Content Analytics – Bring your own AI vs. Driver-less AI

(Bild: metamorworks / shutterstock.com)
Unternehmen, die neue Erkenntnisse aus vorhandenen Daten gewinnen wollen, stehen häufig vor der Entscheidung, eigene Data Scientists mit einem Python-KI-Baukasten eine individuelle Anwendung bauen zu lassen oder eine für den Anwendungsfall von Experten vorkonfektionierte Plattform mit integrierter KI beziehungsweise AutoML-Funktion zu nutzen.
Die ML-basierte Datenanalyse ist für Data Scientists oder Entwickler gleichermaßen eine komplexe Aufgabenstellung, die mit der Auswahl der eingesetzten Frameworks erst anfängt. Doch die Zahl an Frameworks und Tools in der sich rasant entwickelnden Welt der KI und des maschinellen Lernens (ML) ist schon nahezu unüberschaubar. Noch komplexer wird es, will man aus unstrukturierten Inhalten Erkenntnisse gewinnen und das Potenzial dieser "Dark Data" erschließen. Unstrukturierte Texte enthalten zahlreiche unternehmensrelevante Informationen, sind aber nur schwer systematisch auswertbar.
Kommt beim Thema Text & Content Analytics zum Machine Learning noch das Natural Language Processing (NLP) hinzu, sind die Datenmengen noch viel größer, und die Datenvorverarbeitung ist schwieriger – aber auch wichtiger. Die Klaviatur von Tokenizer, Stemmer, Lemmatizer, Word Embeddings, TF/IDF etc. müssen Data Scientist und Entwickler gut beherrschen – zusätzlich zur vielfältigen Welt von ML, neuronalen Netzen und Deep Learning.
Schnell stellt sich die Frage, ob der Data Scientist mit "seinem" Python-KI-Baukasten eine individuelle Anwendung für das Unternehmen bauen und diese Komplexität selbst beherrschen sollte. Oder setzt man besser auf eine Plattform mit integrierten KI-Funktionen, die Experten für bestimmte Anwendungsfälle vorkonfektioniert haben und die vielleicht sogar eine "AutoML"-Funktion bietet? Wie bei "make or buy" üblich, gibt es auch hier keine allgemeingültige Antwort. Eine ergebnisoffene Betrachtung der Vor- und Nachteile beider Ansätze ist für die Entscheidungsfindung nötig.
BYOAIT – Bring your own AI tools
Wenn der Data Scientist im Unternehmen ein Problem mit maschinellem Lernen lösen soll, steht er vor zahlreichen Herausforderungen. Typische Aufgaben wie "Dokumenttypen im Posteingang sollen automatisch klassifiziert werden" oder "Kundenbeschwerden sollen thematisch kategorisiert werden" sind meist einfach zu verstehen. Ob sich das Problem aber mit KI überhaupt gut lösen lässt, mit welcher Erkennungsrate, mit welchen Algorithmen und unter Nutzung welcher Frameworks, ist hingegen nur schwer einzuschätzen. Es ist zudem abhängig von den zur Verfügung stehenden Daten und der Erfahrung des Data Scientist. Hier gilt: Probieren geht über studieren.
Das ist sicher ein Hauptgrund, warum Python als Skriptsprache unter Data Scientists so beliebt ist. Zusammen mit vielen ML- und NLP-Frameworks und einem Jupyter Notebook – der bevorzugten IDE des Data Scientist – steht eine Spielwiese zur Datenanalyse zur Verfügung. Ad hoc lassen sich damit Daten vorverarbeiten, transformieren, Lernmengen aufbauen, Modelle trainieren und anschließend testen. Diese Flexibilität ist ein wesentliches Argument für diesen Ansatz.
Die wichtigsten nativen Python-Frameworks für ML sind Scikit-learn, PyTorch, Keras, Theano und Pandas. Scikit-learn nutzt wiederum NumPy und SciPy und dürfte derzeit zu den beliebtesten Frameworks zählen. Natürlich stehen auch Python-Entwicklern weitere populäre Bibliotheken zur Verfügung, die in anderen Programmiersprachen entwickelt werden. Hier geben sich die Big Five mit ihren Bibliotheken die Klinke in die Hand: TensorFlow (Google), CNTK/DMTK (Microsoft), MXNet (AWS), CoreML (Apple) – Facebook ist mit dem bereits erwähnten PyTorch vertreten. Aber DeepLearning4J, Apache Spark.MLlib oder Caffe dürfen auch nicht unerwähnt bleiben. So kann sehr schnell die übersichtliche Spielwiese im Wildwuchs untergehen. Der Artikel Gehirnbaukästen aus iX 10/2019 [1] liefert eine Einordnung der Frameworks.
