

C++20-Konzepte: Neue Wege mit Konzepten
Konzepte sind eine Neuerung in C++20, die zu verständlicheren Fehlermeldungen und besser lesbarem Code verhelfen können, wie dieser Artikel zeigt.

(Bild: Dilok Klaisataporn/Shutterstock.com)
- Andreas Fertig
Eine Stärke von C++ ist es, generischen Code schreiben zu können. Ein Algorithmus wird generisch implementiert und ist mit verschiedenen Datentypen verwendbar, die verschiedene Anforderungen erfüllen müssen. Konzepte ermöglichen es erstmals, mit Sprachmitteln Anforderungen an generische Datentypen zu formulieren. Das verleiht dem Code mehr Ausdruckskraft. Dieser Teil der Artikelserie zeigt, wie sich Code durch Konzepte klarer formulieren lässt. Bisher waren gerade Fehlermeldungen bei Templates gefürchtet. An dieser Stelle kommen Konzepte ins Spiel: Sie sind dazu in der Lage, Fehlermeldungen auf den Punkt zu bringen.
Eingeschränkte Platzhalterdatentypen
Platzhalterdatentypen sind Datentypen, die der Compiler durch auto selbstständig ermittelt. Dafür verwendet er den bei der Initialisierung zugewiesenen Wert. Die Vorteile zeigen sich bei auto-Variablen. Sie sind dann interessant, wenn der genaue Datentyp nicht näher spezifiziert werden soll.
Videos by heise
Im nachfolgenden Codeausschnitt stellt static_assert sicher, dass x ein integraler Datentyp ist. Das ist ein häufiges Muster in generischem Code. Ob der Datentyp signed oder unsigned ist und ob es sich um einen long int oder nur um einen int handelt, spielt für den Algorithmus und die Berechnung keine Rolle. Ausgeschlossen sind dagegen Gleitkommadatentypen wie float und double.
Ohne C++20 existierte nur die Option, mit einem Type Trait std::is_integral und einem static_assert zu arbeiten:
template<typename T>
auto SomeFunction(T& value)
{
// ...
auto x = Calculate(value);
static_assert(std::is_integral_v<decltype(x)>,
"Only integrals are allowed");
// ...
}Die Umsetzung funktioniert, ist aber nicht elegant, allein schon durch den Einsatz von decltype, das wiederum x als eine unnötige Wiederholung erfordert. Schließlich ist die zusätzliche Anweisung static_assert mit oder ohne Fehlermeldung eine Zeile Code mehr. Zusätzlich besteht das Risiko, bei mehr als einer Variablen die falsche zu testen.
All diese Fragen und potenziellen Fehlerquellen entfallen dank eingeschränkter auto-Variablen in C++20. Zunächst ist jedoch zu beachten, dass an dieser Stelle nur Konzepte verwendet werden können. Praktischerweise enthält die Standardbibliothek das Konzept std::integral. Damit lässt sich die Einschränkung von x wie folgt formulieren:
template<typename T>
auto SomeFunction(T& value)
{
// ...
std::integral auto x = Calculate(value);
// ...
}Im Vergleich zum Overhead und den Entscheidungen, die es in der C++17-Variante zu treffen gilt, ist das Arbeiten mit der C++20-Version wesentlich angenehmer. Einfach und kompakt erlaubt sie das Formulieren der Erwartungshaltung an den Datentyp in generischem Code.
