Hunch - Der Entscheidungsbaum als soziales Objekt
Der Erfolg von Web 2.0-Sites hängt ab von der Menge und dem Nutzen der Inhalte, die die Usergemeinde schafft und zugänglich macht: mehr Use führt zu mehr Usefulness führt zu mehr Usern/potenziellen Kunden
Zum Abschluss der Web 2.0 Expo in San Francisco vertrat Jyri Engeström, Co-Gründer des Twitter-ähnlichen Webservice Jaiku, in seinem Vortrag eine knackige Theorie: Die Erfolgreichen sind genau jene Web 2.0-Unternehmen, die nicht nur ein soziales Netzwerk schaffen, sondern die diesem Netzwerk ein "soziales Objekt" zu Grunde legen, das die User herstellen, teilen, handeln, verändern, kommentieren können. Das soziale Objekt von eBay ist die Versteigerung mit ihren Verkäuferbewertungen; das soziale Objekt bei Wikipedia ist die Lexikonseite mit ihrer Talk Page; das soziale Objekt von Flickr ist das Photo mit seinen Kommentaren.
Engeström denkt beispielsweise, dass LinkedIn früher kein soziales Objekt hatte; als reines soziales Netzwerk fand es zwar anfangs relativ schnell eine größere Anzahl von Usern, von denen viele dann aber bald wieder abwanderten, weil ohne Objekte keine längerfristigen Bindungen zwischen ihnen entstanden. Vor einiger Zeit haben sie offenbar den Job als ihr soziales Objekt definiert; der Service, so Engeström, zieht seiher wieder mehr User an. Mit anderen Worten, Engeströms Konzept des "sozialen Objekts" erscheint mir gerade ziemlich nützlich.
Schon bevor Flickr gegründet wurde, rangen diverse Photo Sharing Sites im Web um Aufmerksamkeit. Dann kam Flickr und machte das Foto zum Objekt, indem jedes einzelne von ihnen seine eigene Webpage bekam: den Permalink. Wo ein Permalink ist, ist ein soziales Objekt; man kann es weitergeben, kommentieren, geo-taggen, in Galerien, Alben, Blogs integrieren und so weiter. Flickr stllte dazu den Web-Programmierern ein Interface zu Verfügung, die so die Funktionalität der Flickr-Objekte in ihre eigenen Programme einbinden und nutzbar machen konnten.
Caterina Fake war 2004 Mitbegründer; Mitverdienerin, als Yahoo Flickr ein Jahr später für 35 Millionen Dollar kaufte; bis Juni 2008 dann als General Manager von Flickr Angestellte bei Yahoo. Sie kennt ihre sozialen Objekte, und man konnte gespannt sein, welches sie als Nächstes wählen würde. Vor allem, weil die sozialen Objekte, die am offensichtlichsten Profitabilität versprechen, schon jeweils mehrfach besetzt sind: YouTube, Vimeo, Hulu und so weiter konkurrieren um das Video als soziales Objekt; last.fm und andere Internetradios um das Musikstück; bei Facebook, twitter und ähnlichen "Personal PR"-Sites ist das Objekt der Status des Users, der durch Statusmeldungen aktualisiert und programmatisch nutzbar gemacht wird. Wir haben in den letzten fünf Jahren viele Experimente und manche Erfolge im Web 2.0 gesehen, und es verlangt einige Originalität, uns mit der Wahl eines sozialen Objekts als Grundlage für einen neuen Web 2.0 Service zu überraschen.
Nun, überrascht war ich, als ich am 27. März las, welches soziale Objekt sie gewählt hatte: den Entscheidungsbaum. Darauf war tatsächlich noch niemand gekommen! Nun, Caterina Fake ist jetzt Chief Product Officer bei einem Startup namens Hunch, wo User Usern helfen, Entscheidungen zu fällen, und zwar mit Hilfe von Enscheidungsbäumen. Wir stehen vor Fragen wie: "Welche Linux-Distribution sollte ich benutzen?" - "Welche 'World of Warcraft'-Klasse sollte ich spielen?" - "Sollte ich von Windows auf Mac umsteigen?"

Andere wissen die Antworten, weil sie die nötigen Informationen besitzen und deshalb über effektive Entscheidungskriterien verfügen. Und solches Wissen können wir nun als Mitglieder der Hunch-Community zur Verfügung stellen, indem wir es als Entscheidungsbaum kodieren, oder indem wir bereits kodierte Entscheidungsbäume verbessern. Der Konsument, oder "naive" Hunch-User, wählt eine Kategorie - "Computers & Internet" etwa oder "Entertainment & Media" -, sucht sich eine Frage aus und bekommt eine Reihe von aus dieser Frage folgenden weiteren Fragen gestellt, für die sie die für sie zutreffende Antwort aus einer Liste auswählen können. Jede mögliche Antwort, jeder "Ast" des Entscheidungsbaumes, ist assoziiert mit einer bestimmten Wahrscheinlichkeit des Zutreffens einer bestimmten Lösung, und resultiert demnach in der nächste Fragen, deren Antwort-Skala die für den Fall dieses speziellen Users richtige Lösung weiter eingrenzt. Meist reichen zwischen acht und zwölf Fragen und Antworten, dann landet man bei einem bestimmten "Blatt" des Baumes, auf dem die für diesen User wahrscheinlich "beste" Antwort auf die entscheidende Frage geschrieben steht. Ob das funktioniert? Wie kann man das testen?

