Herausforderungen und Fallstricke bei der Entwicklung für Multi-Core-Systeme

Parallelisierung von Anwendungen verspricht bessere Performance und kürzere Laufzeiten. Bei der Programmierung gilt es aber, einige Hürden zu überwinden.
Parallelrechner finden sich heutzutage in zahlreichen Mehrkernprozessorsystemen vom Smartphone über Tablets und PCs bis hin zu Industriesteuerungsanlagen und Computerclustern im Rechenzentrum. Die Nutzung dieser Rechenleistung stellt große Herausforderungen an die Softwareentwicklung – zudem sind parallele Programmierparadigmen zu berücksichtigen.
Anders als bei klassischen Anwendungen mit sequenziellem Programmfluss werden beim Parallel Computing mehrere Teilaufgaben gleichzeitig ausgeführt. Dies wird auch als Nebenläufigkeit (concurrency) oder Parallelität (parallelism) bezeichnet. Die Vorteile liegen auf der Hand: Durch eine parallele Bearbeitung lassen sich Mehrkernsysteme effizient auslasten und komplexe Problemstellungen in angemessener Zeit lösen. Allerdings gehen damit auch eine deutlich höhere Komplexität und eine schlechtere Nachvollziehbarkeit des Programmcodes sowie eine höhere Fehleranfälligkeit einher.
Dieser Artikel geht auf Konzepte, Techniken und Herausforderungen paralleler Programmierung mit Java-Threads ein und will Antworten auf die folgenden Fragen geben:
- Wie lässt sich eine hohe Auslastung über viele CPU-Kerne erreichen?
- Wie ist mit Race Conditions und Data Races umzugehen?
- Welche Fallstricke lauern beim Einsatz von Synchronisationstechniken?
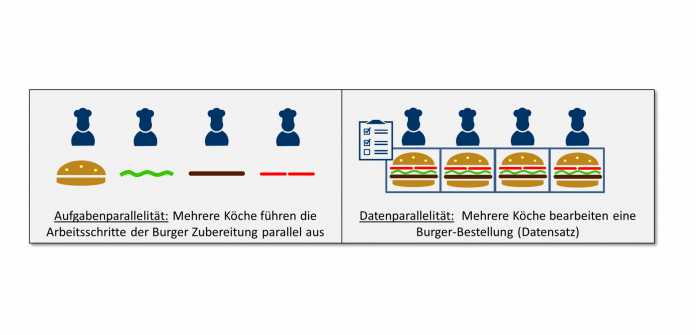
Bei der Parallelverarbeitung unterscheiden Entwickler häufig zwischen Aufgabenparallelität (task parallelism) und Datenparallelität (data parallelism) [1]. Bei der Task-Parallelität wird eine Reihe unterschiedlicher Aufgaben parallel und unabhängig voneinander auf den gleichen oder unterschiedlichen Daten bearbeitet. Im Prinzip ein ähnlicher Vorgang, wie wenn mehrere Köche einen Burger zubereiten und dabei die einzelnen Arbeitsschritte wie die Zubereitung von Salat, Tomaten, Brötchen und Bulette parallel ausführen (s. Abb. 1).

(Bild: Volkswagen AG)
Bei der Datenparallelität wird dieselbe Aufgabe auf unterschiedlichen Bereichen eines Datensatzes parallel ausgeführt. So, als würden mehrere Köche eine Burger-Bestellung (Datensatz) bearbeiten und gleichzeitig die Burger zubereiten.
