Benchmarking Spark: Wie sich unterschiedliche Hardware-Parameter auf Big-Data-Anwendungen auswirken
Dank leistungsfähiger Hadoop-Distributionen ist es einfach geworden, ein komplettes Hadoop/Spark-Cluster in der Cloud zu installieren. Schwieriger wird es jedoch, die optimale Konfiguration der virtualisierten Cloud-Hardware für den jeweiligen Anwendungsfall zu finden, denn unterschiedliche Hardwarekonfigurationen können sich sehr wohl auf das Verhalten von Spark-Anwendungen im Cluster-Betrieb auswirken.


Dank leistungsfähiger Hadoop-Distributionen ist es einfach geworden, ein komplettes Hadoop/Spark-Cluster in wenigen Stunden in der Cloud zu installieren. Schwieriger wird es jedoch, die optimale Konfiguration der virtualisierten Cloud-Hardware für den jeweiligen Anwendungsfall zu finden, denn unterschiedliche Hardwarekonfigurationen können sich sehr wohl auf das Verhalten von Spark-Anwendungen im Cluster-Betrieb auswirken.
Benchmark bezeichnet im Allgemeinen das Vermessen eines Systems. Dabei werden Mess- und Bewertungsverfahren gebildet, um die Qualität und die Leistungsfähigkeit des zu prüfenden Systems mit Kennzahlen beurteilen zu können. Wichtig dabei: Der Benchmark muss sich jederzeit wiederholen lassen, um objektive, valide und verlässliche Daten liefern zu können. Benchmarks informationsverarbeitender Systeme bestehen zumeist aus einzelnen oder Gruppen von Programmen, welche die Leistungsfähigkeit des Systems wiederholbar und übertragbar messen können.
Apache Hadoop wurde einer breiteren Öffentlichkeit bekannt, als es Yahoo 2008 damit gelang, den Terabyte Sort Benchmark [1] zu gewinnen [2]. Seit dieser Zeit sind weitere Hadoop-spezifische Benchmarks hinzugekommen, welche die unterschiedlichen Anforderungen an ein verteiltes System darstellen und vergleichbar machen sollen. Einer der vielseitigsten ist die Benchmark-Suite HiBench [3], die der Prozessorhersteller Intel als Referenz für die Messung von Hadoop- und Spark-Clustern unter der Apache-Lizenz zur Verfügung gestellt hat. In der aktuellen Version 4.0 werden zehn typische Workloads vermessen, die die Bandbreite aller möglichen Arten von Big-Data-Anwendungen abdecken sollen.
HiBench eignet sich gut dazu, die Leistung unterschiedlicher Cluster-Konfigurationen (Anzahl Nodes, CPU-Kerne, Netzwerk- und Storage-I/O etc.) miteinander zu vergleichen [4]. Wer jedoch nur seine eigene Spark-Anwendung auf ihr Performanceverhalten in verschiedenen Cluster-Konfigurationen prüfen möchte, wird andere Lösungen finden müssen. Bevor auf das Vorgehen dabei eingegangen wird, sollen hier aber die wichtigsten Architekturbestandteile einer Spark-Anwendung zusammengefasst werden.
Architektur von Spark
Apache Spark [5] ist ein Framework zur schnellen Analyse großer Datenmengen innerhalb eines Rechner-Clusters. Seine Stärken liegen dabei in der Nutzung des Hauptspeichers, um während der Verarbeitung schneller Zugriff auf Daten und Strukturen zu haben.