Abgekürzte Funktions-Templates
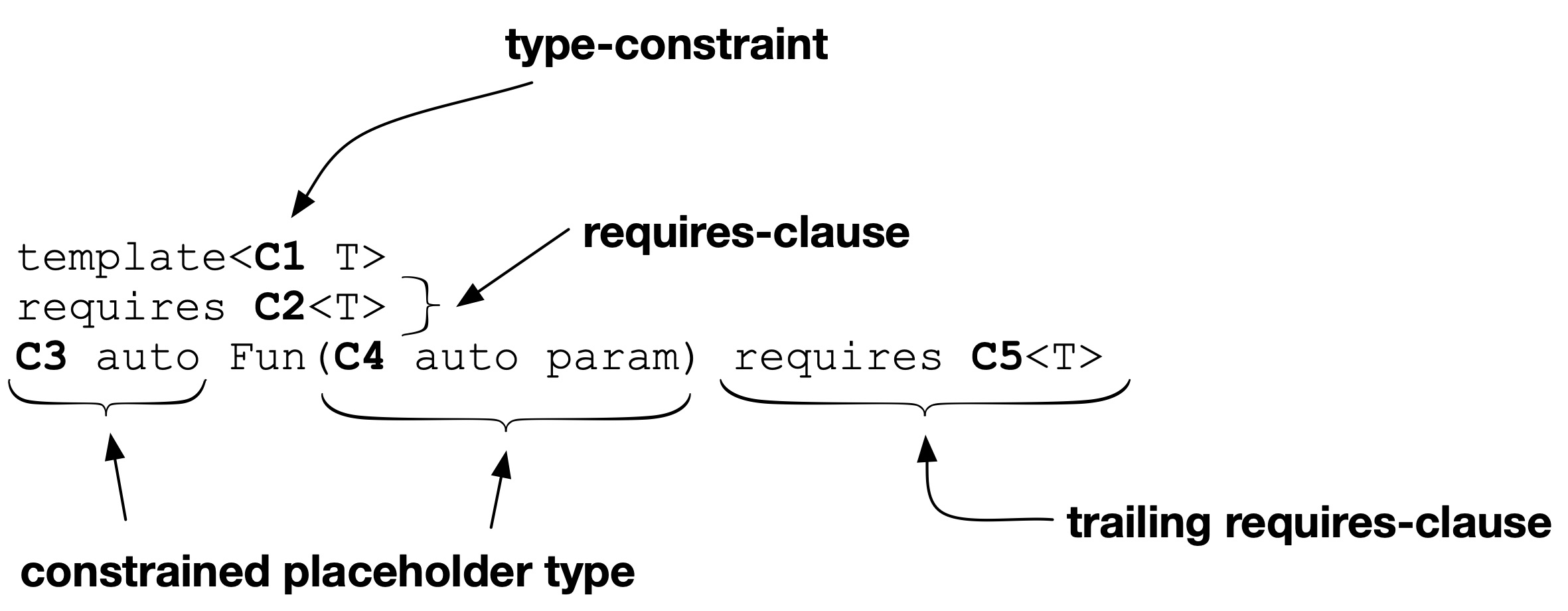
Die Constraint-Platzhaltertypen C3 und C4, die auto-Datentypen einschränken, sind bereits aus dem ersten Teil bekannt. Ein konkreter Fall sind die in C++20 neu hinzugekommenen auto-Parameter. Setzt eine Funktion sie ein, handelt es sich um ein abgekürztes Funktions-Template.
Das folgende Listing zeigt beispielhaft ein vom Autor gerne eingesetztes Muster: Ein Funktions-Template fordert zuerst einen globalen Mutex an, um danach eine dann geschützte Funktion aufzurufen. Der Vorteil dieses Patterns ist, dass der Name des globalen Mutex nur innerhalb der Funktion bekannt sein muss, statt überall in der Codebasis verstreut zu sein.
template<typename T>
void DoLocked(T&& f)
{
std::lock_guard lock{globalOsMutex};
f();
}Zwei Dinge sind an DoLocked verbesserungswürdig: Erstens erfordert die grundsätzlich einfache Funktion viel Schreibarbeit, wobei vor allem der Template-Kopf störend wirkt. Weitaus schwerwiegender ist der zweite Aspekt: Für Benutzer ist es intransparent, dass DoLocked durch typename ein ausführbares Objekt als Parameter erwartet. Zwar teilt der Compiler das in der Fehlermeldung mit, aber meist erst nach gefühlten 20 Seiten. Das folgende Listing zeigt, wie beides in C++20 besser geht:
void DoLocked(std::invocable auto&& f)
{
std::lock_guard lock{globalOsMutex};
f();
}Bei einem abgekürzten Funktions-Template entfällt der Template-Kopf. Wie der Name schon sagt, bedeutet das gleichzeitig, dass jeder auto-Parameter eine Funktion in ein Funktions-Template wandelt.
