"The Regular Expression"-Bibliothek
Wann bietet es sich an, reguläre Ausdrücke zu verwenden? Ein paar typische Anwendungsfälle dokumentieren das.
Mein ursprünglicher Plan war es, über die Regeln der C++ Core Guidelines zu der regex- und chrono-Bibliothek zu schreiben, aber abgesehen von der Überschrift gibt es keinen Inhalt. Heute werde ich die Lücke schließen und über die regex-Bibliothek schreiben.
Da ich bereits einige Artikel zur Zeitbibliothek [1] geschrieben habe, werde ich diese ignorieren. Jetzt geht es los mit meinen Regeln zu regulären Ausdrücken.
Verwende nur reguläre Ausdrücke, wenn es notwendig ist
Reguläre Ausdrücke sind eine mächtige aber auch teure und komplizierte Maschinerie, um mit Text zu arbeiten. Wenn das Interface eines std::string oder ein Algorithmus der Standard Template Library den Job erledigen kann, ziehe ihn vor.
Wann sollst du reguläre Ausdrücke verwenden? Hier sind typische Anwendungsfälle:
Typische Anwendungsfälle für reguläre Ausdrücke
- Entspricht der Text dem Zeichenmuster: std::regex_match
- Suche ein Zeichenmuster in einem Text: std::regex_search
- Ersetze ein Zeichenmuster in einem Text: std::regex_replace
- Iteriere über alle Zeichenmuster in einem Text: std::regex_iterator und std::regex_token_iterator
Nur zur Klarstellung: Die Operationen wirken auf Zeichenmustern und nicht auf Text.
Zuerst einmal solltest du Raw Strings einsetzen, wenn du reguläre Ausdrücke definierst.
Verwende Raw Strings für reguläre Ausdrücke
Der Einfachheit halber werde ich die vorherige Regel brechen. Der reguläre Ausdruck für den Text C++ ist ziemlich hässlich: C\\+\\+. Du musst zwei Backslashes für jedes "+"-Zeichen verwenden. Den ersten Backslash, da das "+"-Zeichen ein spezielles Zeichen in einem regulären Ausdruck ist. Den zweiten, da der Backslash ein besonderes Zeichen in einem String ist. Daher maskiert der eine Backslash ein "+"-Zeichen, der andere Backslash maskiert den Backslash.
Das folgende Beispiel mag dich vielleicht noch nicht überzeugen:
std::string regExpr("C\\+\\+");
std::string regExprRaw(R"(C\+\+)");
Beide Strings stehen für reguläre Ausdrücke, die dem Text C++ entsprechen. Insbesondere der Raw String R"(C\+\+) ist ziemlich hässlich zu lesen. R"(Raw String)" begrenzt den Raw String. Nebenbei gesagt, reguläre Ausdrücke und Pfadnamen und Windows ("C:\temp\newFile.txt") sind typische Kandidaten für Raw Strings.
Stelle dir vor, du möchtest eine Fließkommazahl in einem Text finden, die du durch folgende Sequenz von Zeichen identifizierst: Tabulatur Fließkommazahl Tabulator \\DELIMITER. Hier ist ein konkretes Beispiel für dieses Pattern: "\t5.5\t\\DELIMITER".
Das folgende Programm wendet einen regulären Ausdruck an, der in einem String und in einem Raw String enkodiert ist, um das Zeichenmuster zu finden:
// regexSearchFloatingPoint.cpp
#include <regex>
#include <iostream>
#include <string>
int main(){
std::cout << std::endl;
std::string text = "A text with floating pointer number \t5.5\t\\DELIMITER and more text.";
std::cout << text << std::endl;
std::cout << std::endl;
std::regex rgx("\\t[0-9]+\\.[0-9]+\\t\\\\DELIMITER"); // (1)
std::regex rgxRaw(R"(\t[0-9]+\.[0-9]+\t\\DELIMITER)"); // (2)
if (std::regex_search(text, rgx)) std::cout << "found with rgx" << std::endl;
if (std::regex_search(text, rgxRaw)) std::cout << "found with rgxRaw" << std::endl;
std::cout << std::endl;
}
Der reguläre Ausdruck rgx("\\t[0-9]+\\.[0-9]+\\t\\\\DELIMITER") ist schwer zu lesen. Um n aufeinanderfolgende "\"-Symbole (Zeile 1) zu finden, musst du 2 * n "\"-Symbole verwenden. Im Gegensatz erlaubt die Verwendung eines Raw String, den regulären Ausdruck genau so zu definieren wie das Zeichenmuster, das du suchst: rgxRaw(R"(\t[0-9]+\.[0-9]+\t\\DELIMITER)") (Zeile 2). Der Teilausdruck [0-9]+\.[0-9]+ steht für eine Fließkommazahl. Zumindest eine Zahl ([0-9]+), gefolgt von einem Punkt (\.), gefolgt von mindestens einer Zahl ([0-9]+).
