C++20: Die Vorteile von Modulen
Module sind eines der vier großen Features von C++20 und versprechen viel: unter anderem die Compilezeit zu verkürzen und Makros zu isolieren.
Module sind neben Concepts, Ranges und Coroutinen eines der vier großen Features von C++20 und sie versprechen viel: Sie sollen die Compilezeit verkürzen, Makros isolieren, Header-Dateien und hässliche Workarounds überflüssig werden lassen.
Warum benötigen wir Module? Zur Beantwortung dieser Frage möchte ich gerne ein paar Schritte zurücktreten und vereinfachend darstellen, wie eine ausführbare Datei in C++ erzeugt wird.
Eine einfache ausführbare Datei
Klar, jede Einführung beginnt mit "Hello World":
// helloWorld.cpp
#include <iostream>
int main() {
std::cout << "Hello World" << std::endl;
}


Die ausführbare Datei helloWorld ist um den Faktor 130 größer als die Quellcodedatei helloWorld.cpp.
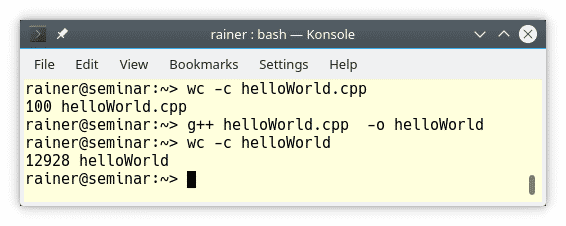
Die Zahlen 100 und 12928 in dem Screenshot stehen für die Anzahl der Bytes.
Es ist natürlich sinnvoll zu wissen, was unter der Decke passiert.
Der klassische Erstellungsprozess
Der Erstellungsprozess lastet auf drei Schultern: Präprozessor, Compiler und Linker.
Präprozessor
Der Präprozessor kümmert sich um Präprozessor-Direktiven wie #include und #define. Der Präprozessor ersetzt die #include-Direktiven mit den Header-Dateien und die Makros (#define) mit dem entsprechenden Text. Dank weiterer Direktiven wie #if, #else, #elif, #ifdef, #ifndef und #endif lassen sich Teile des Sourcecodes inkludieren oder exkludieren.
Diese einfache Textersetzung lässt sich mit dem Compiler-Flag -E beim GCC-/Clang- oder /E beim Windows-Compiler schön darstellen.
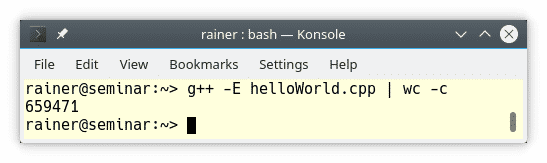
Der Präprozessor produziert tatsächlich eine Textdatei mit mehr als einer halben Million Bytes. Ich will hier nicht GCC tadeln, denn alle anderen Compiler sind ähnlich geschwätzig: Compiler Explorer [1].
Die Ausgabe des Präprozessors stellt die Eingabe für den Compiler dar.
Compiler
Die Kompilierung findet separat auf allen Dateien statt, die der Präprozessor erzeugt. Der Compiler parst den C++-Sourcecode und konvertiert ihn zu Assemblercode. Die dabei erzeugte Datei wird Objektdatei genannt. Sie enthält den kompilierten Code im Binärformat. Die Objektdatei kann Symbole referenzieren, die keine Definition besitzen. Die Objektdatei lässt sich in ein Archiv für die einfache Wiederverwendung packen. Diese Archive werden statische Bibliotheken genannt.
Die Objektdateien oder auch Übersetzungseinheiten, die der Compiler erzeugt, stellen die Eingabe für den Linker dar.
Linker
Der Linker kann eine ausführbare Datei oder auch eine statische oder geteilte Bibliothek (shared library) erzeugen. Es ist die Aufgabe des Linkers, die Referenzen zu undefinierten Symbolen aufzulösen. Die Symbole sind in den Objektdateien oder Bibliotheken definiert. Der typische Fehler in diesem Prozess ist es, dass die Symbole entweder gar nicht oder mehrfach definiert sind.
