Apache Hop – der nächste große Sprung in der Datenintegration

(Bild: Volodymyr Burdiak / Shutterstock.com)
Dank visueller Drag-and-Drop-Benutzeroberfläche ermöglicht Apache Hop schnelles produktives Arbeiten mit Daten – ohne Code schreiben zu müssen.
Apache Hop ist eine neue, auf Metadaten basierende Open-Source-Plattform für Data Engineering und Datenorchestrierung. Das erste offizielle Release der Hop Orchestration Platform erschien im Oktober 2021, seit Mitte des laufenden Jahres liegt Version 2.0 vor [1]. Warum sie für Dateningenieure interessant ist: Die visuelle Entwicklung per Drag-and-Drop- ermöglicht es, Workflows und Pipelines sehr einfach zu gestalten. Dabei sind Scripting und das Schreiben von Code eine Option, keine Notwendigkeit. So haben erfahrene Data Engineers die Möglichkeit, zusätzliche Skripte mitzuverarbeiten, während Nicht-Hardcore-Entwickler sich – mit einer steilen Lernkurve – selbst ihre Datenpipelines erstellen können.
Die visuelle Entwickleroberfläche ermöglicht es Entwicklerinnen und Entwicklern, produktiver zu sein als allein durch das Schreiben von "echtem" handgefertigtem Code. Die Hop GUI ist eine vollwertige visuelle IDE, die sowohl für den Desktop (Windows, macOS und Linux) als auch den Browser (Hop Web) verfügbar ist. Mit Hop GUI lassen sich Workflows und Pipelines visuell entwerfen, ausführen und debuggen.

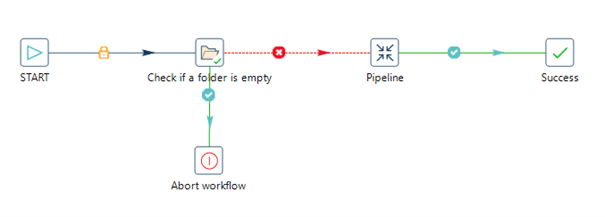
Der visuelle Editor ermöglicht es nicht nur, Hop-Workflows und -Pipelines einfach zu erstellen, auch die Pflege und Nachvollziehbarkeit des visuellen Codes ist einfacher als bei handgeschriebenem Code. Ein Problem zu identifizieren und zu beheben ist in einem klar definierten visuellen Layout viel einfacher, als durch die vielen Zeilen des Quellcodes scrollen zu müssen.
Die grafische Aufbereitung erleichtert auch das Verständnis der erzeugten Pipelines, wenn Entwicklerinnen und Entwickler die Business-Logik mit der Fachabteilung erstellen und abstimmen müssen. Die Fachabteilung bauen so auch mehr Vertrauen in die jeweiligen Daten-Pipelines auf, und gemeinsam kommen alle Beteiligten im Fehlerfall schneller zu Lösungen oder erzielen rascher ein gemeinsames Verständnis bei neuen Anforderungen. Während der Transformation und Zusammenführung der Daten erhält man auf jeder Transformationsstufe Echtzeiteinblicke basierend auf den Daten und verwandelt diese während der Entwicklung in nützliche Informationen.
Trotz aller Vorteile der visuellen Gestaltung sollten Hop-Nutzerinnen und -Nutzer beim Verwalten der Pipelines und Workflows nicht auf Versionskontrolle verzichten. Darüber hinaus empfiehlt sich die nahtlose Integration von Tests, CI/CD und Dokumentation – all das beherrscht Apache Hop.
Strikte Datentrennung
Apache Hop [2] trennt Daten strikt von Metadaten, sodass sich die Datenprozesse unabhängig von den Informationen gestalten lassen. Jeder Objekttyp in Hop beschreibt sowohl, wie Daten gelesen, bearbeitet oder geschrieben werden, als auch, wie Workflows und Pipelines orchestriert werden. Auch intern ist Hop metadatengesteuert und verwendet eine Kernel-Architektur mit einer robusten Engine. Neue Funktionen lassen sich durch den Metadatenansatz in Form von Plug-ins einfach hinzufügen.