Parallele Ausführung beschleunigt Anwendungen – aber in Grenzen
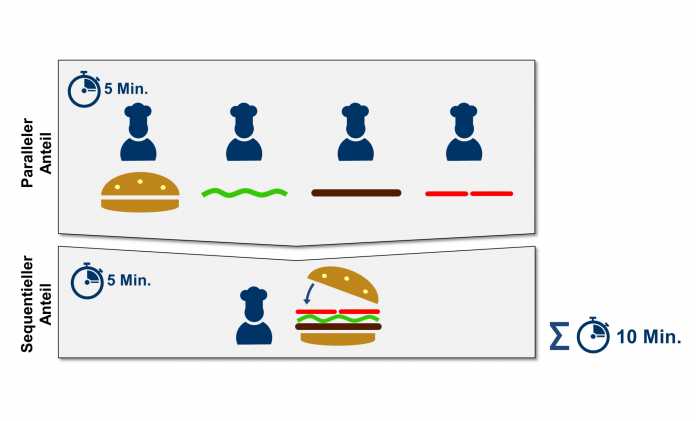
Wie sehr sich eine Anwendung durch parallele Ausführung beschleunigen lässt, ist nach dem Amdahlschen Gesetz [2] abhängig von dem sequenziellen (also dem nicht parallelisierbaren) Anteil einer Applikation. So bereiten mehrere Köche die einzelnen Zutaten des Burgers vor, aber nur ein Koch fügt sie sequenziell zusammen (s. Abb. 2).
(Bild: Volkswagen AG)
Die gesamte Zubereitungszeit hängt also von den fünf Minuten ab, die ein einzelner Koch benötigt, um die Zutaten zusammenzufügen. Auch wenn sehr viele Köche mitkochen und die Zubereitung der Zutaten (paralleler Anteil) beschleunigen, fällt die Gesamtzeit niemals unter fünf Minuten.
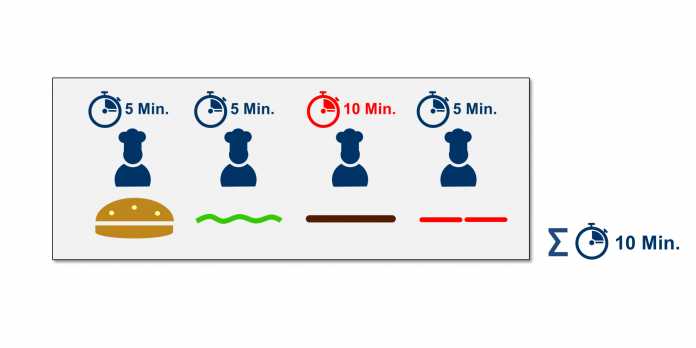
Eine hohe parallele Effizienz lässt sich erzielen, wenn die Problemstellung gut parallelisierbar ist und einen möglichst geringen sequenziellen Anteil besitzt. Gute Parallelisierbarkeit heißt auch, dass sich die einzelnen Teilaufgaben in der gleichen Ausführungszeit erledigen lassen. Andernfalls kommt es zu dem in Abbildung 3 dargestellten Problem.
(Bild: Volkswagen AG)
Der Koch, der die Bulette zubereitet, benötigt deutlich mehr Zeit als die anderen drei Köche. Dies erhöht nicht nur die Bearbeitungszeit des parallelen Anteils, sondern führt auch dazu, dass die anderen drei Köche fünf Minuten warten müssen und nichts zu tun haben, bis der letzte Koch fertig ist.
Um ein Multi-Core-System effizient auszulasten, ist somit eine Problemstellung mit einer hohen Parallelisierung notwendig. Insbesondere Problemstellungen, die denselben Algorithmus auf unterschiedliche Bereiche eines Datensatzes anwenden (Datenparallelität), eignen sich hierfür gut. Anwendungsgebiete wie die Simulation physikalischer Prozesse oder das Training neuronaler Netze sind besonders prädestiniert. Hingegen lassen sich Anwendungen wie Office-Applikationen oder Webserver oftmals kaum parallelisieren.
Parallelverarbeitung mit Java-Threads
Im Folgenden wird die Parallelverarbeitung am Beispiel von Java-Threads vorgestellt. Viele der diskutierten Herausforderungen gelten aber auch in anderen Programmiersprachen wie C++ oder C#. Ein Thread (oder auf das vorhergehende Beispiel bezogen: ein Koch) ist ein sequenzieller Ausführungsstrang innerhalb eines Anwendungsprogramms (Prozess). Dabei kann eine Anwendung aus mehreren Threads bestehen, die parallel ausgeführt werden. Die Threads innerhalb einer Anwendung teilen sich den Speicher des Prozesses, in dem sie gestartet wurden (Shared Memory).