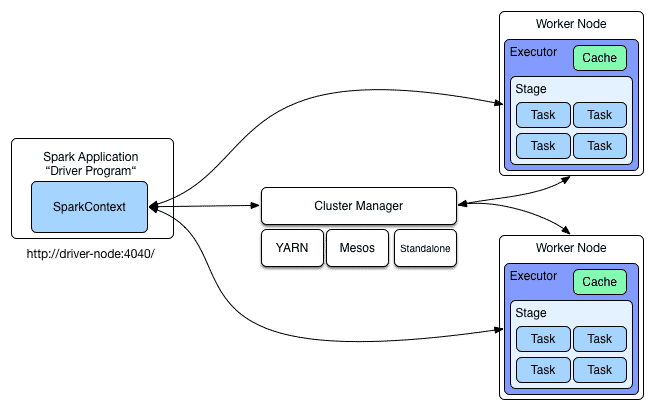
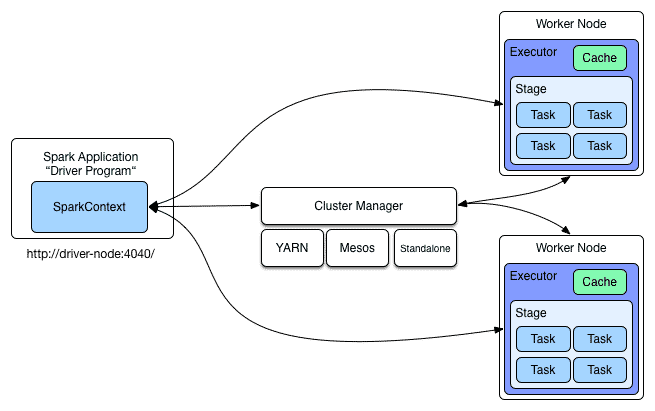
Ein Rechner-Cluster, auf dem Spark zur Ausführung kommt, besteht aus einer Menge einzelner Computersysteme, die über Netzwerkkomponenten verbunden sind. Das System lässt sich als Ansammlung von Ressourcen wie CPUs, Hauptspeicher, Festplatten und Netzwerkverbindungen betrachten. Das Verwalten der Ressourcen überlässt Spark der Cluster-Management-Software. Das Framework kann dabei sowohl allein als auch im Zusammenspiel mit YARN (Yet Another Resource Negotiator) oder Mesos betrieben werden.
Die Schnittstelle zwischen einer Spark-Anwendung und dem Cluster-Manager stellt der sogenannte SparkContext dar. Über ihn verteilt Spark sogenannte Executors auf die einzelnen Rechnersysteme im Cluster, um auf ihnen die Datenverarbeitung ausführen zu können.
Zur Messung der Leistungsfähigkeit eines Spark-Clusters ist es wichtig, die grundlegende Architektur und die Verarbeitung der Daten innerhalb des Spark-Systems zu verstehen. Ein kleiner Rundgang soll sowohl in die Termini als auch in die Besonderheiten der Spark-Architektur einführen.
Im Kern verwaltet und verarbeitet Spark seine Daten als sogenannte Resilient Distributed Datasets (RDDs). Diese verarbeiten Daten verteilt mithilfe zweier unterschiedlicher Arten von Operationen:
- Transformationen ermöglichen die Verarbeitung von Ausgangsdaten in Zieldaten zum Beispiel mit Filter- oder Gruppierungsfunktionen. Transformation liefern als Ergebnis immer ein RDD zurück. Bei Spark spricht man dabei oft von Parent RDDs, die einen Child RDD erzeugen. Transformationen lassen sich verketten. Als Ergebnis davon erzeugt Spark einen Directed Acyclic Graph (DAG), der zur Ausführungszeit abgearbeitet wird.
- Actions dagegen liefern nach ihrer Ausführung einen einzigen Ergebniswert zurück. Als Beispiel soll hier die Anzahl von Datenelementen stehen, die gezählt werden sollen (count).
Richtig schnell macht Spark dabei der Umstand, dass im Gegensatz zum Map-Reduce-Algorithmus von Hadoop die Daten nicht zwingend nach jedem Mapper- oder Reducer-Task auf eine Festplatte zwischenzuspeichern sind, sondern sich im Speicher des Clusters verteilen können. Deshalb spricht man von Spark auch als "In-Memory-Datenanalysesystem".
