Daten aus dem Fitnesstracker analysieren mit Azure Synapse Analytics

(Bild: Maridav / Shutterstock.com)
Die Datenanalyse in einem Serverless-Clouddienst erfordert nur minimalen Programmieraufwand, wie ein Beispiel mit eigenen Fitnessdaten zeigt.
Mit der Azure Data Factory (ADF) hat Microsoft die Funktionen eines klassischen Data Warehouse in die Cloud übertragen. Der neuere Dienst Azure Synapse Analytics (Azure Synapse) geht noch einen Schritt weiter und verknüpft Data Warehousing mit Big Data und Data Science. Wie sich der Cloudservice einfach für die codefreie Datenintegration und Analyse nutzen lässt, verdeutlicht ein Beispiel mit Daten aus einem gängigen Fitnesstracker, dem Xiaomi Mi Fit INTELLI-Band 4.
Use Case aus der Praxis
Azure Synapse baut grundsätzlich auf der gleichen Engine für die Datenintegration auf und bietet die gleichen Arbeitsumgebungen wie ADF, Funktionen rund um die Integration Runtime und Power Query fehlen hingegen [1]. Spark Pools und die Überwachung von Datenflüssen stehen hingegen nur in Azure Synapse zur Verfügung. Das folgende praktische Beispiel verwendet konkret die Azure Synapse Batch ETL Pipeline inklusive der serverlosen SQL-Ressourcenmodelle.
Die zu analysierenden Daten kommen von dem Fitnesstracker von Xiaomi und umfassen die Tagesaktivität (Anzahl Schritte und zurückgelegte Distanz pro Tag) sowie die Schlafaktivität (Tiefschlaf und Leichtschlaf). Obwohl einerseits die Mi-Fit-App auch Statistiken zur Verfügung stellt und sich andererseits in öffentlich zugänglichen Quellen im Internet für die Analyse geeignete Daten finden ließen, zieht es der Autor als experimentierfreudiger Data Engineer vor, mit eigenen Daten zu spielen.
Die Daten lassen sich als zwei CSV-Dateien in Azure Blob Storage hochladen, wo die Azure Synapse Pipeline sie extrahiert, transformiert und in eine gemeinsame CSV-Datei überführt. Danach werden die Daten im serverlosen Azure Synapse SQL-Pool analysiert (Abbildung 1).