Um einen Thread anzulegen, stellt Java, wie viele andere Sprachen auch, die Klasse Thread zur Verfügung. Wollen Entwickler eigene Threads erstellen, erzeugen sie eine vom Thread abgeleitete Klasse, die die Run-Methode überschreibt. Diese enthält den Programmcode, der durch den Thread zur Laufzeit ausgeführt werden soll. Wird ein Thread gestartet, ist zunächst eine Instanz der Klasse zu erstellen und dann die Start-Methode aufzurufen.
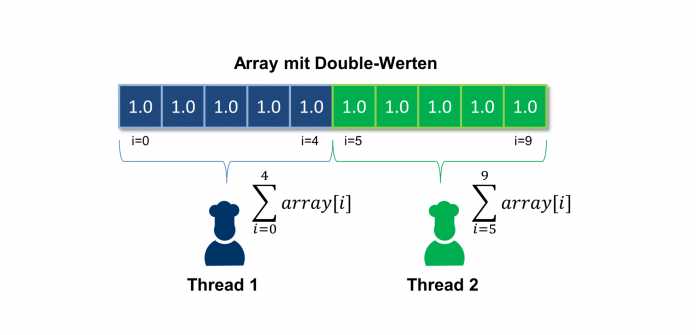
Alternativ lassen sich Threads auch durch Implementieren der Schnittstelle Runnable erstellen. So muss die Klasse nicht vom Thread abgeleitet sein, was Vorteile bei komplexeren Programmstrukturen bietet, da Java keine Mehrfachvererbung unterstützt. Um diese Vorgehensweise in Java zu veranschaulichen, dient als Beispiel die Summenberechnung über die Werte innerhalb eines Arrays (s. Abb. 4).
(Bild: Volkswagen AG)
Dieses Beispiel lässt sich aufgrund der Datenparallelität effizient über mehrere Threads ausführen. Zwei Threads teilen sich die Berechnung der Summe auf. Während Thread 1 die erste Hälfte des Arrays berechnet, übernimmt Thread 2 dies für die zweite Hälfte. Anschließend werden Teilergebnisse addiert.
Das folgende Listing stellt die Klasse Summation (abgeleitet von Thread) dar. Die Run-Methode implementiert die Logik zur Berechnung der Summe. Hierbei wird eine Schleife über dem Array verwendet, die variabel von einem Start-Index bis zu einem End-Index läuft. So lässt sich der gleiche Programmcode für jeden Thread verwenden. Die Klasse Summation erhält über ihren Konstruktor Start und End sowie die in der Klasse Data gekapselten Berechnungsdaten. Data besteht aus einem eindimensionalen Array von Double-Werten und einer Variablen sum zum Speichern der berechneten Summe.
class Data {
double[] array;
double sum;
Data(double[] array) { this.array = array; }
}
class Summation extends Thread {
Data data;
int start, end;
Summation (Data data, int start, int end) {
this.data = data;
this.start = start;
this.end = end;
}
@Override
public void run() {
for (int i = start; i < end; i++) {
data.sum = data.sum + data.array[i];
}
}
}
Das nächste Listing zeigt die Main-Methode des Programms, in der das Array initialisiert und die Threads zur Summenberechnung gestartet werden. Kommt das Programm für ein Array mit 100 Millionen Einträgen auf einem aktuellen Mehrkernrechner zur Ausführung, ergibt sich für einen Thread eine Laufzeit von circa 400 Millisekunden, bei zwei Threads halbiert sich die Laufzeit auf circa 200 Millisekunden. Die Anwendung skaliert also optimal über zwei Threads.
public static void main(String[] args)
// Initialisieren und Füllen des Arrays
double[] array = new double[n];
Arrays.fill(array, 1);
Data data = new Data(array);
// Initialisieren und Starten der Threads 1 und 2
Thread thread1 = new Summation(data, 0, n/2);
thread1.start();
Thread thread2 = new Summation(data, n/2, n);
thread2.start();
// Warten bis Thread 1 und 2 fertig sind
thread1.join();
thread2.join();
// Ergebnisausgabe
System.out.println("sum: " + data.sum);
}
Vermeidung eines Data Race
Führen Entwickler das Programm wiederholt aus, treten gelegentlich Programmabbrüche auf. Auslöser ist ein sogenannter Data Race, das heißt eine Konstellation, bei der mehrere Threads auf dieselben Daten (in diesem Fall die Variable sum) zugreifen und versuchen, diese zu verändern. Die Variable sum ist als 64-Bit-Datentyp (double) implementiert.