Das gilt jedoch nicht für alle Operationen, die Spark auf großen Datenmengen anwenden kann. Je nach Art und Umfang der zu verarbeitenden RDDs muss auch Spark die Daten auf dem lokalen System zwischenspeichern und gegebenenfalls über das Netzwerk auf einen anderen Knoten verschieben. Dieser als "shuffle" bezeichnete Zustand von Spark ist der große Zeitfresser beim Verarbeiten von Daten in RDDs.
Programmatisches
Wie werden Programme ausgeführt?
Jede Spark-Anwendung besteht aus einem Driver-Programm und einem Set von Executors, verteilt über die Worker Nodes des Spark-Clusters. Das Driver-Programm kümmert sich dabei um die Konfiguration und den Kontrollfluss der Spark-Anwendung. Folgendes Beispiel soll das illustrieren.
val conf = new SparkConf()
.setMaster("master_url") // URL des Masterknoten
.setAppName("SparkExamplesMinimal") // Anwendungsname
val sc = new spark.SparkContext(conf) // SparkContext initialisieren
// ...
Im Beispiel initialisiert das Driver-Programm einen SparkContext, um mit dem Cluster interagieren zu können. Darüber hinaus enthält es die Definition der RDDs, die wiederum die einzelnen Actions und Transformationen auf den Daten definieren. Das Driver-Programm serialisiert dabei den entstehenden Graphen und schickt ihm zum Spark-Masterknoten.
Bei der Programmausführung wird die logische Transformation der Daten über die einzelen Operationen in einen Execution Plan überführt. Einzelne Executors führen die einzelnen Operationen auf einem Rechnerknoten aus. Ein Job enthält alle Tasks die für die Ausführung einer Action benötigt werden. Aufeinander folgende Tasks die von einem Job ausgeführt werden, nennt man in Spark Stages.
Das folgende Beispiel zählt die Wörter eines Texts. Die letzte Operation collect() konvertiert den resultierenden RDD in ein Scala-Array und liefert dieses zurück. RDDs lassen sich mit toDebugString() darstellen.
// ...
// RDD to read input file
val textFile = sc.textFile("/Users/rwartala/Documents/Quellcodes/spark
/20000miles-under-the-sea.txt")
// RDD as a result of a map transformation
val lineLengths = textFile.map(s => s.length)
// persits lineLength in memory
lineLengths.persist()
// Split into words and remove empty lines
val tokenized = textFile.filter(line => line.size > 0).map(line
=> line.split(" "))
// Extract the first word from each line (the log level) and do a count
val counts = tokenized.map(words=>(words(0),1)).reduceByKey{(a,b)=>a+b}
val wordCount = counts.collect()
Ein scala> counts.toDebugString liefert folgende Ausgabe:
res16: String =
(2) ShuffledRDD[6] at reduceByKey at :25 []
+-(2) MapPartitionsRDD[5] at map at :25 []
| MapPartitionsRDD[4] at map at :23 []
| MapPartitionsRDD[3] at filter at :23 []
| MapPartitionsRDD[1] at textFile at :21 []
| /Users/rwartala/Documents/Quellcodes/spark/
20000miles-under-the-sea.txt HadoopRDD[0] at textFile at :21 []
Über die Spark-Weboberfläche lässt sich sich der Job im Detail untersuchen und auch der DAG grafisch anzeigen.
Sobald innerhalb eines Driver-Programms eine Action aufgerufen wird, erzeugt Spark einen neuen Job. Je nach Execution Plan des zu verarbeitenden RDDs werden einzelne Stages erzeugt, die wiederum einzelne Task auf den Rechnerknoten mit den Executors gegebenenfalls parallel ausführen können. Damit sich diese Operationen parallel erledigen lassen, müssen sich die Daten auf den Rechnern zur Ausführung bereit befinden.
