C++ Core Guidelines: Ordnung von benutzerdefinierten Datentypen
Inspiriert durch die Guidelines geht es nun um eine generische isSmaller-Funktion.
Mein Artikel heute lehnt sich nur leicht an die C++ Core Guidelines an, denn diese besitzen beim Thema nicht viel Inhalt. Inspiriert durch die Guidelines beschäftige ich mich mit einer generischen isSmaller-Funktion.
Dies sind die Regeln für den heutigen Artikel, an die mich nur sehr leicht anlehne.
- T.64: Use specialization to provide alternative implementations of class templates [1]
- T.65: Use tag dispatch to provide alternative implementations of functions [2]
- T.67: Use specialization to provide alternative implementations for irregular type [3]
Es geht also um Template-Spezialisierung.
Vergleich zweier Accounts: die Erste
Ich möchte gerne einfach anfangen. Daher starte ich mit einer Klasse Account. Für zwei Accounts möchte ich wissen, welcher kleiner ist. Kleiner bedeutet in meinem Fall, auf welchem Account sich weniger Geld befindet:
// isSmaller.cpp
#include <iostream>
class Account{
public:
Account() = default;
Account(double b): balance(b){}
double getBalance() const {
return balance;
}
private:
double balance{0.0};
};
template<typename T>
bool isSmaller(T fir, T sec){
return fir < sec;
}
int main(){
std::cout << std::boolalpha << std::endl;
double firDoub{};
double secDoub{2014.0};
std::cout << "isSmaller(firDoub, secDoub): " << isSmaller(firDoub, secDoub) << std::endl;
Account firAcc{};
Account secAcc{2014.0};
std::cout << "isSmaller(firAcc, secAcc): " << isSmaller(firAcc, secAcc) << std::endl;
std::cout << std::endl;
}
Um mir die Arbeit einfach zu machen, implementiere ich eine generische isSmaller-Funktion (1). Leider klappt das nicht, da sich zwei Accounts nicht vergleichen lassen.. Ich habe den operator< nicht implementiert.

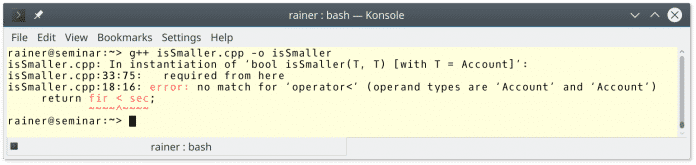
Bevor ich das Problem in verschieden Varianten lösen werden, möchte ich einen kleinen Umweg zu regulären und semiregulären Datentypen machen. Dies aus dem einfachen Grund, da Alexander Stepanovs ursprüngliche Definition von regulären Datentypen von der der C++20 Concepts in einem Punkt abweicht: Ordnung.
Semireguläre und reguläre Datentypen
Die Regel T.67: Use specialization to provide alternative implementations for irregular type [4] bezieht sich auf nichtreguläre Datentypen. Der Begriff "nichtregulär" steht für Datentypen, die weder SemiRegular noch Regular sind. Hier ist als kleine Erinnerungsstütze die Definition von semiregulären und regulären Datentypen:
Regular
- DefaultConstructible
- CopyConstructible, CopyAssignable
- MoveConstructible, MoveAssignable
- Destructible
- Swappable
- EqualityComparable
SemiRegular
- SemiRegular - EqualityComparable
Wenn du mehr Details zu Regular und SemiRegular wissen willst, findest du diese in meinem Artikel "C++ Core Guidelines: Reguläre und semireguäre Datentypen [5]".
Account ist semireguär aber nicht regulär:
// accountSemiRegular.cpp
#include <experimental/type_traits>
#include <iostream>
class Account{
public:
Account() = default;
Account(double b): balance(b){}
double getAccount() const {
return balance;
}
private:
double balance{0.0};
};
template<typename T>
using equal_comparable_t = decltype(std::declval<T&>() == std::declval<T&>());
template<typename T>
struct isEqualityComparable:
std::experimental::is_detected<equal_comparable_t, T>
{};
template<typename T>
struct isSemiRegular: std::integral_constant<bool,
std::is_default_constructible<T>::value &&
std::is_copy_constructible<T>::value &&
std::is_copy_assignable<T>::value &&
std::is_move_constructible<T>::value &&
std::is_move_assignable<T>::value &&
std::is_destructible<T>::value &&
std::is_swappable<T>::value >{};
template<typename T>
struct isRegular: std::integral_constant<bool,
isSemiRegular<T>::value &&
isEqualityComparable<T>::value >{};
int main(){
std::cout << std::boolalpha << std::endl;
std::cout << "isSemiRegular<Account>::value: " << isSemiRegular<Account>::value << std::endl;
std::cout << "isRegular<Account>::value: " << isRegular<Account>::value << std::endl;
std::cout << std::endl;
}
Die Ausgabe des Programms zeigt, dass Account nicht regulär ist.
