Künstliche Intelligenz: eine subjektive Bestandsaufnahme
Künstliche Intelligenz hat das Labor verlassen und ist in der Realität eines jeden von uns angekommen. Aber haben wir noch Einfluss auf das, was da passiert?
Herzlich willkommen zu dem neuen Blog auf heise Developer rund um das Thema künstliche Intelligenz, lieber Mensch. Und auch herzlich willkommen, liebe Maschine. Denn ich bin mir sicher, dass du diesen Text mittels Natural Language Processing (kurz NLP) scannen, analysieren, bewerten, katalogisieren, klassifizieren, verdichten, verschlagworten, übersetzen und eventuell sogar „sinnvoll“ ergänzen wirst.
Weiterlesen nach der Anzeige
Von Menschen und Maschinen - Lars Röwekamp
Lars Röwekamp, Gründer des IT-Beratungs- und Entwicklungsunternehmens open knowledge GmbH, beschäftigt sich im Rahmen seiner Tätigkeit als "CIO New Technologies" mit der eingehenden Analyse und Bewertung neuer Software- und Technologietrends, mit Schwerpunkt auf den Bereichen Machine Learning und Cloud Computing.
Ein besonderes Augenmerk seiner Arbeit liegt in der Einbettung von ML-basierten Prozessen und Anwendungen in die bestehende IT Landschaft von Unternehmen. Gemeinsam mit seinen Kunden analysiert er die Möglichkeiten – und Grenzen - der Erweiterung und Optimierung von Geschäftsprozessen auf Grundlage ML-basierter Ansätze und setzt diese mit Unterstützung seines Teams bis zur Produktionsreife um.
Lars ist Autor mehrerer Fachartikel und -bücher.
Warum ein KI-Blog?
Warum ein heise Blog zu dem Thema KI? Und warum gerade jetzt? Hat doch Alan Turing bereits 1950, also vor mehr als 70 Jahren, seinen berühmten Turing Test entworfen, der uns noch heute täglich millionenfach in Form von Captchas (completely automated public Turing test to tell computers and humans apart) begegnet. Und auch einen ersten, zugegebenermaßen eher primitiven Chatbot namens ELIZA gab es bereits 1966, entwickelt von J. Weizenbaum am MIT.
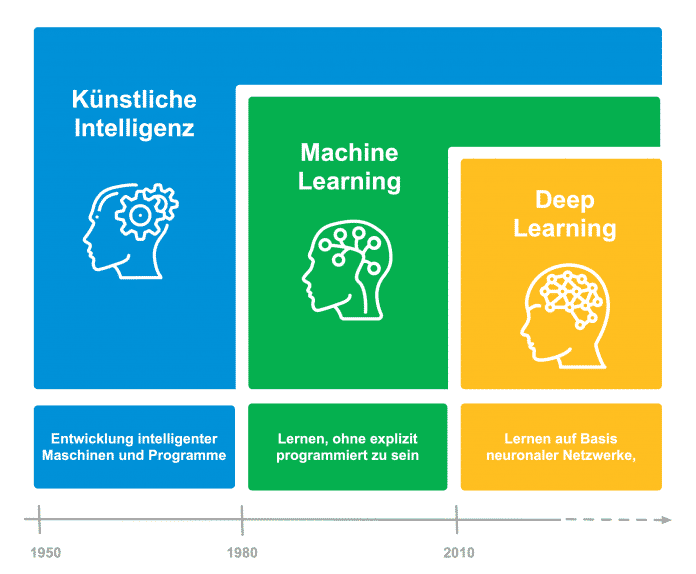
Das Diagramm zeigt die historische Entwicklung der Disziplin künstliche Intelligenz mit ihrer Teildisziplin Machine Learning und dessen Teildisziplin Deep Learning (Abb. 1).
(Bild: open knowledge)
Ist KI damit nicht ein alter Hut und der Blog etliche Jahre zu spät? Die Antwort auf diese Frage ist so einfach wie herausfordernd: KI ist heute kein Nischenfeld der Forschung mehr, sondern in der Praxis angekommen und berührt damit den Alltag eines jeden von uns – ob wir damit einverstanden sind oder nicht. Während KI noch vor zehn Jahren hauptsächlich im akademischen Umfeld zu Hause war, herrscht seit einigen Jahren auch in vielen Unternehmen Goldgräberstimmung, wenn es um das Thema künstliche Intelligenz geht. Die Tragweite dessen, was sie mit dem Einsatz von KI potentiell auslösen, scheint dabei nicht immer bewusst zu sein.
