Parallele Algorithmen der STL mit dem GCC-Compiler
Der GCC-Compiler unterstützt nun mein liebstes C++17-Feature: die parallelen Algorithmen der Standard Template Library (STL).
Der GCC-Compiler unterstützt nun mein liebstes C++17-Feature: die parallelen Algorithmen der Standard Template Library (STL). Das habe ich vor ein paar Tagen bemerkt und ich freue mich, einen Beitrag darüber schreiben zu können und meine Begeisterung zu teilen.

Im Gegensatz zum GCC- und Clang-Compiler unterstützt der Microsoft-Compiler die parallelen Algorithmen seit ihren Anfängen. Das ändert sich nun mit GCC 9. Ab dieser Compiler-Version lassen sich die parallelen Algorithmen verwenden. Bevor ich in meinem nächsten Artikel Performanzzahlen präsentiere, möchte ich über die parallelen Algorithmen der STL berichten und die dafür nötigen Informationen teilen.
Parallele Algorithmen der Standard Template Library
Die Standard Template Library besitzt mehr als 100 Algorithmen zum Suchen, Zählen und Manipulieren von Bereichen und deren Elementen. Mit C++17 erhalten 69 von ihnen neue Überladungen, und neue Algorithmen kommen hinzu. Die überladenen und neuen Algorithmen können mit einer sogenannten Execution Policy aufgerufen werden. Mit einer Execution Policy lässt sich festlegen, ob der Algorithmus sequentiell, parallel oder parallel mit Vektorisierung laufen soll. Um die Execution Policy zu verwenden, braucht es den Header <execution>.
Execution Policy
Der C++17-Standard definiert drei Execution Policies:
std::execution::sequenced_policystd::execution::parallel_policystd::execution::parallel_unsequenced_policy
Das entsprechende Policy-Tag gibt an, ob ein Programm sequentiell, parallel oder parallel mit Vektorisierung ausgeführt werden soll.
std::execution::seq: führt das Programm sequentiell ausstd::execution::par: führt das Programm parallel auf mehreren Threads ausstd::execution::par_unseq:führt das Programm parallel auf mehreren Threads aus und erlaubt das verschränkte Ausführen einzelner Schleifen. Diese Policy ist unter dem Namen SIMD [1] (Single Instruction Multiple Data) bekannt.
Das Verwenden der Execution Policies std::execution::par oder std::execution::par_unseq erlaubt es, den Algorithmus parallel oder parallel und vektorisiert auszuführen. Diese Policy ist aber nur ein Hinweis, den der Compiler nicht umsetzen muss.
Der folgende Codeschnipsel wendet alle Execution Policies an.
std::vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9};
// standard sequential sort
std::sort(v.begin(), v.end()); // (1)
// sequential execution
std::sort(std::execution::seq, v.begin(), v.end()); // (2)
// permitting parallel execution
std::sort(std::execution::par, v.begin(), v.end()); // (3)
// permitting parallel and vectorized execution
std::sort(std::execution::par_unseq, v.begin(), v.end()); // (4)
Wie das Beispiel zeigt, lässt sich jederzeit auch weiterhin die klassische Variante von std::sort (4) verwenden. Außerdem lässt sich in C++17 explizit angeben, ob die sequentielle (2), parallele (3) oder die parallele und vektorisierte (4) Version zum Einsatz kommen soll.
Parallele und vektorisierte Ausführung
Ob ein Algorithmus parallel und vektorisiert ausgeführt wird, hängt von vielen Faktoren ab; zum Beispiel davon, ob die CPU und das Betriebssystem SIMD-Instruktionen unterstützen. Außerdem hängt es vom Compiler und der Optimierungsstufe ab, die für die Übersetzung des Codes verwendet wurde.
Das folgende Beispiel zeigt eine einfache Schleife zum Füllen eines Vektors:
const int SIZE = 8;
int vec[] = {1, 2, 3, 4, 5, 6, 7, 8};
int res[] = {0, 0, 0, 0, 0, 0, 0, 0, 0};
int main( {
for (int i = 0; i < SIZE; ++i) {
res[i] = vec[i]+5;
}
}
Der Ausdruck res[i] = vec[i] + 5 ist hier die entscheidende Zeile. Dank des Compiler Explorers können wir uns die von clang 3.6 generierten Assembleranweisungen genauer ansehen.
- Ohne Optimierung
Hier sind die Assembleranweisungen. Jede Addition wird sequentiell durchgeführt.

