Die vielfältigen Fähigkeiten von Git, Teil 1
(Bild:
Im normalen Entwickleralltag nutzt man die Standardmöglichkeiten von Git. Aber gelegentlich können selten genutzte Fähigkeiten das Leben angenehmer machen – wenn man sie denn kennt.
Wie ein roter Faden durchzieht "Vielfachheit" die Fähigkeiten, die der folgende Artikel vorstellt. Damit ist gemeint, dass von einem Repository aus "mehrere" verwalten werden können, wo im normalen Alltag meistens "eins" genügt. Beispiele gefällig? Man nutzt im Normalfall nur einen Worktree (Verzeichnisbaum) auf der eigenen Festplatte, ein Remote-Repository "origin" und einen Versionsgraphen im lokalen Repository.


Im Folgenden kommen Situationen zur Sprache, in denen mehrere Arbeitsverzeichnisse, mehrere Remotes und mehrere Versionsbäume nützlich sind.
Mehrere Arbeitsverzeichnisse
Eine solche Situation ist die Unterbrechung. Irgendetwas schiebt sich in der Dringlichkeit nach vorne. Was man gerade getan hat, muss unterbrochen werden und warten. Ein klassisches Beispiel aus der DevOps-Praxis: Man entwickelt an einem Feature-Branch. Plötzlich hängt etwas in der CI/CD-Pipeline und ist im master zu fixen, und zwar schnell.
Es gibt mehrere Möglichkeiten, mit einer solchen Situation umzugehen. Beispielsweise kann man git stash benutzen, um den Feature-Branch-Zustand zu sichern. Dann wechselt man vom Feature-Branch zum master und nimmt die Arbeit am CI/CD-Problem auf.
Eine andere, probate Möglichkeit bietet sich dadurch, dass ein Git-Respository auf der lokalen Festplatte mehr als ein Arbeitsverzeichnis ("Worktree") verwalten kann.
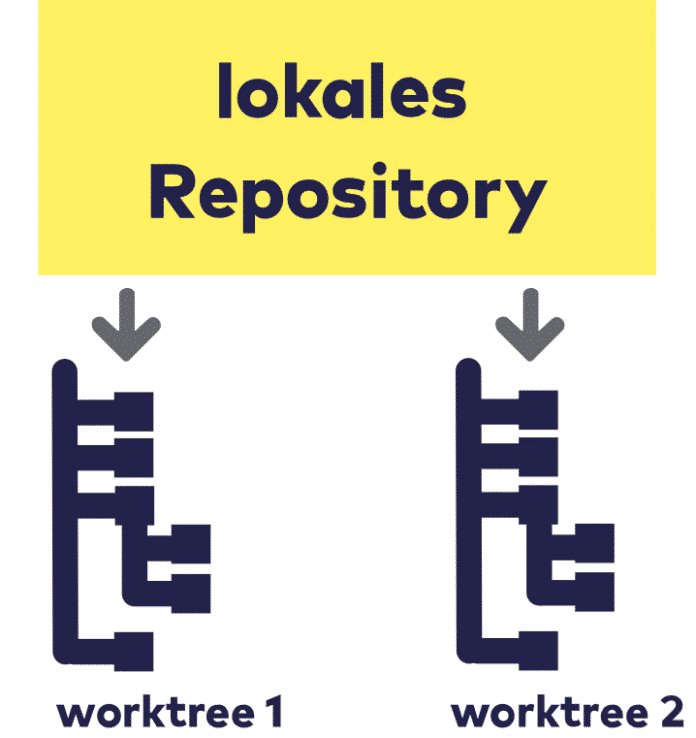
Man erzeugt so ein zweites Arbeitsverzeichnis aus der Wurzel des ersten heraus, zum Beispiel mit
git worktree add ../worktree2 master
Nun kann man mit einem schlichten cd ../worktree2 in das erzeugte Arbeitsverzeichnis wechseln, in dem master bereits ausgecheckt ist, und mit cd wieder zurück ins ursprüngliche mit dem Feature-Branch. Überhaupt ermöglichen multiple Arbeitsverzeichnisse bequeme und schnelle Kontextwechsel. Zwei IDE-Instanzen können parallel laufen, man braucht bei Bedarf nur zwischen den Fenstern zu wechseln.