Wichtig ist aus Sicht des Autors, dass das Konzept std::invocable Nutzern der Funktion DoLocked kommuniziert, dass f aufrufbar sein muss. Ohne das abgekürzte Funktions-Template ist der Einsatz des Konzepts anstelle von typename eine Alternative in C++20. Der auto-Parameter und das Konzept ermöglichen die Einschränkung und Reduzierung von zu lesendem und zu schreibendem Code.
Verbesserte Fehlermeldungen durch Konzepte
Ein bedeutender Unterschied zwischen Konzepten und dem initial erwähnten enable_if sind die Compiler-Fehlermeldungen. Ein Compiler kann gut verstehen, was ein Konzept ausdrückt. Dagegen ist enable_if ein Konstrukt wie viele andere. Der Compiler versteht nicht, dass damit etwas aktiviert oder deaktiviert werden soll.
Als Beispiel hierfür eignet sich die Prüfung, ob ein Datentyp das Interface eines STL-Containers erfüllt. Im Grunde genommen besteht das Interface eines STL-Containers aus dem Vorhandensein der Typen
value_typesize_typeallocator_typeiteratorconst_iterator
sowie der Funktionen
sizebeginendcbegincend
Das ist recht überschaubar. Eine mögliche Implementierung in C++17 ist in diesem Listing zu sehen:
template<typename T, typename U = void> // A
struct is_container : std::false_type {};
template<typename T>
struct is_container<
T,
std::void_t<typename T::value_type, // B
typename T::size_type,
typename T::allocator_type,
typename T::iterator,
typename T::const_iterator,
decltype(std::declval<T>().size()),
decltype(std::declval<T>().begin()),
decltype(std::declval<T>().end()),
decltype(std::declval<T>().cbegin()),
decltype(std::declval<T>().cend())>>
: std::true_type {};
struct A {};
static_assert(!is_container<A>::value); // C
static_assert(is_container<std::vector<int>>::value);Die offenen Fragen sind vor allem für C++-Einsteiger bei diesem Ansatz vielfältig:
- Wieso existiert der Name
is_containerzweimal? - Wieso erbt dieses Konstrukt einmal von
std::false_typeund das andere Mal vonstd::true_type? - Was genau sind
std::false_typeundstd::true_type? std::void_tinB– was war das noch gleich?- Bei der Kaskade von
decltypeundstd::declvalbleibt die Frage, was mehr stört – die Wiederholungen oder dass unklar ist, was sie tun. - Und das Beste zum Schluss: Der Einsatz erfordert
::value, wenn nicht noch mehr Code es mithilfe eines Variablen-Templates versteckt.
Für Einsteiger sind all diese Fragen eine Hürde. Die Formulierung, was zu prüfen ist, findet sich in lesbarem Text in der Beschreibung der oben gezeigten Prüfung, ob ein Datentyp das Interface eines STL-Containers erfüllt. Zum Verständnis des Codes braucht es dagegen einiges an Wissen. Zum Aufatmen zeigt das nächste Listing die Variante in C++20. Hier ist lesbarer Code zu sehen, der einfach und verständlich ist und kein tiefes C++- und STL-Wissen voraussetzt.
