

Details zu Intels neuen Instruktionssätzen AVX512, MPX, SMAP
Die Ende Juli von Intel ohne großen Aufhebens veröffentlichte "Future Intel Architecture Instruction Extensions" umfasst nicht nur die Erweiterung von AVX auf 512 Bit, sondern bietet auch zahlreiche weitere Neuerungen.
(Bild: Intel)
Die Ende Juli von Intel ohne großen Aufhebens veröffentlichte "Future Intel Architecture Instruction Extensions" (PDF-Datei) umfasst nicht nur die Erweiterung von AVX auf 512 Bit, sondern bietet auch Maskierungsmöglichkeiten aller Befehle auf Teilregister, bringt Prefetch-Befehle für Scatter/Gather sowie Kryptobefehle für SHA, besseren Zufallsgenerator und neue Sicherheitsfeatures wie SMAP (Supervisor Mode Access Prevention) und die Speicherschutzerweiterung MPX.
Ursprünglich war der Einbau von 512 Bit mit dem Larrabee New Instruction Set (LNI) schon für den Haswell-Prozessor vorgesehen. Zwischenzeitlich gab es aber diverse Kurskorrekturen bei Intel. Der Grafikchip Larrabee wurde wieder verworfen, seine Technik floss dann in die Xeon-Phi-Coprozessor-Linie ein. AVX512 wurde verschoben und ist nun eine Übermenge von AVX2 und LNI, die offenbar in beide Prozessorlinien eingeführt werden soll, zunächst 2015 in die Xeon-Phi-Linie Nights Landing. Später dürfte dann der 14-nm-Nachfolger von Broadwell namens Skylake damit arbeiten, bei dem Intel in bisher veröffenlichten Roadmaps noch nebulös von AVX3.2 sprach.
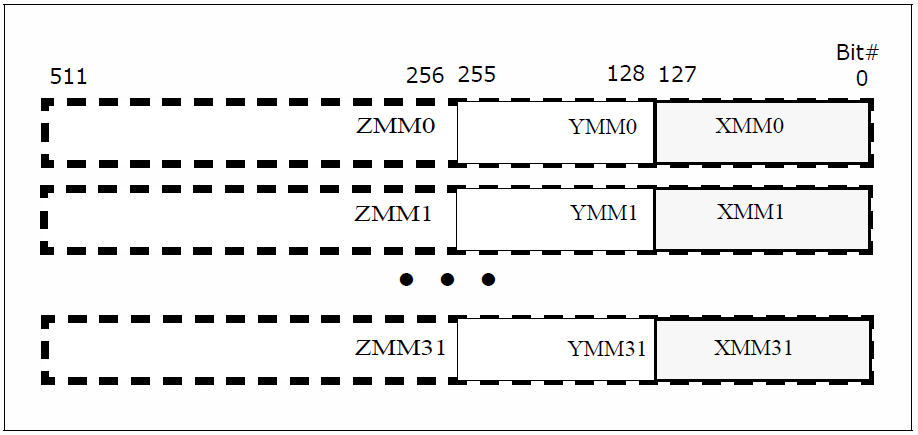
Bei der Registernotation ist man bei AVX512 mit dem Alphabet am Ende, nach XMM (128-bittig) und YMM (256-bittig) folgt nun ZMM (512-bittig). Ansonsten lauten die Befehle wie zuvor bei AVX/AVX2. Ein neues Prefix EVEX sorgt für die Umschaltung auf 512 Bit. Damit man bequemer mit einzelnen Teilen, etwa Words oder Dwords arbeiten kann, lassen sich alle AVX512-Befehle maskieren (Predication). Hierfür stehen sieben Maskenregister (k1-k7) zur Verfügung. Üblicherweise bleiben im Zielregister die Teile, die zu nicht gesetzten Maskenbits gehören, unverändert (merge mode), alternativ kann man sie auch löschen (zero mode). Für die Maskenregister selbst gibt es auch eine Fülle von neuen Befehlen sowie ein weiteres Register k0 für Zwischenwerte. Die alten Operationen (Skalar, SSE, AVX ...) wären damit im Prinzip überflüssig und könnten durch entsprechend maskierte AVX512-Befehle ersetzt werden – das sähe aber umständlicher aus.