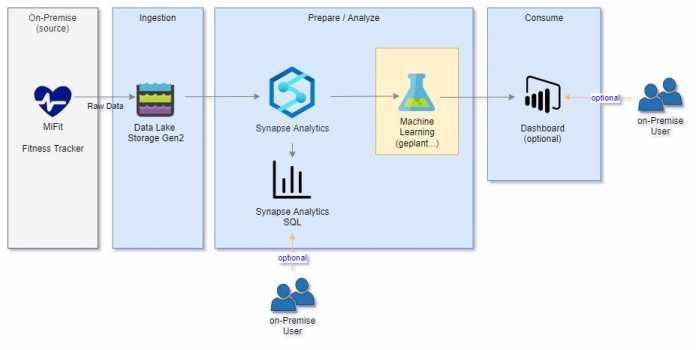
Die Anzahl der Daten ist überschaubar, was für den serverlosen Azure Synapse SQL-Pool von Vorteil ist, weil er nur nach Verwendung abgerechnet wird. Welche Kosten dabei konkret entstehen können, zeigen die Details zu einem praktischen Beispiel am Ende des Artikels.
Daten bereitstellen
Besitzer eines Fitnesstracker haben das Recht, eigene Daten vom Gerät zu exportieren – nicht zuletzt dank der DSGVO. Bei dem hier verwendeten Tracker ist dieser Prozess doch nicht so einfach, und es finden sich nur wenige hilfreiche Informationen [2] im Internet.
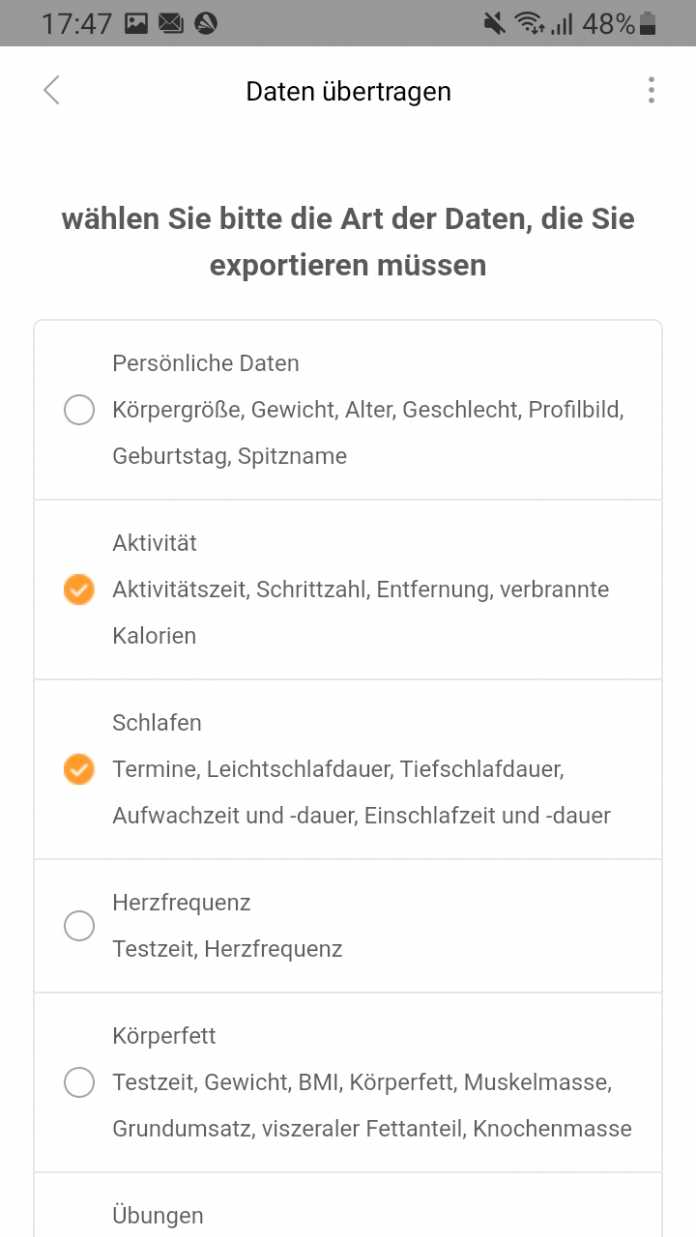
Die verkürzte Zusammenfassung, der beim vorliegenden Fitnesstracker erforderlichen Schritte unter Android 9, 10 oder 11 lautet:
- In der App unten in der Leiste auf Profil tippen
- Nach unten scrollen und Einstellungen auswählen
- In den Einstellungen auf Über gehen und wieder nach unten zum Punkt Benutzerrechte ausüben scrollen
- Im Punkt Benutzerrechte ausüben wieder nach unten scrollen und Daten übertragen auswählen
- Im Punkt Daten übertragen kann man endlich alle notwendigen Daten auswählen (s. Abb. 2) und an eine E-Mail-Adresse schicken lassen
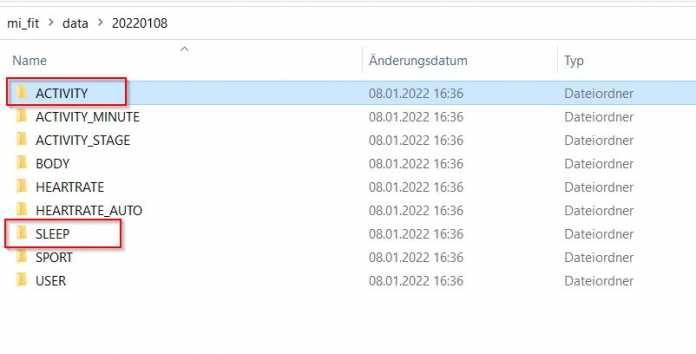
Via App überträgt der Fitnesstracker die Daten zunächst zum Austauschserver, der binnen weniger Minuten eine E-Mail mit dem Downloadlink und dem Passwort verschickt. Unter dem enthaltenen Link liegt eine passwortgeschützte ZIP-Datei parat. Nachdem die Datei heruntergeladen und entpackt ist, sieht die Verzeichnisstruktur wie in Abbildung 3 aus. Für das Beispiel in diesem Artikel sind nur die Dateien ACTIVITY.csv und SLEEP.csv relevant. Die Struktur dieser Daten gibt Abbildung 4 wieder. Nach der Vorbereitung von Azure Synapse Analytics lassen sich beide Dateien in die Azure Cloud hochladen.
Besitzer einer Apple Watch kommen übrigens laut einem Beitrag bei Medium [3] in nur drei Schritten, an ihre Daten und eine geeignete ZIP-Datei. In dem ZIP-Archiv findet sich dann eine große XML-Datei, die für die Verarbeitung in Azure Synapse lediglich geparst werden sollte.

