Computer liest Gedanken - fast
Kann man an der Gehirnaktivität eines Menschen ablesen, woran der gerade denkt? US-Forscher haben den ersten Schritt dorthin per Software gelöst
Wenn man ganz materialistisch davon ausgeht, dass all unsere Gedanken physische Entsprechungen im Gehirn haben müssen, dann ist Gedanken zu lesen im Prinzip eine sehr einfache Aufgabe. Herausfinden muss man dazu ja nur, welche Form genau einem bestimmten Gedanken entspricht. Trotz der Existenz der funktionellen Magnetresonanztomografie, die schon sehr erfolgreich die gerade aktiven Schaltstellen im Gehirn ausfindig macht, gibt es noch keinen Gedankenlese-Apparat - zumindest wurde in der Fachliteratur noch nicht davon berichtet.
Das liegt vor allem an zwei bisher ungeklärten Problemen: Zum einen kann ein Mensch eine Menge Gedanken formen: abstrakte, konkrete, fantastische… Zum anderen ist noch nicht klar, ob zwei identische Gedanken bei unterschiedlichen Menschen auch gleich aussehen. Die Forschung war deshalb bisher vor allem mit dem Katalogisieren beschäftigt. Was passiert wann und wo im menschlichen Gehirn?
Ein gehöriger Schritt voran ist nun einem amerikanischen Forscherteam gelungen, das seine Ergebnisse zwar noch nicht per Gedankenübertragung in die Welt überträgt, aber immerhin in der renommierten Fachzeitschrift Science davon berichtet. Die Wissenschaftler haben, kurz gesagt, ein Computermodell geschaffen, das mit erstaunlicher Sicherheit die Gehirnaktivität eines Menschen voraussagen kann, der gerade an einen bestimmten Gegenstand denkt. Dazu braucht das System das betreffende Wort nicht zu erlernen - es benötigt lediglich eine Trainingsphase mit 60 anderen Wörtern.

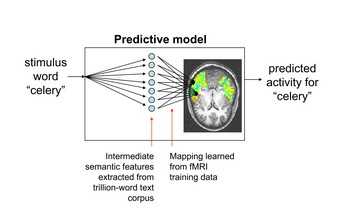
Das Prinzip dahinter: Die Forscher setzen darauf, dass Substantive eine Bedeutung besitzen. Diese Bedeutung lässt sich unterschiedlichen Kategorien zuordnen und zwar in mehr oder weniger starkem Maße. Ein Gemüse etwa passt eher zu „essen“ als zu „fürchten“, wobei etwa bei „Spinat“ bei manch einem der Koeffizient für „fürchten“ nahe oder gar über dem für „essen“ liegen dürfte.
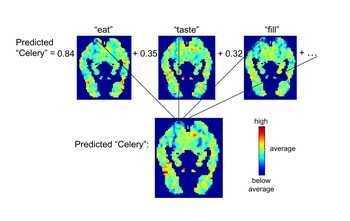
Den Wörtern lassen sich die Kategorien also mit gewissen Koeffizienten zuordnen, je näher bei 1, desto besser passt die Kategorie. Jetzt benötigt man nur noch Lernwörter, um eine Verbindung zwischen Gehirnaktivität und der speziellen Ausprägung jeder Kategorie herstellen zu können - die Forscher kamen dabei mit 60 Trainingsvokabeln aus.
Die Gehirnaktivität bei unbekannten Wörtern lässt sich dann daraus vorhersagen, dass man die Aktivitäten der dem Wort zugeordneten Kategorien linear kombiniert. Das funktionierte überraschend gut - im Mittel mit über 75 Prozent Wahrscheinlichkeit. Die Forscher nutzten eine selbst erstellte Kategorienliste, die aus den Wörtern see, hear, listen, taste, smell, eat, touch, rub, lift, manipulate, run, push, fill, move, ride, say, fear, open, approach, near, enter, drive, wear, break und clean bestand. Doch selbst wenn die Kategorien per Zufall festgelegt wurden, lag die Vorhersagegenauigkeit noch über 50 Prozent.
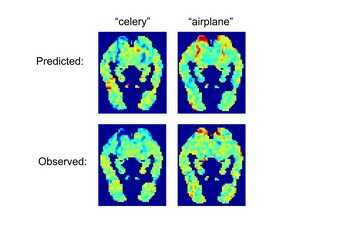
Dabei zeigte sich, dass die vorhergesagten Muster in der linken Gehirnhälfte genauer als in der rechten waren - das passt, so die Forscher, zu der verbreiteten Ansicht, dass die linke Gehirnhälfte in stärkerem Maße für die semantische Kodierung zuständig ist. Statistisch schwerer zu unterscheiden ließen sich dabei sehr ähnliche Wörter, die den gleichen Kategorien angehören: Spinat und Grünkohl etwa klingen und schmecken zwar ganz anders, repräsentieren aber ähnliche Gehirnmuster. Interessanterweise waren die Unterschiede von Proband zu Proband dabei klein genug, dass die Software immer noch über der Zufallswahrscheinlichkeit lag, wenn es galt, mit Daten einer Person die Gedankenmuster einer anderen vorherzusagen.
Mit echtem Gedankenlesen hat das Computermodell der Forscher noch nicht viel zu tun. Allein schon deshalb, weil die Probanden hier bewusst und möglichst ohne Ablenkung an ein Wort denken und dessen Bild betrachten mussten. Schon, wenn dazu eine Kopfbewegung nötig war, verschlechterten sich die Vorhersagen. Was die Software aber schon kann: Einem bestimmten Aktivitätsmuster aus einer Reihe von 1000 Wörtern die wahrscheinlichste Bedeutung zuzuordnen. Mit einer Wahrscheinlichkeit von im Mittel 72 Prozent fand das Programm dabei den tatsächlichen Gedanken des Probanden heraus. In der Zukunft wollen die Forscher ihre Arbeit mit Adjektiv-Substantiv-Kombinationen und einfachen Sätzen fortsetzen. Zudem wollen sie untersuchen, wie das Gehirn abstrakte Wörter und Konzepte darstellt.