Im Kontext von Text & Content Analytics sind zudem in der Regel noch weitere Bibliotheken für das NLP nötig. Ohne Kenntnis des Natural Language Toolkit (NLTK) oder spaCy dürfte es der Python-Entwickler schwer haben. Aber reichen diese Bibliotheken? Welche Bedeutung kommt eigentlich den in den Bibliotheken angeboten Algorithmen zu?
Tatsächlich liegt hier der Hase im Pfeffer: Welcher Algorithmus ist für welchen Anwendungsfall geeignet und welche Features werden überhaupt gelernt? Vor lauter Mathematik gerät das eigentliche Ziel schnell aus den Augen.
Beispiel Textklassifikation: einfache Aufgabenstellung, große Komplexität
Ein konkretes Beispiel für die Komplexität der Wahl der richtigen Algorithmen ist die Textklassifikation, die für viele Anwendungsfälle wichtig ist: Ob es um die automatische Erkennung von Dokumenten im Posteingang, die Stimmungsanalyse in der Kundenkommunikation (Sentiment Analysis), die automatische Verschlagwortung in einem Dokumentenmanagementsystem (DMS) oder die Zuordnung von Unfallberichten zu Sachbearbeitern geht, immer müssen Texte Klassen zugeordnet werden. Die Klassifikation ist zudem eine der grundlegenden ML-Aufgaben beim Supervised Learning. Eine informative Übersicht zur Vielfalt der Verfahren findet sich im Google ML Guide zur Textklassifikation [2].

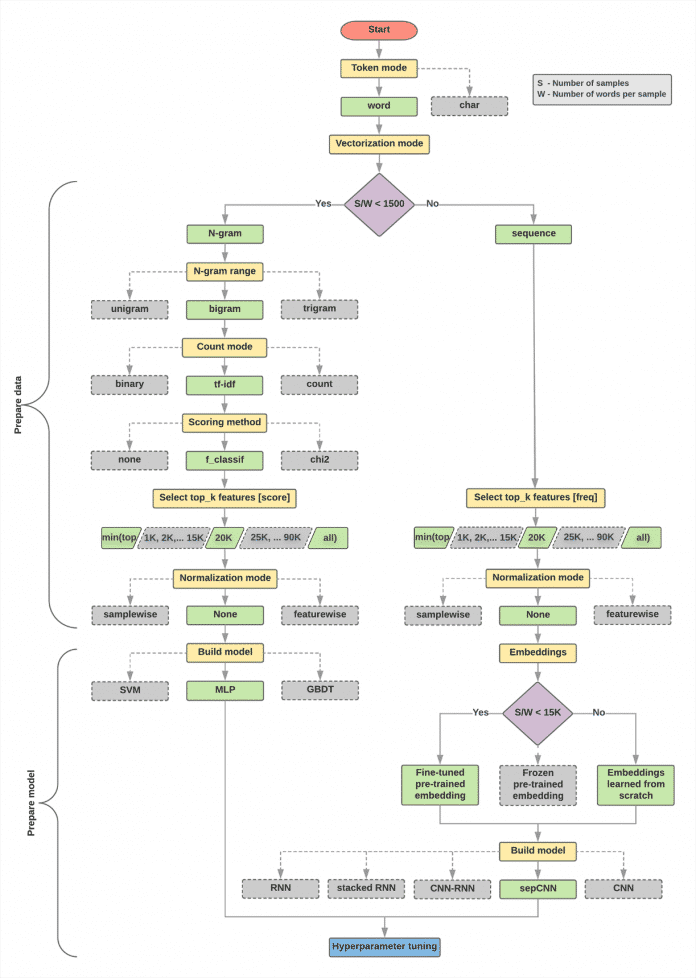
(Bild: Google)
Zunächst stellt sich die Frage, wie sich ein Text in einen numerischen Vektor verwandeln lässt, den letztlich alle ML-Verfahren benötigen. Dieser Feature-Vektor ist bei strukturierten Daten viel leichter erstellt: Beispielsweise lassen sich Sensordaten von Maschinen oft direkt für ein Vorhersagemodell zu möglichen Ausfällen nutzen.