- Mit maximaler Optimierung
Durch Verwenden der höchsten Optimierungsstufe -O3 kommen spezielle Register wie xmm0 zum Einsatz, die 128 Bit oder 4 int's aufnehmen können. Dieses spezielle Register bedeutet, dass die Addition parallel auf vier Elemente des Vektors erfolgt.

Das Überladen eines Algorithmus ohne Execution Policy und das Überladen eines Algorithmus mit einer sequenziellen Execution Policy std::execution::seq unterscheiden sich in einem Aspekt: Exceptions.
Exceptions
Wenn eine Exception während der Verwendung eines Algorithmus mit einer Execution Policy auftritt, wird std::terminate [2] aufgerufen. std::terminate ruft den installierten std::terminate_handler [3] auf. Die Konsequenz ist, dass standardmäßig std::abort [4] aufgerufen wird, was zu einem anormalen Programmabbruch führt. Die Behandlung von Exceptions ist der Unterschied zwischen dem Aufruf eines Algorithmus ohne Execution Policy und einem Algorithmus mit einer sequenziellen std::execution::seq Execution Policy. Der Aufruf des Algorithmus ohne Execution Policy propagiert die Exception. Dadurch lässt sich die Exception abfangen.
Mit C++17 erhielten 69 der STL-Algorithmen neue Überladungen, und neue Algorithmen wurden hinzugefügt.
Algorithmen
Hier sind die 69 Algorithmen mit parallelisierten Versionen.

Die neuen Algorithmen
Die neuen Algorithmen in C++17, die für die parallele Ausführung konzipiert sind, befinden sich im std Namensraum und benötigen die Headerdatei <numeric>.
std::exclusive_scan: Wendet von links ein binäres Callable auf das i-te (exklusive) Element des Bereichs an. Das linke Argument des Callables ist das vorherige Ergebnis. Speichert die Zwischenergebnisse.std::inclusive_scan: Wendet von links ein binäres Callable bis zum i-ten (inklusiven) Element des Bereichs an. Das linke Argument der Callable ist das vorherige Ergebnis. Speichert die Zwischenergebnisse.std::transform_exclusive_scan: Wendet zuerst eine unäres Callable auf den Bereich an und wendet anschließendstd::exclusive_scanan.std::transform_inclusive_scan: Wendet zuerst eine unäres Callable auf den Bereich an und wendet anschließendstd::inclusive_scananstd::reduce: Wendet ein binäres Callable auf den Bereich an.std::transform_reduce:Wendet zuerst ein unäres Callable auf einen oder einen binäres Callable auf zwei Bereiche an und dannstd::reduceauf den resultierenden Bereich.
Ein Callable ist eine Entität, die sich aufrufen lässt. Prominente Beispiele für Callables sind Funktion, Funktionsobjekte oder Lambda-Ausdrücke.
Zugegebenermaßen ist diese Beschreibung nicht leicht zu verdauen, aber wer std::accumulate und std::partial_sum bereits kennt, dem sollten die reduce- und scan-Varianten vertraut sein. std::reduce ist das parallele Pendant zu std::accumulate und scan das parallele Pendant zu partial_sum. Die parallele Ausführung ist der Grund dafür, dass std::reduce einen assoziativen und kommutativen Callable benötigt. Die entsprechende Aussage gilt für die scan-Varianten im Gegensatz zu den partial_sum-Varianten. Wer die vollständigen Details nachlesen möchte, sollte cppreferenc.com/algorithm [5] besuchen.
Warum brauchen wir std::reduce für die parallele Ausführung, wenn wir doch bereits std::accumulate besitzen? Der Grund ist einfach: std::accumulate verarbeitet seine Elemente in einer Reihenfolge, die nicht parallelisiert werden kann.
std::accumulateversusstd::reduce
Während std::accumulate seine Elemente von links nach rechts abarbeitet, wendet std::reduce keine definierte Reihenfolge an. Lass mich mit einem kleinen Codeschnipsel beginnen, der std::accumulate und std::reduce verwendet. Der Callable ist die Lambda-Funktion [](int a, int b){ return a * b; }.
std::vector<int> v{1, 2, 3, 4};
std::accumulate(v.begin(), v.end(), 1, [](int a, int b){ return a * b; });
std::reduce(std::execution::par, v.begin(), v.end(), 1 , [](int a, int b){ return a * b; });
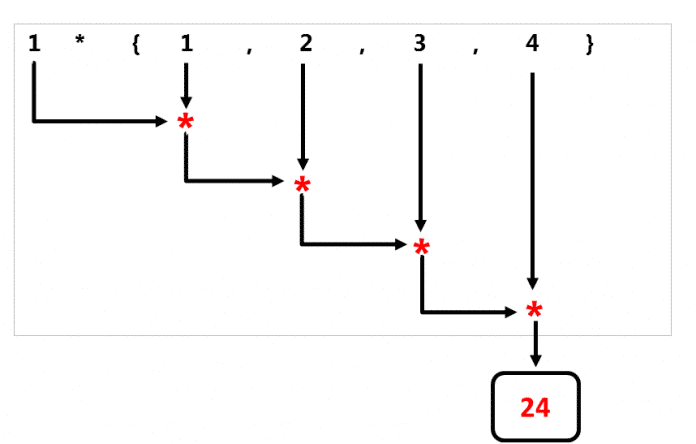
Die beiden folgenden Diagramme zeigen die unterschiedlichen Verarbeitungsstrategien von std::accumulate und std::reduce.
-
std::accumulatebeginnt links und wendet nacheinander den binären Operator an.
- Im Gegensatz dazu wendet
std::reduceden binären Operator auf eine nichtdeterministische Weise an.
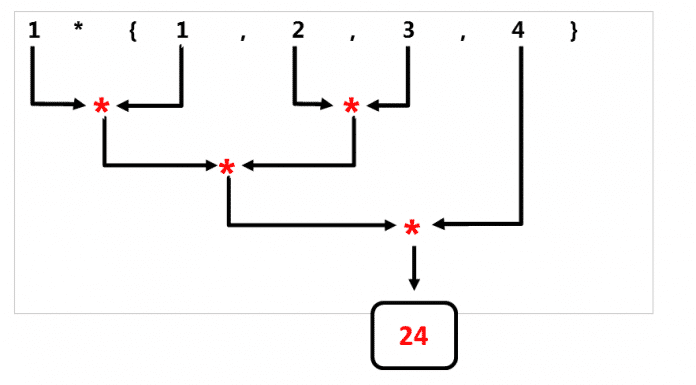
Die Assoziativität des Callables erlaubt es dem std::reduce Algorithmus, den Reduktionsschritt auf beliebige benachbarte Paare von Elementen zu anzuwenden. Dank der Kommutativität können die Zwischenergebnisse in beliebiger Reihenfolge berechnet werden.
Wie geht's weiter?
Wie eingangs versprochen, wird mein nächster Beitrag die parallelen Algorithmen der STL verwenden und liefert Performanzzahlen für den Microsoft- und den GCC-Compiler.
C++ Seminare

