

Toolbox: Texterkennung mit Tesseract OCR
Das freie Texterkennungsprogramm Tesseract OCR verwandelt Bild in Text und glänzt mit hoher Genauigkeit. In der aktuellen Version kann die Texterkennung auch mit Spalten-Layouts umgehen und ist damit eine ausgewachsene OCR-Engine für Linux, Mac OS X und Windows.
- David Wolski

Jede Texterkennung muss auch bei unklaren Schriftbildern und verschiedenen Fonts in einem Dokument mit einer guten Erkennungsrate aufwarten können. Denn auch bei einer Fehlerrate von nur wenigen Prozent summiert sich bei tausenden Zeichen schnell eine erhebliche Menge an falsch erkannten Zeichen. Moderne OCR-Programme können bei lateinischer Schrift eine Erkennungsrate von bis zu 98 Prozent vorweisen. Um diese Präzision zu erreichen, versucht OCR (Optical Character Recognition) die kognitiven Fähigkeiten des menschlichen Auges und des Gehirns nachzubilden: Der erste Schritt ist die Aufteilung der gesamten Textseite in Layout-Elemente. Zeilen werden in Wörter und schließlich in Buchstaben zerlegt. Auf der Ebene einzelner Buchstaben geht es um Mustererkennung anhand bekannter Merkmale. Eine zweite Analyse findet dann auf Wortebene statt, um Muster nach einem Wörterbuch abzugleichen und bei Bedarf zu korrigieren. Erst mit der Kombination dieser verschiedenen Methoden und durch Kontextanalyse von Buchstaben können auch unklare Schriftbilder beispielsweise in älteren Zeitungen erkannt werden.

(Bild: Ray Smith, Google Inc)
Mehr als zwei Jahrzehnte Entwicklungszeit
In den Algorithmen guter OCR-Programme mit hohen Erkennungsraten stecken mehrere Jahre oder sogar Jahrzehnte Entwicklungszeit. Umso überraschender ist, dass eine der besten OCR-Engines ein Open-Source-Projekt ist: Tesseract OCR hat bereits in frühen Versionen bei repräsentativen Testreihen eine Genauigkeit von 97,69 Prozent erreicht. Die Software liegt heute in Version 3.0 vor, die auch komplexe Schriften wie Chinesisch unterstützt und über eine Layout-Analyse mit Spalten-Erkennung verfügt.
Tesseract OCR (4 Bilder)
Setup
Tesseract OCR hat bereits einen weiten Weg zurück gelegt: Zwischen 1985 und 1995 wurde es von Hewlett-Packard entwickelt, doch es gab nie eine kommerzielle Veröffentlichung. Seit 2005 ist Tesseract OCR Open Source und steht unter der Apache License 2.0. Google pflegt das Projekt seit 2006 und beschäftigt zudem mit Ray Smith einen der ursprünglichen Programmentwickler und OCR-Experten. Unter anderem nutzt Google das Programm für eigene Projekte, beispielsweise für Google Books.
Der Programmcode ist bei Google Code untergekommen und legte dort in den letzten fünf Jahren immerhin zwei große Versionssprünge hin. Obwohl Open Source, findet die Entwicklung des Programms in einem geschlossenen Team statt. Details zu geplanten Verbesserungen, neuen Funktionen und der gegenwärtigen Arbeit stehen nicht öffentlich zur Verfügung. Fertig gestellte Versionen bringen jedoch eine ausreichende Dokumentation und eine Liste der Neuerungen mit, sodass sich Tesseract OCR in andere Projekte als Texterkennungs-Engine einbinden lässt.
Texterkennung pur