Texte hingegen erfordern erst die Umwandlung in Token, wobei ein Stemming (Stammformreduktion) erfolgen kann oder auch Stopp-Wörter entfernt werden. Anschließend lassen sich einzelne Wörter (Unigramm) oder auch Kombinationen von Wörtern (Bigramm oder Trigramm) nutzen. Die Existenz, Häufigkeit oder auch der TF/IDF-Score (Vorkommenshäufigkeit und inverse Dokumenthäufigkeit) fließen nun in den Vektor ein. Im einfachsten Fall spricht man hier vom Bag-of-Words-Modell.
Kommen 10.000 verschiedene Wörter in der Trainingsmenge vor, so fallen rein rechnerisch bei Trigrammen bereits eine Billion Kombinationen an. Das ist auch heute noch zu viel für Machine Learning. Daher muss eine Feature Reduction erfolgen, für die es wiederum diverse Verfahren gibt. Erst am Ende steht dann die Wahl des eigentlichen ML-Algorithmus. Soll es ein Multi-layer Perceptron (also ein sozusagen normales neuronales Netz) sein? Oder doch eine Support Vector Machine (SVM)? Hat sich Maximum-Entropie nicht als gut bei Texten herausgestellt? Basieren die meisten Spam-Filter nicht immer noch auf Naive Bayes? Was ist eigentlich dieses Gradient Boosting on Decision Trees (GBDT)? Oder fehlt etwa XGBoost noch in der Framework-Liste?
Angesichts der unüberschaubaren Vielfalt fällt die Wahl der richtigen Mischung schwer. Auf die Textklassifikation übertragen, heißt das: Wie sieht es denn hier mit Deep Learning aus? Tatsächlich sind Recurrent Neural Networks (RNN) auf den ersten Blick für die Verarbeitung von Text gut geeignet, da sie eine Art Gedächtnis haben und somit die Reihenfolge von Wörtern berücksichtigen können. Aber auch Convolutional Neural Networks (CNN) kommen zum Einsatz.
Grundlage sind in diesen Fällen sogenannte Word Embeddings, die einzelne Wörter in Vektoren verwandeln, sodass am Ende Matrizen als Input für das Deep Neural Network (DNN) dienen. Voraussetzung für all diese Verfahren sind aber riesige Datenmengen, die man sich zunächst aus unterschiedlichen Quellsystemen besorgen muss. Statt den Content zur KI zu bringen, ist eine sinnvolle Alternative, KI-Funktionen dort zu integrieren, wo die unstrukturierten Informationen gemanagt werden, beispielsweise direkt in einer Content-Services-Plattform.
Beim Ansatz "Bring your own AI” steht großer Flexibilität und Freiheit eine gewaltige Komplexität gegenüber. Die Erstellung eigener Modelle mit einem eigenen Baukasten an Werkzeugen setzt solides Expertenwissen voraus. Aber selbst wenn das vorhanden ist, bleibt ein Problem häufig unbeachtet: Mit dem Deployment des trainierten Modells ist die Arbeit nicht getan, die kontinuierliche Verbesserung der Modelle mit neuen Daten, ihre Reproduzierbarkeit und das Benchmarking sind nicht zu unterschätzen.
Deploy your model – damit ist die Arbeit nicht getan
Wer ein per Jupyter Notebook in vielen Versuchen und Iterationen optimiertes und trainiertes Modell einfach deployt und in Produktion nimmt, darf nicht vergessen, alle Schritte zur Erstellung des Modells reproduzierbar vorzuhalten und in einer Pipeline zu automatisieren.
Übertrieben formuliert: Nichts ist so alt wie das gestern trainierte Modell. Kommen täglich neue Daten hinzu, müssen diese im Rahmen des Gesamtprozess in die Trainingsmenge einfließen und zur weiteren Verbesserung des Modell dienen. Es gilt also, die Spielwiese in eine Automationsumgebung zu überführen, die kontinuierlich Modelle erstellt und ihre Erkennungsrate mit aktuellen Daten misst. Online-Learning, Modellversionierung und On-the-fly-Benchmarks mit verschiedenen Versionen sind Konzepte, die zum Ansatz "Driver-less AI" (Auto-ML) führen.
Driver-less AI als Teil einer Plattform
Beherrschen der Komplexität, die Automatisierung der Modellerstellung sowie des Deployments, die stetige Verbesserung im Produktivbetrieb und eine direkte Operation auf den Daten dort, wo diese sich befinden – das sind entscheidende Aspekte, die sowohl für die Integration von ML- und NLP-Methoden in die Plattformen als auch für einen Ansatz sprechen, der als Auto-ML oder Driver-less AI bezeichnet wird.