Das Hop-Entwicklerteam hat von Beginn an auf Flexibilität, Erweiterbarkeit und Wartbarkeit der Plattform konzentriert. Alles sollte austauschbar sein. Das bedeutet für Systemadministratoren, dass sie die volle Kontrolle über die Funktionsweise haben, schnell neue Funktionen in Form von Plug-ins hinzufügen können, und auch nur jene zulassen, die wirklich nötig sind. Damit fügt sich Hop gut in DevOps- und CI/CD-Umgebungen ein.
Viele Data Engineers sollten mit der Herausforderung vertraut sein, viele Projekte gleichzeitig umsetzen zu müssen. Dabei kann es leicht zu Fehlern kommen, wenn die Beteiligten in mehreren Projekten oder über mehrere Branches hinweg arbeiten: Schnell ist der erstellte Code im falschen Projekt gespeichert. Das integrierte Lifecycle Management in Hop ermöglicht es, zwischen verschiedenen Projekten und Umgebungen zu wechseln. Hop passt dabei automatisch alle Metadaten dem jeweiligen Projekt an, sodass ein Arbeiten im "falschen Raum" fast unmöglich ist.
Typische Data-Engineering-Teams decken meist mehrere Themen ab und führen diese in einer Reihe von Umgebungen aus. In Hop können die Teams ihre Arbeit in separaten Hop-Projekten organisieren und mit unterschiedlichen Umgebungskonfigurationen pro Projekt speichern. Durch die Trennung von Projekten und Umgebungen behalten die Teams von der Entwicklung über das Testen bis hin zur Produktion die Übersicht und Kontrolle über den Code und die jeweiligen neuen Features.
In der Hop-Oberfläche erstellte Workflows und Pipelines sind laufzeitunabhängig und lassen sich auf unterschiedlichen Umgebungen wie einem lokalen Laptop, einem Remote-Server oder auch auf Apache Spark, Apache Flink und Google Dataflow über Apache Beam ausführen. Nutzerinnen und Nutzer können so eine einfache und schnelle Skalierung ihrer ETL-Datentransformationsprozesse (Extract, Transform, Load) vornehmen. Auch Upgrades schon länger bestehender ETL-Strecken auf neue Techniken gelingen leichter, wenn immer schnellere Zyklen die Projektteams vor Herausforderungen stellen. Erfahrungsgemäß verbraucht der Austausch eines ETL-Tools alle paar Jahre sehr viel Zeit und Ressourcen – und verursacht damit vermeidbare Kosten.
Vierfache Arbeitserleichterung
Bei der täglichen Arbeit profitieren Hop-Anwenderinnen und -Anwender regelmäßig von den gleichen vier großen Arbeitserleichterungen:
- Qualität der Datenprozesse durch Testen,
- verbesserte Zusammenarbeit in verteilten Teams durch visuelle Codevergleiche,
- individuelle Logging-Verfahren sowie
- flexible und schnell skalierende Laufzeit-Umgebungen.
Verbesserung der Codequalität
In hochkomplexen Datenprojekten, in denen Daten aus verschiedenen Quellsystemen zusammenfließen müssen, ist Testen unabdingbar. Testen erfordert das Auseinandersetzen mit einigen wichtigen Fragen: Stehen überhaupt Testdaten zur Verfügung? Ist das Testdatenset zu groß oder zu klein? Muss man sich Testdaten selbst erzeugen? Welche Testanforderungen haben die einzelnen Stakeholder der jeweiligen Quellsysteme? Wie testet man einzelne Datenstrecken im Vergleich zu ganzen Datenbankbeladungen? Was passiert beim Zusammenführen von Daten aus verschiedenen Quellsystemen, wenn sich die Datenstruktur eines Quellsystems ändert und man Anpassungen vornehmen muss? Wie stellt man sicher, dass vorgenommene Änderungen auch keine Seiteneffekte haben oder andere Änderungen am Code Fehler erzeugen?