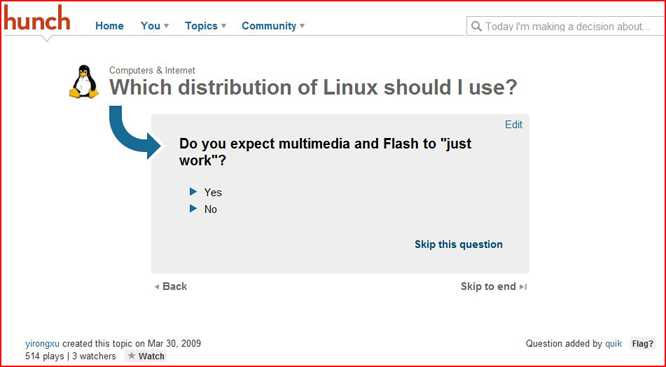
Am dritten Tag, fällt mir auf, dass es mittlerweile ein paar Fragen bei Hunch gibt, bei denen ich von Vornherein glaube, sagen zu können, welche Teilentscheidungen zu einer spezifischen Gesamtentscheidung führen sollten. Die Frage "Which distribution of Linux should I use?" beispielsweise habe ich vor einem Jahr entschieden, und wenn ich die Kriterien anlege, die mich damals zur Wahl von Ubuntu geführt haben, sollte ich die Fragen so beantworten können, dass das System mir am Ende rät, Ubuntu zu benutzen. Also versuche ich das, und hallo, Ubuntu kommt heraus. Nicht schlecht, denke ich.

Eine Woche später spiele ich dieselbe Frage - dasselbe Topic, in Hunch-Sprech - noch mal durch: diesmal kommt Fedora 10! Hallo? Ich stelle fest, dass der Entscheidungsbaum verändert wurde; der User Antonio D'souza alias quik hatte am 2.April die Frage: "Do you expect multimedia and Flash to 'just work'?" hinzugefügt, und ich hatte sie mit "Yes" beantwortet, weil ich damals tatsächlich erwartet hatte, dass Flash in Ubuntu "einfach funktionieren" würde. Tat es aber dann nicht, sondern ich musste erst herausfinden, dass man bei Linux-Systemen erst eine von mehreren Alternativen wählen muss, und nach welchen Kriterien. Da hat also die Weisheit der Menge, in Gestalt von Antonio D'souza, tatsächlich dazu geführt, dass jemand, der erwartet, dass Flash unter Linux "einfach funktioniert", nicht länger auf Ubuntu gestoßen wird, weil man das von Ubuntu eben nicht voraussetzen kann. Und ich kann als skeptischer Nutzer den Entscheidungsmechanismus mit seiner Entstehungs- und Veränderungsgeschichte inspizieren und Zeitpunkt und Verursacher jeder Veränderung lückenlos bestimmen. Das gefällt mir.

Als nächstes Test-Topic wähle ich "Which World of Warcraft class should I pick?", weil ich mal zu WoW recherchiert habe und glaube, genug über das System der Charakterklassen zu wissen, um die Fragen so beantworten zu können, dass das System mir am Ende die Klasse "Rogue" vorschlagen wird. Das klappt tadellos, am dritten ebenso wie am elften Tag nach der Hunch-Eröffnung. Einige dieser Entscheidungsbäume sind von Firmen wie Blizzard bezahlt und thematisieren Produkte wie World of Warcraft; deshalb trägt das Topic dann ein kleines WoW-Logo neben dem Titel. Das Linux-Topic trägt einen kleinen Pinguin - ich glaube aber nicht, dass jemand dafür bezahlt hat. Jedenfalls hat Hunch von Anfang an ein plausibel erscheinendes Geschäftsmodell, und zwar eines, das nicht auf Anzeigen basiert, und das ist momental vieleicht noch überraschenden, weil noch seltener, als ein neues cooles soziales Objekt.
Wird es abheben? Wird Hunch die kritische Masse an aktiven Usern erreichen, die es braucht, um den Entscheidungsbaum vom Arbor Obscurum zum brennenden Busch werden zu lassen? Das Blog sagt, dass sie am 27.März mit 30.000 eingeladenen Usern gestartet und seither täglich gewachsen sind; jeder User kann fünf weitere Einladungen verteilen. Am zwölften Tag zähle ich auf ihrem Index 1.569 Topics, gegliedert in 22 Kategorien. Außerdem hat die junge Gemeinde innerhalb von fünf Tagen 1,5 Millionen "Teach Hunch About You"-Fragen beantwortet, Fragen zur Größe des Haushaltes, Geschmacksfragen, moralische Fragen, alles mögliche. Das sind momentan die Daten, und wenn wir sie ansehen, dann sehen wir, dass wir noch nichts sehen, jedenfalls noch nichts Zukünftiges absehen können, doch das gegenwärtige Schauspiel ist spektakulär genug: wie mal wieder überraschender Weise eine spontan entstehende virtuelle Menschenmenge in kurzer Zeit eine riesige Menge neuer Daten über sich selbst produziert, auf Teufel komm raus, was wir damit machen, sehen wir später. Und ich bin mir sicher, dass wir davon noch nicht alles gesehen haben.