Die Integration von ML- und NLP Methoden in die Plattformen zur Datenhaltung findet sich sowohl bei Datenbanken wie Google BigQuery ML, Vertica sowie SQL Server Machine Learning Services als auch im Enterprise Content Management (ECM) bei Content Services Platforms wie Doxis4 Cognitive Services. Gerade im ECM-Umfeld lassen sich hierbei NLP-Funktionen wiederverwenden, die im Bereich einer intelligenten Volltextsuche sowieso bereits vorhanden sind. Die Datenvorverarbeitung beruht hier auf ähnlichen Prinzipien. Tokenizer, Stemmer und TF/IDF-Statistik sind in Anwendungen wie Elasticsearch oder Apache Solr ohnehin integriert.
Der gesamte Schritt des Sammelns von Beispieldaten und der Datenvorverarbeitung vereinfacht sich dadurch deutlich. Nutzt ein ECM zur Verwaltung der Inhalte Metadaten und keine Ordnerstrukturen, so liegen gelabelte Inhalte vor, die sich mit einer einfachen Suchbedingung direkt für die Textklassifikation nutzen lassen. Das ECM dient hier unmittelbar als "ground truth" und Benchmarks in Bezug auf Verbesserungen oder Verschlechterungen der Erkennungsrate können einfach direkt im Produktivsystem erfolgen. Die Plattform speichert die trainierten Modelle direkt versioniert.
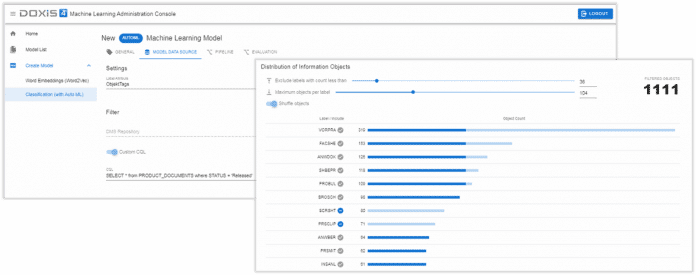
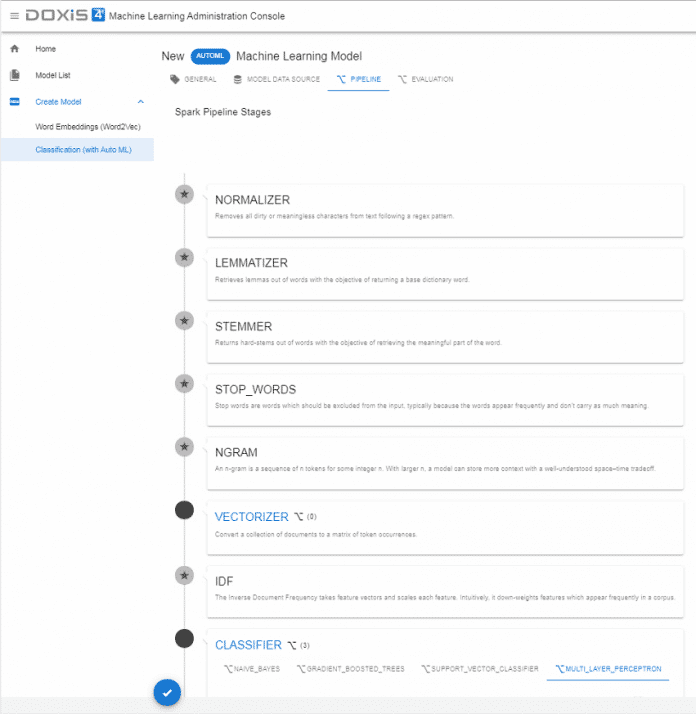
Die Komplexität lässt sich mit einem AutoML -Ansatz weiter reduzieren. Wie bei fast allen KI-Themen zählen Google, Salesforce & Co als Vorreiter (Google AutoML, Salesforce TransmogrifAI, AutoKeras [3] etc.). Aber auch andere Anbieter wie H2O.ai oder im Kontext von Content-Plattformen SER sind auf den Zug aufgesprungen. AutoML bedeutet in diesem Kontext [4], viele der oben am Beispiel der Textklassifikation dargestellten Optionen – vom Feature Engineering bis zur Model Selection und dem Parameter Tuning – automatisch zu evaluieren, um das beste Verfahren zu ermitteln. Dann bleibt nur noch die Entscheidung, nach welchem Kriterium das beste Verfahren ermittelt werden soll. Oft bietet sich der F1-Score als Mittelweg zwischen geringer Fehlerquote und hoher Erkennungsrate an – beides gleichzeitig ist noch Zukunftsmusik.