Die Details zu dem Programm gibt es auch in dem bereits veröffentlichten Artikel "C++ Core Guidelines: Reguläre und semireguäre Datentypen [6]".
Indem ich dem Datentyp Account einen Gleichheitsoperator (operator ==) spendiere, wird dieser regulär:
// accountRegular.cpp
#include <iostream>
class Account{
public:
Account() = default;
Account(double b): balance(b){}
friend bool operator == (Account const& fir, Account const& sec) { // (1)
return fir.getBalance() == sec.getBalance();
}
double getBalance() const {
return balance;
}
private:
double balance{0.0};
};
template<typename T>
bool isSmaller(T fir, T sec){
return fir < sec;
}
int main(){
std::cout << std::boolalpha << std::endl;
double firDou{};
double secDou{2014.0};
std::cout << "isSmaller(firDou, secDou): " << isSmaller(firDou, secDou) << std::endl;
Account firAcc{};
Account secAcc{2014.0};
std::cout << "isSmaller(firAcc, secAcc): " << isSmaller(firAcc, secAcc) << std::endl;
std::cout << std::endl;
}
Leider lassen sich Accounts immer noch nicht vergleichen.
Die ist der entscheidende Unterschied zwischen regulären Datentypen, wie sie Alexander Stepanov beschreibt, und dem Concept Regular, wie sie C++20 definiert. Laut Stepanov sollte ein regulärer Datentyp eine totale Ordnung unterstützen.
Jetzt komme ich wieder zu meinem ursprünglichen Plan zurück.
Vergleich zweier Accounts: die Zweite
Die zentrale Idee meiner Variationen ist es, dass sich konkrete Accounts mit der generischen isSmaller-Funktion vergleichen lassen.
Überladen des operator <
Dies ist offensichtlich die naheliegendste Lösung. Selbst die Fehlermeldung des Programms isSmaller.cpp hat mich darauf hingewiesen:
// accountIsSmaller1.cpp
#include <iostream>
class Account{
public:
Account() = default;
Account(double b): balance(b){}
friend bool operator == (Account const& fir, Account const& sec) {
return fir.getBalance() == sec.getBalance();
}
friend bool operator < (Account const& fir, Account const& sec) {
return fir.getBalance() < sec.getBalance();
}
double getBalance() const {
return balance;
}
private:
double balance{0.0};
};
template<typename T>
bool isSmaller(T fir, T sec){
return fir < sec;
}
int main(){
std::cout << std::boolalpha << std::endl;
double firDou{};
double secDou{2014.0};
std::cout << "isSmaller(firDou, secDou): " << isSmaller(firDou, secDou) << std::endl;
Account firAcc{};
Account secAcc{2014.0};
std::cout << "isSmaller(firAcc, secAcc): " << isSmaller(firAcc, secAcc) << std::endl;
std::cout << std::endl;
}
Vollständige Spezialisierung der Funktion isSmaller
Falls du die Definition von Account nicht ändern kannst, kannst du zumindest isSmaller für Account vollständig spezialisieren:
// accountIsSmaller2.cpp
#include <iostream>
class Account{
public:
Account() = default;
Account(double b): balance(b){}
friend bool operator == (Account const& fir, Account const& sec) {
return fir.getBalance() == sec.getBalance();
}
double getBalance() const {
return balance;
}
private:
double balance{0.0};
};
template<typename T>
bool isSmaller(T fir, T sec){
return fir < sec;
}
template<>
bool isSmaller<Account>(Account fir, Account sec){
return fir.getBalance() < sec.getBalance();
}
int main(){
std::cout << std::boolalpha << std::endl;
double firDou{};
double secDou{2014.0};
std::cout << "isSmaller(firDou, secDou): " << isSmaller(firDou, secDou) << std::endl;
Account firAcc{};
Account secAcc{2014.0};
std::cout << "isSmaller(firAcc, secAcc): " << isSmaller(firAcc, secAcc) << std::endl;
std::cout << std::endl;
}
Nebenbei gesagt, eine nichtgenerische Funktion bool isSmaller(Account fir, Account sec) hätte diesen Job auch erfüllt.
