Serverless Computing, Teil 1: Theorie und Praxis
Nach IaaS, PaaS, BaaS und SaaS kristallisiert sich mit dem Akronym FaaS – Function as a Service – der nächste Evolutionsschritt der noch relativ jungen Cloud-Historie heraus. Laut Wunschvorstellung der Anbieter sollen Enterprise-Anwendungen zukünftig gänzlich ohne Server auskommen. Aber wie soll das funktionieren?
Enterprise-Projekte bringen per Definition eine gewisse Komplexität mit sich. Das gilt sowohl für die umzusetzende Fachlichkeit als auch für die zur Laufzeit benötigte Infrastruktur. Die Entwicklung und Bereitstellung entsprechender Anwendungen wird daher nicht selten mit übergroßen Projektstrukturen, umständlichen Entwicklungsprozessen, schwergewichtigen Anwendungsservern, langsamen Test- und Deploymentzyklen sowie unnötig komplexer Provisionierung assoziiert. Da bilden auch Java-Projekte leider keine Ausnahme.
Modularisierungskonzepte wie Microservices inklusive minimalistischer Runtimes wie Spring Boot oder aber an Java EE angelehnte Umsetzungen lassen das Ganze zwar einfacher werden, aber eben noch nicht einfach genug. Optimal wäre es erst, wenn Entwickler sich tatsächlich nur noch um die Implementierung der fachlichen Bausteine kümmern müssten. Ein Traumszenario? Keineswegs. Zumindest nicht nach Ansicht der Cloud- und Serverless-Propagandisten. "Run code, not Server", so das Motto der Stunde.
Das kleine Cloud-Einmaleins
Eine Anwendung besteht aus Fachlichkeit beziehungsweise Use-Cases. Ziel sollte es somit sein, dass sich die Entwickler der Anwendung maßgeblich auf deren Umsetzung konzentrieren können. Die Realität sieht leider anders aus. Ein Großteil der Zeit innerhalb eines Projekts wird nicht für die Anwendungsentwicklung selbst, sondern für das korrekte Aufsetzen und Betreiben der zur Laufzeit benötigten Infrastruktur und Backend-Services ver(sch)wendet.
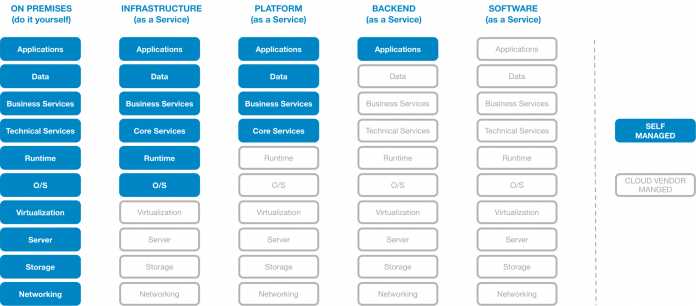
Genau an der Stelle setzen die unterschiedlichen Cloud-Angebote an und liefern den Entwicklerteams Out-of-the-box-Dienste unterschiedlichster Granularität. Angefangen bei virtuellen Rechnern (Infrastructure as a Service, IaaS) über Datenbanken, Dateisysteme oder Anwendungsserver (Platform as a Service, PaaS), bis hin zu komplexen Softwareanwendungen – als modulare Services (Backend as a Service, BaaS) oder in Gänze (Software as a Service, SaaS) – kann sich ein Cloud-affines Entwicklerteam einer breiten Palette an Möglichkeiten bedienen (s. Abb. 1).

Einmal abgesehen von der Tatsache, dass sich mithilfe der Cloud-Dienste in allen Phasen des Softwarelebenszyklus ein großer Teil des Entwicklungs- und operationalen Aufwands einsparen lässt, bringt deren Einsatz noch einen weiteren, wichtigen Vorteil mit sich: automatische Skalierung. Dank der Verlagerung von Infrastruktur in die Cloud kann eine Anwendung "on the fly" skalieren. Werden zum Beispiel zusätzliche Rechnerinstanzen benötigt, lassen sie sich in Minuten statt Tagen oder Wochen zur Verfügung stellen.
