Test: Googles Skipfish
Googles neuer, kostenloser Scanner Skipfish soll nach Einschätzung des Autors Michal Zalewski bei der automatischen Suche nach Schwachstellen in Webanwendungen gleich in der Oberliga mitspielen. Wir haben uns angeschaut, ob der Scanner diese selbstbewussten Versprechen halten kann.
Bei Sicherheitsuntersuchungen von Web-Applikationen nutzt man automatische Scanner, um eine Grundlage zu schaffen und die dann durch manuelle Tests auszubauen. Je nach Anforderung und Kenntnis des Anwenders kommen dabei minimalistische Basiswerkzeuge wie Nikto oder umfangreiche kommerzielle Tools wie Rational AppScan zum Einsatz. Ziel dieser Scans ist es vor allem, Konfigurations- und Implementierungsfehler im Zusammenspiel von Webserver, Applikationsserver, Applikationslogik und anderen Komponenten aufzudecken, die eine moderne Web-Applikation ausmachen. Zu den typischerweise gefundenen Schwachstellen gehören unter anderem SQL-Injection, Cross Site Scripting, Cross Site Request Forgery und Code Injection.
Vorhang auf
Skipfish [1] unterstützt alle Funktionen, die man sich für eine generische Untersuchung einer Web-Seite wünscht: Er kann mit Cookies umgehen, Authentifizierungsinformationen und Werte für HTML-Formular-Variablen verarbeiten, oder sogar nur ein Sitzungs-Token verwenden, um sich als authentifizierter Nutzer auf der Zielseite zu bewegen. Eine der Spezialitäten von Skipfish ist das brutale Ausprobieren von möglichen Datei- und Verzeichnisnamen, um beispielsweise vom Admin vergessene Backupversionen von Scripten, gepackte Archive ganzer Web-Applikationen oder versehentlich hinterlassene Konfigurationsdateien von SSH oder Subversion ausfindig zu machen. Da sich solche Fundstücke nur durch Ausprobieren aufspüren lassen, verknüpft der Scanner verschiedene bekannte Endungen mit allen möglichen Dateinamen, welche er über die normalen Links auf der Web Seite findet.
Darüber hinaus probiert er einige handverlesene Schlüsselwörter als Verzeichnis- und Dateinamen durch, die er vermutlich aus dem Google Suchindex extrahiert. Zu beachten ist hierbei, dass Skipfish tatsächlich alles mit allem kombiniert und ausprobiert. Das heißt in der Praxis wird jedes Schlüsselwort mit jeder Endung und jeder tatsächlich auf dem Webserver gefundenen Datei kombiniert und das Ergebnis sowohl als Datei- und Verzeichnisname als auch als Argument einer HTTP-POST-Anfrage verwendet. Dieses Vorgehen hat eine kombinatorische Explosion zur Folge, welche sich schnell bemerkbar macht. Zum Glück bringt Skipfish vordefinierte Wörterbücher unterschiedlichen Umfangs mit, so dass man das Ausmaß der Anfrageflut selbst bestimmen kann. Doch auch das von Zalewski als Einstieg empfohlene minimale Wörterbuch hat 2007 Einträge verursacht noch rund 42000 Anfragen pro getestetem Verzeichnis.
Um einen Eindruck von Skipfish zu erhalten, haben wir ein paar typische Szenarien kurz untersucht: ein Microsoft Internet Information Server 7.5 auf Windows 7 mit einem Screwturn Wiki 3.0.2 für ASP.NET stellte die typische interaktive Web-Applikation dar. Ein Linux basierter Apache-2.2.3-Server mit klassischen, in Perl geschriebenen CGI-Scripten repräsentierte den eher altbackenen Ansatz. Als typischer Produzent für Fehlalarme und Probleme beim Scannen kam ein alter HP-LaserJet-Drucker mit ChaiServer 3.0 zum Einsatz.
Einsatz
Skipfish liegt nur im Quellcode vor und muss zunächst für die Zielplattform übersetzt werden. Das setzt die Installation von libidn voraus, einer freien Bibliothek zum Codieren und Decodieren von Internationalized Domain Names (IDN) – unter Ubuntu 9.10 ist dies beispielsweise mit sudo apt-get install libidn11-dev schnell erledigt. Nach dem erfolgreichen Übersetzen gilt es, im Unterverzeichnis Dictionary eine Wörterbuchdatei auszuwählen und unter dem Namen skipfish.wl in das Verzeichnis zu kopieren, in dem das Skipfish-Binary liegt. Alternativ kann man den Pfad auch als Option angeben. Beachten sollte man, dass Skipfish die angegebene Datei automatisch erweitert, man sollte also immer mit einer Kopie arbeiten.