Das Speichermodell von Java realisiert 64-Bit-Datentypen als nichtatomar, das heißt, nicht Thread-sicher, da eine Schreiboperation des Werts in zwei Schritten erfolgt, eine für jede 32-Bit-Hälfte. Hierdurch kann ein Zustand entstehen, bei dem ein Thread einen 64-Bit-Wert liest, bei dem die erste 32-Bit-Hälfte durch einen anderen Thread bereits verändert wurde, die zweite Hälfte jedoch noch nicht (siehe hierzu Java Language Specification [3]).
Abhilfe kann hier unter anderem die Kennzeichnung der Variable als volatile schaffen. Für die mit volatile gekennzeichneten 64-Bit-Variablen (wie double und long) stellt die Java-Laufzeitumgebung sicher, dass Schreibvorgänge stets Thread-sicher sind und andere Threads immer nur vollständig (über beide 32-Bit-Hälften) geschriebene Werte sehen. Wird volatile bei folgendem Beispiel eingeführt, läuft die Anwendung stabil ohne Programmabbrüche durch, was jedoch mit einer deutlich längeren Laufzeit einhergeht.
class Data {
...
volatile double sum;
}
Die Ergebnisausgabe des Programms zeigt allerdings nach jeder Programmausführung unterschiedliche Ergebnisse an. Das korrekte Ergebnis von 100 Millionen fehlt. Grund ist die Berechnung der Summe: Dabei kommt es zu einer sogenannten Race Condition. Das heißt, das Ergebnis ist abhängig von der zeitlichen Reihenfolge, in der die Threads die Einzeloperationen ausführen.
Die Summenberechnung besteht aus drei Einzeloperationen: Einlesen der alten Summe, Addieren der Summe mit dem jeweiligen Wert aus dem Array und schließlich dem Speichern der neuen Summe. Die zeitliche Abfolge, um diese Operationen über mehrere Threads abzuarbeiten, ist zufällig und nicht deterministisch. Entsprechend kann es zu Fehlern bei der Berechnung kommen, wie Abbildung 5 zeigt.

(Bild: Volkswagen AG)
Synchronisation des kritischen Abschnitts
Um das Race-Condition-Problem bei der Summenberechnung zu lösen, gibt es in Java die Möglichkeit, Methoden als synchronized zu kennzeichnen. Dabei ist sichergestellt, dass sie immer nur ein Thread zur Zeit ausführt. Alle anderen Threads müssen warten, bis ein ausführender Thread die Methode wieder verlassen hat. Für die Umsetzung wird die Summenberechnung in die synchronisierte Methode increaseSum der Klasse Data verschoben (nächstes Codebeispiel). So lässt sich das Data-Race-Problem aus dem vorhergehenden Abschnitt gleich mit lösen. Auf das Schlüsselwort volatile kann in diesem Fall verzichtet werden.
class Data {
double[] array;
double sum;
Data(double[] array) { this.array = array; }
public synchronized void increaseSum(double i) {
sum += i;
}
}
class Summation extends Thread {
Data data;
int start, end;
Summation (Data data, int start, int end) {
this.data = data;
this.start = start;
this.end = end;
}
@Override
public void run() {
for (int i = start; i < end; i++) {
data.increaseSum(data.array[i]);
}
}
}
Bei erneutem Ausführen des Programms wird das korrekte Ergebnis reproduzierbar ausgegeben. Allerdings liegt die Laufzeit für zwei Threads bei circa 5000 Millisekunden und damit um mehr als eine Größenordnung höher als bei der nicht synchronisierten Variante im ersten Codebeispiel. Die letzte Codeversion verdeutlicht, dass die Synchronisation große Einbußen bei der Performance nach sich zieht, weil die benötigte Logik zur Summenberechnung um ein Vielfaches komplexer ist.
Beim Aufruf einer synchronisierten Methode wird eine Sperre auf dem Objekt gesetzt beziehungsweise beim Verlassen der Methode zurückgesetzt. Ist die Methode bereits gesperrt, wird der aufrufende Thread blockiert. Neben der eigentlichen Berechnung der Summe erfolgt im Beispiel somit auch der Aufruf dieses Synchronisationsmechanismus 100 Millionen Mal.