Vorbereitungen für Azure Synapse Analytics
Um sämtliche beschriebenen Schritte in der Azure Cloud nachvollziehen zu können, sind eine Registrierung im Azure Cloud Portal sowie ein aktives Abo erforderlich. Die Registrierung ist kostenlos und die ersten 30 Tage stehen die Azure-Angebote kostenfrei zum Testen zur Verfügung. Nach dieser Probephase verlangt der Cloud-Anbieter für die meisten Komponenten jedoch Gebühren. Azure Synapse zählt nicht dazu, aber das Verwenden des mitgelieferten Serverless SQL-Pool wird nach Auslastung abgerechnet. Die Verarbeitung sämtlicher Daten aus dem Beispiel erfolgt in der Azure Cloud, eine lokale Entwicklungsumgebung ist nicht nötig. Es empfiehlt sich jedoch eine stabile Internetverbindung zum Azure Portal.
Basierend auf den von Azure empfohlenen Best Practices sollte eine eigene Ressourcengruppe sowie ein Storage-Account für Azure Synapse erstellt werden. Außerdem sollte die Azure-Region Deutschland ausgewählt sein (s. Abb. 5). Anhand einer kurzen Einführung in Azure Synapse [4] sowie einer Schritt-für-Schritt Anleitung zum Erstellen des Azure-Synapse-Arbeitsbereichs [5] finden sich auch Einsteigerinnen und Einsteiger rasch zurecht. Das Bereitstellen von Azure Synapse dauert nur wenige Minuten. Anschließend sollte sich die Ressourcengruppe ähnlich wie in Abbildung 6 darstellen. Damit steht eine codelose Entwicklungsumgebung in Azure Synapse Studio zum Experimentieren bereit, die sich per Klick in den Azure Synapse Workspace starten lässt.


Erstellen der Pipeline in Azure Synapse Analytics
Vor dem Erstellen der Pipeline liegen die Dateien ACTIVITY.csv und SLEEP.csv im gleichen Azure Data Lake Storage (siehe Abbildung 7) wie der Azure Synapse Workspace. Aus architektonischen Gründen ist es zwar ratsam beide voneinander getrennt abzulegen, für das vorliegende Beispiel kann man dieses Pattern aber vernachlässigen.

Azure Synapse bietet verschiedene Pipelines. In diesem Artikel kommt die Pipeline mit Dataflow zum Einsatz (siehe Abbildung 8), die folgende Aktionen ausführt:
- Liest die Dateien ACTIVITY.csv und die SLEEP.csv ein
- Joint die Dateien anhand ihres Erfassungsdatums
- Filtert überflüssige Spalten (z. B.
runDistance) heraus - Berechnet
totalSleepTimeund splittet das Datum in die drei Spalten "Tag", "Monat" und "Jahr" - Schreibt das Ergebnis in eine gemeinsame ACTIVITY_SLEEP.csv-Datei

Sämtliche Aktionen lassen sich in Azure Synapse Studio einrichten, ohne dafür Code zu schreiben. Die allgemeine Vorgehensweise zum schrittweisen Erstellen von Pipelines mit Dataflow fasst eine Quick-Start-Anleitung [6] zusammen. Zu den vorbereitenden Maßnahmen für den Dataflow im Beispiel zählt auch das Einrichten eines Linked Service (verknüpfter Dienst) zu dem Account in Azure Data Lake Storage Gen2, in dem die Dateien ACTIVITY.csv und SLEEP.csv gespeichert sind. Darüber hinaus bedarf es zweier Input-Integration-Datensätze: dsACTIVITY für ACTIVITY.csv (s. Abb. 9) und dsSLEEP für SLEEP.csv sowie eines Output-Integration-Datensatzes dsOutACTIVITYundSLEEP für ACTIVITY_SLEEP.csv.

Das Zusammenlegen der Dateien lässt sich durch die Bedingung Inner-Join definieren (s. Abb. 10) und die selektierten Spalten in der Select-Activity festlegen, wie Abbildung 11 zeigt. Im nächsten Schritt lassen sich die neuen Spalten im Expression Builder bauen (Abbildung 12), anschließend die Daten nach dem Erfassungsdatum aufsteigend sortieren (Abbildung13) und schließlich in ACTIVITY_SLEEP.csv speichern. Da sämtliche Daten in einer Datei landen sollen, muss die Option Single Partition ausgewählt sein. Das gleiche gilt für die Sortierung: Denn sonst werden die Current-Partitionen getrennt sortiert und nach dem Zufallsprinzip in einer Datei zusammengeführt. Das Ergebnis wäre dann eine unsortierte Datenmenge in der CSV-Datei.