In der geschilderten Beispielsituation, dass an der CI/CD-Pipeline etwas repariert werden muss, kann das sehr angenehm sein: Während der CI/CD-Job erst losläuft, hat man schon wieder die Arbeit am Feature-Branch aufgenommen.
Intern hat worktree2 in seinem Verwaltungsverzeichnis .git nur eine Art Verweis auf das eigentliche Repository. Dadurch stehen alle Commits, Branches, Remotes usw. in beiden gleichartig zur Verfügung. Man kann zum Beispiel in einem Arbeitsverzeichnis einen Commit zu einem Branch hinzufügen und ihn in einem zweiten Arbeitsverzeichnis in einen anderen Branch hineinmergen.
Den Index gibt es naturgemäß für jeden Worktree einzeln. So bleiben die verschiedenengit add-Befehle unabhängig voneinander. Übrigens wehrt sich Git dagegen, den selben Branch in zwei verschiedenen Arbeitsverzeichnissen auszuchecken.
Wer das Arbeiten mit parallelen Arbeitsverzeichnissen für sich entdeckt hat, mag vielleicht gleich beim Anlegen eines neuen Feature-Branches für diesen ein eigenes Arbeitsverzeichnis vorsehen. Dafür bietet git add worktreeeine ähnliche Funktionsweise -b new_branch wie git checkout. Man nutzt sie zum Beispiel wie folgt:
git fetch origin
git worktree add -b f_branch ../f_branch_worktree origin/master
Ein solches Arbeitsverzeichnis lässt sich wieder abräumen, zum Beispiel mit folgender Zeile:
git worktree remove ../f_branch_worktree
Die Arbeit mit mehreren Worktrees hat sich in der alltäglichen Praxis des Autors bewährt. Allerdings warnt die Dokumentation derzeit, dass das Feature von Git noch experimentell ist, und rät insbesondere davon ab, von Repositorys mit Submodulen mehrere Arbeitsverzeichnisse zu generieren.
Mehrere Remotes
Das Git-Repository auf der eigenen Festplatte kann mit mehreren "Remotes" kommunizieren, also fernen Git-Repositorys, wie sie normalerweise auf irgendwelchen Git-Servern liegen.
Mehrere Remotes können zum Beispiel nützlich sein, wenn man temporär mit einer Person zusammenarbeitet, die auf den offiziellen Git-Server keinen Zugriff hat. Dem Autor ist das mehrfach passiert, zuletzt mit einer Praktikantin. Einerseits wünschte das betreffende Projekt ihre Mitarbeit. Andererseits wollte das Unternehmen für die (kurzzeitige) Mitarbeit nicht den Aufwand treiben, der Praktikantin einen Account im Firmen-LDAP einzurichten. Am LDAP-Account hängt aber der Zugriff auf das offizielle Repo. Was nun? Bekommt man die Zusammenarbeit trotz der Rahmenbedingungen hin?
Das geht recht problemlos, indem man ein zweites, temporäres Remote-Repo anlegt, auf das beide zugreifen können.
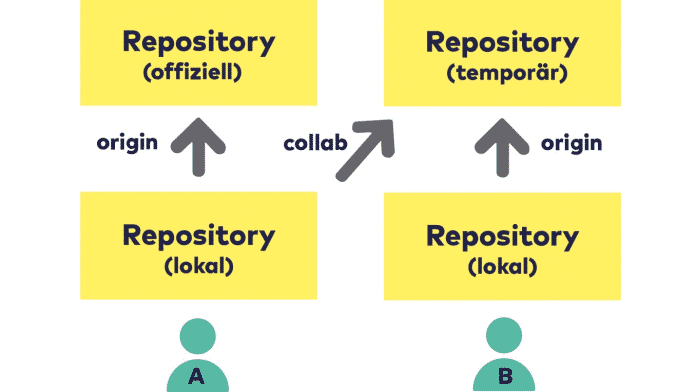
Schnell mal eben ein temporäres Remote
Es gibt verschiedene Möglichkeiten, wie man ein temporäres Repository aufsetzen kann, auf das zwei Personen A und B zugreifen können.