Letztlich liegt es nahe, das "Probieren geht über Studieren" zu automatisieren und mit der Automatisierung eine wohldefinierte und reproduzierbare Pipeline zur Erstellung und Anwendung von ML-Modellen in Produktivsystemen zu entwickeln. Die KI-Experten einiger Plattformhersteller haben den Baukasten bereits passend zusammengestellt, sodass Cognitive Services zum integralen Bestandteil der Plattform avancieren – so wie sich vor Jahren auch Workflow-Funktionen in ERP, CRM und ECM-Systeme etabliert haben.
Fazit: Vorkonfektioniert statt selbermachen
Im betrachteten Anwendungsfall Content Analytics sprechen zahlreiche Gründe für den Einsatz von Driver-less AI. ML-basierte Cognitive Services als Teil einer Daten- und Content-Plattform, kombiniert mit einem AutoML-Ansatz, sind tief integriert, einfach zu verwenden und nah an den Daten. Eine gesonderte Data Collection entfällt, die KI kommt direkt dort zum Einsatz, wo die Daten liegen. Darüber hinaus ergeben sich Synergieeffekte, da die Plattformen bereits weite Teile der nötigen Datenvorverarbeitung für unstrukturierte Inhalte standardmäßig mitbringen.
Da auch die benötigten Frameworks schon in die Plattform integriert sind, entfällt die Komplexität, aus dem Wildwuchs der verfügbaren Python-Bibliotheken, die für den konkreten Anwendungsfall passenden auszuwählen. Im Idealfall ist außerdem eine automatisierte, kontinuierliche Aktualisierung der Lernmengen und die sich daraus ergebende Optimierung der Modelle im Produktivbetrieb implementiert. Ein Punkt, der beim individuelleren Bring-your-own-AI-Ansatz häufig vergessen wird.
Da zudem ausgewiesene Experten für ML und NLP häufig schwer zu bekommen sind, stellt sich für viele Unternehmen die Frage erst gar nicht, ob der eigene KI-Baukasten die bessere Wahl ist. Ein GUI-basierter Ansatz erweitert den Kreis der möglichen Anwender deutlich, sodass Unternehmen eine größere Chance haben, geeignete Mitarbeiter zu finden.
Aber die individuelle Analyse und Exploration eines ML-Problems durch einen Experten hat ebenfalls ihre Vorteile, die auch in Zukunft maßgeschneiderte Ansätze rechtfertigen. So lassen sich Ad-hoc-Analysen einfacher erstellen und Individualanforderungen leichter umsetzen. Darüber hinaus stehen theoretisch alle KI-Frameworks zur Verfügung, nicht nur diejenigen, die ein Plattformhersteller integriert hat.
AutoML als integraler Teil einer Daten- und Content-Plattform ist noch ein recht neuer, wenig verbreiteter Ansatz. Nicht jedes Unternehmen wird daher direkt auf diesen Zug aufspringen wollen. Sobald aber diese Plattformen sowohl offene Plug-in-Schnittstellen bieten, um individuell weitere Frameworks zu ergänzen und in eine Analysekette einzubinden und zum anderen im Sinne der Content Federation einen einheitlichen Zugriff auf verschiedene Quellen bieten, dürften AutoML-Ansätze weiter an Attraktivität gewinnen.
Dr. Gregor Joeris (gregor.joeris@ser.de)
ist Chief Technology Officer der SER Group und der innovative Kopf hinter den SER-Technologien & -Produkten. Er hat an der RWTH Aachen Informatik studiert und in Bremen promoviert. Heute steht Dr. Joeris federführend für die Konzeption und Weiterentwicklung der Enterprise Content Management-Plattform Doxis4.
Weiterführende Informationen:
- Comparative study of CNN and RNN for natural language processing [5]
- Towards Automated Machine Learning: Evaluation and Comparison of AutoML Approaches and Tools. [6]
(map [7])
URL dieses Artikels:
https://www.heise.de/-4582953
Links in diesem Artikel:
[1] https://www.heise.de/select/ix/2019/10/1922716211702851464
[2] https://developers.google.com/machine-learning/guides/text-classification/step-2-5
[3] https://towardsdatascience.com/autokeras-the-killer-of-googles-automl-9e84c552a319
[4] https://www.ser.de/technologie/content-analytics.html
[5] http://arxiv.org/abs/1702.01923
[6] https://arxiv.org/abs/1908.05557
[7] mailto:map@ix.de
Copyright © 2019 Heise Medien