Gleiches gilt für neue Datenbanken, zusätzlichen Plattenplatz oder weitere Instanzen von Anwendungsservern. Selbst komplexe Dienste wie Kundenverwaltung, Social-Media-Integration, Push Notifications, Chat und Messaging oder Nutzeranalysen passen sich dank Cloud-basierter Backend-Services automatisch der anfallenden Last an. Abgerechnet wird dabei in der Regel aufwandsbasiert via Pay-per-use-Modell. Hohe Initialkosten und somit ein nur schwer kalkulierbares Projektrisiko gehören der Vergangenheit an.
Es ist sicherlich für jedermann vorstellbar, dass der Einsatz Cloud-basierter, virtualisierter Server eine deutlich vereinfachte Provisionierung mit sich bringt. Gleiches gilt für die Verwendung vorinstallierter und vorkonfigurierter Datenbank- und Storage-Systeme oder Anwendungsserver in der Cloud. Und selbst die Einbindung von Rundum-sorglos-Softwaremodulen zur Abdeckung von Standardaufgaben wie der Verwaltung von Kunden- oder Produktdaten eines Web-Shops scheint gangbar (s. Abb. 2).
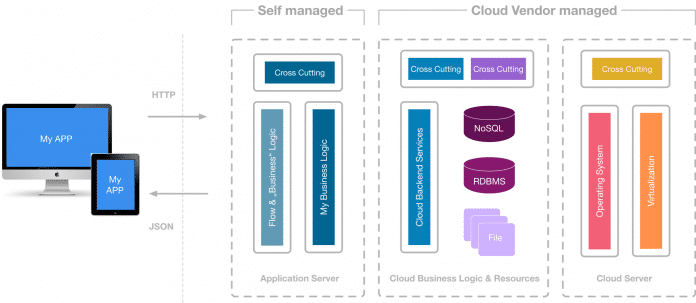
Aber wo genau befindet sich die Grenze? Oder anders gefragt: Wie weit lässt sich die Verlagerung der eigenen Anwendung in Richtung Cloud treiben? Ist es realistisch, wie es der Begriff Serverless suggeriert, seine Anwendung vollständig in die Cloud zu verlagern, sodass kein Server mehr zu betreiben, zu administrieren und zu konfigurieren ist? Die Verwendung von Containern wie Docker schafft zwar einheitliche Umgebungen zur Entwicklungs- und Laufzeit und minimiert so den administrativen Aufwand, eliminiert wird er durch ihren Einsatz aber nicht.
Wer braucht schon einen Server?
Eine Enterprise-Anwendung setzt sich aus anwendungsspezifischer Logik zusammen. In der Java-Welt läuft diese in der Regel als mehrschichtiger Monolith auf einem Application Server oder alternativ verteilt in Form mehrerer eigenständiger (Micro-)Services inklusive eingebetteter Server-Runtime-Komponente. Die Frage, die sich auf dem Weg zu Serverless stellt, ist somit, wie sich die Logik weg vom selbst verwalteten Server bewegen lässt. Ein genauerer Blick auf die Logik einer Anwendung offenbart die Unterscheidung in drei Aufgabenbereiche:
- Ablaufsteuerung und lokale Logik
- standardisierte Geschäftslogik
- individuelle Geschäftslogik
Die Ablaufsteuerung befindet sich normalerweise in UI-Controllern. Diese nehmen Eingaben der UI entgegen, triggern im Hintergrund die Abarbeitung von Geschäftslogik an (2. und 3.), um am Ende die als nächste darzustellende UI-Ansicht zu bestimmen. In einer reinen Cloud-Architektur ließe sich diese Logik in den Client verlagern. Er könnte zum Beispiel eine in JavaScript geschriebene Single Page Application sein. Gleiches gilt für die lokale Logik, also die Geschäftslogik, die nicht auf geteilte Ressourcen wie Datenbanken, Dateisystem et cetera zugreift. Auch sie ließe sich vollständig auf den Client verlagern. Vorausgesetzt natürlich, dass keine sicherheitsrelevanten Aspekte dagegen sprechen. Zum Beispiel sollten Security-Credentials niemals auf dem Client gespeichert werden.