Zugriff auf gemeinsam genutzte Daten reduzieren
Der zweite Lösungsansatz vereint die Vorteile des ersten (hohe parallele Effizienz) und vierten Codebeispiels (Vermeidung von Race Conditions). Dazu ist der Zugriff auf gemeinsam durch beide Threads genutzte Daten deutlich zu reduzieren. Das folgende Listing führt innerhalb der Summenberechnung eine lokale Variable sum ein, die nur vom jeweiligen Thread verwendet wird. Das heißt, die Threads arbeiten zur Berechnung auf eigenen Daten und erst nach Abschluss der Iteration erfolgt die Addition der beiden Teilsummen. Nur dieser letzte Schritt erfordert eine Synchronisation. Bei einer erneuten Ausführung des Programmcodes für ein Array mit 100 Millionen Einträgen und zwei Threads, ist das korrekte Ergebnis reproduzierbar bei einer Laufzeit von circa 200 Millisekunden erreicht.
class Summation extends Thread {
Data data;
int start, end;
Summation (Data data, int start, int end) {
this.data = data;
this.start = start;
this.end = end;
}
@Override
public void run() {
double sum = 0.0;
for (int i = start; i < end; i++) {
sum += data.array[i];
}
data.increaseSum(sum);
}
}
Fazit
Um moderne Mehrkernsysteme (Multi-Core-Prozessoren, Grafikkarten oder HPC-Cluster) effizient auszulasten, sind Techniken der parallelen Programmierung notwendig. Dadurch lassen sich erhebliche Performanceverbesserungen hinsichtlich der Laufzeit komplexer Anwendungen erzielen. Das Beispiel auf Basis von Java-Threads zeigt die grundlegenden Herausforderungen paralleler Applikationsentwicklung und lässt sich auf andere Sprachen wie C++ und C# sowie Techniken der Parallelverarbeitung auf Grafikkarten übertragen. Die Grundfragestellungen bleiben immer dieselben:
- Die Problemstellung muss gut parallelisierbar sein und einen möglichst geringen sequenziellen (nichtparallelisierbaren) Anteil aufweisen. Gut geeignet sind numerische Simulationsverfahren, das Training neuronaler Netze sowie mathematische Verfahren wie Matrizen-, Tensor- und Vektorberechnungen.
- Um parallele Anwendungen zu entwickeln, sind Kenntnisse über das Speichermodell entscheidend, wie beispielsweise bezüglich der Atomarität von Datentypen oder Sichtbarkeit (sind Änderungen von Variablen über mehrere Threads hinweg sichtbar).
- Nichtsynchronisierte parallele Speicherzugriffe können zu fehlerhaften Ergebnissen und Programmabbrüchen führen. Aber jede Form der Synchronisation (atomare Variablen, synchronized etc.) ist teuer und reduziert die parallele Effizienz. Außerdem verschlechtert sich die Nachvollziehbarkeit des Programmcodes deutlich.
- Gemeinsam genutzte, veränderliche Daten sind auf ein Minimum zu reduzieren. Optimal sind separate Speicherzugriffe pro Thread oder ein Read-only-Zugriff auf Daten von mehreren Threads.
Dr. Sebastian Bindick
ist IT-Architekt bei der Volkswagen Group IT. Seine Schwerpunkte liegen in den Bereichen moderne Architekturen, Web-Technologien, Testautomatisierung und Computational Engineering. Er ist Autor von Fachartikeln, hält Vorträge auf IT-Konferenzen und ist Gastdozent an verschiedenen Universitäten.
(map [4])
URL dieses Artikels:
https://www.heise.de/-4364313
Links in diesem Artikel:
[1] https://en.wikipedia.org/wiki/Data_parallelism#Data_parallelism_vs._task_parallelism
[2] https://de.wikipedia.org/wiki/Amdahlsches_Gesetz
[3] https://docs.oracle.com/javase/specs/jls/se9/html/jls-17.html#jls-17.7
[4] mailto:map@ix.de
Copyright © 2019 Heise Medien