RDDs verwalten die Daten in Form sogenannter Partitions. Jede Partition enthält dabei einen Teil der Daten. Vorstellen lassen sie sich als Teile einer großen Liste. Die Daten innerhalb einer Partition werden sequenziell verarbeitet. Die Partitionen lassen sich hingegen über die Task der Executors parallel durchführen. Folgendes Beispiel soll das veranschaulichen: Der Befehl
val rdd = sc.textFile("hdfs://192.168.172.56/Users/rwartala/
Documents/Quellcodes/spark/20000miles-under-the-sea.txt")
erzeugt einen RDD aus der Textdatei, die sich im Hadoop-Dateisystem befindet. Ein
val tokenized = textFile.filter(line => line.size > 0).map(line
=> line.split(" "))
splittet die Datei in einzelne Partitionen auf, damit sich diese parallel verarbeiten lassen. Wenn die Daten aus Hadoop kommen, ist die Partitionsgröße in der Regel gleich der Größe eines HDFS-Blocks.
Um die ideale Laufzeitumgebung für die eigene Spark-Anwendung zu finden und das Zusammenspiel von Hauptspeicherbedarf, Netzwerk- und Storagedurchsatz zu untersuchen, wäre eine Testumgebung nötig, die sich in diesen Hardwareparametern individuell konfigurieren lässt. Das wird erst seit dem Aufkommen von Cloud-Anbietern und der Virtualisierung von Hardware-Ressourcen möglich.
Testumgebung in der Cloud
Dank Cloud-Anbietern muss man sich nicht selbst die teure Hardware anschaffen und installieren, um ein Rechen-Cluster betreiben zu können. Spark liefert mit spark-ec2 ein Skript, mit dem sich Amazons Elastic Compute Cloud als Cluster-System nutzen lässt.
Mit einem gültigen AWS-Konto kann man mit spark-ec2 vollständig automatisiert ein Cluster konfigurieren, die nötige Software installieren und seine Spark-Anwendungen ausführen. Dazu übergibt man dem Skript eine Reihe von Parametern. Mit ihnen lassen sich nicht nur die Region der Installation bestimmen (z.B. eu-central-1 für Frankfurt, ap-northeast-1 für Tokio oder us-west-1 für Kalifornien), sondern auch die Anzahl und Leistungsfähigkeit der zu startenden Computing-Hardware und des Storage.
Folgender Beispielaufruf soll die Anwendung illustrieren. Dem Skript übergibt man als Erstes die Zugangsschlüssel für den Login und wählt danach die Region und die Zone von Amazons Rechenzentrum aus. Die Parameter --instance-type und --slaves bestimmen dann den Typ der Hardware und die Anzahl der zu nutzenden Worker Nodes.
$ export AWS_ACCESS_KEY_ID=MEIN_AWS_ACCESS_KEY
$ export AWS_SECRET_ACCESS_KEY=MEIN_AWS_SECRET_ACCESS_KEY
$SPARK_HOME/ec2/spark-ec2
--key-pair=data2day-benchmark
--identity-file=data2day-benchmark.pem.txt
--region=eu-west-1 --zone=eu-west-1a
--instance-type=m1.large
--slaves=2
--hadoop-major-version=yarn
--spark-version=1.4.1 launch data2day-spark-cluster
Mit den letzten beiden Optionen --hadoop-major-version und --spark-version wählt man die zu installierende Hadoop- und Spark-Version aus. Der Befehl launch startet dann das Cluster mit dem angegebenen Namen data2day-spark-cluster. Je nach gewählter Anzahl Worker Nodes kann die Instanziierung des Clusters einige Minuten in Anspruch nehmen. Ab jetzt kostet die Nutzung von Amazons Cloud-Infrastruktur Geld und kann je nach gewählter Region und Instanztypen wenige bis einige Dollars kosten [6].
Ist das Skript fertig, lässt sich die Spark-Web-UI über http://ec2-52-18-92-74.eu-west-1.compute.amazonaws.com:8080 öffnen.