KI und Herausforderungen in der Realität
Mit dem Einzug von KI/ML in die reale (Wirtschafts)-Welt und damit auch in unser tägliches Leben entstehen neue Herausforderungen. Nicht mehr das Erreichen eines hochoptimierten Vorhersageergebnisses unter Laborbedingungen steht im Vordergrund, sondern schlicht und einfach die Praxistauglichkeit eines Modells. Und das sowohl während des Designs und des Trainings des Modells als auch zur Laufzeit und somit im produktiven Einsatz.
Wie einfach kommt man an die fürs Training benötigten Daten? Welche Qualität sollten diese mindestens haben? Und wie wird sichergestellt, dass die Daten keinen unerwünschten Bias mit sich bringen? Wie bettet man das Modell in die vorhandene Softwarelandschaft ein? Und wie spielt dabei der ML-Entwicklungsprozess mit dem hauseigenen Software-Development-Lifecycle zusammen?
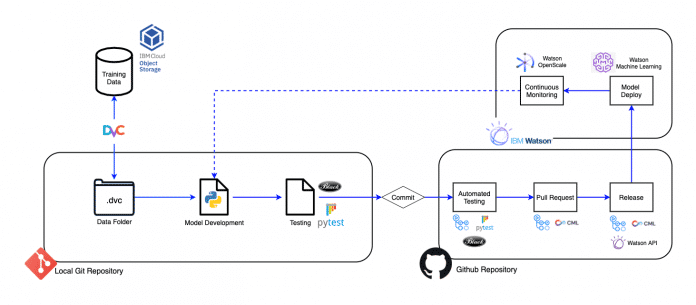
Auch die Frage nach der Nachhaltigkeit des Modells stellt sich, denn in der Regel geht es nicht darum, einmalig ein sehr gutes Ergebnis zu erzielen, sondern über einen möglichst langen Zeitraum gleichbleibend gute Resultate. In diesem Kontext kommen zusätzliche Aspekte, wie Model Observability, Data und Model Drifting, Retraining , CI/CD-Pipelines, Colaborative Training und Development Environments oder Model & Data Repositories ins Spiel. Ein neues, sehr spannendes Umfeld, welches in Anlehnung an DevOps auch mit dem Begriff MLOps bezeichnet wird.
Eine exemplarischere MLOps-Umgebung auf Basis von Git und IBM Infrastruktur (Abb. 2)
Natürlich spielt die Performance beziehungsweise Accuracy (Genauigkeit) des Modells auch weiterhin eine wichtige Rolle. In der Praxis gelten Modelle mit 70 % Accuracy allerdings bereits als gut und Modelle mit 80 % oder mehr als sehr gut. Also eher niedrige Werte, wenn man es gewohnt ist, regelbasierte Software nach Spezifikation zu implementieren. Aber genau hier liegt der Unterschied, denn KI-basierte Systeme lassen sich nicht durch eine einfache Spezifikation abbilden, sondern versuchen Muster in komplexen Daten zu erkennen und daraus Ergebnisse beziehungsweise Vorhersagen und deren Wahrscheinlichkeiten herzuleiten. 100 % Genauigkeit sind damit per Definition ausgeschlossen.
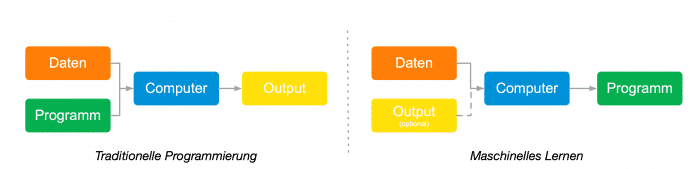
Die Gegenüberstellung verdeutlicht den konzeptionellen Unterschied zwischen der traditionellen Programmierung und dem Machine Learning (Abb. 3).