Es gibt auch einen Satz neuer AVX-Befehle, etwa weitaus genauere Start-Approximationen für Exponentiation, Kehrwert, Wurzelziehen, die aus internen Tabellen gespeist werden. Und zu Scatter/Gather kommen jetzt auch Prefetch-Befehle hinzu, die die Ziele von bis zu 16 Adressen in die Caches laden.
Für den Krypto-Bereich gab es bislang die AES-Befehle, AVX512 bietet im Beiprogramm Ähnliches auch für SHA. Der Zufallsgenerator, der mit Ivy Bridge eingeführt wurde, war bislang offenbar nicht "NIST SP800-90B&C compliant). In der nächsten Generation soll das der Befehl RDSEED nachholen.
Weiterhin kann man mit dem unabhängig von AVX512 spezifizierten SMAP für einzelne Speicherseiten festlegen, dass nicht nur wie bisher mit SMEP die Ausführung von Befehlen im Userland aus dem Supervisor-Modus heraus verboten sind, sondern jeglicher Zugriff vom Supervisor-Modus auf die Seite: SMAP (Supervisor Mode Access Prevention).
Intels Memory Protection Extension MPX geht solche Sicherheitsklassiker wie Buffer-Over- oder Underflow nun mit Hardwarehilfe an. Seit jeher gibt es den Bound-Befehl, der einen Interrupt 5 auslöst, falls ein Feldindex außerhalb eines vorgegebenen Bereiches liegt. Diesen Befehl hatte man aber kaum benutzt und bei der Spezifikation von 64 Bit ganz unter den Tisch fallen lassen.
Mit MPX erweitert Intel dieses Konzept jetzt nicht nur auf 64 Bit, sondern führt auch vier spezielle 128-bittige BOUND-Register (BND0 .. BND3) ein, die jeweils die Ober und Untergrenze eines überwachten Bereiches abspeichern. Zugriffe außerhalb dieses Bereiches führen zu einer Bound Exception. Die MPX-Befehle sind dabei so geschickt in den Opcode-Raum eingebunden, dass herkömmliche Prozessoren sie als NOP betrachten und sie ignorieren, statt mit einer Fehlermeldung "Unbekannter Opcode" abzubrechen.
Auch für die ganz normale Integer-Unit fallen noch ein paar sanfte Erweiterungen ab, etwa solche Kleinigkeiten, die Pat Gelsinger damals beim 386 vergessen hatte, wie eine vorzeichenlose Integer-Addition mit Carry- oder Overflow-Flag. Und irgendwas oder irgendwer muss Intel auch bewogen haben, eine schnellere Setz und Löschmöglichkeit für das Alignment-Flag im EFLAGS-Register zu schaffen (via CLAC und STAC), als es mit PUSHFQ-, Maskier- und POPFQ-Operationen über den Stack derzeit möglich ist. Bei gesetztem AC-Flag gibt es bei unalignten Zugriffen eine AC-Exception.
Und schließlich baut Intel die Möglichkeiten für Processor Trace (PT) für Debugging und Profiling weiter aus. Auf Wunsch sammeln zukünftige Prozessoren bei Programmverzweigungen, Interrupts, Exceptions, Seitenwechseln, Taktänderungen und so weiter entsprechende Informationen in kleinen Paketen und speichern diese, gegebenenfalls gefiltert über einen vorgegebenen virtuellen Adressraum (CR3-Register) ab. Das Ganze soll ohne allzu großen Overhead klappen und ohne, dass man vorher die Software fürs Profilieren orchestrieren muss. (as)