Diesen klassischen Erstellungsprozess aus drei Schritten hat C++ von C geerbt. Er funktioniert ausreichend gut, wenn es eine Übersetzungseinheit gibt. Wenn du aber mehr als eine Übersetzungseinheit besitzt, hat er viele Schwächen.
Schwächen des klassischen Erstellungsprozesses
Ohne einen Anspruch auf Vollständigkeit möchte ich ein paar Schwächen des klassischen Erstellungsprozesses vorstellen. Module überwinden diese Schwächen.
Wiederholte Ersetzung der Header-Dateien
Der Präprozessor ersetzt jede #include-Direktive mit der entsprechenden Header-Datei. Lass mich zur Verdeutlichung mein am Anfang des Artikels vorgestelltes helloWord.cpp-Programm ein wenig modifizieren. Ich habe es refaktorisiert und zwei Quelldateien (hello.cpp und world.cpp) hinzugefügt. Die Datei hello.cpp bietet die Funktion hello; die Datei word.cpp bietet die Funktion world an. Beide Quelldateien besitzen die entsprechenden Header-Dateien. Refaktorisierung bedeutet, dass sich das neue Programm helloWorld2.cpp wie das Programm helloWorld.cpp verhält. Lediglich die interne Struktur hat sich verändert. Hier sind die neuen Dateien:
hello.cppundhello.h
// hello.cpp
#include "hello.h"
void hello() {
std::cout << "hello ";
}
// hello.h
#include <iostream>
void hello();
world.cppundworld.h
// world.cpp
#include "world.h"
void world() {
std::cout << "world";
}
// world.h
#include <iostream>
void world();
helloWorld2.cpp
// helloWorld2.cpp
#include <iostream>
#include "hello.h"
#include "world.h"
int main() {
hello();
world();
std::cout << std::endl;
}
Das Erzeugen und Ausführen des Programms verhält sich erwartungsgemäß.
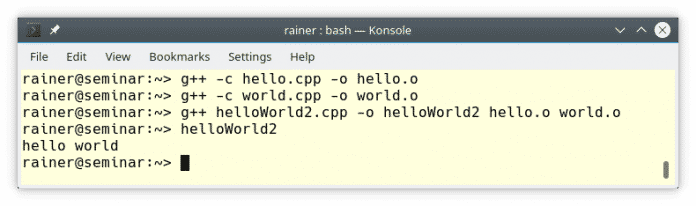
Es gibt aber eine Schwäche. Der Präprozessor vollzieht seine Ersetzung auf jeder Quelldatei. Das heißt, dass die Header-Datei <iostream> Mal in jeder Übersetzungseinheit inkludiert wird. Konsequenterweise wird jede Quelldatei damit auf mehr als eine halbe Million Bytes aufgeblasen.
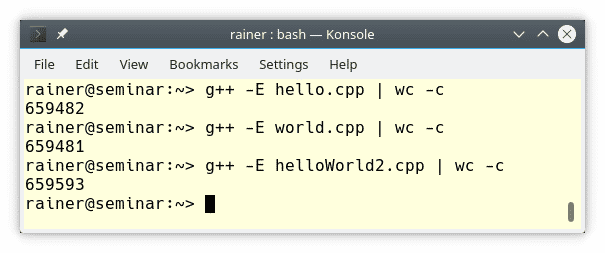
Dieser Aufwand ist eine Vergeudung von Übersetzungszeit.
Im Gegensatz dazu wird ein Modul nur einmal importiert. Dieser Prozess ist buchstäblich umsonst.
Isolation von Präprozessor-Makros
Falls es einen Konsens in der C++-Community gibt, dann diesen: Wir sollten die Präprozessor-Makros loswerden. Warum? Die Verwendung eines Makros stellt lediglich Textersetzung ohne C++-Semantik dar. Diese naive Ersetzung besitzt viele Schwächen: Zum Beispiel kann der Wert eines Makros davon abhängen, in welcher Reihenfolge du Makros inkludierst. Darüber hinaus können Makros mit bereits bestehenden oder Bezeichnern in deiner Applikation kollidieren.