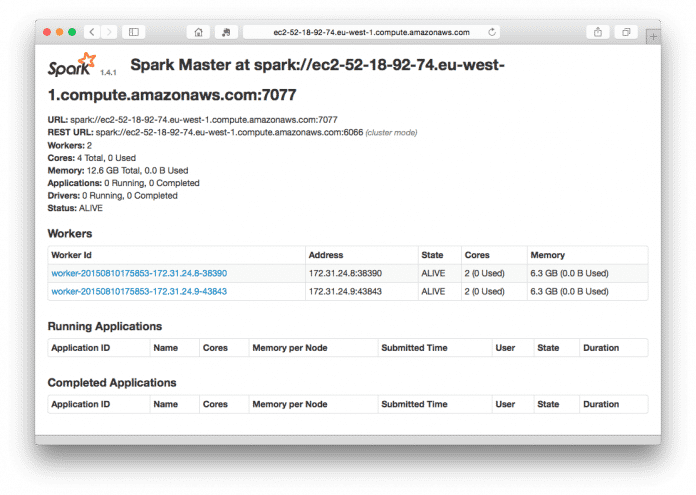
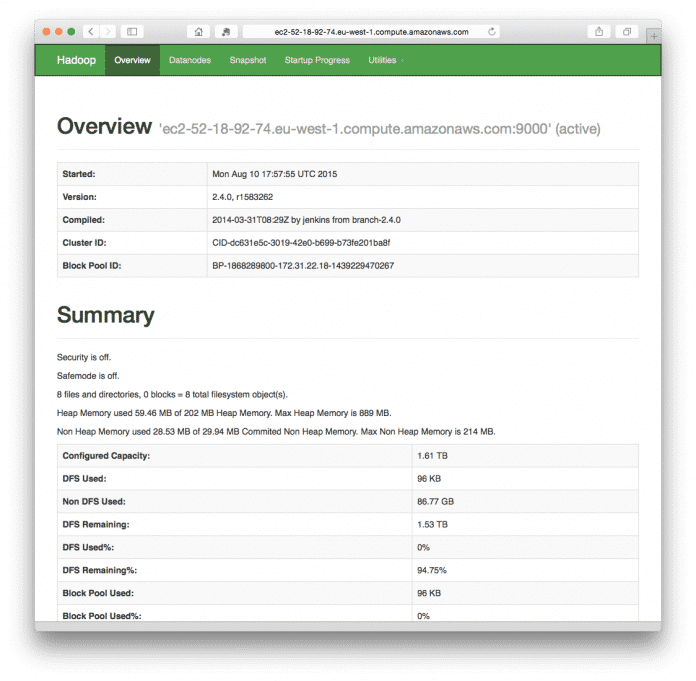
Gleichzeitig mit der Spark-Installation wurde ein vollständiges Hadoop Distributed File System (HDFS) auf dem gleichen Knoten gestartet. Es ist über die Portnummer 50070 zugänglich mit http://ec2-52-18-92-74.eu-west-1.compute.amazonaws.com:50070/dfshealth.html#tab-overview.
Login und Logout
Um das Cluster nutzen zu können, muss man sich auf ihm mit dem login-Befehl anmelden.
spark-ec2
--key-pair=data2day-benchmark
--identity-file=data2day-benchmark.pem.txt
--region=eu-west-1 --zone=eu-west-1a login data2day-spark-cluster
Nach dem Login findet man sich auf dem Master Node wieder und kann dort sowohl das Cluster-Dateisystem über den hdfs-Befehl als auch Spark-Anwendungen mithilfe von spark-submit verteilen und ausführen. So lässt sich das Beispielprogramm zur Berechnung von Pi mit dem folgenden Code starten:
./spark/bin/spark-submit
--master spark://ec2-52-19-33-37.eu-west-1.compute.amazonaws.com:7077
--deploy-mode cluster
--name "SparkPi program"
--class org.apache.spark.examples.SparkPi
/root/spark/lib/spark-examples-*.jar 1000
Um das Cluster zu beenden, reicht die Ausführung des spark-ec2-Skripts via Aufruf von destroy.
spark-ec2
--key-pair=data2day-benchmark
--identity-file=data2day-benchmark.pem.txt
--region=eu-west-1
--zone=eu-west-1a destroy data2day-spark-cluster
Dabei werden alle Worker Nodes terminiert, und es sind keine Gebühren mehr fällig.