template<typename T>
concept container = requires(T t)
{
typename T::value_type;
typename T::size_type;
typename T::allocator_type;
typename T::iterator;
typename T::const_iterator;
t.size();
t.begin();
t.end();
t.cbegin();
t.cend();
};
struct A {};
static_assert(not container<A>);
static_assert(container<std::vector<int>>);Diese Version sieht beinahe so aus wie der zuerst formulierte reine Text. Es bleibt die Frage, wie es um die Fehlermeldungen steht. Beim Verwenden der C++17-Implementierung is_container gibt Clang folgende Fehlermeldung aus:
<source>:32:1: error: static_assert failed due to requirement 'is_container<std::array<int, 5>, void>::value' static_assert(is_container<std::array<int, 5>>::value); ^ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 1 error generated. Compiler returned: 1 Sie zeigt an, dass static_assert funktioniert und std::array das Interface is_container nicht erfüllt. Auf der Habenseite kompiliert der offensichtlich falsche Code nicht und schafft es damit nie zum Kunden – ein essenzieller Punkt. Darüber hinaus teilt die Fehlermeldung keine weiteren Informationen, etwa wieso std::array kein Container ist.
C++20 und das Konzept container helfen an dieser Stelle weiter. Beim Aufruf von container mit einem std::array in static_assert zeigt Clang folgende Fehlerausgabe:
<source>:26:1: error: static_assert failed static_assert(container<std::array<int, 5>>); ^ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <source>:26:15: note: because 'std::array<int, 5>' does not satisfy 'container' static_assert(container<std::array<int, 5>>); ^ <source>:9:17: note: because 'typename T::allocator_type' would be invalid: no type named 'allocator_type' in 'std::array<int, 5>' typename T::allocator_type; ^ 1 error generated. Compiler returned: 1 Nach wie vor ist zu sehen, dass static_assert seinen Job erledigt, indem er verhindert, dass der Code kompiliert. Nun kommt die Mächtigkeit von Konzepten ins Spiel: Der Compiler versteht jetzt, dass es sich bei den einzelnen Anforderungen um solche handelt und weiß exakt, welche Anforderung nicht erfüllt ist. Das zeigt die Ausgabe, die mitteilt, dass der Container std::array über keinen Typ allocator_type verfügt. Das ist logisch, denn der Grundgedanke von std::array ist, dass es zur Compile-Zeit alloziert wird. In der C++17-Variante ist das ein schwer auffindbarer Fehler. Bei std::array ist weitgehend bekannt, dass es nicht alloziert. Doch vor allem in einer großen und womöglich neuen Codebasis mit weniger bekannten Datentypen bieten die Fehlermeldungen von C++20 und Konzepten einen großen Gewinn.
Neue Möglichkeiten durch die Trailing Requires Clause
Die Trailing Requires Clause ermöglicht das Einschränken von Methoden eines Klassen-Templates, ohne dass sie selbst ein Template werden müssen.
Ein Beispiel ist eine Wrapper-Klasse wie std::optional, die das Verhalten des zu umschließenden Datentyps nachahmen soll. Eine der Aufgaben ist es, einen Default-Konstruktor nur dann bereitzustellen, wenn der umschlossene Datentyp selbst einen besitzt. Im nachfolgenden Listing ist eine stark vereinfachte Version in Form der Klasse Wrapper zu sehen.
#include <type_traits>
template<typename T>
class Wrapper
{
public:
template<typename std::enable_if<
std::is_default_constructible_v<T>,
T>::type = 0>
Wrapper()
{}
Wrapper(T) {}
// more access functions
};
static_assert(
std::is_default_constructible_v<Wrapper<int>>);Der enable_if für den Default-Konstruktor sieht richtig aus und funktioniert wunderbar in Kombination mit int oder anderen Datentypen, die einen Default-Konstruktor mitbringen. Fehlt Letzterer bei einem verwendeten Datentyp, kompiliert der Code jedoch nicht mehr, unabhängig davon, ob Wrapper standardmäßig initialisiert wird oder nicht.