Stelle dir vor, du hast die zwei Header-Dateien webcolor.h und productinfo.h:
// webcolors.h
#define RED 0xFF0000
// productinfo.h
#define RED 0
Wenn nun eine Quelldatei client.cpp beide Header-Dateien inkludiert, hängt der Wert vom Makro RED davon ab, in welcher Reihenfolge die Header-Dateien inkludiert wurden. Diese Abhängigkeit ist sehr fehleranfällig.
Im Gegensatz dazu stellt es keinen Unterschied dar, in welcher Reihenfolge Module importiert werden.
Mehrfache Definition von Symbolen
ODR steht für One Definition Rule und sagt im Falle einer Funktion aus:
- Eine Funktion kann nicht mehr als eine Definition pro Übersetzungseinheit besitzen.
- Eine Funktion kann nicht mehr als eine Definition pro Programm besitzen.
- Eine Inline-Funktion mit externer Bindung kann in mehr als einer Übersetzungseinheit definiert werden. Für jede Definition muss aber gelten, dass sie identisch ist.
Lass mich testen, ob sich mein Linker beschwert, wenn ich versuche ein Programm zu linken und dabei die One Definition Rule verletze. Das folgende Codebeispiel besitzt zwei Header-Dateien header.h und header2.h. Das main-Programm inkludiert zweimal die Header-Datei header.h und bricht damit die One Definition Rule, da die Funktion func dadurch doppelt inkludiert wird.
// header.h
void func() {}
// header2.h
#include "header.h"
// main.cpp
#include "header.h"
#include "header2.h"
int main() {}
Der Linker beschwert sich sofort über die doppelte Definition von func:
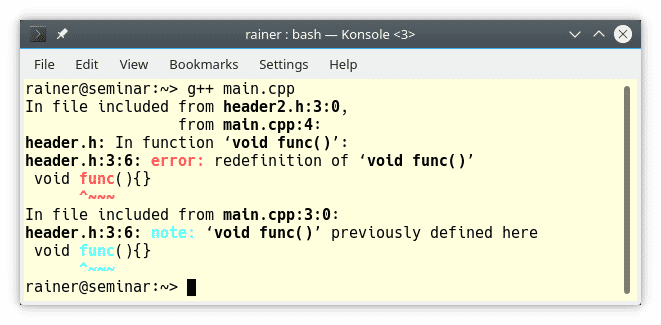
Sicherlich haben wir uns an hässliche Workarounds wie einen Inklude-Guard für Header-Dateien gewöhnt. Das Hinzufügen des Inklude-Guard FUNC_H zu der Header-Datei löst das Problem.
// header.h
#ifndef FUNC_H
#define FUNC_H
void func(){}
#endif
Im Gegensatz dazu sind identische Namen mit Modulen sehr unwahrscheinlich.
Bevor ich diesen Artikel abschließe, möchte ich noch die Vorteile von Modulen zusammenfassen.
Vorteile von Modulen
- Ein Modul wird nur einmal importiert. Dieser Prozess ist buchstäblich umsonst.
- Es stellt keinen Unterschied dar, in welcher Reihenfolge Module importiert werden.
- Identische Namen mit Modulen sind sehr unwahrscheinlich.
- Module erlauben es dir, die logische Struktur deines Codes auszudrücken. Du kannst explizit angeben, welche Namen exportiert werden sollen oder nicht. Zusätzlich lassen sich Module einfach in neue Module verpacken und damit dem Kunden als logisches Paket anbieten.
- Dank Modulen besteht nicht mehr die Notwendigkeit, den Sourcecode in das Interface und die Implementierung zu separieren.
Wie geht's weiter?
Module versprechen viel. In meinen nächsten Artikel werde ich mein erstes Modul definieren und einsetzen. ( [2])
URL dieses Artikels:
https://www.heise.de/-4717856
Links in diesem Artikel:
[1] https://godbolt.org/z/rtXGFQ
[2] mailto:rainer@grimm-jaud.de
Copyright © 2020 Heise Medien