Die Verlagerung der standardisierten Geschäftslogik wurde oben im Rahmen der Vorstellung von BaaS beschrieben. Denn genau das ist es, was ein Backend as a Service ausmacht. Es bietet standardisierte Services und somit unter anderem standardisierte Geschäftslogik in der Cloud. Bleibt die individuelle Logik, also die serverseitige Logik, die die BaaS-Angebote der Cloud-Anbieter nicht abdecken können. Sie ist es, die bisher eine eigene Server-Runtime benötigte – egal ob in Form eines Application Server oder eingebettet als Runtime-Komponente eines (Micro-)Services.
Function as a Service
Genau diese Lücke haben auch einige Cloud-Anbieter erkannt, allen voran Amazon und Microsoft, und bieten in der Cloud Laufzeitumgebungen für die Ausführung einzelner Business-Methoden (FaaS) an (s. Abb. 3). Die Idee dahinter ist, dass Entwickler lediglich die Business-Methoden der Anwendung implementieren, sie in die Cloud laden und ab diesem Moment – so die Theorie – keinen weiteren Aufwand mehr mit ihnen haben.
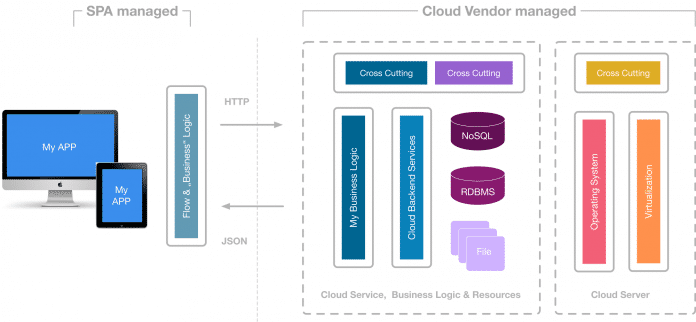
Aufgerufen werden die Funktionen entweder synchron via klassischem Request-/Response-Modell oder asynchron über Events. Um eine zu enge Kopplung der einzelnen Funktionen zu vermeiden und den Ressourcenbedarf zur Laufzeit zu optimieren, sollte – wenn möglich – auf die asynchrone Variante zurückgegriffen werden. Das gilt insbesondere bei verschachtelten Aufrufen von Funktionen, da sonst die aufrufenden Funktionen unnötig lange am Leben gehalten werden und entsprechende Kosten verursachen.
Was zunächst stark nach Platform as a Service klingt, unterscheidet sich in der Praxis stark von diesem Ansatz. Während PaaS eine langlebige Ablaufumgebung für die gesamte Laufzeit – vom Start bis zum gezielten Herunterfahren – eines Application Server oder eines (Micro-)Services zur Verfügung stellt, bietet Function as a Sercice eine kurzlebige Runtime, die lediglich für die Ausführungszeit eines einzelnen Funktionsaufrufs existiert. Laufzeiten von wenigen Sekunden oder gar Millisekunden sind das Maß der Dinge. Adrian Cockcroft, ehemals Cloud-Architekt bei Netflix und heute VP Cloud Architectures bei Amazon, schrieb dazu in einem seiner Tweets: "If your PaaS can efficiently start instances in 20ms that run half a second, then call it serverless."
Die FaaS-Runtime skaliert automatisch mit steigender Last. Wird eine Funktion häufiger aufgerufen, werden automatisch entsprechend viele FaaS-Runtimes gestartet und nach Abarbeitung der Funktion wieder beendet. Die Nutzung von FaaS eignet sich somit insbesondere für Szenarien, in denen das Lastverhalten einzelner Business-Methoden extrem schwanken kann. Natürlich existieren im Hintergrund auch weiterhin physikalische und virtuelle Server sowie minimalistische Server-Runtimes zur Ausführung der Funktionen. Der Begriff Serverless soll lediglich ausdrücken, dass sich Anwendungsentwickler um diese keinerlei Gedanken mehr machen müssen beziehungsweise keinerlei administrativen Aufwand mit ihnen haben.
