Gedankenlesen im Zeitalter der Gehirnscanner
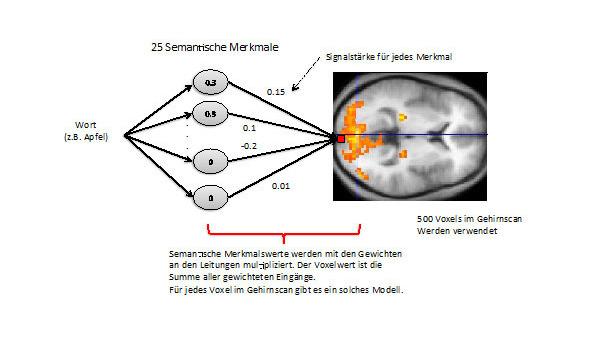
Lineares Modell für das Muster in jedem Voxel. Bild: R. Rojas
Forscher tasten langsam das Dickicht der Gehirnfunktionen ab und enträtseln nach und nach die Architektur des Gehirns
Bildgebende Verfahren in den Neurowissenschaften liefern immer feiner aufgelöste Bilder des Gehirns und seiner Funktionalität. Mittlerweile ist es möglich, das Aktivitätsmuster für gedachte Begriffe oder gesehene Muster approximativ vorherzusagen und mit gespeicherten Mustern zu vergleichen. Die fMRT-Geräte, sogenannte "Teleskope fürs Gehirn", sind immer wieder eine gute Quelle für Überraschungen.
Im vergangenen September wurde ein an der Universität Berkeley produziertes Video vorgestellt: Die Bildabfolge zeigt die rekonstruierte Aktivität des Gehirns beim Betrachten eines Videoclips von wenigen Sekunden Länge. Eine Person schaute sich ein kurzes Video an und der Computer versuchte anhand der dabei erzeugten und mit fMRT gemessenen Aktivitätsmuster im Gehirn, die gesehene Bildfolge zu erraten.
Das Ergebnis ist teilweise frappierend: Wenn Gesichter gesehen wurden, erzeugt der Computer auch Umrisse und Schatten von Gesichtern ungefähr an derselben Stelle und mit derselben Ausrichtung wie beim betrachteten Video (Weiterer Erfolg im "Gedankenlesen"). Dies stellt eine primitive Form des "Gedankenlesens" dar, das trotz der Einschränkungen der Messapparatur eindrucksvolle Resultate liefert. So tasten die Forscher langsam das Dickicht der Gehirnfunktionen ab und enträtseln peu à peu die Architektur des Gehirns.
Imaging Technology und Kognitionswissenschaften
Der menschliche Kortex ist nur wenige Millimeter dick, umhüllt das Gehirn und kommt somit der Oberfläche des Kopfes am nächsten. Da die Neuronen sich durch Ionenentladungen bemerkbar machen, ist es möglich, ihre Aktivität direkt mit Kopfsensoren, z.B. mit einem Elektroenzephalogramm (EEG), zu detektieren. Solche Messungen betreffen immer ein ausgedehntes Areal im Kortex. Nicht-invasive Verfahren müssen sich immer mit dieser relativ niedrigeren Auflösung zufrieden geben.

Eine höhere Auflösung und eine 3D-Ansicht der Gehirnaktivität kann durch fMRT-Messungen erreicht werden. Das Wort fMRT steht für funktionelle Magnetresonanztomographie. Der Kopf einer Person wird in ein sehr starkes Magnetfeld eingetaucht, wobei nacheinander Messungen in dünnen transversalen Schnitten vorgenommen werden, d.h. der Kopf wird gescannt: Das Magnetfeld arbeitet sich von oben nach unten durch, bis das ganze Gehirn angestrahlt wurde. Das Magnetfeld richtet zuerst Moleküle und geladene Teilchen im Gehirn aus, ein Radiosignal stört diese kollektive Ausrichtung, und wenn das Radiosignal ausgeschaltet wird, strahlen diese Moleküle selbst ein charakteristisches Signal aus. Detektoren um das Gehirn empfangen diese elektromagnetische Abstrahlung. Durch gezielte Änderungen des Magnetfeldes kann letzendlich ein Reflektionsspektrum des Areals berechnet und daraus eine Karte der Gehirnaktivität erstellt werden.
