

Neue Algorithmen in C++17
Die Standard Template Library (STL) hat mehr als 100 Algorithmen für das Suchen, Zählen und Manipulieren von Bereichen und ihren Elementen. Mit C++17 gibt es 69 davon in neuen Variationen und sieben neue Algorithmen. Diese neuen Algorithmen und neuen Varianten können mit einer sogenannten Ausführungsstrategie parametrisiert werden.
- Rainer Grimm
Die Idee ist ganz einfach. Die Standard Template Library (STL) hat mehr als 100 Algorithmen für das Suchen, Zählen und Manipulieren von Bereichen und ihren Elementen. Mit C++17 gibt es 69 davon in neuen Variationen und sieben neue Algorithmen. Diese neuen Algorithmen und neuen Varianten lassen sich mit einer sogenannten Ausführungsstrategie parametrisieren. Dank dieser Ausführungsstrategie lässt sich angeben, ob der Algorithmus sequenziell, parallel oder parallel und vektorisierend ausgeführt wird.
In einem früheren Artikel ging es bereits um die Algorithmen, die mit C++17 parallel ausgeführt werden können..

Heute schreibe ich über die sieben neuen Algorithmen. Hier sind sie:
std::for_each_n
std::exclusive_scan
std::inclusive_scan
std::transform_exclusive_scan
std::transform_inclusive_scan
std::parallel::reduce
std::parallel::transform_reduceMit Ausnahme von std::for_each_n sind die Namen der neuen Algorithmen ziemlich ungewöhnlich. Daher gibt es jetzt einen kleinen Umweg in die rein funktionale Programmiersprache Haskell.
Ein kleiner Umweg
Um die lange Geschichte kurz zu machen: Alle neue Funktionen haben Pendants in Haskell.
- for_each_n heißt map in Haskell.
- exclusive_scan und inclusive_scan besitzen in Haskell den Namen scanl und scanl1.
- transform_exclusive_scan und transform_inclusive_scan sind Kompositionen der Haskell-Funktionen map und scanl or scanl1.
- reduce wird in Haskell foldl oder foldl1 genannt.
- transform_reduce ist eine Komposition der Haskell-Funktionen map und foldl oder foldl1.
Bevor die Haskell-Funktionen in Aktion zu sehen sind, möchte ich noch ein paar Anmerkungen zu den verschiedenen Funktionen machen.
- map wendet eine Funktion auf eine Liste an.
- foldl und foldl1 wenden eine binäre Operation auf eine Liste an und reduzieren sie dabei auf einen Wert. foldl benötigt im Gegensatz zu foldl1 einen Startwert.
- scanl und scanl1 wenden dieselbe Strategie wie foldl und foldl1 an. Sie produzieren aber im Gegensatz dazu alle Zwischenwerte. Daher ist der Rückgabewert eine Liste von Werten.
- foldl, foldl1, scanl und scanl1 starten ihren Job von links.
Jetzt geht es los. Hier ist die Haskell Interpreter Shell.