Besonders bequem hat man es, wenn es irgendwo einen Rechner gibt, auf dem Git installiert ist und auf den sowohl A als auch B per ssh zugreifen können. Das könnte ein ohnehin vorhandener Server sein. Auch eine kurzfristig in einer Cloud oder bei einem Provider angemietete virtuelle oder reale Maschine ist brauchbar. Selbst ein Winzling (ein Raspberry Pi oder Ähnliches) reicht dafür aus. Einer der beiden Arbeitsplatzrechner (der von A oder der von B) lässt sich ebenfalls prima einsetzen, Vertrauen zwischen A und B vorausgesetzt. Ein Docker-Container ist ebenfalls nutzbar.
Für einen temporären Repository-Server braucht man sich normalerweise keine Gedanken über Backups zu machen (was die Sache weiter vereinfacht), denn alle Informationen sind in den lokalen Repositorys ebenfalls vorhanden. Was wichtig ist, wandert über kurz oder lang ins offizielle Repository. Nach Ende der Kooperation kann das temporäre Repository einfach ohne Weiteres gelöscht werden.
Ist ein Server gefunden, ist das temporäre Respository mit wenigen Handgriffen eingerichtet. Im folgenden Beispiel haben beide auf dem Host server.example.org Zugriff auf den gemeinsam genutzten User user. Einer von beiden bringt die Sache in Gang:
ssh user@server.example.org mkdir -p collab-repo
ssh user@server.example.org cd collab-repo '&&' git init --bare
Anschließend richtet A für sein lokales Repository ein neue Verbindung zu einem "Remote" mit dem Namen collab ein:
git remote add collab user@server.example.org:collab-repo
und füllt das neue temporäre Repo:
git push collab master
B holt sich das Material mit dem Befehl:
git clone user@server.example.org:collab-repo
Nutzen A und B für den ssh-Zugriff auf server.example.org unterschiedliche Nutzer auser und buser, wird es geringfügig komplizierter. Gewöhnlich wird man eine gemeinsame Gruppe wie ggroup auf server.example.org finden oder erstellen, der auser und buser beide angehören.
Dann kann A das Repository wie folgt initialisieren:
ssh auser@server.example.org mkdir -p collab-repo
ssh auser@server.example.org chgrp ggroup collab-repo
ssh auser@server.example.org chmod g+sw collab-repo
ssh auser@server.example.org cd collab-repo '&&' git init --bare --share=group
Anschließend nutzt A auser@server.example.org:collab-repo und B buser@server.example.org:/home/auser/collab-repo für den Zugriff.
Eventuell ist es noch nötig, /home/auser mit chmod a+rx /home/auser für lesende Zugriffe zu öffnen. Das ermöglicht unter Umständen lesenden Zugriff durch andere User von server.example.org auch auf andere Dateien von auser. Will man das vermeiden, nutzt man alternativ ein neutrales Verzeichnis, z. B. /var/lib/collab-repo.
Arbeiten mit einem temporären Kollaborations-Repository
Wenn man ein temporäres Repository erst einmal hat, können die beiden beteiligten Personen bequem damit arbeiten.
B möchte zum Beispiel in einem Feature-Branch arbeiten:
git fetch
git checkout -b b_contrib origin/master
A kann neues Material aus dem offiziellen Repository jederzeit zur Verfügung stellen:
git fetch origin
git push collab origin/master:master
B nimmt das Material entgegen, wie bei Feature-Branches üblich:
git fetch origin
git rebase origin/master
B kann Material zur Verfügung stellen:
git push origin -u b_contrib
und A schaut es sich an:
git fetch collab
git checkout -b b_contrib collab/b_contrib
(Alternativ richtet sich A dafür einen eigenen Worktree ein.)