Bei fMRT wird eigentlich die Durchblutung von Gehirnregionen gemessen. Sind die Neuronen in einer Region sehr aktiv, steigt dort die Durchblutung. Fällt ihre Aktivität, fällt auch die Durchblutung. Diese indirekte Messung der Gehirnaktivität kann nicht zwischen inhibitorischen oder exzitatorischen Signalen unterscheiden und ist zudem langsam, da die Durchblutung sich auch nur allmählich ändern kann. Integrationszeiten von mehreren Sekunden sind deswegen notwendig. Somit können Gedanken mit fMRT nicht wirklich gelesen werden, da das Gehirn viel schneller arbeitet (wollen wir zumindest hoffen!), aber bei gezielten Experimenten mit geduldigen Probanden können trotzdem Schlüsse über die Gehirnaktivität gezogen werden.
Es geht dabei um das reverse engineering des Gehirns. Als die ersten fMRT-Geräte vorgestellt wurden (vor kaum etwa 20 Jahren), war es nicht ganz klar, ob damit die Ausgabe-Spikes von Gehirnregionen oder nur der Energieverbrauch gemessen wurde. Später wurde klar, dass vor allem der Energieverbrauch gemessen wird, allerdings mit einer deutlichen Verzögerung.1 Seitdem hat es eine wahre Explosion an fMRT-Studien gegeben. Es ist wie bei der Erfindung des Mikroskops: Plötzlich wird eine ganz neue Welt sichtbar. Dass allerdings die Messungen kompliziert sind und große statistische Sorgfalt benötigen, wurde nicht zuletzt durch das Beispiel des toten Lachses im fMRT-Zylinder, der menschliche Emotionen in Gesichter "erkennen" konnte, unterstrichen.2
Das semantische Gehirn
Einen wichtigen Auftritt haben fMRT-Scans haben erfahren, als Spezialisten für Maschinelles Lernen zur Hilfe herangezogen wurden. Die fMRT-Bildsequenzen können sehr verwickelt sein, da die Aktivitäten von mehreren Tausenden Voxel (das 3D-Äquivalent von Pixeln) interpretiert werden müssen. Bereits bei den simpelsten Aufgaben blitzt es überall im Gehirn, da viele Gehirnareale eine Art Superkomitee für jede Entscheidung und Erkennung bilden.
Bei vielen früheren Studien hat man sich mit der Beschreibung des "Leuchtmusters" zufrieden gegeben. So können wir immer wieder über neue Sichtungen von kognitiven Funktionen lesen. Sogar die Werbespezialisten schieben jetzt Probanden in den fMRT-Zylinder und beobachten ihre Gehirne bei der Betrachtung von Werbeclips bzw. bei Kaufentscheidungen (das sogenannte Neuroeconomics). Dass manche Leute ihre Handys "lieben", behauptet z.B. Martin Lindstrom, da bei Probanden die "Liebe-Regionen" des Gehirns aktiv wurden, sobald deren Handy klingelte.3
Wie kann man dann aber bei ernsteren Versuchen fMRT-Muster voneinander unterscheiden und vor allem, kann man sie gewissermaßen vorhersagen? Diese Frage haben der Amerikaner Tom Mitchell und Mitarbeiter in einer bahnbrechenden Arbeit im Jahr 2008 beantwortet.4 Ihr in der Zeitschrift Science veröffentlichtes Paper hat ein neues Paradigma für die Deutung von fMRT-Messungen eröffnet und seitdem zu vielen Folgeuntersuchungen geführt. Mitchell und Co. haben nämlich die Abbildung von Gegenständen im Gehirn untersucht, d.h. wie glimmt das fMRT-Signal, wenn man an ein Haus oder an einen Hund denkt? Gibt es Unterschiede? Und wenn es sie gibt, können wir vorhersagen, wie das Gehirn bei einem neuen Wort beim fMRT funkeln wird?