Mit spark-ec2 lässt sich eine Reihe unterschiedlicher Cluster-Konfigurationen auf einfache Art und Weise nutzen. Es eignet sich als günstige Testumgebung, um Maschinen mit mehr Hauptspeicher und Maschinen mit schnellerem Storage (z. B. SSDs) für die eigene Spark-Anwendung zu konfigurieren.
Dependencies
Nah oder weit?
Die Spark-Web-UI ist für die Analyse der Jobs der erste Ausgangspunkt. Hier lässt sich die Ausführung der Jobs, ihrer einzelnen Stages im Zusammenspiel mit dem Storage, der Spark-Umgebung und den Exekutoren untersuchen. Die Spark-API ermöglicht es Entwicklern, mithilfe der verschiedenen Transformations und Actions Daten auf verschiedenste Art und Weise zu verarbeiten. Je nach verwendeter Operation können die Abhängigkeiten der Daten zwischen den Partitionen der RDDs nah (Narrow Dependencies) oder weit (Wide Dependencies) sein.
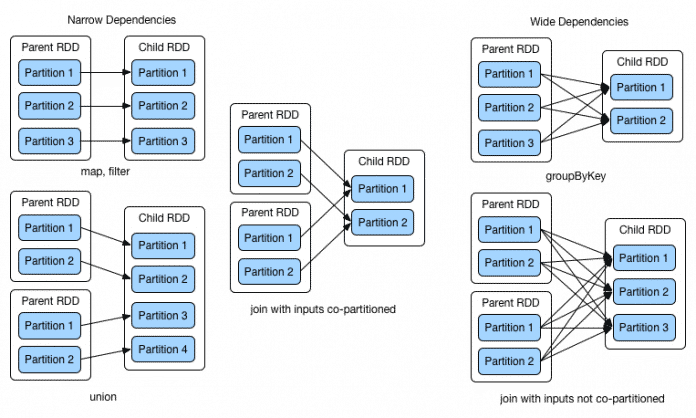
Von Datenlokalität (Narrow Dependencies) spricht man dabei nur, wenn die Daten als Partitions bereits auf dem Worker Node vorhanden sind. Oft ist die Ausführung von Operationen auf den Daten davon abhängig, welche auf anderen Worker Nodes gespeichert sind. Zwischenresultate bei Actions und Transformations mit weiten Abhängigkeiten werden auf dem Storage zwischengespeichert. Die Nutzung von Storage zur Zwischenspeicherung oder gar der Transfer der Daten von einem Worker Node auf die anderen bremsen die Datenverarbeitung von Spark extrem ab. Das lässt sich einfach verdeutlichen, macht man sich die unterschiedlichen Größenordnungen der Zugriffe bewusst:
| Speicher | Lese-/Schreibgeschwindigkeit | Zugriffszeit |
| RAM | 100 GByte/s | 50,00 ns |
| SSD | 500 GByte/s | 0,05 ms |
| HDD | 100 GByte/s | 5,00 ms |
Zusammenfassend heißt das: Der Zugriff auf den Hauptspeicher ist in der Regel 1000-mal schneller als der Zugriff auf SSDs. Letztere hingegen sind rund 100-mal schneller als der Einsatz von Festplatten. Natürlich sind das nur Richtwerte, die nicht in allen Fällen die Performance abbilden. Als Anhaltspunkt können die Werte aber nützlich sein.
Wie schnell muss meine Anwendung laufen?
Diese Frage sollte man sich als Erstes stellen, wenn man daran geht, die unterschiedlichen Cluster-Konfigurationen mit Hilfe einer Testumgebung in der Cloud zu analysieren. Trotz eines Spark-Clusters-on-Demand kostet jedes Hochfahren einer Konfiguration Geld. Da schadet es nicht, sich vorher den Speicherverbrauch und die Struktur der eigenen RDDs einmal anzuschauen.