Soll das Material im offiziellen Repository als Feature-Branch auftauchen, kann A es dort zugänglich machen:
git push origin collab/b_contrib:b_contrib
Ross und beide Reiter nennen
Bei der vorgestellten Arbeitsweise bleiben die Commits von B erhalten. Sie finden sich später komplett mit Checkin-Kommentar, Zeitstempel und Autorenangabe "B" im offiziellen Repo. Dass sie durch Vermittlung von A dort gelandet sind, geht aus dem Repository-Inhalt nicht mehr hervor.
Das kann im Einzelfall erwünscht oder unerwünscht sein. Möglicherweise möchte man die Mitwirkung von A langfristig nachvollziehen können. Dafür bietet sich eine andere selten genutzte Vielfalt an, die Git bietet.
Jedes Versionsmanagementsystem kann selbstverständlich für jede Änderung die Frage beantworten: "Wer war das?" Git bietet dazu noch Mehrwert: Für jeden Commit werden nicht nur ein, sondern zwei Verantwortliche ins Repository eingetragen. Als "Author" wird in der Git-Terminologie die Person bezeichnet, die die Änderung inhaltlich entwickelte, als "Committer", wer sie ins Repository eintrug. Die beiden sind häufig identisch, müssen es aber nicht sein.

Einen neuen Commit kennzeichnet die eintragende Person als den inhaltlichen Beitrag von zum
Beispiel "A. U. Thor", mit einem Befehl wie
git commit --author='A U Thor <a.u.thor@example.org>'
Die entstehenden kompletten Angaben kann man sich mit git log anschauen, für den letzten Commit zum Beispiel mit
git log --pretty=fuller HEAD^..HEAD
Ein beispielhafter Output sieht wie folgt aus:
commit 84601e93dff652b0c8c2cbc1ec9e476366b06888 (HEAD -> git-vielfalt-artikel)
Author: A U Thor <a.u.thor@example.org>
AuthorDate: Mon Mar 4 14:23:18 2019 +0100
Commit: Andreas Krüger <andreas.krueger@innoq.com>
CommitDate: Mon Mar 4 14:23:18 2019 +0100
Sample commit with different author.
Es ist auch möglich, sich nachträglich als Committer einzutragen. Dazu erstellt derjenige einfach eine passende Kopie des Materials. In der oben beschriebenen Situation könnte A dazu folgende Befehle ausführen:
git checkout b_contrib
git rebase --no-ff origin/master
Repo mit einem Commit
Die bisher vorgeschlagene Methode der Zusammenarbeit von A und B basiert auf vollwertigen Repositorys, die jeweils die gesamte Vergangenheit des Projekts mit an Bord haben. Die historische Vollständigkeit ist manchmal nützlich, aber gelegentlich auch überflüssiger Ballast. Das Hauptthema der Artikelserie, "Vielzahl statt Einzahl", wird deshalb hier kurzfristig umgekehrt: Es soll im Folgenden von Repositorys die Rede sein, die statt der sonst üblichen Gesamthistorie nur einen Commit enthalten.
Eine (teilweise) Kopie eines Repositorys mit unvollständiger Historie nennt die Git-Dokumentation "shallow". Man erzeugt sie mit einer entsprechenden --depth-Option von git clone.

Als Beispiel soll eine Zusammenarbeit zwischen A und B auf dem Feature-Branch f_branch erfolgen. Den hat A bereits angelegt. Dann kann A ein Repository nur mit dem letzten Commit von f_branch erzeugen und an B weitergeben. Das geht notfalls sogar ohne eigenen Git-Server.
