

Arbeit teilen
Für die freie Datenbank MySQL gibt es verschiedene Verfahren, Replikation zu implementieren. Sie unterscheiden sich sowohl im Komfort als auch in der Fähigkeit, die Datenintegrität zu bewahren.
- Erkan Yanar
Hochverfügbarkeit (HA) und Skalierung spielen für anspruchsvollere MySQL-Installationen eine wichtige Rolle. Gerade das Skalieren von Lesezugriffen via Replikation trug wesentlich zum Erfolg von MySQL als Verwalter großer Datenmengen bei. Dieser Artikel gibt einen Überblick über gängige freie HA-Produkte für MySQL.
Skalierung bedeutet im Folgenden, die Last auf mehrere Rechner zu verteilen. Hochverfügbarkeit steht zum einen für Verfügbarkeit der Daten. So dürfen etwa beim Absturz eines Rechners keine Daten verloren gehen. Zum anderen bezieht sich der Begriff auf den Dienst selbst, der möglichst unterbrechungsfrei bereitstehen soll.
MySQL-Replikation ist die klassische, uni-direktionale Hochverfügbarkeitstechnik: Änderungen schreibt der Server in das Bin-Log des Master; von dort kopiert sie der Slave in sein Relay-Log. Sein SQL-Thread liest sie und überträgt sie in die Datenbank. MySQL unterscheidet zwischen semisynchroner und asynchroner Replikation. Bei der asynchronen landen die Daten nach dem Commit im Bin-Log, der Slave holt sie irgendwann dort ab. Bei der semisynchronen Replikation hingegen kommt das Commit erst zurück, wenn die Daten im Relay-Log eines Slave stehen (Abb. 1). Sie bezahlt diese Gewissheit mit Latenz.
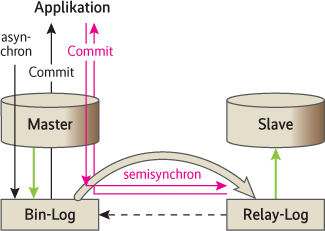
Viele Anwender nutzen Replikation, um Lesezugriffe zu skalieren: Nicht nur der Master, sondern auch alle Slaves können Daten liefern. Zudem lässt sich die durch die Replikation entstehende Datenredundanz gewinnbringend für die Verfügbarkeit nutzen.
Asynchrone Replikation ist in puncto Hochverfügbarkeit der Daten nur ein „best effort“, da nach einem Commit nicht alle Daten bei einem Slave angekommen sein müssen. Bei der semisynchronen Replikation liegen die Daten zumindest schon im Relay-Log des Slaves, bevor die Transaktion als beendet gilt (s. Abb.2). So kurz die Zeitspanne zwischen dem Schreiben in das Relay-Log bis zur Ankunft in der Datenbank sein mag, muss eine HA-Implementierung sie doch berücksichtigen. Eine einfache Variante, einen hochverfügbaren Dienst zu gewährleisten, benutzt für die Anwendung eine virtuelle IP-Adresse (VIP). Bei einem Failover ist sie auf dem übernehmenden Slave zu aktivieren, wenn sichergestellt ist, dass er alle Transaktionen aus dem Relay-Log ausgeführt hat. Das verhindert Datensalat.
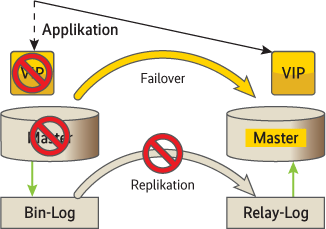
IP-Adresse zeigt (Abb. 2).
Der sich etablierende Standard für alle hochverfügbaren Dienste unter Linux ist wohl das freie Pacemaker/Corosync. Hier kümmern sich sogenannte Resource Agents (RA) um die zu überwachenden Dienste. Pacemaker ist sehr leistungsfähig und für viele verschiedene Szenarien einsetzbar. So kann es mit einem Resource Agent die VIP verwalten und mit einem anderen die MySQL-Server überwachen. Fällt einer von ihnen aus, schwenkt Pacemaker die VIP auf einen funktionsfähigen Slave.

Die Tabelle „Vergleich der MySQL-Replikationsverfahren“ stellt die im Folgenden präsentierten Produkte und Methoden gegenüber. Sie vergleicht SQL und Schema-Design, Implementierung von Hochverfügbarkeit und Administration. Hierbei ist berücksichtigt, das InnoDB derzeit die Default Storage Engine für MySQL ist.