Der Vollständigkeit halber ist hier die Ausgabe des Programms:

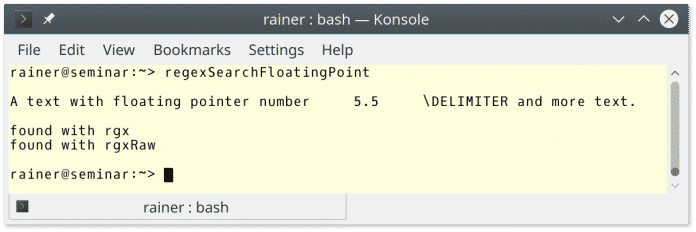
Ehrlich gesagt, war das Beispiel recht einfach.
Für eine tiefere Analyse verwende match_result
Die Anwendung von regulären Ausdrücken besteht typischerweise aus drei Schritten. Dies gilt für std::regex_search und std::regex_match.
- Erkläre den regulären Ausdruck.
- Speichere das Ergebnis der Suche.
- Analysiere das Ergebnis.
Was heißt das? Dieses Mal möchte ich die erste E-Mail Adresse in einem Text finden. Der folgende reguläre Ausdruck (RFC 5322 Official Standard) findet nicht alle E-Mail Adressen, da diese sehr irregulär sind.
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[az0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x2\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")
@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
Der Lesbarkeit wegen, habe ich einen Zeilenumbruch in den regulären Ausdruck eingefügt. Die erste Zeile entspricht dem lokalen Anteil der E-Mail Adresse und die zweite Zeile dem Domainanteil der E-Mail-Adresse. Mein Programm wird einen einfachen regulären Ausdruck verwenden, um die E-Mail-Adresse zu finden. Der reguläre Ausdruck ist nicht perfekt, tut aber seinen Job. Zusätzlich möchte ich den lokalen Anteil und den Domänenanteil der E-Mail-Adresse finden.
Hier geht es los:
// regexSearchEmail.cpp
#include <regex>
#include <iostream>
#include <string>
int main(){
std::cout << std::endl;
std::string emailText = "A text with an email address: rainer@grimm-jaud.de.";
// (1)
std::string regExprStr(R"(([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4}))");
std::regex rgx(regExprStr);
// (2)
std::smatch smatch;
if (std::regex_search(emailText, smatch, rgx)){
// (3)
std::cout << "Text: " << emailText << std::endl;
std::cout << std::endl;
std::cout << "Before the email address: " << smatch.prefix() << std::endl;
std::cout << "After the email address: " << smatch.suffix() << std::endl;
std::cout << std::endl;
std::cout << "Length of email adress: " << smatch.length() << std::endl;
std::cout << std::endl;
std::cout << "Email address: " << smatch[0] << std::endl; // (6)
std::cout << "Local part: " << smatch[1] << std::endl; // (4)
std::cout << "Domain name: " << smatch[2] << std::endl; // (5)
}
std::cout << std::endl;
}
Die Zeilen 1, 2 und 3 stehen für die drei typischen Schritte für reguläre Ausdrücke. Der reguläre Ausdruck in Zeile 1 benötigt ein paar Worte.
Hier ist er: ([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4})
- [\w.%+-]+: Zumindest einer der folgenden Buchstaben: "\w", ".", "%", "+", oder "-". "\w" steht für ein Wortzeichen.
- [\w.-]+\.[a-zA-Z]{2,4}: Zumindest eines von "\w", ".", "-" Zeichen, gefolgt von einem Punkt ".", gefolgt von 2 bis 4 Buchstaben von den Zeichen a-z oder A-Z.
- (...)@(...): Die runden Klammern stehen für eine Erfassungsgruppe. Sie erlauben es, Teilausdrücke in einem Suchergebnis auszuzeichnen. Die erste Erfassungsgruppe (Zeile 4) ist der lokale Anteil der E-Mail-Adresse. Die zweite Erfassungsgruppe (Zeil 5) ist der Domänenanteil der E-Mail-Adresse. Auf den ganzen Treffer lässt sich mit der 0-ten Erfassungsgruppe zugreifen (Zeile 6).
Die Ausgabe des Programms zeigt die genaue Analyse:
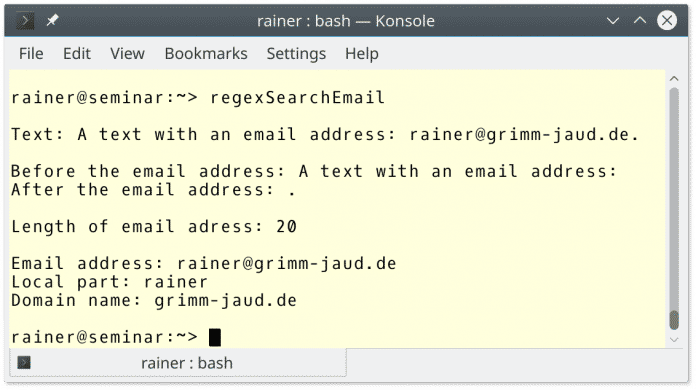
Wie geht's weiter?
Ich bin noch nicht fertig. Es gibt noch mehr über reguläre Ausdrücke in meinen nächsten Artikel zu schreiben. Ich werde über die verschiedenen Arten von Text schreiben und darüber, wie es sich leicht über alle Treffer iterieren lässt.
( [2])
URL dieses Artikels:
https://www.heise.de/-4469602
Links in diesem Artikel:
[1] https://www.grimm-jaud.de/index.php/blog/tag/time
[2] mailto:rainer@grimm-jaud.de
Copyright © 2019 Heise Medien