Es ist schon seit Jahrzehnten bekannt, dass das Gehirn Begriffe in semantische Klassen unterteilt. Vor allem durch die Untersuchung von Patienten, die gewisse Probleme mit der Erkennung oder Nennung von Objekten aufwiesen, wurden "semantische Dimensionen" entdeckt. Wenn wir z.B. über Hunde und Katzen oder über Steine und Erde nachdenken, ist eine der ersten semantischen Unterscheidungen im Gehirn die zwischen lebendigen und nicht lebendigen Objekten. Noch mehr: Anscheinend wird dieser Unterschied in ungleichen Gehirnarealen verarbeitet, da manche Personen Lebewesen, die ihnen gezeigt werden, benennen können, nicht aber unbelebte Objekte. Die umgekehrte semantische "Aphasie" gibt es auch. Es gibt andere Patienten, die Schwierigkeiten mit dem Unterschied zwischen manipulierbaren und nicht manipulierbaren Objekte haben, usw.
Es ist, als ob das Gehirn, sobald ein Objekt gesehen oder an es gedacht wird, sofort ein paar Etiketten dazu klebt, die dann das Begreifen des Objekts erlauben, wie z.B.: es ist nicht-lebendig, es ist manipulierbar, es ist klein, es ist essbar, es ist kompakt. Es könnte ein Apfel sein und weitere Gehirnareale würden dies bestätigen. Sind aber die semantischen Dimensionen im Gehirn beschädigt, kann der Patient das Objekt sehen, nicht aber benennen, und ist sich auch nicht richtig sicher darüber, was das ist.5
Tom Mitchell hat bei seinen Experimenten einen Satz von Substantiven benutzt, nämlich 60, die die verschiedenen semantischen Dimensionen abdecken. Er hat für seine Experimente 25 sogenannte semantische Merkmale ausgewählt und diese durch 25 verschiedene Verben repräsentiert. Die ausgewählten Verben waren auf Englisch: see, hear, listen, taste, smell, eat, touch, rub, lift, manipulate, run, push, fill, move, ride, say, fear, open, approach, near, enter, drive, wear, break, und clean. Für jedes Substantiv wurde in einer umfangreichen Text-Datenbank nachgeschaut, wie oft es sehr nah zu diesen 25 Verben erscheint. Das Wort Apfel hat beispielsweise eine größere "Nähe" zu "essen", "riechen" und "kosten" als zu "fahren", "benutzen" oder "brechen".
Die Kookkurrenz eines jedes Substantivs zu den 25 Verben wird dann in einen Satz von 25 Zahlen verwandelt. Apfel z.B. könnte als der Vektor mit dreimal 33% Kookkurrenz mit den drei Verben "essen", "riechen", und "kosten" und fast Null mit all den anderen geschrieben werden (so dass die Summe aller Zahlen 100% ergibt). Dann wird angenommen, dass sich alle semantische Merkmale im Gehirn linear überlagern, mit unterschiedlichen Gewichtungen. Die Abb. 2 zeigt das von Mitchell verwendete Modell.
Jedes Voxel im Modell hat eine Aktivität, die eine gewichtete Summe der 25 semantischen Merkmale darstellt, d.h. pro Voxel haben wir 25 gewichtete Leitungen. Die passenden Gewichte werden aus 60 Bildern dieses Voxels für 60 Worte und ihre jeweilige semantische Codierung gelernt (d.h. sie werden einfach mittels minimalen Quadraten angepasst). Am Ende haben wir damit ein einfaches Modell für die Produktion aller Voxelwerte im Bild.
Jetzt kommt das Interessante: Wollen wir das fMRT-Muster für ein neues Wort vorhersagen, können wir das Wort zuerst in semantische Merkmale kodieren (automatisch, durch die Nähe zu den oben erwähnten 25 Verben) und dann die 25 Zahlen als Eingabe für das Modell verwenden. Das Resultat ist eine Prognose des erwarteten Signals für jedes Voxel im fMRT-Bild.
Wie man sieht, ist das Modell erstaunlich einfach. Es wird angenommen, dass sich die verschiedenen semantischen Muster einfach aufaddieren lassen (proportional zu der Stärke des semantischen Merkmals) und dass es keinen "crosstalk" gibt, so dass kein Voxel einen anderen "behindert" oder schwächer macht.