(1) und (2) definieren eine List von ganzen Zahlen und Strings. In (3) wende ich die Lambda-Funktion auf (\a -> a * a) die Liste der ganzen Zahlen an. (4) und (5) benötigen schon einen genaueren Blick. Der Ausdruck (4) multipliziert (*) alle Paare von Ganzzahlen, beginnend mit 1 als dem neutralen Element der Multiplikation. Ausdruck (5) tut das Entsprechende für die Addition. Ziemlich schwer sind die Ausdrücke (6), (7) und (9) für das imperative Auge zu lesen. Man muss sie von rechts nach links lesen. scanl1 (+) . map(\a -> length a (7) ist eine Funktionskomposition. Der Punkt (.) komponiert zwei Funktionen. Die erste Funktion bildet jedes Element auf ihre Länge ab, die zweite Funktion addierte die Listen der Längen zusammen. (9) ist (7) sehr ähnlich. Der Unterschied ist aber, dass foldl einen Wert erzeugt und einen Startwert benötigt. Das ist die 0. Nun sollte der Ausdruck (8) lesbar sein. Der Ausdruck verbindet sukzessive zwei Strings mit dem Zeichen ":".
Doch warum stelle ich in einem C++-Artikel so viel anspruchsvollen Haskell-Code vor? Dafür gibt es zwei gute Gründe:
- Du kennst nun die Geschichte der C++-Funktionen.
- Die Haskell-Funktionen helfen, die C++-Funktionen leichter zu verstehen, denn Erstere besitzen eine deutlich komplexere Syntax.
Die sieben neuen Algorithmen
Da der Umfang des C++-Sourcecodes deutlich das Layout dieses Artikels sprengen würde und sich daher nicht leicht konsumieren lässt, stelle ich die Algorithmen nur in Codeschnipseln vor. Auf meinem englischen Blogartikel "C++17: New Parallel Algorithm of the Standard Template Library" gibt es den ganzen Sourcecode. Wie versprochen wird es jetzt anspruchsvoll.
In Anlehnung an Haskell kommen zwei Vektoren zum Einsatz
std::vector<int> intVec{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::vector<int> strVec{"Only","for","testing","purpose"};
std::for_each_n
std::for_each_n(std::execution::par,
intVec.begin(), 5, [](int& arg){ arg *= arg; });
Der for_each_n-Algorithmus bildet die ersten fünf Ganzzahlen auf ihr Quadrat ab.
std::exclusive_scan und std::inclusive_scan
std::inclusive_scan(std::execution::par,
intVec.begin(), intVec.end(), intVec.begin(),
[](int fir, int sec){ return fir * sec; }, 1);
std::exclusive_scan(std::execution::par,
intVec.begin(), intVec.end(), intVec.begin(), 1,
[](int fir, int sec){ return fir * sec; });
// scanl (*) 1 ints
Beide Funktionen sind ziemlich ähnlich, den sie wenden eine binäre Operation auf ihre Elemente an. Der Unterschied ist aber, dass std::exclusive_scan in jeder Iteration das letzte Element ignoriert. Der Sourcecode enthält der Lesbarkeit willen in der letzten Zeile den entsprechenden Ausdruck in Haskell.
std::transform_exclusive_scan
Jetzt kommt die schwere Kost: Der Algorithmus ist recht anspruchsvoll zu lesen.
std::vector<int> intVec2(intVec.size());
std::transform_exclusive_scan(std::execution::par,
intVec.begin(), intVec.end(),
intVec2.begin(), 0,
[](int fir, int sec){ return fir + sec; },
[](int arg){ return arg *= arg; });
// scanl (+) 0 . map(\a -> a * a) $ ints s
Wende im ersten Schritt die Lambda-Funktion [](int arg){ return arg *= arg; } auf jedes Element des Bereichs intVec.begin() bis intVec.end() an. Wende anschließend im zweiten Schritt die binäre Operation [](int fir, int sec){ return fir + sec; } auf den temporären Vektor an. Das bedeutet: Summiere alle Werte auf, beginnend mit dem Startelement 0. Das Ergebnis wird nach intVec2.begin() geschrieben.
std::transform_inclusive_scan
std::transform_inclusive_scan(std::execution::par,
strVec.begin(), strVec.end(),
strVec2.begin(), 0,
[](auto fir, auto sec){ return fir + sec; },
[](auto s){ return s.length(); });
// scanl1 (+) . map(\a -> length a) $ strings
Der Algorithmus std::transform_inclusive_scan ist seinem Namensvetter std::transform_exclusive_scan sehr ähnlich. Im ersten Schritt wird jedes Element des Vektors auf seine Länge abgebildet.
std::parallel::reduce
std::string res = std::parallel::reduce(std::execution::par,
strVec.begin() + 1, strVec.end(), strVec[0],
[](auto fir, auto sec){ return fir + ":" + sec; });
// foldl1 (\l r -> l ++ ":" ++ r) strings
Nach der schweren Kost sollte std::paralllel::reduce relativ einfach zu lesen sein. Der Algorithmus verbindet benachbarte Elemente des Vektors mit einem Doppelpunkt: ":". Der resultierende String sollte nicht mit einem Doppelpunkt starten. Daher beginnt der Bereich beim zweiten Element des Vektors (strVec.begin() + 1), und das Startelement von std::parallel::reduce ist das erste Element des Vektors: stdVec[0].
std::parallel::transform_reduce
std::size_t res7 = std::parallel::transform_reduce(std::execution::par,
strVec2.begin(), strVec2.end(),
[](std::string s){ return s.length(); },
0, [](std::size_t a, std::size_t b){ return a + b; });
// foldl1 (\l r -> l ++ ":" ++ r) strings
Zum Algorithmus std::parallel::transform_reduce gibt es eine interessante Geschichte. Diese habe ich bereits in dem Artikel "Parallele Algorithmen der STL" vorgestellt.
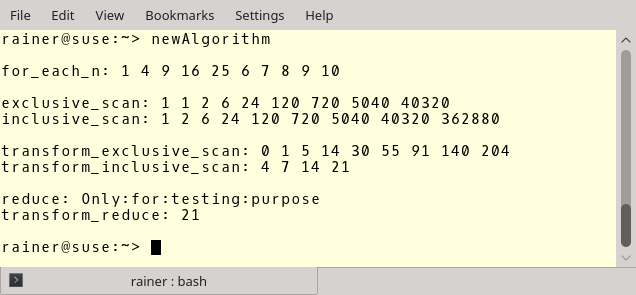
Zum Abschluss gibt es die Ausgabe des Programms. Diese habe ich mithilfe von HPX erhalten. HPX (High Performance ParalleX) ist "... a general purpose C++ runtime system for parallel and distributed applications of any scale". Insbesondere bietet HPX bereits die parallelen Versionen der Algorithmen der STL an.
Was ich noch sagen wollte
Selbst die sieben Algorithmen gibt es noch in verschiedenen Geschmacksrichtungen. Sie lassen sich mit mit und ohne Startelement oder auch mit und ohne Ausführungsstrategie aufrufen. Selbst Funktionen wie std::scan oder std::parallel::reduce, die einen binären Operator benötigt, kann man ohne diesen aufrufen. In diesem Fall kommt die Addition als Default für den binären Operator zum Einsatz. Um die Algorithmen parallel oder parallel und vektorisierend anzuwenden, muss der binäre Operator assoziative sein. Das macht viel Sinn, denn die Algorithmen können einfach auf mehreren Kernen laufen. Für die Details bietet sich die Lektüre des Wikipedia-Artikels zur "Präfixsumme" an. Hier gibt es noch weitere Details zu den Algorithmen: "extensions for parallelism"
Wie geht's weiter?
Im nächsten Artikel schreibe ich über die verbesserten assoziativen und sequenziellen Container der STL. Verbesserung bedeutet in diesem Fall: An der Performanzschraube der assoziativen Container wurde gedreht und das Interface der sequenziellen Container vereinheitlicht. ()