Ein beispielhaftes "Hello FaaS"
Nicht nur AWS
Zur Umsetzung des skizzierten Anwendungsszenarios wird im Rahmen des Beispiels Amazons AWS Cloud verwendet. Die Realisierung der einzelnen Funktionen erfolgt mithilfe von AWS Lambda [1], Amazons FaaS-Implementierung. Das gezeigte Szenario ließe sich aber auch in ähnlicher Form problemlos mit anderen FaaS-Providern wie Google Functions [2], Microsoft Azure Functions [3] oder IBM OpenWhisk [4] realisieren.
Ein Beispiel sagt mehr als tausend Worte: Mithilfe der Anwendung "myJourney" können Anwender Reiseerlebnisse mit Freunden und Bekannten teilen. Zu diesem Zweck laden sie Bilder ihrer Reise inklusive Meta-Informationen in die Cloud. Die Bilder landen dort in einer zur Anwendung gehörenden Dateiablage, die Meta-Daten in einer entsprechenden Datenbank. Zusätzlich wird für die hochgeladenen Bilder ein Thumbnail erzeugt. Wie lässt sich ein solches Szenario mithilfe von Function as a Service als Serverless-Architektur realisieren?
Eine erste Funktion uploadImageToCloud lädt das Bild in die Cloud und legt es dort in einem zur Anwendung gehörenden Cloud-Dateisystem ab. Parallel dazu nimmt eine zweite Funktion insertImageMetaDataIntoCloudDB die zur Verfügung gestellten Meta-Daten und speichert sie in eine anwendungsspezifische Cloud-Datenbank.
/**
* Handles lambda function call
*
* @param imageUploadRequest Image information, e.g. URI of the image
* @param context Lambda function context
* @return String indicating if everything was fine.
* @throws IOException In case of file handling problems
*/
public ImageUploadResponse uploadImageToCloud(
ImageUploadRequest imageUploadRequest,
Context context) throws IOException {
// extract image info from request data
ImageInfo imageInfo =
ImageInfo.extractFromRequest(imageUploadRequest);
// create an in-memory-file
File inMemoryFile = Files.createTempFile(null, null).toFile();
FileUtils.copyURLToFile(new URL(imageInfo.getUri()), inMemoryFile);
// create object metadata for s3 storage
ObjectMetadata metadata = ... ;
// create PUT OBJECT S3 request with
// - predefined bucket (AWS_S3_BUCKET_NAME)
// - filename including path (AWS_S3_BUEKCT_KEY)
// - file to store
// - some additional meta data
// - public read access
PutObjectRequest putObjectRequest = new PutObjectRequest(
AWS_S3_BUCKET_NAME, AWS_S3_BUEKCT_KEY, inMemoryFile)
.withMetadata(metadata)
.withCannedAcl(CannedAccessControlList.PublicRead);
// call PUT OBJECT to AWS S3 bucket
// no credentials needed, lambda function has own AWS IAM role
PutObjectResult result = AWS_S3_CLIENT.putObject(putObjectRequest);
ImageUploadResponseBuilder builder
= new ImageUploadResponseBuilder();
return new ImageUploadResponseBuilder()
.withAwsS3BucketName(AWS_S3_BUCKET_NAME)
.withAwsS3BucketKey(AWS_S3_BUEKCT_KEY)
.withAwsS3ObjectSize(inMemoryFile.length())
.build();
}
Alternativ ließen sich die beiden Schritte in einer Funktion realisieren. Zur Optimierung der Laufzeit sowie zur Trennung der Zuständigkeiten wurde hier jedoch bewusst auf zwei Funktionen zurückgegriffen (s. Abb. 4, Step 1a und 1b).