Mit ./skipfish -o example-log http://www.example.com/ startet man den Scan des Servers, nach dessen Ende der Report im Verzeichnis example-log liegt. Um nur das Unterverzeichnis blog auf dem Server zu untersuchen, gibt man "-I /blog -o blog-report http://www.example.com/blog" an.

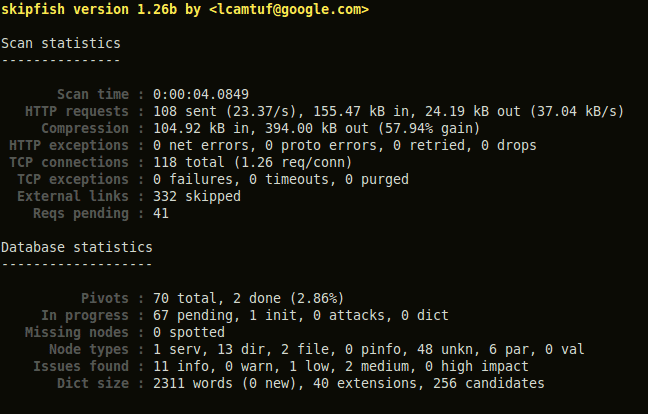
Skipfish produziert eine enorme Menge von Anfragen, die er gleichzeitig und in beeindruckender Geschwindigkeit absetzt. Beim ersten Lauf in einem lokalen Gigabit-Ethernet-Segment gegen ein ausreichend skaliertes System erreichte er 2796 HTTP-Anfragen pro Sekunde. Dies trieb die Last eines CPU-Kerns des scannenden Systems sofort auf 100 Prozent. Der TCP/IP-Stack von Linux kann zwar mit der Last umgehen, muss allerdings sämtliche dafür vorgesehenen Mittel nutzen, wie ein Blick auf die netstat-Ausgaben schnell zeigt.
Nach dem Start bekommt man Zweifel, ob Skipfish tatsächlich in absehbarer Zeit mit der Untersuchung fertig wird. Eine Abschätzung, wie lange der Test wohl noch dauert, ist unmöglich. Es dauerte dann auch tatsächlich über vier Stunden bis der Scanner den benachbarten IIS 7.5 mit dem Screwturn-Wiki untersucht hatte. Hierfür hat er 68 GB Daten transferiert um 40 Millionen HTTP-Anfragen abzusetzen. Auf dem Scanner-System wurde nahezu den gesamten Zeitraum ein CPU-Kern komplett ausgelastet und für die Kombinationen der übersichtlichen Anzahl von 1195 Dateien in 43 Verzeichnissen des Wiki wurden seitens Skipfish 140 MB Arbeitsspeicher benötigt. Der IIS lastete in der Zeit zwei Intel XEON 2.5 GHz Kerne vollständig aus, verbrauchte zwischen 100 MB bis 500 MB zusätzlichen Arbeitsspeicher und produzierte in seiner Standardeinstellung 1,5 GB in der Log-Datei.
[pagebreak Interpretionsarbeit]
Interpretationsarbeit
Für die Untersuchung des Apache-Webservers wurde versuchsweise die Wörterbuchfunktion ausgeschaltet. Es war Skipfish aber weiterhin gestattet, neue Wörter während des Scan-Vorgangs zu lernen, was 304 neue Einträge zur Folge hatte. Dies reduzierte die Laufzeit dann auf 20 Minuten, in denen knapp 300.000 HTTP-Anfragen gestellt wurden, welche mit 232 MB Netzwerkverkehr zu Buche schlugen.
