

C++17: Neuzugänge in den Bibliotheken
Seit Juni ist C++17 Feature-komplett. Das ist ein guter Anlass, die Neuerungen zu betrachten. Nachdem es im vorherigen Artikel um einige generelle Aspekte und die Sprachmittel ging, stehen nun die neuen Bibliotheksfunktionen im Mittelpunkt.

- Nicolai Josuttis
Viele der in C++17 aufgenommenen Bibliotheken sind bereits in Boost vorhanden und weisen damit eine zum Teil große Anwendungserfahrung auf. Im Rahmen der Aufnahme in C++17 kann sich dennoch etwas ändern – vor allem, weil die Macher alle bis C++17 hinzugekommenen Sprachmittel voraussetzen können.
Portabler Zugriff auf das Dateisystem
Die größte von Boost adaptierte Bibliothek ist "Filesystem" für den bequemen und portablen Zugriff auf Dateisysteme. Das folgende Beispiel zeigt die Ausgabe der Größe einer Datei beziehungsweise, falls filename für ein Verzeichnis steht, das Auflisten dessen Inhalts:
std::filesystem::path p(filename);
if (exists(p)) {
if (is_regular_file(p)) {
std::cout << " size of " << p
<< " is " << file_size(p) << '\n';
}
else if (is_directory(p)) {
// liste Directory auf:
std::cout << p << " is a directory containing:\n";
for (auto& e : std::filesystem::directory_iterator(p)) {
std::cout << " " << f.path() << '\n';
}
}
}
Bei der Adaption gab es einige Verbesserungen. Das Listing zeigt, dass neuerdings das Iterieren über die Dateien eines Verzeichnisses bequem mit einer Range-based-for-Schleife möglich ist. Mit solch einer Schleife kann man übrigens auch rekursiv durch Verzeichnisbäume gehen. Weitere Neuerungen sind Befehle zum Anlegen von Elementen wie Dateien, Verzeichnissen und symbolische Links.
Im Rahmen der Aufnahme in C++17 haben die Macher außerdem die lange gewünschte Funktion zur Berechnung relativer Pfade aus zwei absoluten hinzugefügt. Herausgekommen ist ein ganzes Sammelsurium von Funktionen, da Entwickler manchmal das Dateisystem berücksichtigen wollen, um etwa Symbolic-Links korrekt zu behandeln, an anderen Stellen jedoch unabhängig davon arbeiten möchten. An der Stelle zeigt sich, dass eine solche Bibliothek Eigenschaften unterschiedlicher Dateisysteme nur bedingt kapseln kann, da diese jeweils große Eigenheiten aufweisen können. Unter dem Aspekt ist die Bibliothek bemerkenswert portabel.
Strings ohne Speicherplatz
Mit der Klasse string_view hat eine weitere String-Klasse Einzug in den Standard gehalten. Sie enthält den Speicherplatz der Zeichenfolge nicht selbst, sondern repräsentiert einen Verweis auf eine externe. Das beschleunigt das Kopieren, da nur der Verweis statt des Inhalts repliziert wird. Der Anwender muss jedoch darauf achten, dass der Speicherplatz zur Verfügung steht, solange ein string_view existiert.
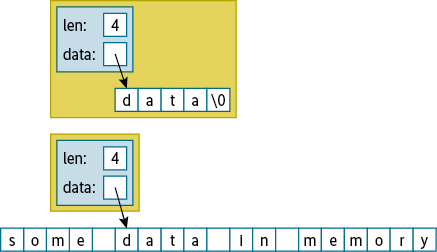
Die Nutzung der Klasse ist beispielsweise besonders hilfreich, wenn das Programm mit mmap() Daten aus Dateien direkt in den Hauptspeicher gemappt hat und die Daten ohne zeitintensives Verwalten des Heap-Speicherplatzes verwenden soll.
Funktionen, die Strings als Parameter verwenden, können (und sollten) nun zur Unterstützung statt const string& den Datentyp string_view verwenden, wenn folgende Umstände gegeben sind:
- Es wird kein Null-Terminator am Ende benötigt (der String also z.B. nicht an eine C-Funktion durchgereicht).
- Die Lebenszeit des Strings wird nicht verlängert, ohne intern eine Kopie zu ziehen.
Wenn ein Aufrufer solcher Funktionen zum Beispiel eine String-Konstante übergibt, muss für den string_views-Parameter lediglich die Länge des Strings ermittelt werden, es entfällt das Erzeugen eines temporären Objekts vom Typ string.