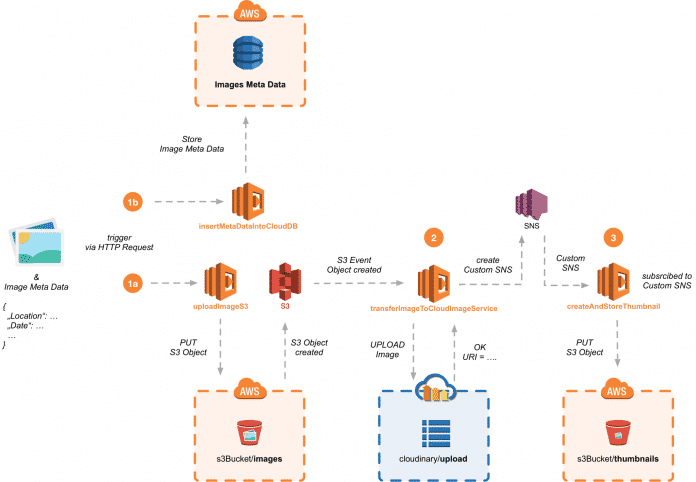
Durch das Ablegen des Bildes im Dateisystem wird ein Event "Object created" ausgelöst, das eine für das Event und das zugehörige Verzeichnis der Dateiablage als Listener registrierte Funktion transferImageToCloudImageService triggert. Sie überträgt zunächst das Bild aus dem Dateisystem in einen externen Cloud-basierten Bildmanipulations-Service (Cloudinary [5]) zwecks späterer Bearbeitung. Mithilfe der vom Service zurückgelieferten URI erzeugt die Funktion anschließend ein selbstdefiniertes Event, das interessierten Funktionen signalisieren soll, dass ein Bild zur Generierung eines Thumbnails bereitliegt (Abb. 4, Step 2). Siehe dazu den zugehörigen Quellcode:
/**
* Transfers image from AWS S3 cloud to cloudinary image service
*
* @param s3Event event that indicates new image in AWS S3 bucket
* @param context Lambda function context
* @return upload location of cloudinary image service
*/
public String transferImageToCloudImageService (S3Event s3Event,
Context context) {
String uploadLocation = "UNKNOWN";
// extract info from S3 event, to get access to S3 object
// and upload object to Cloudinary image cloud
for (S3EventNotificationRecord s3EventNotificationRecord :
s3Event.getRecords()) {
// extract object (image) information from S3 event
S3Entity s3Entity = s3EventNotificationRecord.getS3();
String eventName = s3EventNotificationRecord.getEventName();
String bucketName = s3Entity.getBucket().getName();
String objectName = s3Entity.getObject().getKey();
// access image object from S3 bucket)
S3Object s3Object = AWS_S3_CLIENT.getObject(bucketName,
objectName);
// upload image to Cloudinary image cloud
try {
// create an in-memory-file
File inMemoryFile = Files.createTempFile(
null, null).toFile();
S3ObjectInputStream s3ObjectInputStream =
s3Object.getObjectContent();
FileUtils.copyInputStreamToFile(s3ObjectInputStream,
inMemoryFile);
Map uploadMetaData = CLOUDINARY_CLIENT.uploader()
.upload(inMemoryFile, keepFileInfoMetaData());
uploadLocation = uploadMetaData.get(URL).toString();
// publish aws sns message with image URI to topic
PublishResult publishResult = AWS_SNS_CLIENT
.publish(SNS_TOPIC, uploadLocation);
} catch (IOException e) {
// handle IO Exception
...