Bei Tesseract OCR handelt es sich um ein reines Kommandozeilentool ohne grafische Oberfläche. Zwar gibt es verschiedene Frontends, doch die Bedienung von Tesseract OCR auf der Kommandozeile ist unkompliziert. In aktuellen Linux-Distributionen lässt sich Tesseract OCR 3.0 in der Regel einfach aus den Standard-Paketquellen mit dem jeweiligen Paketmanager installieren. Aktuell ist Version 3.0 von Tesseract OCR. Erst diese enthält fortgeschrittene Funktionen wie Layout-Analyse. In Ubuntu 12.04 installiert man die Version inklusive der benötigten Sprachdateien für englischen und deutschen Text beispielsweise mit dem folgenden Befehl:
sudo apt-get install tesseract-ocr tesseract-ocr-deu tesseract-ocr-eng
Auch Fedora bietet die aktuelle Version von Tesseract OCR in den Paketquellen an, während für Debian 6 (Squeeze) bislang nur Version 2.04 vorliegt; Debian 7.0 (Wheezy) enthält ereits eine neue Version. Für andere Distributionen lässt sich Tesseract OCR gegebenenfalls aus dem Quellcode kompilieren.
Windows-Anwender finden ein Installationspaket mit Setup-Programm im Download-Verzeichnis der Projekt-Webseite. Zusätzlich müssen stets die Sprachdateien für die gewünschte Erkennungssprache installiert werden, die dort ebenfalls bereit stehen. Die gewählte Datei muss dabei zur verwendeten Tesseract-Version passen. Bei der Installation unter Windows fragt das Setup-Programm allerdings nach, ob weitere Sprachen neben Englisch benötigt werden und installiert die Sprachdateien dann gleich mit. Um eine Sprache nachträglich hinzuzufügen, werden die neuen Sprachdateien unter Windows einfach in den Unterordner „tessdata“ im Programmverzeichnis von Tesseract OCR kopiert.
Tesseract OCR kommt mit wenig Kommandozeilenoptionen aus und funktioniert nach dem folgenden Schema:
tesseract [Bilddatei] [Ausgabedatei] -l [Sprache]
Die zu erkennende Bilddatei sollte als unkomprimiertes TIFF vorliegen, denn Tesseract OCR ist beim Bildformat sehr wählerisch. Version 3.0 der Software bindet inzwischen die Programmbibliothek Leptonica ein und kann so auch mit anderen Bildformaten wie PNG und JPG umgehen. Für optimale Ergebnisse sollte die Bildauflösung etwa 300 dpi betragen.
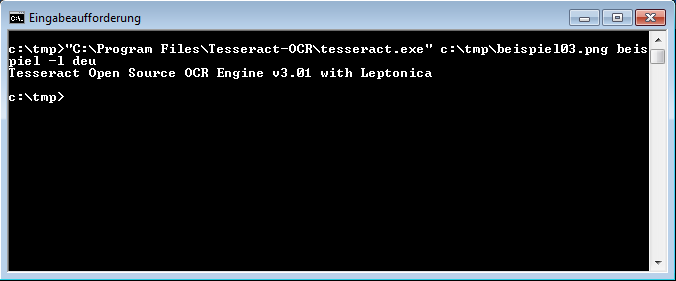
Um Tesseract OCR beispielsweise die Datei beispiel.tiff vorzusetzen und dabei die Erkennung für deutschsprachige Texte zu aktivieren, dient folgendes Kommando:
tesseract beispiel.tiff beispiel -l deu
Die Dateiendung der resultierenden Text-Datei beispiel.txt ergänzt Tesseract OCR automatisch.
Gimagereader: Freundliches Frontend
Während die Befehlszeile für Linux-affine Anwender kein Hindernis sein dürfte, ist diese Arbeitsweise für manche Benutzer ein Graus. Frontends für Tesseract OCR sorgen für mehr Komfort, bieten eine Oberfläche für die wichtigsten Funktionen und präsentieren auch gleich die Ergebnisse der Texterkennung.

Für Linux besteht kein Mangel an Frontends; der überzeugendste Vertreter dieser Klasse ist Gimagereader 0.9, das eine mit Python und PyGTK erstellte Oberfläche bietet. Das Programm ist für Linux und Windows verfügbar und liegt als fertiges DEB- und RPM-Paket vor sowie für Windows als EXE-Datei mit Installer. Gimagereader ergänzt die Fähigkeiten von Tesseract OCR um ein Vorschau- und Ausgabefenster sowie eine Rechtschreibprüfung, die von OpenOffice geerbt wurde. Die Rechtschreibprüfung für die ausgewählte Sprache erleichtert die nachträgliche Korrektur von Fehlern ungemein. Beim Einlesen von PDFs kommt Gimagereader auch mit mehrseitigen Dokumenten zurecht und schickt Seite für Seite an die Texterkennung. Ein umständliches Auseinandernehmen und Konvertieren in TIFF entfällt. Bei Textseiten mit komplexem Layout wählt man den gewünschten Bereich mit der Maus. Gimagereader ist damit der ideale Begleiter für Tesseract OCR ab Version 3.0.
Fazit
Die Erkennungsrate und Verarbeitungsgeschwindigkeit von Tesseract OCR erreichen selbst viele kommerziellen und proprietären Programmen nicht. Obwohl das Open-Source-Programm als Kommandozeilentool und in Skripten seine Aufgabe sehr gut erledigt, ist es wegen fehlender grafischer Oberfläche und magerer Dokumentation ein Geheimtipp geblieben. Gerade unter Windows-Anwendern dürfte die Bereitschaft traditionell gering sein, Texterkennung in der Eingabeaufforderung zu erledigen. Ein Frontend wie Gimagereader behebt diesen Mangel sowohl unter Linux als auch Windows und erschließt die Vorzüge und Fähigkeiten von Tesseract OCR erst so richtig. (lmd) (lmd)