Mit Apache Hop-Unit-Tests lassen sich Daten in Form von Eingabedatensätzen simulieren und die Ausgabe anhand von "Golden-Datasets" validieren. Hop-Pipelines ermöglichen es, testgetrieben zu arbeiten, aber auch Regressionstests durchzuführen, um sicherzustellen, dass alte, bereits behobene Probleme nicht erneut auftreten.
Für das Erstellen eines Unit-Tests stehen in Apache Hop verschiedene graphische Actions zur Verfügung, die sich jederzeit verwenden lassen. Darüber hinaus lässt sich bei Bedarf ein neues Data-Set anlegen und sofort nutzen.

Die Ausgabe nach jedem absolvierten Unit-Test liefert alle relevanten Informationen zum Test. In einer Datenbank abgelegt, vervollständigt sie die Dokumentation. Sämtliche für ein Projekt erstellten Unit-Tests lassen sich regelmäßig automatisiert – beispielsweise über Jenkins – ausführen, um ein kontinuierlich, gründlich getestetes Projekt sicherzustellen.
Entwicklerinnen und Entwickler können die Tests selbst auf der Oberfläche erzeugen oder auf zuvor definierte Test-Data-Sets im Projekt zurückgreifen. Das trägt zu höherer Codequalität bei und stärkt Sicherheit sowie Vertrauen in den neu generierten Code. Tests helfen außerdem bei der schnellen Ermittlung von Seiteneffekten und erleichtern das Leben eines Dateningenieurs enorm.
Für den Fall, dass keine Testdaten zur Verfügung stehen, bietet Hop die "Fake-Data"-Aktion, mit der sich eigene Testdaten generieren lassen. Sie greift auf die Library JavaFaker zurück und ermöglicht das Erstellen verschiedener, zum Testen benötigter Attribute. Das beschleunigt die Entwicklung, da man nicht mehr externe Testdaten mit hohem Aufwand manuell einlesen muss. Auch wenn kein direkter Zugriff auf das Quellsystem besteht oder es zu lange dauert, an die Quelldaten zu gelangen.
Verbesserte Zusammenarbeit in verteilten Teams durch visuelle Codevergleiche
Heutzutage greifen (fast) alle Softwareprojekte auf Versionsverwaltungs-Tools wie Git zurück. Doch in Kombination mit grafischen ETL-Tools treten dabei häufig Probleme auf. Gerade bei der gemeinsamen Arbeit großer verteilter Teams an einem Datenprojekt kann es schnell zu Überschneidungen oder Codeänderung an den gleichen Stellen kommen – und in der Folge zu Merge-Konflikten. Auch lassen sich Änderungen, beispielsweise bei einem Code Review, nur schwer nachvollziehen, da sie in einem zeilenbasierten Vergleich nicht direkt ins Auge springen. Das kostet Teams sehr viel Zeit sowie Analyse- und Abstimmungsaufwand, der sich durch eine visuelle Anzeige der Änderungen im Code verringern ließe. Hier kommt die visuelle Änderungsanzeige von Hop ins Spiel, mit der sich die Änderungen zu allen gespeicherten Versionen im Versionsverwaltungstool vergleichen lassen, sodass auf einen Blick die Änderungen für jeden Schritt ersichtlich sind. Sie hilft bei eventuell notwendiger Fehlersuche, ist aber auch bei Codereviews und Abstimmungen mit anderen Entwicklern nützlich.
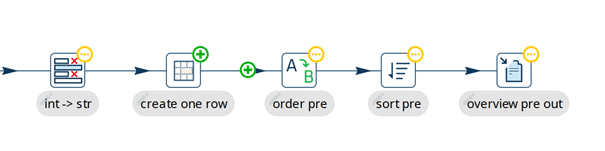
Wie alle anderen gängigen Git-Funktionen findet sich dieses Feature ebenfalls im File-Explorer von Apache Hop. Anhand der Farbe der Pipelines lässt sich der jeweilige Status der einzelnen Files ablesen. Zwar ist die Funktion in Datenprojekten nicht grundsätzlich neu, aber mit Hop entfällt für Entwicklerinnen und Entwickler der bisher übliche Wechsel des Tools. Sie können in ihrer gewohnten Oberfläche weiterarbeiten, ohne Störungen im Arbeitsfluss.