}
}
return uploadLocation;
}
Das Erzeugen des Thumbnails sowie dessen anschließende Ablage in einem separaten Ordner der Cloud-Dateiablage erfolgt letztlich durch die Funktion createAndStoreThumbnail (Abb. 4, Step 3):
/**
* Transfers image from AWS S3 cloud to cloudinary image service
*
* @param SNSEvent event that indicates the image location
* @param context Lambda function context
*/
public void createAndStoreThumbnail(SNSEvent event, Context context) {
String awsThumbnailLocation = "UNKNOWN";
for (SNSEvent.SNSRecord snsRecord : event.getRecords()) {
// extract image service uri from message
String snsId = snsRecord.getSNS().getMessageId();
String snsMessage = snsRecord.getSNS().getMessage();
// use cloudinary on-th-fly service to convert image
String generateThumbnailUri =
createGenerateThumbnailUri(snsMessage);
try {
File file = Files.createTempFile(null,null).toFile();
FileUtils.copyURLToFile(new URL(generateThumbnailUri),
file);
// set image S3 storage destination
String imageName = createStorageName(generateThumbnailUri);
// create PUT OBJECT S3 request with
// - predefined bucket (AWS_S3_BUCKET_NAME)
// - new filename (AWS_S3_BUCKET_KEY)
// - file to store
// - some additional meta data
// - public read access
PutObjectRequest putObjectRequest = new PutObjectRequest(
AWS_S3_BUCKET_NAME, AWS_S3_BUCKET_KEY, file)
.withCannedAcl(CannedAccessControlList.PublicRead);
// call PUT OBJECT to AWS S3 bucket
// no credentials needed, lambda function has own AWS IAM
PutObjectResult result = AWS_S3_CLIENT
.putObject(putObjectRequest);
} catch (IOException e) {
// handle excpetion
...
}
}
}
Komposition versus Orchestrierung
Das Beispiel verdeutlicht, dass die Ablaufsteuerung der Anwendung nicht explizit durch eine zentrale Stelle gesteuert wird, sondern sich implizit durch die ausgelösten Events und die zugehörigen Event-Listener, also die für das Event registrierten Funktionen, ergibt. Es findet demnach eine dynamische, selbstorganisierte Komposition und keine statische Orchestrierung statt. Der Vorteil einer solchen eventgetriebenen Architektur liegt darin, dass sich durch die starke Entkopplung der einzelnen fachlichen Komponenten neue Business-Logik einfach hinzufügen und bestehende Business-Logik problemlos ändern lässt. Als Schnittstelle dient das Event beziehungsweise dessen Payload. Solange diese stabil oder abwärtskompatibel bleibt, lassen sich die einzelnen Funktionen unabhängig voneinander ändern.
Problematisch wird es immer dann, wenn sich ein Event im Aufbau so ändert, dass die Funktionen es nicht mehr verarbeiten können. Das betrifft weniger die durch die Cloud-Komponenten ausgelösten Standard-Events als vielmehr die selbstdefinierten Custom-Events, wie das gezeigte zur Signalisierung, dass ein neues Bild im Image-Manipulation-Service abgelegt wurde.
Im vorliegenden Beispiel ist es noch einfach, den Überblick über die verwendeten Events und deren zugeordneten Funktionen zu behalten. In einem deutlich komplexeren Szenario dagegen stellt das eine nicht zu unterschätzende Herausforderung dar. Das ist aber weniger ein Problem des Serverless-Ansatzes als vielmehr eine allgemeine Herausforderung ereignisgetriebener Architekturen.
Das Tor zur Cloud: API Gateway
Im Beispiel wird stillschweigend davon ausgegangen, dass die erste Serverless-Funktion uploadImageToCloud durch einen RESTFul API Call des Clients ausgelöst wird. Wer allerdings einen Blick auf die Methodensignatur des ersten Quellcodebeispiels wirft, findet dort nichts, was auf eine RESTful-Schnittstelle hinweist. Wie kommt es also zur Verbindung zwischen Client und Funktion?