Neue Arten von Datenstrukturen
In C++17 sind drei neue Arten von generischen Datenstrukturen hinzugekommen, die die Sprachmittel sinnvoll ergänzen: std::optional, std::any und std::variant. Auch wenn boost.org Vorläufer zu den Strukturen enthält, gab es teilweise große Änderungen – insbesondere bei std::variant.
Der Datentyp std::optional dient dazu, existierende Datentypen mit der zusätzlichen Fähigkeit zu versehen, den Wert "kein Wert gesetzt" vergeben und abfragen zu können – somit bekommt die Wertesemantik zusätzlich den Wert NULL beziehungsweise NIL. Die Objekte können Auskunft geben, ob ein Wert gesetzt ist. Ist das der Fall, können Entwickler ihn direkt verwenden.
Wenn beispielsweise eine Funktion optional einen String zurückliefert, der auch leer sein kann
std::optional<std::string> foo();
kann sie einen String wie folgt zurückliefern:
return std::string(...);
Das darf auch der Leerstring sein:
return "";
Die Funktion kann aber auch keinen(!) String zurückliefern, wodurch sich eine andere Semantik als bei einem zurückgelieferten Leerstring ergibt:
return std::optional<std::string>();
Oder in "moderner" C++-Schreibweise:
return std::optional<std::string>{};
Der Rückgabewert lässt sich dann wie folgt auswerten:
const std::optional<std::string>& s = foo();
if (s) {
std::cout << "foo() returned '" << *s << "'\n";
}
Der Zugriff erfolgt also mit *s. Der vorherige Test ist notwendig, da das Verhalten undefiniert ist, wenn kein Wert gesetzt ist. Der alternative Zugriff mit s.value() wirft in dem Fall eine Exception.
Moderne Varianten
Mit std::variant gibt es einen neuen generischen Datentyp zum Umgang mit festgelegten Varianten wie sie in Unions zu finden sind. Objekte haben jeweils den Wert eines der Datentypen, die Entwickler beim Deklarieren als mögliche Typen angegeben haben. Im Gegensatz zu dem union-Sprachmittel, können sie wirklich jeden beliebigen Datentyp halten, und die Objekte kennen ihren jeweiligen Datentyp. Dafür lässt sich variant nicht zur Typumwandlung von bits verwenden.
Die folgende Deklaration legt ein variant-Objekt an, das einen int und einen String halten kann, und initialisiert das Objekt gleich:
std::variant<int, std::string> var(42);
Fehlt der Wert zur Initialisierung, nutzt die Bibliothek den Default-Konstruktor des ersten Datentyps. Werte anderer Datentypen lassen sich ohne Weiteres zuweisen:
var = "new value";
var.index() gibt den Index des verwendeten Datentyps aus. Mit der obigen Zuweisung wechselt er somit von 0 auf 1.
Der direkte Zugriff ist mit get<>() möglich, was wahlweise die Angabe des korrekten Datentyps oder dessen Index erfordert:
std::string s = std::get<std::string>(var); // Zugriff ueber Typ
int i = std::get<0>(); // Zugriff ueber Index
Der Compiler versagt das Übersetzen dieser Zeilen bei Verwendung eines Datentyps oder eines Index, der grundsätzlich nicht möglich ist. Implizite Typumwandlungen sind erlaubt, solange sie nicht mehrdeutig sind. Der Zugriff wirft zur Laufzeit eine bad_variant_access-Exception, wenn der Typ des aktuellen Werts nicht passt.
Varianten können den gleichen auch Datentyp mehrfach halten:
std::variant<int, int, std::string> var;
var.emplace<1>(42); // setzt zweiten int
int i = std::get<1>(); // greift auf zweiten int zu
Eine andere Möglichkeit des Zugriffs sind Visitors. Dabei handelt es sich um Funktionsobjekte (Functors) oder Lambdas, die für jeden Datentyp eine entsprechende Zugriffsfunktion anbieten, wie folgendes Beispiel zeigt:
std::variant<int, std::string> var(42);
struct MyVisitor
{
void operator() (int i) const {
std::cout << i << '\n';
}
void operator() (std::string s) const {
std::cout << s << '\n';
}
};
std::visit(MyVisitor(), var); // ruft passenden operator() auf
Mit den ab C++14 unterstützen generischen Lambdas geht das noch einfacher:
std::visit([](auto&& val) {
std::cout << val << '\n';
},
var);
Beliebige Datentypen
Mit dem Datentyp std::any steht ein weiterer Mechanismus für mehrere Datentypen zur Verfügung, die jedoch nicht beschränkt sind. Objekte können zur Laufzeit ihren Datentyp im Prinzip beliebig ändern, was die übliche Typbindung zur Laufzeit quasi aufhebt. Zusätzlich können Objekte wirklich leer sein.