Nachdem die Pipeline fertiggestellt und in Azure Synapse veröffentlicht ist, lässt sie sich im Menü "Pipelines" anstoßen (Trigger hinzufügen / Jetzt auslösen). Danach sind die Ausführungen im Azure Synapse Monitor zu sehen (Abbildung 14).

Das Beispiel umfasst insgesamt 695 Sätze von Schlafdaten und zurückgelegten Schritten, die allein aus dem Jahr 2021 stammen, und zur Analyse in den serverlosen Azure Synapse SQL-Pool einfließen.
Erstellen des serverlosen Azure Synapse SQL Pools und Analyse der Daten
Gegenüber einem dedizierten SQL-Pool hat der in Azure Synapse integrierte serverlose SQL-Pool einige Einschränkungen – er unterstützt beispielsweise nur externe Tabellen. Da er aber nur nach Verwendung abgerechnet wird, lässt er sich zur SQL-Analyse der Fitnesstrackerdaten kostengünstiger nutzen. Dabei ist es grundsätzlich möglich, die master-Datenbank des integrierten SQL-Pool zu verwenden, besser ist es aber, alle benutzerdefinierten Datenbankobjekte in einer separaten Nicht-master-Datenbank anzulegen [7] (Abbildung 15).

Sobald diese neue Datenbank fertig ist, lässt sich der Editor auf sie umschalten, um die weiteren benutzerdefinierten Datenbankobjekte zu erstellen. Für den Zugriff auf die externe Tabelle ACTIVITY_SLEEP (Listing 1) benötigt man zuerst Data Source (Datenquelle) und File-Format (Abbildung 16). Sind diese Objekte vorhanden und die externe Tabelle erstellt, lässt sich die SQL-Abfrage auf diese externe Tabelle ausführen (Listing 2). Die Ergebnisse erscheinen standardmäßig in tabellarischer Form, im visuellen Editor von Azure Synapse lässt sich aber auf die Diagramm-Ansicht umschalten, um wie in Abbildung 17 gezeigt, verschiedene Grafiken darstellen zu können.
Listing 1: Erstellen der externen Tabelle für die Datei ACTIVITY_SLEEP.csv
CREATE EXTERNAL TABLE MiFit.ACTIVITY_SLEEP (
[date] date,
[steps] int,
[distance] int,
[calories] int,
[deepSleepTime] int,
[shallowSleepTime] int,
[wakeTime] int,
[startSleep] datetime2(0),
[stopSleep] datetime2(0),
[totalSleepTime] int,
[year] int,
[month] int,
[day] int
)
WITH (
LOCATION = 'out/ACTIVITY_SLEEP.csv',
DATA_SOURCE = [dsExternalData],
FILE_FORMAT = [skipHeaderCSV]
)
GO
Listing 2: Beispiel der SQL-Abfrage zur Analyse der Fitnesstrackerdaten (vgl. Abb. 17)
SELECT TOP (1000) [month]
,avg([deepSleepTime]) as "Durchschnitt Tiefschlaf (Minuten)"
,avg([shallowSleepTime]) as "Durchschnitt Leichtschlaf (Minuten)"
,avg([totalSleepTime]) as "Durchschnitt Schlaf (Minuten)"
,round(sum([steps]) / 1000, 0) as "Summe Schritte (x1000)"
,avg([steps]) as "Durchschnitt Schritte"
,round(sum([distance]) / 1000, 0) as "Summe Distanz (km)"
FROM [MiFit].[ACTIVITY_SLEEP]
WHERE [year] = 2021
GROUP BY [month]
ORDER BY [month]
Das vorgestellte Beispiel macht die prinzipielle Vorgehensweise beim Aufbauen einer lauffähigen Azure Synapse Pipeline deutlich. Alternativ lassen sich die zwei Dateien ACTIVITY.csv und SLEEP.csv auch ohne Pipeline – via SQL "on the fly" – im serverlosen SQL Pool joinen, um ein ähnliches Ergebnis wie ACTIVITY_SLEEP.csv zu erhalten. Allerdings ist dabei zu beachten, dass unnötige beziehungsweise oft ausgeführte Joins die Laufzeiten erhöhen, die Beanspruchung der Azure-Ressourcen erhöhen und damit zu steigenden Kosten führen.
Die Analyse der Daten im Use Case setzt stillschweigend voraus, dass die tägliche Aktivität (zurückgelegte Distanz in km) vom Schlaf abhängig ist. Das ist grundsätzlich sicherlich weitgehend zutreffend, die Daten aus dem Monat November widersprechen allerdings dieser Annahme – und erfordern daher noch eine tiefergehende Untersuchung.
Kostenabschätzung zum Use Case
Für das vorgestellte Beispiel fallen folgende Kosten an:
- Kosten für Storage-Account (Speicherplatz) des Azure Synapse Workspace und für die Haltung der Fitnesstrackerdaten.
- Kosten für das Ausführen der Pipeline und das Nutzen des integrierten SQL Pools
Da die Daten nur einige KByte groß und die Laufzeiten der Pipelines sowie der SQL-Abfragen kurz sind, fallen für die Verarbeitung der Beispieldaten nur die in Abbildung 18 aufgeführten Kosten an.