(Bild: open knowledge)
Die scheinbar fehlende Genauigkeit der KI-basierten Lösungen ist in vielen Fällen nicht weiter tragisch. In Szenarien, wie der automatischen Übersetzung von Texten, Logistikoptimierung oder Verkaufsprognosen geht es in der Praxis weniger darum, ein optimales Ergebnis zu erzielen, als vielmehr eine generelle Verbesserung herbeizuführen. „Alles ist besser als nichts“ könnte das passende Motto dazu lauten. Ein Modell in den eben genannten Anwendungsfeldern gilt entsprechend immer dann als hinreichend gut, wenn der Nutzen die Kosten übersteigt.
Anders sieht es dagegen bei Anwendungsfeldern aus, in denen fehlerhafte Vorhersagen – also die fehlenden 10 bis 30 Prozent – fatale Auswirkungen haben könnten. Typische Beispiele sind Qualitätssicherung in der Produktion kritischer Bauteile, medizinische Vorhersagen, autonomes Fahren oder gar KI-gestützte Waffensysteme. Hier gilt es zwingend, parallel zu der KI, immer auch den Menschen mit einzubeziehen und so ggf. die Vorhersage der KI zu korrigieren, bevor es auf ihrer Basis zu einer Aktion kommt.
Von Menschen und Maschinen
Der Mensch spielt im Umfeld von KI an mehreren Stellen eine wichtige Rolle. Zum einen ist er Nutznießer aber gegebenenfalls auch Opfer der Entscheidungen beziehungsweise Vorhersage einer KI. Egal ob personalisierte Empfehlung einer Web-Plattform, die Einstufung innerhalb eines Scoring-Systems, wie Banken und Versicherungen es gerne anwenden, oder aber bei einem KI-gestützten Recruiting-Prozess. Am Ende steht immer der Mensch. Das ist nicht weiter kritisch, solange der Mensch Alternativen hat, auf die er zurückgreifen kann. Kritisch wird es immer dann, wenn eben diese Alternativen nicht gegeben sind.
Zu den populären Negativbeispiele sind gehören das amerikanische Gesundheitssystem, welches mittels KI optimiert werden sollte und dabei Menschen afroamerikanischer Herkunft in der Vergabe von Gesundheitsmitteln nachweislich benachteiligt hat (siehe Studie Health Care AI Systems Are Biased in Journal of the American Medical Association) oder der Versuch von Amazon ein KI-gestütztes Recruiting durchzuführen, das am Ende Frauen diskriminiert hat und daher recht schnell wieder eingestellt wurde.
Der Mensch ist aber nicht nur Anwender der KI, sondern auch deren Gestalter und somit gleichzeitig auch für die Qualität des Modells und der zum Training verwendeten Daten, sowie die Überwachung des laufenden KI-Systems und dessen Adaption an eine sich ständig verändernde Umwelt verantwortlich. Eine Studie der Stanford University aus dem Jahr 2018 zeigt in diesem Zusammenhang, wie essenziell es für ein erfolgreiches ML-Modell ist, den Menschen dauerhaft in der Loop zu halten.
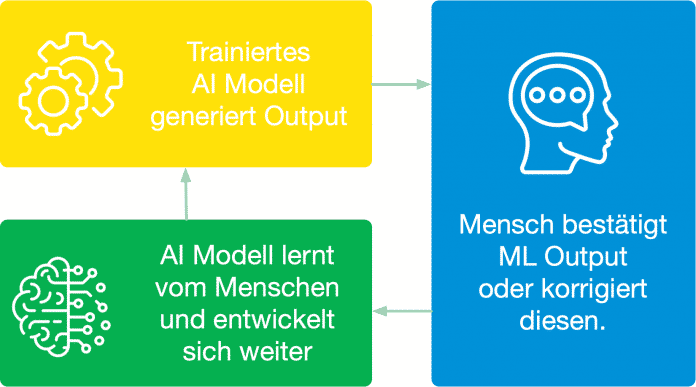
HITL (Human-in-the-Loop), so das zugehörige Akronym. HITL sieht vor, dass Menschen die Entscheidungen von Maschinen beziehungsweise deren Auswirkungen auf einzelne Personen oder Personengruppen überwachen und gegebenenfalls korrigierend eingreifen. Stehen dabei die Interessen verschiedener Personengruppen im Konflikt, so wird dieses durch den menschlichen „Controller“ ebenfalls berücksichtigt (siehe Abb. 4).