Beim Anlegen der Serverless-Funktion lässt sich ein Trigger für diese definieren. Er kann zum Beispiel das Anlegen, Ändern oder Löschen eines Objekts in der Dateiablage, ein neuer Eintrag im Cloud-Log oder ein selbstdefiniertes Custom-Event sein. Zusätzlich besteht die Möglichkeit, einen HTTP-Aufruf eines API Gateways – im Beispiel handelt es sich um das AWS API Gateway – als Trigger zu verwenden. Es übernimmt dabei die Aufgabe, den RESTful Call des Clients entgegenzunehmen und gemäß vorgegebener Konfiguration in ein FaaS-konformes Event beziehungsweise einen entsprechenden Request zu transformieren. Gleiches gilt für die umgekehrte Richtung und somit für eine mögliche Response der Funktion. Das Gateway fungiert dabei als eine Art Schleuse zwischen Client und Cloud-Backend und garantiert so eine starke Entkopplung beider Welten. Die Schnittstellen der Funktionen lassen sich ändern, ohne dass Anpassungen an den Clients durchzuführen sind. Sogar ein Austausch von Funktionen ist so möglich.
Neben der beschriebenen Transformation kann ein API Gateway noch weitere wichtige Aufgaben übernehmen, wodurch seine Verwendung zu einem wichtigen Design Pattern für Cloud-Anwendungen wird. Zum Beispiel können innerhalb des Gateways zentrale Security-Checks (Authorization, Authentication, DDoS & Injection) stattfinden. Auch ein Test auf API-Schlüssel und ein damit verbundenes Limitieren von Zugriffen auf die Services und Funktionen im Cloud-Backend ist möglich. Weiterhin bietet sich die Umsetzung nichtfunktionaler Aspekte wie Logging oder Response-Chaching an. Es kann durchaus auch sinnvoll sein, das API Gateway zur Aggregation von Ergebnissen mehrerer Services und Funktionen des Cloud-Backends zu nutzen, um so teure Client-Server-Roundtrips über das langsamere LAN einzusparen (s. Abb. 5).

Fazit
Große Enterprise-Projekte bringen eine entsprechende Komplexität mit sich. Nicht selten liegt der Fokus der Entwicklung mehr auf Infrastruktur und Technologie als auf der Umsetzung der Fachlichkeit. Abhilfe schafft eine Verlagerung einzelner Komponenten in die Cloud. Eine Grenze scheint erst bei der individuellen Business-Logik der eigenen Anwendung erreicht. Doch selbst diese Grenze wird es zukünftig nicht mehr geben. Verschiedene Cloud-Anbieter bieten die Möglichkeit, einzelne Funktionen als Services (FaaS) in der Cloud zu hinterlegen und so die eigene Fachlichkeit, aufgeteilt in kleinen Blöcken, abzubilden.
Angesprochen werden die Funktionen von außen über ein API Gateway oder Cloud-intern via Event einer anderen Cloud-Komponente. Die Skalierung zur Laufzeit erfolgt automatisch. Bezahlt wird pro Aufruf. Der Anwendungsentwickler muss sich um keinerlei Infrastruktur kümmern – Serverless ist das Schlagwort der Stunde.
Die Ablaufsteuerung der Anwendung ergibt sich impliziert durch die Komposition der Events. Orchestrierende Komponenten dagegen sucht man vergebens. Wie man dabei zur Entwicklungs- und Laufzeit den Überblick behalten kann und welche Chancen und Risiken der Schritt hin zu einer Serverless-Cloud-Architekur birgt, zeigt der zweite Teil.
Lars Röwekamp
ist Gründer des IT-Beratungs- und Entwicklungsunternehmens open knowledge GmbH und beschäftigt sich im Rahmen seiner Tätigkeit als "CIO New Technologies" mit der eingehenden Analyse und Bewertung neuer Software- und Technologietrends. Ein besonderer Schwerpunkt seiner Arbeit liegt derzeit in den Bereichen Enterprise und Mobile Computing.
(ane [6])
URL dieses Artikels:
https://www.heise.de/-3756877
Links in diesem Artikel:
[1] https://aws.amazon.com/de/lambda/
[2] https://cloud.google.com/functions/
[3] https://azure.microsoft.com/de-de/services/functions/
[4] https://developer.ibm.com/openwhisk/
[5] http://cloudinary.com/
[6] mailto:ane@heise.de
Copyright © 2017 Heise Medien