Beispielsweise sind folgende Initialisierungen und Zuweisungen möglich:
std::any anyVal;
anyVal = 42;
anyVal = std::string("hello");
anyVal = "oops";
In dem Beispiel ist anyVal erst leer und enthält dann nacheinander einen Integer, einen String und einen Zeiger auf eine Zeichenfolge. Intern erfolgt die Ermittlung und Prüfung des Datentyps über typeid.
Zum Verwenden der enthaltenen Werte ist die Umwandlung des Objekts in den richtigen Wert mit std::any_cast erforderlich:
int i = std::any_cast<int>(anyVal);
Falls das Objekt keinen int enthält, wird eine bad_any_cast-Exception geworfen. Der Typ muss dabei (bis auf Konstantheit und Referenzen) exakt stimmen. Hält das Objekt einen int, lässt sich der Wert nicht als long oder short auslesen, da sie andere Typ-IDs haben.
Der Typ lässt sich mit type() prüfen:
if (anyVal.type() == typeid(std::string)) ...
Alle Datentypen müssen kopierbar sein. Move-only Datentypen sind nicht erlaubt, die Move-Semantik aber durchaus:
std::string s("a long value disabling SSO");
std::any a;
// move s in to std::any a:
a = std::move(s);
// move out from std::any a to s:
s = std::any_cast<std::string>(std::move(a));
Die Details für C++17 sind aber noch in der Diskussion.
Container und STL
Verschieben zwischen Sets und Maps
Alle assoziativen und ungeordneten Container definieren neuerdings einen speziellen Subtype node_handle, mit dem Entwickler Elemente von einen Container in einen anderen schieben (splicen) können. Die Datenstruktur und der Elementtyp müsen dabei gleich sein. Das folgende Beispiel zeigt das Verschieben eines Elements in einem Multiset in ein anderes Set:
std::multiset<int> src{1, 1, 3, 5};
std::set<int> dst;
dst.insert(src.extract(1)); // OK, splices first
// element with value 1
Der Vorteil ist, dass alle Operationen Speicherplatz weder freigegeben noch neu anfordern, da das von extract() gelieferte Objekt vom Typ std::multiset<int>::node_type den internen Speicherplatz hält, der dem Set dst übergeben wird.
Der erneute Versuch, ein Element mit dem Wert 1 zu übertragen, führt in dem Beispiel zu einem Fehler, da im Gegensatz zur Quelle im Ziel keine Duplikate erlaubt sind:
auto r = dst.insert(src.extract(1)); // Fehler, da keine
// Duplikate erlaubt
In dem Fall ist über r der Zugriff auf das temporär gehaltene Element möglich.
Den Mechanismus können Entwickler auch dazu verwenden, den Schlüssel einer (ungeordneten) Map ohne Speicherplatzoperationen zu verändern:
std::map<int, std::string> m{{1,"mango"},
{2,"papaya"},
{3,"guava"}};
auto nh = m.extract(2);
nh.key() = 4;
m.insert(std::move(nh)); // Fehler ohne move()
Danach hat die Map m den Wert "papaya" unter dem Schlüsselwert 4.
Parallel ausgeführte STL-Algorithmen
Schon lange gab es die Überlegung und Implementierungen, um bei der Ausführung von STL-Algorithmen (Standard Template Library) auszunutzen, dass Rechner mehrere Prozessoren haben können. Entsprechende Mechanismen unter dem Namen "Parallele STL" sind Bestandteil von C++17. Fast alle Algorithmen können jetzt wahlweise sequentiell, parallel oder vektoriell arbeiten.
Dabei müssen Entwickler darauf achten, dass durch die Parallelisierung beziehungsweise Vektorisierung kein undefiniertes Verhalten entsteht.



- "Sequenziell" führt die Algorithmen für alle Elemente wie bisher sequenziell aus.
- "Parallel" bedeutet, dass mehrere "Tasks" (Teilaufgaben oder Elementbearbeitungen) parallel laufen können. Das System führt jede Aufgabe oder Bearbeitung dabei aber jeweils von Anfang bis Ende durch. Entwickler dürfen keine Bearbeitung verwenden, bei der paralleler Zugriff zu einer Race Condition führen könnte.
- "Vektoriell" heißt, dass mehrere "Tasks" parallel ausgeführt und dabei sogar von Teilaufgaben anderer Tasks unterbrochen werden können. Ein Prozessor mag also mit der ersten Anweisung der ersten Teilaufgabe anfangen und dann mit der ersten Anweisung einer anderen Teilaufgabe fortfahren, bevor er die zweite Anweisung der ersten Teilaufgabe angeht.