MMM
Master-Master Replication Manager (MMM) existiert schon länger und verwaltet einen Master samt mehreren Slaves. Anders als Pacemaker ist es speziell für und um MySQL geschrieben. Das muss allerdings nicht heißen, dass es dafür besser geeignet ist. MMM bringt eine eigene HA-Software mit und kümmert sich gar nicht um Datenkonsistenz: Es konzentriert sich nur auf die Verfügbarkeit des Services und nicht auf die der Daten.
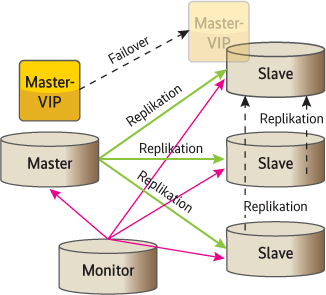
propagiert es einen der Slaves zum neuen Chef aller Nodes (Abb. 3).
Sei beispielsweise ein Master (M) mit drei Slaves (S1, S2, S3) gegeben (s. Abb.3). Bei seinem Ausfall haben die Daten auf allen Slaves einen unterschiedlich großen Rückstand bezogen auf M. Ist der Abstand für S1 am geringsten, macht MMM ihn zum Master, indem er die VIP an S1 hängt. S2 und S3 bleiben Slaves mit dem neuen Master S1, sie ziehen jedoch nicht automatisch dessen neuere Daten nach. Bei diesem Prozedere gehen sämtliche Daten verloren, die S1 noch nicht gesichert hat. Deshalb sollte man auf MMM verzichten.
MHA
MHA (MySQL Master High Availability Manager and Tools) funktioniert prinzipiell ebenso wie MMM. So bringt es sein eigenes HA/Monitoring mit. Anders als MMM gewährleistet MHA, dass bei einem Ausfall des Masters alle Slaves auf demselben Stand sind wie derjenige mit dem geringsten Rückstand. So würden im obigen Beispiel S2 und S3 erst Daten von S1 einspielen, bevor sie zu seinen Slaves werden. Das stellt zumindest sicher, dass alle Slaves mit demselben Datenstand arbeiten. Ein Rückstand gegenüber dem ausgefallenen Master bleibt jedoch bestehen.
DRBD/SAN
Shared Storage, etwa ein SAN (Storage Area Network) oder DRBD (Distributed Replicated Block Device), ist eine weitere Möglichkeit, Daten hochverfügbar zu halten. Hier ist das Storage-System alleine für die Hochverfügbarkeit verantwortlich. Deshalb muss MySQL so konfiguriert sein, dass jedes Commit sicher in der Speicherschicht ankommt – es reicht nicht, dass es im Cache des Dateisystems steht. Anders als bei der Replikation sind Slaves nicht einmal zum Lesen nutzbar. Kommt es bei einem Datenbank- oder Serverabsturz zu einem Failover, führt der startende MySQL-Daemon erst ein Recovery der Datenbank durch. Das dauert und ist nicht zwangsläufig erfolgreich. Bei einem Fehler ist kein Failover möglich, und der ganze Cluster steht.
Nach einem erfolgreichen Recovery startet die Datenbank mit einem leeren Cache, dem sogenannten Buffer-Pool. Deshalb dauert es nach dem Starten des MySQL-Servers noch, bis die genutzten Daten darin vorliegen, die Datenbank sozusagen ihre „Betriebstemperatur“ erreicht hat und Anfragen so schnell wie vorher beantwortet.
Daher ist im Vergleich zur Replikation von einer längeren Stillstandszeit auszugehen, und es dauert ebenfalls länger, bis die durchschnittliche Leistung wieder erreicht wird. Unter Linux werden Shared-Nothing-Installationen wie diese mit Pacemaker/Corosync zum Verwalten von DRBD, VIP, MySQL und Stonith (Shoot the other server in the head) genutzt. Das Stonith-Verfahren schaltet den alten Server zuverlässig ab.
MySQL-NDB-Cluster
Ein MySQL-NDB-Cluster besteht aus drei Komponenten, zum Verständnis der Funktionsweise braucht man jedoch nur die Storage- und API-Nodes zu betrachten. Auf ihnen läuft jeweils der NDB- beziehungsweise der MySQL-Daemon. MySQL-Server greifen via TCP/IP auf die Storage-Nodes zu, auf denen die Daten verteilt liegen.
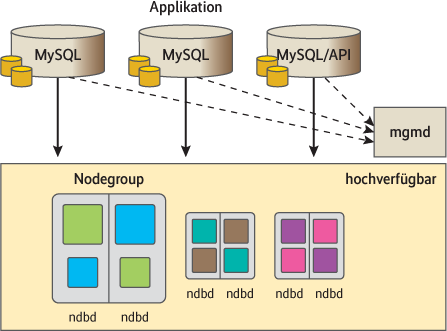
sich auf den Storage-Knoten, und nur diese sind hochverfügbar (Abb. 4).