Je nach Art der Anwendung muss man sich über die Hardware-Resourcen des Clusters Gedanken machen. Handelt es sich bei der eigenen Spark-Anwendung um eine CPU-lastige Maschine-Learning-Anwendung, sollten Instanzen mit mehr Kerne und mehr GHz genutzt werden. Sollen viele kleine Partitionen verarbeitet werden und nutzen viele RDDs Transformationen mit Narrow Dependencies, eignet sich ein Cluster aus vielen kleinen Instanzen vielleicht besser als wenige große Instanztypen.
Auswahl an Maschinen
| Instanztyp | vCPUs | Arbeitsspeicher | Instanz-Speicher | Preis* |
| m3.xlarge | 4 | 15 GByte | 2x 40 GByte SSD | $0,266/h |
| m3.2xlarge | 8 | 30 GByte | 2x 80 GByte SSD | $0,532/h |
| c3.4xlarge | 16 | 30 GByte | 2x 160 GByte SSD | $0,84/h |
| c3.8xlarge | 32 | 60 GByte | 2x 320 GByte SSD | $1,68/h |
Im Gegensatz zu Machine-Learning-Anwendungen, die viele Datentransformationen im Rahmen ihrer Algorithmen ausführen, sind Programme für die Extraktion, Transformation und sowie das Laden der Daten (ETL) in der Regel I/O-lastiger.
Die Ausführung zweier Anwendungen aus dem Fundus der mitgelieferten Spark-Beispiele sollen das illustrieren. Die erste nutzt die Machine-Learning-Bibliothek MLlib, um eine lineare Regression für eine Anzahl Werte zu erstellen, die sich innerhalb einer Textdatei befinden. Einstellen lässt sich bei dem Beispielprogramm die Anzahl der Iterationen. Es erzeugt dabei ein Trainingsmodell. Dieses Modell wird genutzt, den Fehler mit der mittleren quadratischen Abweichung zu bestimmen (Root Mean Squared Error). Um die Anwendung im Cluster ausführen zu können, müssen die Daten im HDFS liegen. Mit Hilfe von
$ ./ephemeral-hdfs/bin/hdfs dfs -mkdir /data
$ ./ephemeral-hdfs/bin/hdfs dfs -put /root/spark/data/mllib
/sample_linear_regression_data.txt /data/.
lassen sich die lokalen Beispieldaten in Hadoops Dateisystem kopieren. Die Anwendung selbst lässt sich dann wie folgt starten:
$ ./spark/bin/spark-submit
--class org.apache.spark.examples.mllib.LinearRegression
--name "LinearRegressionTest" spark/lib/spark-examples-*.jar
--numIterations 10000
hdfs://ec2-52-19-43-176.eu-west-1.compute.amazonaws.com:9000
/data sample_linear_regression_data.txt
Folgende Tabelle illustriert die Testergebnisse bei 1000 Iterationen.
| Test Nr. | Instanztyp | Cores Gesamt | RAM pro Node | Anzahl WorkerNode | Laufzeit |
| 1 | m1.large | 2 | 2 GByte | 3 | 4,60 Min. |
| 2 | m1.large | 6 | 6 GByte | 3 | 4,50 Min. |
| 3 | m3.large | 6 | 5,8 GByte | 3 | 0,43 Min. |
| 4 | c3.2xlarge | 24 | 13,6 GByte | 3 | 0,29 Min. |
Die Testergenisse zeigen, dass im Beispiel zur Berechung der linearen Regression, die Leistung der CPU stärker wiegt als der I/O-Durchsatz des angeschlossenen Storage. Das liegt daran, dass die m3-Instanzen Intels neueste Xeon-Prozessorgeneration nutzen.
Eine Anwendung, bei der es stärker auf I/O ankommt, ist die sogenannte Logdateianalyse. Für den Test soll ein Beispielanwendung von Databricks zum Einsatz kommen, welche die Logdaten eines Apache-Webservers analysieren kann. Die eigentlichen Anwendung, lässt sich über folgende Kommandos installieren:
$ git clone https://github.com/databricks/reference-apps.git
$ cd reference-apps/logs_analyzer/chapter1/scala/
Ist das Scala Build Tool (sbt) noch nicht installiert, kann man das über
$ curl https://bintray.com/sbt/rpm/rpm | sudo tee
/etc/yum.repos.d/bintray-sbt-rpm.repo
$ sudo yum install sbt
nachholen. Danach benötigt man noch access.log-Daten im HDFS. Für den Test wurde eine Dateigröße von drei Gigabyte gewählt.