Der Grund hierfür ist, dass der Default-Konstruktor kein Template ist. Ohne einen Template-Parameter, beispielsweise in Form eines Arguments für den Konstruktor, ist die Formulierung eines Templates aber nicht möglich. Eine leicht abgewandelte Form dieses Problems ist der Kopierkonstruktor. Dabei existiert zwar das benötigte Argument für die Formulierung eines Templates, aber die Form eines Kopierkonstruktors hat gemäß dem C++-Standard keinen Template-Kopf. Wird er dennoch hinzugefügt, ist das Ergebnis ein Konvertierungskonstruktor. Zudem ist es dann schwer, diesen Konstruktor auf exakt den Datentyp T festzulegen. Somit tut sich bei einer im Grunde genommen einfachen Aufgabe ein ganzer Sumpf an Problemen auf.
Davon abgesehen, dass die gezeigte und vermeintlich einfache Umsetzung nicht funktioniert, enthält sie enable_if, std::is_default_constructible_v und einen Default-Template-Parameter.
Das ist ein Fall für die Trailing Requires Clause der C++20-Konzepte. Sie erlaubt das Aktivieren oder Deaktivieren einer Funktion, ohne dass diese selbst ein Template sein muss. Da Wrapper ein Klassen-Template ist, steht der erforderliche Template-Parameter T für die Auswertung von std::is_default_constructible_v zur Verfügung. Durch die Trailing Requires Clause ist es zudem möglich, dem Compiler die Bereitstellung der Default-Implementierung für den Konstruktor mittels =default zu übertragen:
template<typename T>
class Wrapper
{
public:
Wrapper() requires(
std::is_default_constructible_v<T>) = default;
Wrapper(T) {}
};
struct A {
A() = delete;
;
};
static_assert(
std::is_default_constructible_v<Wrapper<int>>);
static_assert(
not std::is_default_constructible_v<Wrapper<A>>);Als Erstes ist sicherlich zu erwähnen, dass die hier gezeigte Version im Gegensatz zu der vorherigen funktioniert. Ein weiteres Plus ist die Lesbarkeit. Dank requires erübrigt sich enable_if.
Diese Variante lässt sich eins zu eins auf den Kopierkonstruktor übertragen, wodurch das komplizierte Filtern auf den richtigen Datentyp entfällt. Beim Kopierkonstruktor ist ebenso wie beim Default-Konstruktor jeweils eine Basisklasse nötig. Von dieser erbt der Wrapper, um die Funktionalität ohne C++20 zu realisieren. Insgesamt erzeugt das wesentlich mehr und vor allem schwerer zu verstehenden Code. C++20 ist dahingehend ein großer Gewinn.
Mit der Trailing Requires Clause lässt sich auch der Destruktor aktivieren oder deaktivieren, in Abhängigkeit von den Eigenschaften eines Datentyps.
Zusammengefasst lässt sich die Trailing Requires Clause auf die folgenden Konstruktoren anwenden, die nicht als Template formuliert werden können:
- Default-Konstruktor
- Kopierkonstruktor
- Destruktor
Schnittstellen mit Konzepten statt Vererbungsdefinition
Ein weiteres Beispiel soll zeigen, wie Konzepte den Code sicherer machen und die Einschränkung gut lesbar dokumentieren.
Vererbung und virtuelle Funktionen führen gelegentlich zu Diskussionen in Bezug auf Performance und Speicherbedarf. Die Tabelle virtueller Methoden, die durch virtuelle Funktionen entsteht, benötigt etwas Speicherplatz. Gleichzeitig kostet das Dereferenzieren des Zeigers etwas Laufzeit. Dank guter Compiler und vor allem deren Optimizer sind virtuelle Funktionen dennoch eigenen Varianten vorzuziehen. Nicht immer ist Vererbung das, was an dieser Stelle gewünscht ist, und erscheint dann wie ein Provisorium. Außerdem gibt es durch virtuelle Funktionen Fehlerquellen wie pure virtuelle Funktionen, die zur Laufzeit zu einer Dereferenzierung eines Null-Zeigers und damit einem Absturz des Programms führen, oder die Funktion in der Basisklasse kommt zum Einsatz, obwohl sie nicht gewünscht ist. All das lässt sich finden und beheben, es nicht suchen und beheben zu müssen, ist jedoch vorzuziehen.