In den nächsten Monaten biete ich die folgenden Seminare an. Falls es die Covid-19 Situation zulässt, werde ich die Seminare nach Rücksprache als Präsenzseminare durchführen.
- C++20 [6]: 10.08.2021 - 12.08.2021 (Termingarantie, Online)
- Embedded Programmierung mit modernem C++ [7]: 21.09.2021 - 23.09.2021
- Clean Code: Best Practices für modernes C++ [8]: 14.12.2021 - 16.12.2021
- Concurrency mit modernem C++ [9]: 08.02.2022 - 09.02.2022
- Design Pattern und Architekturpattern mit C+ [10]+: 05.04.2022 - 07.04.2022
( [11])
URL dieses Artikels:
https://www.heise.de/-6140991
Links in diesem Artikel:
[1] https://en.wikipedia.org/wiki/SIMD
[2] https://en.cppreference.com/w/cpp/error/terminate
[3] https://en.cppreference.com/w/cpp/error/terminate_handler
[4] https://en.cppreference.com/w/cpp/utility/program/abort
[5] https://en.cppreference.com/w/cpp/algorithm
[6] https://www.modernescpp.de/index.php/c/2-c/32-c-20
[7] https://www.modernescpp.de/index.php/c/2-c/33-embedded-programmierung-mit-modernem-c20210421085111
[8] https://www.modernescpp.de/index.php/c/2-c/34-clean-code-best-practices-fuer-modernes-c
[9] https://www.modernescpp.de/index.php/c/2-c/35-concurrency-mit-modernem-c
[10] https://www.modernescpp.de/index.php/c/2-c/36-design-pattern-und-architekturpattern-mit-c
[11] mailto:rainer@grimm-jaud.de
Copyright © 2021 Heise Medien