Ein paar Beispiele sollen die unterschiedlichen Möglichkeiten und Voraussetzungen aufzeigen. Der folgende Code kann vektoriell laufen:
transform (std::execution::par_unseq,
coll1.begin(),coll1.end(), // Quelle
coll2.begin(), // Ziel
[] (auto x) { // Operation
auto y = x * x;
return y;
});
Die Reihenfolge, in der die Transformierung der Elemente erfolgt, ist unbedeutend. Ebenso ist es unkritisch, wenn das System erst die erste und dann die zweite Anweisung für alle Elemente durchführt.
Der folgende Code kann parallel, aber nicht vektoriell laufen:
transform (std::execution::par,
coll1.begin(),coll1.end(), // Quelle
coll2.begin(), // Ziel
[] (auto x) { // Operation
std::lock_guard<mutex> lg(m);
return x*x;
});
Verschiedene parallel laufende Threads dürfen den gleichen Lock anfordern, womit sie auf die anderen Threads warten. Ein vektorieller Ansatz könnte jedoch nach Anforderung eines ersten Locks einen zweiten für ein anderes Element anfordern, ohne den ersten freigegeben zu haben. Das kann je nach Mutex zu einer Exception oder einem Deadlock führen.
Der Aufruf:
transform (std::execution::seq,
coll1.begin(),coll1.end(), // Quelle
coll2.begin(), // Ziel
op); // Operation
entspricht dem bisherigen und natürlich weiter verfügbaren
transform (coll1.begin(),coll1.end(), // Quelle
coll2.begin(), // Ziel
op); // Operation
Sahnehäubchen und Fazit
Ein paar Sahnehäubchen
Nach den wichtigsten Bibliotheken folgt wie im ersten Teil des Artikels eine Übersicht von weiteren nützlichen Bibliotheks-Features:
- C++17 übernimmt jetzt die C-Bibliotheken aus der Version C11 statt aus C99.
- Weitere mathematische Funktionen sind Bestandteil der Bibliotheken: Solche für elliptische Integrale, Polynomiale, Bessel-Funktionen sowie gcd() und lcm() (größter gemeinsamer Teiler und kleinstes gemeinsames Vielfaches).
- Es gibt wohl eine kleine Bibliothek, um mit hoher Performanz Zahlen in Strings umzuwandeln und umgekehrt. Allerdings ist das zughörige Interface noch nicht ganz geklärt.
- Explizites Alignment ist nun auch bei Heap-Speicherplatz erlaubt.
- Ein Mutex für Read/Write-Locks, die keine Timer verwenden können, (shared_mutex ergänzt den bisherigen shared_timed_mutex).
- Etliche neue Hilfsfunktionen wie data() auch für nicht konstante Strings oder is_lock_free() für atomare Datentypen
- Bugfixes und kleine Verbesserungen an zahlreichen Stellen (noexcept, constexpr, neue Hilfstypen usw.)
Fazit
Bei der Standardbibliothek gilt das gleiche wie bei den Sprachmitteln: "Viel Kleinvieh macht auch Mist". Fast 200 zusätzliche Seiten definieren im Standard neue Bibliotheken, Klassen und Funktionen, die das tägliche Programmieren signifikant vereinfachen können. Neben den neuen Datenstrukturen ragt vor allem die Bibliothek für den Dateizugriff heraus. Und die Wirkung parallel ausgeführter STL-Algorithmen kann erheblich sein.
Viele weitere Bibliotheken, die es nicht in C++17 geschafft haben, sind in Arbeit. Dazu gehören die Netzwerkkommunikation (eine Adaption von Boost-Asio und Transactional Memory. Am Horizont zeichnet sich bereits die "STL2" ab, die Bereiche nicht mehr getrennt mit begin() und end() definieren und damit erheblich bequemer umzusetzen sein wird und zu effizienterem Code führen kann. Siehe dazu range-v3 auf GitHub und den Entwurf "C++ Extensions for Ranges".
Auch hier gilt, dass letzte Details noch im Fluss sind. Alle Angaben zu C++17 also noch immer ohne Gewähr.
Nicolai Josuttis
ist seit dem ersten C++-Standard an der Standardisierung von C++ aktiv beteiligt und hat mehrere Bücher zu der Programmiersprache geschrieben (darunter das weltweite Standardwerk "The C++ Standard Library"). Er gibt Schulungen zum Umstieg auf modernes C++ wie C++11, C++14 oder jetzt auch C++17.
(rme)