Generell liefert Skipfish vergleichsweise viele Ergebnisse und legt diese im angegebenen Verzeichnis als HTML, JavaScript mit JSON und rohen Datendateien ab. Den Report kann man dann in einem Browser mit JavaScript betrachten oder die Rohdaten selbst auswerten. Der Anteil der Fehlalarme ist leider deutlich höher als bei zum Vergleich eingesetzten Tools wie Nikto oder der Burp Suite. So werden gerne mal reguläre ASCII-Textdateien als JSON-Antwort ohne XSSI-Schutz (Cross Site Script Inclusion) interpretiert. Besonders großen Wert legt Skipfish auf korrekte MIME-Type und Zeichensatz Antworten vom Server. Jede Abweichung wird mit einem Ergebnis der Klasse "erhöhtes Risiko" quittiert, wobei wiederum nur ein Teil tatsächlich zutreffen.
Die Möglichkeit Verzeichnisinhalte aufzulisten, würdigt Skipfish bei keinem der getesteten Ziele mit einem Ergebniseintrag. Auch dem Inhalt der robots.txt-Datei, welcher gerade für die Identifikation interessanter Bereiche des Server wichtig sein kann, wird keine weitere Beachtung geschenkt und dem Anwender als "Interesting File"-Ergebnis zur eigenen Interpretation überlassen.
Der Vorhang fällt
Die Ausbeute der vier Stunden andauernden Untersuchung des IIS 7.5 mit dem Screwturn-Wiki sind 8 Ergebnisse mit hohem Risiko, 264 mit erhöhtem Risiko, 55 mit geringem Risiko, 123 Warnungen und 254 Anmerkungen. Die Gesamtmenge an Daten auf der Festplatte beläuft sich auf 851 MB und der Webbrowser sollte ein Gigabyte freien Arbeitsspeicher zur Verfügung haben, damit man die Ergebnisseite auch betrachten kann.

Leider stellen sich die 8 wichtigsten Ergebnisse – alles angebliche Integer-Überläufe in HTTP-GET-Parametern, als Falschmeldungen heraus. Bei der nächsten Klasse von Ergebnissen, "Interessante Server Meldungen", werden HTTP 404 Fehler (Ressource nicht gefunden) und HTTP 500 Fehler (interner Serverfehler) vermischt, so dass man alle 130 angezeigten Ergebnisse einzeln durchgehen müsste. Da der IIS bei "HTTP 500" eine generische Fehlermeldung zeigt, um dem Angreifer keine zusätzlichen Informationen zu geben, müsste man die verbliebenen Anfragen einzeln in Korrelation mit den Webserver-Log-Daten setzen oder erneut manuell testen. Ein Blick in die Server-Logs zeigt allerdings, dass sich dieser Aufwand nicht lohnen würde, da es sich immer um den selben Fehler handelt und dieser keine Relevanz für die Sicherheit hat. Dass Falschmeldungen keine Ausnahmen sind, zeigte sich auch bei einer späteren Analyse eines Typo3-Systems, bei dem Skipfish vor kritischen SQL-Injection-Lücken warnte.
Als Besonderheit ist anzumerken, dass Skipfish das Vorhandensein eines IPS erkennt und unter "Warnungen" aufführt. Im Test bemerkte es die HttpRequestValidationException, welche von ASP.NET bei allzu offensichtlichen SQL-Injection- oder Cross-Site-Scripting-Angriffen erzeugt wird, und zu einem HTTP 500 Fehler führt.
[pagebreak Auswertung]
Auswertung
Unterm Strich kann Skipfish bei der Konstellation IIS 7.5 und Screwturn nicht glänzen. Hervorzuheben ist allerdings, dass der brutale Wörterbucheinsatz selbstständig die URI /wiki/ gefunden hat und dadurch ohne manuelle Hilfe dieses untersuchen konnte.
Bei der Untersuchung des Apache Servers mit CGI-Scripten, für die die Wörterbuchfunktion auf pures Lernen begrenzt wurde, schneidet Skipfish etwas besser ab. Es werden nur 47 Ergebnisse mit erhöhtem Risiko, 6 mit geringem Risiko, eine Warnung und 65 Bemerkungen angezeigt, was auch nur 83 MB beansprucht. Mit den klassischen Perl-generierten HTML-Formularen weiß Skipfish interessanterweise nicht umzugehen. Daher werden auch die gelernten Schlüsselworte nicht als Eingabe für die Formularfelder probiert. Der Scanner erkennt allerdings richtig, dass die Formulare nicht gegen Cross Site Request Forgery (CSRF) geschützt sind.