Angenommen, das lokale Repo von A liegt in $HOME/lokal-repo. Dann erzeugt A die unvollständige Kopie (in einem Verzeichnis, das vorzugsweise gerade nicht in einem Git-Worktree liegt) mit:
git clone --bare --single-branch -b f_branch --depth 1 file://$HOME/lokal-repo
Die erzeugte teilweise Repository-Kopie enthält zunächst noch einen Verweis auf das eigene lokale $HOME/lokal-repo. Den entfernt A:
git remote remove origin
Das präparierte Repository kann A nun in ein ZIP-Archiv oder Ähnliches einpacken und auf passendem Weg B zur Verfügung stellen. Das empfiehlt sich vor allem, wenn ein SSH-Server noch nicht gefunden ist, die Netzwerkverbindung zwischen A und B lahmt und B möglichst schnell loslegen soll.
B packt das Archiv wieder aus und nutzt das entstehende Repository als Basis für eine git clone-Operation. Mit dem daraus entstehenden Arbeits-Repository arbeitet B lokal wie gewohnt weiter.
Später soll B Ergebnisse zur Verfügung stellen. Man kann dann problemlos nachträglich auf einen gemeinsam erreichbaren Klon aufrüsten, auf den B Schreibzugriff hat, zum Beispiel ssh-basiert wie oben.
Haben sich nur Textdateien geändert, kann B eine Patch-Datei an A schicken, also den Output von git diff. Das geht bequem via E-Mail. Mit git apply und anschließendem git commit --author ... kann A die Ergebnisse von B lokal integrieren.
Teilweise Kopieren: Auch sonst nützlich!
Die Idee, sich beim Kopieren eines Repositorys auf den letzten Commit zu beschränken, ist auch sonst gelegentlich nützlich. Viele Builds, CI-Pipelines und ähnliche automatisierte Prozesse können auf einfache Weise erheblich beschleunigt werden, wenn einem ohnehin vorhandenen git clone die Option --depth 1 mitgegeben wird.
Derselbe Trick kann ebenfalls hilfreich sein, wenn man auf den Inhalt eines Open-Source-Repositorys neugierig ist. Man will gerne so schnell wie möglich einen Worktree auf der eigenen Festplatte begutachten können. Die Historie des Repositorys interessiert erst später, in zweiter Linie.
In diesem Fall besorgt man sich das Repository zunächst mit git clone --depth 1. Das geht schnell, entsprechend bald kann man anfangen, sich im Worktree umzusehen. Währenddessen lässt man im Hintergrund den langen Download der Gesamthistorie laufen:
git fetch --unshallow
Wenn man das auf einem Repository mit vollständiger Historie aufruft, erscheint natürlich eine Fehlermeldung. Bei einigen Git-Versionen ist die Fehlermeldung verwirrend falsch ins Deutsche übersetzt:
Die Option --unshallow kann nicht in einem Repository mit unvollständiger Historie verwendet werden.
Das sollte eigentlich "... mit vollständiger Historie ..." heißen.
Wenn man von einem Repository beim initialen Klonen nur den letzten Commit haben wollte, holt Git auch bei späteren git fetch-Operationen zunächst nur den betreffenden Branch. Bei von Anfang an komplett geklonten Repositorys holt git fetch dagegen normalerweise alle vorhandenen Branches. Man kann nachträglich mit folgender Zeile konfigurieren, dass alle Branches geholt werden sollen:
git config remote.origin.fetch '+refs/heads/*:refs/remotes/origin/*'
Fazit
Im ersten Teil ging es um vielfältige Fähigkeiten von Git, deren Kenntnis im normalen Entwickleralltag gelegentlich nützlich wird. Der folgende zweite Teil bietet Nützliches für Autoren von Open-Source-Software (oder solche, die es werden wollen) sowie für DevOps und Automatisierer.
Dr. Andreas Krüger
arbeitet als Senior Consultant bei INNOQ. Er übernimmt Verantwortung für Infrastruktur wie Cloud-Umgebungen oder Build- und Deployment Pipelines, plant, verhandelt, dokumentiert und implementiert Schnittstellen, Algorithmen und Anwendungen und entwirft tragfähige Softwarearchitektur.
(bbo [1])
URL dieses Artikels:
https://www.heise.de/-4456122
Links in diesem Artikel:
[1] mailto:bbo@ix.de
Copyright © 2019 Heise Medien