Human-in-the-Loop: Der Mensch als Controller (Abb. 4)
(Bild: open knowledge)
Auch der Ruf nach staatlicher Kontrolle der KI-Systeme wird immer lauter. So wundert es nicht, dass es zurzeit auf unterschiedlichsten Ebenen Bestrebungen gibt, KI-Modelle in Bezug auf potenziell negative Auswirkungen für einzelne Personen oder Personengruppen zu kategorisieren und je nach Kategorie mit Auflagen zu versehen.
In der einfachsten Variante könnte ein Anbieter eines KI-Systems dazu verpflichtet werden, das zur Vorhersage verwendete Verfahren zu nennen. Das würde dem Anwender dabei helfen, die Qualität der Vorhersage besser bewerten zu können. Sinnvolle Szenarien wären persönliche Empfehlungen in Webshops oder Übersetzungen. In beiden Fällen ist der persönliche Schaden einer schlechten KI nicht weiter kritisch. Trotzdem möchte man gegebenenfalls wissen, „wem“ man die Vorhersage zu verdanken hat.
Ist die Auswirkung der KI-Entscheidung auf einzelne Personen oder Personengruppen spürbarer, könnte zusätzlich gefordert werden, die für die Vorhersage verantwortlichen Faktoren offenzulegen. Das würde die Entscheidung der KI nachvollziehbar machen und einem Anwender beispielsweise zeigen, warum ein Kredit nicht genehmigt wurde oder aus welchem Grund die eigene Versicherungspolice teurer ist als die vom Nachbarn.
In den bisher genannten Beispielen hätte der Anwender der KI immer die Option, auf alternative Anbieter zu wechseln. Was aber, wenn es diese Möglichkeit, wie zum Beispiel im Falle einer KI-gestützen Mitarbeiterbewerbung, nicht gibt. Dann könnten Regularien vorsehen, dass der Mensch immer auch die Chance bekommen muss, das Ergebnis der KI zu verweigern und eine nicht KI-gestützte Variante zu wählen.
Natürlich muss in diesem Kontext auch überlegt werden, in welchen Szenarien KI-basierte Systeme generell nicht zum Einsatz kommen dürfen. Diskussionen dazu gibt es viele. Insbesondere immer dann, wenn die Entscheidung der KI dazu führen kann, dass einem Menschen erheblicher Schaden zugefügt wird. Ein extremes Beispiel wäre ein bewaffnetes Drohnensystem auf Basis von Gesichtserkennung zur Eliminierung von international gesuchten Terroristen.
Bei all den Betrachtungen gilt es zu bedenken, dass eine KI immer auf Basis von Wahrscheinlichkeiten arbeitet und somit niemals eine hundertprozentige Sicherheit bietet.
Zum Abschluss noch ein kurzer Blick darauf, wie eine Maschine das Thema „Mensch und Maschine“ interpretiert. Abbildung 5 zeigt einige von DALL-E 2 generierte Bilder für die Beschreibung „A realistic painting of an artificial intelligence thinking bout what it would be like being a human.“. Irgendwie menschlich, oder?
"von Menschen und Maschinen" aus Sicht einer Maschine (Abb. 5)
Mit dem neuen heise Developer Blog “von Menschen und Maschinen“ werde ich einen Großteil der in diesem Beitrag aufgeworfenen Themen und Aspekte aufgreifen und vertiefen.
Dazu werde ich sowohl praxisnahe Anwendungsszenarien skizzieren und deren ethische Aspekte diskutieren als auch aktuelle Entwicklungen im Bereich der ML-Modelle aufgreifen und einen Blick hinter deren Kulissen werfen. Natürlich werde ich aber auch Tools, Frameworks und Libraries für den ML-Entwickler vorstellen und immer wieder den MLOps-Prozess und seine Tücken beleuchten.
All das getreu dem Motto „Humans in the Loop“. Wer also Wunschthemen hat, die er oder sie gerne einmal besprochen haben möchte, ist herzlich dazu eingeladen, diese an mich heranzutragen. In diesem Sinne „stay connected!“.