Gemeinhin teilt man Storage-Nodes in Paare auf, sogenannte Node Groups. Jedes Paar spiegelt seine Daten gegenseitig (s. Abb. 4). Änderungen durchlaufen das Paar in einem zweistufigen Commit, sodass man von einer synchronen Replikation sprechen kann. Dabei werden erst die Transaktionen auf den Nodes bis zum Commit ausgeführt (1. Phase). Die Knoten signalisieren das Erreichen dieses Stadiums dem Master. Liegen von allen Nodes Bestätigungen vor, schickt er ihnen die eigentliche Aufforderung zum Commit (2. Phase).
Den Ausfall eines Node fängt der Partner auf, und beim erneuten Start synchronisiert ein Knoten seine Daten online vom Partner. Auch das Hinzufügen neuer Pärchen kann online geschehen. Statt „online“ ist häufig der Begriff „Rolling Restart“ zu hören. Er bezeichnet, dass der Cluster als Ganzes während des Neustarts einzelner Komponenten funktionsfähig bleibt.
Den Zugriff auf die Storage-Nodes kann man auf mehrere MySQL-Server verteilen, die im laufenden Betrieb hinzugefügt werden können. Aus Anwendungssicht sieht der Zugriff auf die Speicherknoten so aus wie der auf die Datenbank. Einziger Unterschied: Beim Anlegen der Tabellen ist die Storage Engine NDB zu wählen.
CREATE TABLE daten (...)
ENGINE=NDB
Allerdings unterliegt die NDB-Engine Einschränkungen gegenüber dem üblichen InnoDB. Sie unterstützt keine Fremdschlüssel-Constraints, und Joins dauern länger – vor allem komplexe. NDB eignet sich gut für solche Anwendungen, die meist direkt per Schlüssel auf die Daten zugreifen.
Ein NDB-Cluster bietet keine Hochverfügbarkeit des Dienstes. Der Ausfall eines Servers gefährdet zwar nicht die Hochverfügbarkeit der Daten, man sollte ihn jedoch abfangen, um den eigentlichen Service verfügbar zu halten. Hierfür bieten sich virtuelle IP-Adressen oder einfache Load-Balancer an.
Galera
Galera ist eine Replikationstechnik von Codership, die als Patch für den MySQL-Server zur Verfügung steht. Dadurch sind die Server selbst replikationsfähig. Galera verspricht synchrone Replikation und eine Multimaster-Topologie für InnoDB-Tabellen. Deshalb lassen sich Daten auf jeden Node im Cluster schreiben (Multi-Master), und anders als bei der MySQL-Replikation ist die Hochverfügbarkeit der Daten gewährleistet. Das vermeidet Schwierigkeiten wegen auf den Slaves fehlender Daten. Da alle Nodes schreiben können, entfällt der Aufwand für das Weiterleiten geänderter Daten vom Master zum Slave. DRBD/SAN-Methoden versprechen zwar einen Failover ohne Datenverlust, bezahlt wird dies jedoch mit Zeitaufwand für das Recovery und das Füllen des Buffer Pool beim Umschalten. Auch kann es vorkommen, dass die Datenbank nicht wiederherzustellen ist – dann steht der ganze Cluster. Galera hingegen wechselt die Applikation immer auf einen schon laufenden Node. Wartezeiten wie bei Shared Storage fallen nicht an.
Weitere Besonderheiten von Galera sind der State Snapshot Transfer (SST) und der Incremental State Transfer (IST). SST synchronisiert einen Node mit dem Datenbestand des Clusters. Dadurch lassen sich neue Nodes leicht automatisch in den Clusterverbund einbinden. Derzeit gibt es SST-Skripte, die Daten via mysqldump, rsync oder xtrabackup synchronisieren.
Für den IST nutzt Galera einen konfigurierbaren, lokalen Cache, der die letzten Transaktionen vorhält. Kommt ein neuer oder neugestarteter Knoten in den Cluster, und die fehlenden Daten liegen in diesem Cache, führt Galera einen IST statt eines SST durch. Dies ist gerade bei großen Datenbanken attraktiv – 50 MByte Transaktionen sind schneller übertragen als 500 GByte Daten. Zumal Letzteres zurzeit noch den Sender („Donor“) blockiert. So ist das Restarten eines MySQL-Servers wegen einer Konfigurationsänderung oder eines Upgrades schnell erledigt, weil ein schneller IST statt eines vollständigen SST das Synchronisieren übernimmt. Die Hochverfügbarkeit des Dienstes lässt sich am einfachsten mit einem Load-Balancer erreichen. Eine Alternative dazu wäre Pacemaker.