Individualisiertes und nachvollziehbares Logging
Für die meisten Data Engineers ist Logging kein spannendes Thema. Nach der persönlichen Erfahrung des Autors verfolgen viele Projekte einen Alles-oder-Nichts-Ansatz: Entweder protokollieren die Verantwortlichen gar nicht oder sie erfassen jede mögliche Metrik und speichern alles. Die sinnvolle Anforderung in Datenprojekten liegt aber meistens in der Mitte. Hop zeigt sich auch hier als echter "Game Changer":
Der minimalistische Ansatz besteht darin, nur die Start- und Stoppzeiten des Gesamtprozesses zu loggen. Das funktioniert allerdings nur bei Projekten, deren potenzielle Fehleranfälligkeit gering ist und deren Datenprozesse sich einfach wiederholen lassen, ohne dass es zu Duplikaten kommt.
Viele Projekte erfordern ein intensiveres Logging. Um zu erfassen, was in einem Ladeprozess vor sich geht, sollte es für jeden Prozess ein Step-by-Step-Logging geben. So ließen sich in einem idealen Design der Start, das Ende sowie alle weiteren erforderlichen Informationen wie Fehler, Ausnahmen und Prüfungsinformationen etc loggen.
Apache Hop bietet die Option, eine Logging-Anforderung pro Pipeline zu steuern. Dadurch lassen sich mehrere ETL-Strecken mit unterschiedlichen Anforderungen auch individuell behandeln. Die Logging-Details sowie das Intervall der Logs lassen sich detailliert konfigurieren, um nur so viel wie nötig und so wenig wie möglich zu loggen.
Zum Steuern dient ein eigener Metadaten-Typ: Pipeline Log. Er loggt die Interaktion einer Pipeline mit einer anderen und schreibt diese Informationen in eine beliebige Datenbank.
Häufig benötigen Data Engineers den Output einer Pipeline für die Steuerung der nächsten Pipeline. Dafür bietet Hop einen weiteren Metadatentyp: Pipeline Probe. Er streamt Daten von einer laufenden Pipeline zu einer anderen. Die empfangende Pipeline kann die Informationen dann beispielsweise für Datenqualität, Datenprofilierung, Datenherkunft usw. verarbeiten.
Die zu speichernden Log-Daten landen in vielen Projekten vollständig in einer Datenbank oder entsprechend riesigen Logfiles. Das kann sich als problematisch erweisen, wenn nicht dokumentiert ist, wo die Informationen zu finden sind, denn Logfiles müssen leicht zugänglich und verständlich sein. Durch große unleserliche Logfiles oder Datenbanktabellen mit Logdaten zu navigieren, ist vielen Usern nicht zuzumuten. Häufig müssen in Projekten nicht nur Datenbankadministratoren, sondern auch Helpdesk-Mitarbeiter, Geschäftsanalysten und Wirtschaftsprüfer einsehen können, was in den Protokollen steht – und jede dieser Gruppen hat unterschiedliche Erwartungen, wie sie an die Daten gelangt.
Mithilfe der Log-Pipeline lassen sich die Anforderungen der unterschiedlichen Nutzergruppen jederzeit und nachvollziehbar in geeigneter Form aufbereiten und in den zugehörigen Zielen bereitstellen. So lässt sich etwa das Logging einer Pipeline automatisiert für drei verschiedene Zielgruppen aufbereiten und zur Verfügung stellen.
Mehr Flexibilität dank Run Configurations
Eine essenzielle Frage vor jedem Datenprojekt ist, in welcher Umgebung die erstellten Daten-Pipelines laufen sollen. Die dafür notwendigen Entscheidungen lassen sich aber häufig noch gar nicht vor dem Projektstart treffen. Reicht es, die Pipelines auf einem lokalen Server laufen zu lassen? Wachsen die Daten so schnell, dass man gleich auf Apache Spark oder auf Google DataFlow setzen sollte? Viele Anforderungen ändern sich während eines Projekts. Gerade in der agilen Entwicklung kann es sich schnell als Problem erweisen, wenn man auf die falsche Umgebung gesetzt hat.
