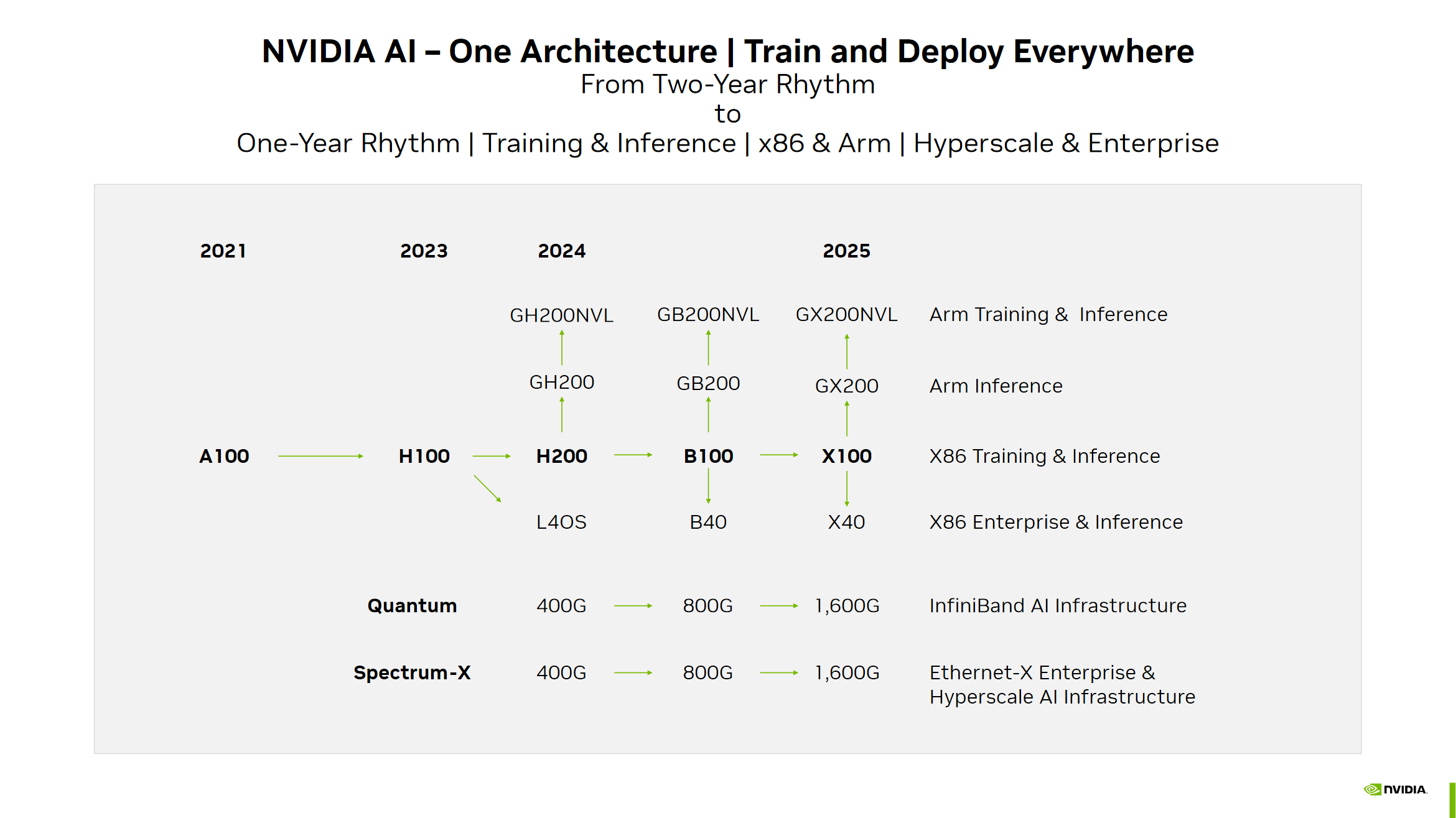
(Bild: Nvidia)
Mehr GeForce-Topmodelle möglich
Zusätzlich will Nvidia mit der B40 und "X40" neue Grafikkarten für Enterprise-Kunden und das Ausführen fertig trainiert KI-Algorithmen (Inferencing) bringen. Bisherige Ableger dieser Klasse verwenden GPUs, die Nvidia auch bei seinen GeForce-Topmodellen einsetzt. So teilen sich etwa die neue L40S und die GeForce RTX 4090 die AD102-GPU und die A40 sowie GeForce RTX 3090 (Ti) die GA102-GPU.
Diese Varianten verwenden bisher GDDR- statt HBM-RAM, zudem sind sie noch auf 3D-Bildberechnungen ausgelegt. Sollte Nvidia die Aufteilung beibehalten, könnten künftig auch häufiger neue GeForce-Topmodelle erscheinen.
Videos by heise
Viele weitere Modelle
Zusätzlich zu B100 und "X100" gibt es die üblichen Ableger wie GB200 und "GX200", die einen Rechenbeschleuniger mit einem selbst entwickelten ARM-Prozessor kombinieren. Die NVL-Versionen mit besonders viel Speicherkapazität bewirbt Nvidia als Flaggschiffe fürs Training von neuronalen Netzen.
Eine H100-Neuauflage, H200 genannt, überbrückt die Wartezeit bis Blackwell. Sie verwendet wahrscheinlich wie das angekündigte GH200-Board HBM3e- statt HBM3-RAM, mit höherer Übertragungsrate und größerer Kapazität.
Parallel beschleunigt die Firma seine Interconnects und Switches, die mehrere Server-Blades miteinander verbinden: 2024 verdoppelt sich die Übertragungsrate auf 800 Gbit/s, 2025 sollen sie 1,6 Tbit/s schaffen.

Das Geld für die gestrafften Zyklen kommt primär von den A100- und H100-Verkäufen. Firmen reißen Nvidia die GPU-Beschleuniger fürs KI-Training förmlich aus der Hand. Nvidias Quartalsumsatz mit diesen GPUs ist zuletzt auf mehr als 10 Milliarden US-Dollar geschossen und soll noch weiter steigen – einzig limitiert durch die Fertigungs- und Packaging-Kapazitäten des Chipauftragsfertigers TSMC.


(mma)