Galera ist alternativ zum Multi-Master-Modus, in dem alle Nodes Daten schreiben dürfen, als einfacher Replikationsersatz verwendbar. Hierbei schreibt nur der Master Daten, wodurch clusterspezifische Limitierungen entfallen (siehe Tabelle). Unter anderem funktionieren LOCK TABLES und SELECT FOR UPDATE, sodass die Tabelle/Zeilen garantiert gesperrt sind. Im Multi-Master-Modus ist dies nicht der Fall.
Fazit
Es gibt viele Möglichkeiten, MySQL hochverfügbar zu betreiben. Das für den NDB-Cluster benötigte Know-how ist nicht oft anzutreffen. Er lohnt sich vor allem für schreibintensive und stark parallelisierte Applikationen, die einen hohen Durchsatz brauchen.
Für allgemeine Einsatzzwecke lässt sich die Verfügbarkeit der Daten entweder durch die MySQL-Replikation oder durch DRBD gewährleisten. Die eingebaute Replikation bietet den Vorzug, dass alle Slaves Daten liefern können. Das Umschalten auf einen der Slaves erfolgt immer auf eine laufende MySQL-Instanz mit den Daten im Arbeitsspeicher. Wer die Replikation der Daten via DRBD oder im SAN für sicherer hält als die MySQL-Replikation, nimmt diese Lösung. Vor allem das Synchronisieren der Daten nach dem Umschalten verlangt bei DRBD kein MySQL-Know-how und ist eine typische Aufgabe des Systemadministrators.
Galera ist die jüngste Möglichkeit, MySQL hochverfügbar zu betreiben. Seine eigene Replikation ermöglicht es wie beim NDB-Cluster, auf alle Nodes schreibend zuzugreifen. Die beiden sind zudem die einzigen Produkte, die Rolling Upgrades und Rolling Restarts ermöglichen. Wer sich auf InnoDB als Storage Engine beschränken kann, erhält mit Galera eine synchrone Replikation, die sicherer und leistungsfähiger als die semisynchrone Replikation von MySQL ist. Applikationen, die SELECT FOR UPDATE intensiv nutzen, können Galera im Ein-Master-Modus betreiben. Somit entfallen Limitierungen für LOCK TABLES und SELECT FOR UPDATE. Zum Lesen lassen sich weiterhin alle Rechner nutzen.
Erkan Yanar
ist Diplom-Soziologe und arbeitet als DBA-Consultant.
iX-TRACT
- MySQL bringt von Haus aus asynchrone und semisynchrone Replikation mit. Damit lassen sich Lesezugriffe beschleunigen und die Datenverfügbarkeit verbessern.
- Darauf aufsetzende Verfahren gewährleisten nicht immer die Konsistenz der Daten.
- Das freie Galera bietet sowohl Multi- als auch Single-Master-Replikation. Es erlaubt wie der NDB-Cluster das Hinzufügen von Knoten im laufenden Betrieb.
Split Brain, Fencing, Quorum
Split Brain ist ein Zustand in einem Cluster, bei dem die Nodes voneinander getrennt sind und jeder Teil den Dienst unabhängig weiter bedient. So ist nicht mehr klar geregelt welche Datenbank den relevanten Datensatz hat. Die beiden Strategien „Fencing“ und „Quorum“ sollen Datendefekte verhindern.
Beim Quorum (Mehrheitsentscheid) muss jeder Node immer die Mehrheit seiner Kollegen im Cluster sehen können, damit er sich nicht abschaltet. Daher wird immer eine ungerade Anzahl von Voting-Teilnehmern benötigt, sodass eine eindeutige Mehrheit zustande kommen kann. Eine alternative Methode ist das Fencing (Einzäunen). Dabei sperrt man einen Node so ein, dass er nicht mehr auf Ressourcen zugreifen, geschweige denn welche anbieten kann.
Stonith (Shoot The Other Node In The Head) ist eine Technik, Nodes aus dem Cluster zu werfen. Übernimmt ein Node aufgrund eines Failover die Ressourcen, kann er damit sicher gehen, dass der alte Knoten wirklich aus dem Cluster verschwindet. Es gibt viele Stonith-Implementierungen, etwa indem man sich mit dem ILO-Board (Integrated Lights-Out) verbindet und den Node runterfährt.
Galera und der NDB-Cluster benutzen die Quorum-Technik, MHA bringt optional eine Fencing-Option mit. DRBD/SAN, das klassisch auf zwei Nodes läuft, sollte man mit Fencing konfigurieren.
(ck)