Zusammenfassung und weitere Schritte
Mit diesem einfachen Beispiel lässt sich der Prozess zum Vorbereiten der Daten für die Analyse im serverlosen Pool via Pipeline in Azure Synapse mehr oder weniger komplett nachvollziehen. Die konkrete Aufgabe hilft, das Azure Synapse Studio und dessen Werkzeuge besser kennenzulernen. Der Analyse der Daten liegt die Annahme zugrunde, dass die Aktivität vom Schlaf – und insbesondere vom Tiefschlaf – abhängig ist. Da das Jahr 2020 vom coronabedingten Lockdown geprägt war, sind nur die Daten von 2021 berücksichtigt. Die Annahme bezüglich der Korrelation zwischen Schlaf und Aktivität lässt sich demnach grundsätzlich durch die grobe Analyse bestätigen. Allerdings zeigen die Daten für November 2021 eine deutliche Abweichung. Als Grund dafür könnte besonders regnerisches Wetter in Nürnberg in diesem Zeitraum die Aktivitäten des Trägers des Fitnesstrackers beeinflusst haben.
Was kommt als nächstes? Die Analyse ließe sich weiter verfeinern und um Wetterdaten ergänzen, sofern die dazu notwendigen GPS-Koordinaten vorlägen. Mit Azure Machine Learning (Azure ML) ließe sich zudem ein Modell aufbauen, das prüft, welche Schlafgewohnheiten die Aktivität besser fördert. Damit ließe sich beispielsweise ermitteln, ob kurze oder längere Schlafphasen zu mehr Aktivität führen, oder ob Tiefschlaf effektiver wirkt als lange zu schlafen.
Das Beispiel zeigt, wie sich eine Azure Synapse Pipeline für einen praktischen Use Case schnell und mit wenig Aufwand erstellen lässt. Das überschaubare Datenvolumen aus dem Fitnesstracker ließe sich zwar prinzipiell auch auf einem Einplatinencomputer wie dem Raspberry Pi mit Pythoncode vergleichsweise einfach und schnell analysieren, aber Azure Synapse bietet demgegenüber umfangreiche Möglichkeiten "out of the box". Die Kosten des Clouddienstes sind beim Experimentieren zudem überschaubar und die Lernkurve ist auch für Neulinge nicht zu steil. Erst wenn produktive Einsatzszenarien ins Spiel kommen, die etwa die DDL-Möglichkeiten eines dedizierten SQL-Pool oder gar eines Spark-Pool erfordern, und automatisches Deployment sowie Securityanforderungen hinzukommen, empfiehlt sich ein genauerer Blick auf die Preismodelle in der Azure-Cloud.
Vladimir Poliakov
absolvierte 1995 das Studium an der Russian State Hydrometeorological University (RSHU) in St. Petersburg und arbeitete im Forschungsinstitut für Arktis und Antarktis. Nach seiner Auswanderung nach Deutschland war er seit 1998 in der IT-Branche als Entwickler, DBA, Systemarchitekt, BI- und Big-Data-Spezialist aktiv und ist zurzeit hauptberuflich als Data Integration Engineer bei der TeamBank AG tätig.
(map [8])
URL dieses Artikels:
https://www.heise.de/-6670082
Links in diesem Artikel:
[1] https://docs.microsoft.com/de-de/azure/synapse-analytics/data-integration/concepts-data-factory-differences
[2] https://korniichuk.medium.com/export-xiaomi-data-87f7e284b379
[3] https://medium.com/@dhangerkapil/how-i-used-azure-databricks-synapse-analytics-and-azure-machine-learning-to-get-insights-from-the-f18fb89ed2e5
[4] https://docs.microsoft.com/de-de/azure/synapse-analytics/get-started
[5] https://docs.microsoft.com/de-de/azure/synapse-analytics/get-started-create-workspace
[6] https://docs.microsoft.com/de-de/azure/synapse-analytics/quickstart-data-flow
[7] https://docs.microsoft.com/de-de/azure/synapse-analytics/get-started-analyze-sql-on-demand
[8] mailto:map@ix.de
Copyright © 2022 Heise Medien