Man kann jetzt folgendes Experiment durchführen: Man nimmt zwei Wörter und nur eines davon wird den Probanden gezeigt. Für beide Wörter werden ihre semantischen Merkmale und damit die erwarteten Gehirnmuster berechnet (anhand des berechneten Modells). Der Experimentator rät das Wort, dessen vorhergesagtes Muster am ähnlichsten zum fMRT-Bild ist. Wäre damit das richtige Wort nur zufällig ausgewählt worden, würde man nur 50% richtige Prognosen erwarten. In Wirklichkeit werden etwa 77% der Worte bei verschiedenen Probanden richtig erraten.
Damit ist klar, dass das Modell trotz seiner Einfachheit teilweise die Realität der Gehirnaktivität wiederspiegelt. Wenn außerdem geschaut wird, welche Gehirnareale für die unterschiedlichen semantischen Merkmale "zuständig" sind, findet man z.B. für das Wort "Essen" Aktivität im Teil des Cortex, das für Schmecken zuständig ist. Es ist, als ob das Gehirn primitiverweise bereits vorhandene Areale einfach wiederverwendet und so die Welt darum herum kodiert und versteht.

Das YouTube-Gehirn
Womit wir zum Anfang zurückkehren. Das Experiment in Berkeley ähnelt den Experimenten von Mitchell.6 Wenige Sekunden lange Videoclips wurden Probanden gezeigt. Die Videoclips wurden in Merkmale, in diesem Fall visuelle Merkmale, verwandelt, die Gestalt, Kanten und Bewegung in einer visuellen Region beschreiben. Die mit fMRT registrierten Gehirnmuster werden dazu verwendet, Klassifikatoren für jedes Voxel im Gehirn zu bestimmen, wobei die visuellen Merkmale die Eingabe in das Modell darstellen. Der Prozess ist sehr ähnlich wie bei Mitchell, statt der semantischen werden eben visuelle Merkmale verwendet.
Schaut jetzt ein Proband ein für den Experimentator unbekanntes Videoclip von YouTube an, werden dessen Gehirnmuster gespeichert. Dann werden mit den trainierten Klassifikatoren die Gehirnmuster für 18 Millionen Sekunden von zufällig ausgewählten YouTube-Videoclips vorhergesagt. Die 100 am besten passenden Clips zum beobachteten Gehirnmuster (in der vorgegebenen Zeit von wenigen Sekunden) werden dann einfach überlagert und gewichtet mit dem Grad der Ähnlichkeit zum beobachteten Muster. Das Resultat wird abgespielt. Da fMRT-Signale zu langsam im Vergleich zu Videos sind, wurde ein Modell der neuronalen Aktivität vorgeschaltet, die das Endergebnis verbessert.
Eigentlich würde man bei der Überlagerung von 100 Videoclips aus YouTube einfach ein wirres Video erwarten - das Resultat ist jedoch nicht so chaotisch. Schatten und Formen wie beim vom Proband beobachteten Videoclip sind auszumachen. Am besten schaut man sich selber das Ergebnis auf der Webseite des Labors von Prof. Jack Gallant in Berkeley an.
Obwohl man vielleicht jetzt vermuten könnte, dass die Dekodierung des Gehirns damit in nicht allzuweiter Ferne liegen sollte, ist dem nicht so. Die hier besprochenen Experimente sind erste Anzeichen dafür, dass das Gehirn gewissen Prinzipien folgt, die in einer komplexen inneren Architektur vergegenständlicht sind. Dies ist nur das erste "Stammeln" einer Technologie, die kaum zwei Jahrzehnte alt ist. Die Technologie ist weit gekommen, aber nicht so weit, dass man befürchten müsste, die Gedanken wären nicht mehr frei.7 Wie bei jeder Technik gibt es jedoch sicherlich immer Spielraum für viele Arten von Missbrauch und man sollte der jeweiligen "homeland security" in Zukunft aufmerksam auf die Finger schauen.