$./ephemeral-hdfs/bin/hdfs dfs -put access.log /data/
Den DAG der RDDs zeigt folgende Abbildung:
| Test Nr. | Instanztyp | Cores Gesamt | RAM pro Node | Anzahl WorkerNode | Laufzeit |
| 5 | m1.large | 6 | 5,8 GByte | 3 | 3,60 Min. |
| 6 | c3.2xlarge | 24 | 13,6 GByte | 3 | 0,2 Min. |
Spark-Anwendungen zur Laufzeit
Selbstverständlich lässt sich nicht nur die nötige Hardware auf die Anforderungen der eigenen Spark-Anwendung optimieren. Neben der Spark-UI gibt es weitere Tools, mit deren Hilfe sich das Laufzeitverhalten einer Spark-Anwendung untersuchen lässt. Beispiele dafür sind:
- YourKit [7] (Java-Profiler)
- Ganglia [8] (Monitoring-System)
- jmap (in Java enthaltenes Tool zur Untersuchung von Prozessspeicher)
- jstat (in Java enthaltenes Tool für Statistiken der JVM)
- jconsole (grafische Oberfläche für die Analyse von JMX)
Es gibt eine Reihe von Möglichkeiten, Spark-Anwendungen zu tunen. Im Standard nutzt Spark MEMORY-ONLY-Caches zur Deserialisierung von Objekten. Die Nutzung von MEMORYANDDISK-Cache kann vor teuren Neuberechnung bewahren. Stellt die CPU-Leitung im Cluster keinen Flaschenhals dar, wohl aber die I/O bei zu vielen Shuffle-Operationen, lässt sich die Geschwindigkeit mit der LZF-Kompression verbessern (conf.set("spark.io.compression.codec", "lzf")). Alternativ können in solchen Fällen auch mehr Disks die Performance erhöhen.
Fazit
Möchte man nicht allzu viel Arbeit in das Tuning der eigenen Spark-Anwendung investieren, lohnt sich der Vergleich unterschiedlicher Hardware-Konfigurationen für das Spark-Cluster. Mit Hilfe des in Spark enthaltenen spark-ec2-Skripts lassen sich die Anzahl der Worker Nodes und die jeweiligen Instanztypen von EC2 einfach hoch- und runterfahren und so für einfache Geschwindigkeitstests nutzen.
Wer seine Anwendung auf gegebene Hardware optimieren muss, findet sowohl in den Spark-Bordmitteln als auch bei einer Reihe von Open-Source-Tools weitreichende Unterstützung. So lasst sich vielleicht auch der eine oder andere Euro sparen, wenn es darum geht, effektiv mit den Rechnerressourcen umzugehen.
Ramon Wartala
ist Diplom-Informatiker und arbeitet als Director Technology für die Online-Marketing-Agentur Performance Media Deutschland GmbH in Hamburg. Er ist seit über 12 Jahren freier Autor und Speaker zum Thema Softwareentwicklung und Data Mining. Nebenbei berät er Firmen im Bereich Big Data und greift dabei am liebsten auf das freie Framework Hadoop zurück.
URL dieses Artikels:
https://www.heise.de/-2826144
Links in diesem Artikel:
[1] http://sortbenchmark.org/
[2] https://developer.yahoo.com/blogs/hadoop/apache-hadoop-wins-terabyte-sort-benchmark-408.html
[3] https://github.com/intel-hadoop/HiBench
[4] http://wiki.opf-labs.org/display/SP/Benchmarking+Hadoop+installations
[5] http://spark.apache.org/
[6] https://aws.amazon.com/de/ec2/pricing/
[7] https://www.yourkit.com
[8] http://ganglia.sourceforge.net
Copyright © 2015 Heise Medien