Ziel ist es, mehrere Objekte zu haben, die eine gemeinsame Eigenschaft besitzen. Sie alle haben eine Funktion draw, die das Zeichnen des jeweiligen Objekts erlaubt. Der typische Weg vor C++20 war eine Basisklasse, die die Methode draw definiert, von der alle Objekte erben, und womöglich auch CRTP (Curiously Recurring Template Pattern). Das folgende Listing zeigt eine denkbare Implementierung am Beispiel der Klassen Circle und Rectangle, die beide über eine Funktion draw verfügen. Das Interface bestimmt sich durch die Basisklasse Drawable, und die Funktion Paint nimmt ein Drawable-Objekt entgegen.
struct Drawable {
virtual ~Drawable() = default;
virtual void draw() const = 0;
};
struct Circle : public Drawable {
void draw() const override;
};
struct Rectangle : public Drawable {
void draw() const override;
};
void Paint(const Drawable& shape);
void Use()
{
Circle c{};
Paint(c);
Rectangle r{};
Paint(r);
}Konzepte erlauben eine solche Schnittstellendefinition ohne Vererbung. Dadurch entfallen die Tabelle virtueller Methoden und die Dereferenzierung durch den virtuellen Funktionszeiger – also im Grunde genau das, was auch der neue Ranges-Bibliotheksteil in C++20 bewirkt. Die aufgerufene Funktion beschreibt dadurch die Schnittstelle und nicht mehr die Klasse. Im folgenden Listing ist die Implementierung dargestellt:
template<typename T>
concept drawable = requires(T obj) { obj.draw(); };
struct Circle {
void draw() const;
};
struct Rectangle {
void draw() const;
};
void Paint(const drawable auto& shape);
void Use()
{
Circle c{};
Paint(c);
Rectangle r{};
Paint(r);
}Das Großartige an dieser Lösung ist, dass sie erweiterbar ist. Angenommen, es gibt eine weitere Klasse Point, die über keine dezidierte draw-Funktion verfügt. Allerdings gibt es dafür eine freie Funktion Paint, die in der Lage ist, einen Point zu zeichnen. Gleichzeitig gibt es noch mehr solcher Objekte, die über eine globale Funktion Paint darstellbar sind. Während das in der Vererbungswelt ein Problem darstellt, ist die Erweiterung bei Konzepten recht einfach.
template<typename T>
concept drawable = requires(T obj) { obj.draw(); }
|| requires(T obj) { Paint(obj); };
struct Circle {
void draw() const;
};
struct Rectangle {
void draw() const;
};
struct Point {
int x;
int y;
};
void Paint(const Point& p);
void Draw(const drawable auto& shape);
void Use()
{
Circle c{};
Draw(c);
Rectangle r{};
Draw(r);
Point pt{2, 3};
Draw(pt);
}Wie Draw nun implementiert wird, ist Geschmackssache. Eine Variante ist die Umsetzung in nur einer Funktion, in der constexpr if entscheidet, ob draw oder Paint aufgerufen wird:
void Draw(const drawable auto& shape)
{
if constexpr(requires() { shape.draw(); }) {
shape.draw();
} else {
Paint(shape);
}
}Zusammenfassung
Konzepte ermöglichen es, ohne Wissen über Template-Metaprogrammierung Anforderungen in Code zu formulieren. Der Code wird durch den Einsatz von Konzepten anstelle vom generischen typename direkt zur lesbaren Dokumentation. Seitenlange und unklare Fehlermeldungen sind mit Konzepten ebenfalls passé. Wie im Beispiel „Schnittstellen mit Konzepten statt Vererbungsdefinition“ zu sehen, ergeben sich durch Konzepte neue Muster und Möglichkeiten.
Der vollständige Code steht auf GitHub zur Verfügung.
Andreas Fertig
beschäftigt sich als Trainer und Berater mit C++. Er ist der Autor von Programming with C++20. Im Web ist er unter andreasfertig.info zu finden.
(mai)
