Vom schnellen Verschwinden der Forschungsdaten
Die meisten Datenbestände von veröffentlichten Studien sind nach einer Stichprobe von biologischen Artikeln nach 20 Jahren nicht mehr erreichbar
Nicht nur wegen der NSA sprechen alle von Big Data, also vom Sammeln, Speichern, Durchsuchen und Auswerten von großen Datenmengen aus vielen unterschiedlichen Quellen. Angesichts der Datensammelwut der Geheimdienste und der Internetkonzerne wird gerne vergessen, dass den immer größeren Datenmengen, die produziert und gespeichert werden, auch ein digitales Nirwana gegenübersteht, in das viele der Daten immer schneller verschwinden, wenn sie nicht zeit- und kostenaufwändig aktualisiert werden. Das betrifft natürlich die von Einzelpersonen online veröffentlichten Daten sehr viel stärker als solche, die von Organisationen vorrätig gehalten werden, sofern diese eine Politik der langfristigen Speicherung verfolgen und nicht von der Menge der Daten erschlagen werden, was selbst die gigantischen Speicherkapazitäten der NSA begrenzt.
Einen Blick in den Bereich der Wissenschaften haben kanadische Forscher geworfen und einmal überprüft, wie lange auf Forschungsdaten zugegriffen werden kann. Dazu haben sie 516 Artikel mit morphologischen Daten von Pflanzen und Tieren herangezogen, die zwischen 1991 und 2011 veröffentlicht wurden. Herangezogen wurden einfache Daten, nämlich Längenmessungen, die seit Jahrzehnten gleich gemacht werden. Die wissenschaftlichen Untersuchungen waren mit Steuermitteln gefördert worden, die Daten sollten also zugänglich bleiben. Dabei zeigte sich, wie sie in ihrer Studie schreiben, die in Current Biology erschienen ist, dass der Zugang zu den Daten vor allem vom Alter der Artikel abhängig ist. Zwei Jahre nach der Veröffentlichung sind die Daten noch weitgehend für andere Wissenschaftler abrufbar, nach 20 Jahren schon sind 80 Prozent der Daten nicht mehr für Online- Recherchen verfügbar.
Dabei spielen Nachlässigkeit oder Wurstigkeit eine entscheidende Rolle. Wichtig für Wissenschaftskollegen ist, dass zumindest eine der Email-Adressen, die in den Artikeln angegeben werden, noch funktioniert um sich die Daten zusenden zu lassen. Immerhin konnte bei 74 Prozent der Artikel noch eine funktionierende Adresse gefunden werden. Erhalten haben die Autoren aber nur 101 Datensets (19%), 20 (4 %) seien noch in Arbeit und könnten nicht geteilt werden. Daher waren noch 121 Datensets der 516 Artikel, mithin 23 Prozent, verfügbar. Timothy Vines von der University of British Columbia findet das doch erstaunlich: "Ich denke, niemand erwartet, die Daten aus einem 50 Jahre alten Artikel erhalten zu können, aber zu entdecken, dass fast alle Daten innerhalb von 20 Jahren verschwunden sind, ist ein bisschen überraschend."
Wenn es eine funktionierende Email-Adresse gab, konnten keine Unterschiede zwischen alten und neueren Artikeln im Hinblick auf die Beantwortung einer Anfrage festgestellt werden. Aber es gibt einen starken Zusammenhang zwischen dem Alter des Artikels und der Verfügbarkeit der Daten sowie dem Vorhandensein einer funktionierenden Email-Adresse. Jedes Jahr sinkt die Chance, auf eine funktionierende Email-Adresse zu stoßen, um 7 Prozent, und die Möglichkeit, über die Autoren an die Originaldaten zu kommen, um 17 Prozent. Für die Nichtverfügbarkeit wurden unterschiedliche Gründe angegeben, wenn die ursprünglichen Autoren überhaupt erreicht werden konnten. Man sagen, die Daten seien ganz verloren, weil sie sich beispielsweise auf einem gestohlenen Computer befanden. Andere vermuteten, sie wären vielleicht noch an einem anderen Ort, oder sagten, sie seien sich einigermaßen sicher, dass sie sich noch irgendwo auf einer Diskette oder auf anderen Speichermedien befänden, aber dass sie diese aufgrund fehlender Hardware nicht mehr abrufen könnten. Das können daher auch Ausreden gewesen sein, weil die Befragten sich nicht die Mühe machen wollten, die Daten zu suchen und zu versenden.

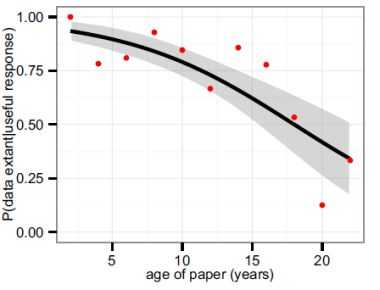
Es könne allerdings sein, dass die Email-Adressen nicht mehr so schnell gewechselt werden oder verschwinden, vor dem Jahr 2000 war dies noch deutlich häufiger als danach. Aber aus den Daten lässt sich noch nicht ableiten, ob sich hier eine stärkere Kontinuität ergibt. Allerdings scheint die Bereitschaft der Wissenschaftler, ihre Daten an Kollegen zu geben, sowieso nicht sonderlich ausgeprägt zu sein. Von den Wissenschaftlern, die Artikel im Jahr 2011 veröffentlichten, schickten nur 40 Prozent auf die Anfrage die Daten. Wenn die Wissenschaftler Auskunft über die Daten gaben, waren die zu den Artikeln aus 2011 gehörenden noch zu 100 Prozent vorhanden, 1991 nur noch zu 33 Prozent.
Viele der Daten, so die Autoren, seien einzigartig für die Zeit oder den Ort, an dem sie erhoben wurden. Wenn sie einmal verloren seien, könnten sie oft nicht ersetzt werden – oder nur mit hohen KOsten. Es sei daher unverantwortlich, ihre Aufbewahrung den einzelnen Wissenschaftlern zu überlassen, weil man nicht im Voraus wissen könne, on und zu welchen Zwecken sie noch gebraucht werden können. Wissenschaftler, die durch Steuergelder finanziert werden, müssten angehalten werden, ihre Daten einer öffentlichen Datenbank zu übergeben, wo sie vorrätig gehalten werden. Manche Wissenschaftsjournale speichern bereits auf ihren Servern die Daten ab, um sie vorrätig zu halten. Darauf setzen die Autoren vor allem: "Wissenschaftliche Daten gehen mit einer überraschenden Geschwindigkeit verloren, es ist eine konzertierte Aktion, vor allem seitens der Verlage, notwendig, um sicherzustellen, dass sie für künftige Forscher gespeichert sind", so Vines.