Sowohl unter der Kategorie "Interesting File" als auch unter "Incorrect or missing MIME type" wird eine URL gelistet, bei der tatsächlich eine Fehlkonfiguration des Servers zur Anzeige eines CGI Scripts im Quellcode führt, anstatt seine Ausführung auszulösen. Dieses Ergebnis ist der Kombination aus Dateinamen und Endungen (in diesem Fall einer leeren Endung) zu verdanken.
Die Untersuchung des Druckers lieferte übrigens keine Ergebnisse, da wir den Scan nach 18 Stunden abbrechen mussten, weil immer noch kein Ende in Sicht war. In solchen Situationen stört, dass Skipfish seinen Report über die bisherigen Erkenntnisse erst nach dem regulären Ende des Durchlaufs oder beim vorherigen Beenden mit Control-C ins Verzeichnis schreibt. Während des Laufs hat man keine Möglichkeit herauszufinden, ob und was das Tool bereits gefunden hat.
Einschätzung
Die Stärke von Skipfish ist das Entdecken von vergessenen Daten sowie das Provozieren von unerwartetem Verhalten auf den Servern. Die Permutation der Schlüsselwörter und Datei-Erweiterungen sowie gelernter Elemente sind einem Fuzzer sehr ähnlich, was sich natürlich auf die resultierenden Datenmengen ähnlich auswirkt.
In großen Rechenzentren, wie denen von Google, die eine sehr heterogene Landschaft von Web Applikationen beherbergen, welche auf nahezu unbegrenzte Rechnerressourcen und Netzwerkbandbreite zurückgreifen können, kann der Einsatz sicherlich schon heute zur Entdeckung von unerwarteten Funktionen und Inhalten führen.
Hat man allerdings direkten Zugriff auf das Dateisystem der Web-Server, ergibt der Einsatz von Skipfish weniger Sinn – insbesondere wenn er über eine Internet-Verbindung erfolgt. Die übertragenen Datenmengen des Scanners entsprechen fast einem vollständigen Abbild des Dateisystems, sodass man die Skripte und Dateien einer Anwendung besser in aller Ruhe und mit bekannten Mitteln direkt vor Ort analysiert.
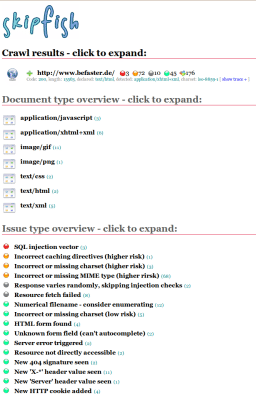
Für den professionellen Gebrauch ist Skipfish in seiner momentanen Form nur sehr bedingt geeignet. Die auf jeden Fall fällige Überprüfung der Testergebnisse artet wegen der Meldungsflut sehr schnell zur Sysiphus-Arbeit aus. Zudem sind gemeldete Probleme wie "Incorrect or missing charset", "Incorrect caching directives" oder "Incorrect or missing MIME type" sehr abstrakt und alles andere als eindeutig. Selbst erfahrene Pen-Tester müssen oft erstmal Recherchieren, worin das Problem nun eigentlich besteht. Mit diesem Hintergrund ist Skipfish für den weniger professionellen Anwender oder für den schnellen "Test für Zwischendurch" überhaupt nicht geeignet und führt vermutlich eher ungerechtfertigt zu Panik als zur Beruhigung.
Der Einsatz der Wörterbuchfunktion verbietet sich in vielen Einsatzszenarien schon allein wegen der anfallenden Datenmengen und der daraus resultierenden Last für die Zielsysteme. Eine ausgewachsene Java-basierte Business-Web-Anwendung würde einem Skipfish-Scan mit minimalem Wörterbuch wahrscheinlich nicht standhalten, da CPU- und Hauptspeicherbedarf das System vorher zum Stillstand bringt. Auch Firewalls mit komplexeren Inspektionsmodulen oder IDS/IPS Systeme würden die Empfänger ihrer Log-Meldungen in extremen Datenmengen ertränken oder schlicht den Dienst quittieren. (dab [2])
URL dieses Artikels:
https://www.heise.de/-975546
Links in diesem Artikel:
[1] http://code.google.com/p/skipfish/
[2] mailto:dab@ct.de
Copyright © 2010 Heise Medien