Erweiterung von isSmaller um eine binäres Prädikat
Es gibt eine weitere Variante für die generische Funktion isSmaller. isSmaller erhält einen zusätzlichen Typ-Parameter für ein binäres Prädikat. Diese Strategie wird häufig in der Standard Template Library verwendet:
// accountIsSmaller3.cpp
#include <functional>
#include <iostream>
#include <string>
class Account{
public:
Account() = default;
Account(double b): balance(b){}
friend bool operator == (Account const& fir, Account const& sec) {
return fir.getBalance() == sec.getBalance();
}
double getBalance() const {
return balance;
}
private:
double balance{0.0};
};
template <typename T, typename Pred = std::less<T> > // (1)
bool isSmaller(T fir, T sec, Pred pred = Pred() ){ // (2)
return pred(fir, sec); // (3)
}
int main(){
std::cout << std::boolalpha << std::endl;
double firDou{};
double secDou{2014.0};
std::cout << "isSmaller(firDou, secDou): " << isSmaller(firDou, secDou) << std::endl;
Account firAcc{};
Account secAcc{2014.0};
auto res = isSmaller(firAcc, secAcc, [](const Account& fir, const Account& sec){
return fir.getBalance() < sec.getBalance();
});
std::cout << "isSmaller(firAcc, secAcc): " << res << std::endl;
std::cout << std::endl;
std::string firStr = "AAA";
std::string secStr = "BB";
std::cout << "isSmaller(firStr, secStr): " << isSmaller(firStr, secStr) << std::endl;
auto res2 = isSmaller(firStr, secStr, [](const std::string& fir, const std::string& sec){
return fir.length() < sec.length();
});
std::cout << "isSmaller(firStr, secStr): " << res2 << std::endl;
std::cout << std::endl;
}
Die generische Funktion wendet std::less<T> als Default-Ordnung (1) an. Dazu wird das binäre Prädikat in der Zeile (2) instanziiert und in der Zeile (3) verwendet. Wenn du dieses Prädikat nicht setzt, kommt std::less<T> zum Einsatz. Zusätzlich lässt sich ein binäres Prädikat wie in Zeile (4) oder (5) verwenden. Eine Lambda-Funktion ist der ideale Kandidat für diesen Anwendungsfall.
Zum Abschluss kommt die Ausgabe des Programms:
Worin unterscheiden sich die drei Variationen?
Vergleich zweier Accounts: die Dritte

Die vollständige Spezialisierung ist keine allgemeine Lösung, denn sie funktioniert nur für isSmaller. Im Gegensatz dazu lässt sich der Vergleichsoperator (operator <) sehr häufig anwenden. Entsprechend kann das Prädikat für jeden Datentyp verwendet werden. Der Vergleichsoperator und die vollständige Spezialisierung sind statisch. Das heißt, dass die Ordnung zur Compilezeit definiert wird und in dem Datentyp oder der generischen Funktion codiert ist. Im Gegensatz dazu lässt sich die Erweiterung mit verschiedenen Prädikaten aufrufen. Diese Entscheidung fällt erst zur Laufzeit. Der Vergleichsoperator erweitert den Datentyp, die beiden Varianten die generische Funktion. Die Erweiterung durch das Prädikat ist die einzige Variante, die verschiedene Ordnung unterstützt. So lassen sich zum Beispiel Strings lexikographisch oder aufgrund ihrer Länge vergleichen.
Basierend auf diesem Vergleich ist es eine einfache Daumenregel, den Vergleichsoperator (operator <) für deinen Datentyp zu implementieren und dann eine generische Funktion mit einem Erweiterungspunkt zu versehen, wenn dies notwendig ist. Damit verhalten sich deine Datentypen im Sinne von Alexander Stepanov regulär und können auf verschiedene Arten verglichen werden.
Wie geht's weiter ?
Im nächsten Artikel geht es mit Templates weiter. Insbesondere geht um Templates und Ableitungshierarchie. ( [7])
URL dieses Artikels:
https://www.heise.de/-4246119
Links in diesem Artikel:
[1] http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rt-specialization
[2] http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rt-tag-dispatch
[3] http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rt-specialization2
[4] http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rt-specialization2
[5] https://www.heise.de/blog/C-Core-Guidelines-Regulaere-und-semiregulaere-Datentypen-4232030.html
[6] https://www.heise.de/blog/C-Core-Guidelines-Regulaere-und-semiregulaere-Datentypen-4232030.html
[7] mailto:rainer@grimm-jaud.de
Copyright © 2018 Heise Medien