Apache Hop empfiehlt sich in dieser Situation aufgrund seiner Flexibilität. Data Engineers können auf der Plattform ihre Umgebungen frei wählen und jederzeit ändern. Über Run-Konfigurationen lassen sich sowohl die Fähigkeiten von Hop als auch anderer Plattformen wie Apache Beam und vergleichbaren nutzen. Datenteams entwerfen einmalig ihre gewünschten Hop-Workflows und -Pipelines und können diese anschließend überall dort ausführen, wo sich die zu verarbeitenden Daten am sinnvollsten anwenden lassen.
Blick nach vorn
Wie sehen die nächsten Schritte bei der Weiterentwicklung von Apache Hop aus? Nach Einschätzung des Autors stehen drei wichtige neue Features auf der Roadmap. Punkt eins ist die Erstellung eines neuen Softwaremarktplatzes, auf dem Plug-ins von Drittanbietern zu finden sind. Dabei kann es sich beispielsweise um Verbindungen zu weiteren Datenbanken, neue Transformationsmöglichkeiten und Verbindungen zu Anwendungen großer ERP-Anbieter handeln. Laut den Hop-Entwicklern soll zudem Apache Airflow als weitere Workflow-Engine integriert werden, um mehr Flexibilität bei deren Ausführung zu bieten. Drittens soll es in Zukunft eine neue GUI zum Anzeigen der Vorschau und zum Debuggen von Pipelines und Workflows unter Berücksichtigung lang andauernder und Streaming-Workloads geben.
Übersicht über die Datenprozesse
Datenprozesse müssen einfach zu entwerfen, simpel zu testen, schnell auszuführen und rasch bereitzustellen sein. Durch die visuelle Drag-and-drop-Benutzeroberfläche ermöglicht es Apache Hop Personen aller Qualifikationsstufen, produktiv mit Daten zu arbeiten, ohne Code schreiben zu müssen. Damit empfiehlt sich das Open-Source-Projekt Apache Hop als vielversprechende Option für anspruchsvolle Datenprojekte. In der kurzen Zeit, die das Projekt zur Verfügung steht, hat es auf jeden Fall das Arbeitsleben des Autors dieses Beitrags spürbar bereichert. Die Plattform dürfte insbesondere für Nicht-Hardcore-Entwickler interessant sein, die selbst eigene Daten-Pipelines erstellen wollen.
Die Datenwelt wird sich auch in Zukunft schnell weiterentwickeln. Um auf den Fortschritt von Cloud-Umgebungen und Laufzeitumgebungen gezielt reagieren zu können, ist es ratsam, auf eine flexible Open-Source-Plattform zu bauen, die sich durch metadatengetriebene Plug-ins jederzeit der sich schnell ändernden Technologielandschaft anpasst.
Wer Interesse an Apache Hop hat und einen detaillierten Einblick in die Software und deren Möglichkeiten gewinnen möchte, sollte an einem der nächsten Apache-Hop-User-Meetups teilnehmen. Dort lernt man die deutschsprachige Hop-Community sowie Entwicklerinnen und Entwickler persönlich kennen. Weitere Informationen sowie Videoaufzeichnungen vergangener Apache-Hop-User-Meetings finden sich in der Terminübersicht bei it-novum [3].
Philipp Heck
arbeitet seit 2014 als Senior Consultant im Bereich Data Engineering und Data Analytics bei it-novum. In dieser Funktion betreut er Projekte im Bereich Business Analytics, Data Warehousing, Datenintegration und Planung.
(map [4])
URL dieses Artikels:
https://www.heise.de/-7222047
Links in diesem Artikel:
[1] https://www.heise.de/news/Datenintegration-Grosser-Schritt-zur-Version-2-0-bei-Apache-Hop-7131245.html
[2] https://hop.apache.org/
[3] https://data.it-novum.com/termine/
[4] mailto:map@ix.de
Copyright © 2022 Heise Medien