

Fachliche Schulden als Kontrapunkt zu "Technical Debt"
Die meisten IT-Profis haben sicherlich schon technische Schulden erfahren, identifiziert, produziert und hoffentlich reduziert. Die wenigsten jedoch haben sich intensiver mit fachlichen Schulden (Domain Debt) auseinandergesetzt. Was sind fachliche Schulden und warum müssen sie ernster genommen werden?

- Sven-Torben Janus
Eine konkrete wissenschaftliche Definition technischer Schulden gibt es nicht. Die Merkmale zu ihrer Identifikation sind sogar sehr ambivalent. Beispielsweise zählt die Nichtausführung bestimmter Aufgaben oder deren Aufschiebung auf einen zukünftigen Zeitpunkt dazu. Wer hat schließlich noch nicht von fehlender Dokumentation oder unzureichenden Tests gehört? Aber auch die Nutzung von Anti-Patterns,
schlechtem Programmierstil oder fehlende Standards sind kennzeichnend. Trotz dieser Ambivalenz gibt es oftmals einen gemeinsamen Kernpunkt: Technische Schulden sind Aufwandstreiber.
Software mit technischen Schulden ist schwieriger zu warten als Software ohne technische Schulden. Ihre Weiterentwicklung und Wartung dauert schlichtweg länger und ist somit kostenintensiver. Je länger technische Verschuldung besteht, desto teurer wird deren Beseitigung. Schlimmer noch, wenn weitere technische Schulden hinzukommen. Die Softwarebranche scheint sich an solche Schulden gewöhnt zu haben. Zwar versucht man sie zu bekämpfen, jedoch lassen sie sich anscheinend nicht gänzlich vermeiden – und das ist nicht wertend gemeint.
Was in der Softwarebranche jedoch nahezu nie oder zumindest nur sehr selten diskutiert wird, sind fachliche Schulden. Zumindest sind die wenigen Stimmen, die sich zum Thema äußern, in der breiten Masse kaum wahrnehmbar.
(Miss-)Verständnisse
Allerdings gibt es diese Stimmen. Beispielsweise sagte der EventStorming-Erfinder Alberto Brandolini 2017: "It's developer's (mis)understanding, not expert knowledge, that gets released in production."
Wenn das stimmt, müsste man fordern, dass alle Entwickler Fach- beziehungsweise Domänenexperten werden. Aber wie verhält es sich, wenn Entwickler (noch) keine solchen Experten sind? Was ist, wenn sie in einem Lernprozess und damit erst auf dem Weg sind, Experten zu werden? Sie machen Fehler, denn diese sind wichtig, um zu lernen. Beispielsweise tendieren Entwickler dazu anzunehmen, dass Konzepte und Modelle aus einem Kontext der Domäne auch in einem anderen gültig sind. Manchmal erstellen sie inakkurate Abstraktionen und Modelle, weil ihnen Kontextinformationen fehlen – einfache Informationen wie das "Big Picture" oder darüber, wie ihre aktuelle Aufgabe die Bedüfnisse von Benutzern oder Geschäftsprozesse unterstützt.
Auf diese Art kommt es immer wieder vor, dass sich (möglicherweise fehlgeleitete) Hunderttausend-Euro-Entscheidungen in Code manifestieren, der nicht an Geschäftszielen ausgerichtet ist, die niemals jemand deutlich geäußert hat. Als Resultat sind Nachbesserungen und Refactorings unausweichlich.
Welche Art von Fehlern oder Missverständnissen auch existieren, sie schlagen sich in Code nieder. Entwickler verbringen Zeit damit, solchen Code zu schreiben, und gewinnen hoffentlich neue Einblicke in ihre Problemdomäne. Sie refaktorisieren Code, justieren Modelle oder gestalten Kontexte neu. Manager strukturieren Teams neu und widmen Verantwortlichkeiten um. All das kostet Zeit, Aufwand und am Ende Geld. Ist daher Code nicht als eine Art Aufwandstreiber anzusehen? Handelt es sich dabei um Schulden – fachliche, nichttechnische Schulden?
Schulden analysieren
Um diese Fragen zu beantworten, soll folgendes reales Beispiel betrachtet werden. Ein Eisenbahnunternehmen arbeitet mit mehreren Teams an der Neuimplementierung eines größeren Softwaresystems. Wer ein System für ein solches Unternehmen entwickelt, modelliert (manchmal nicht so) offensichtliche Dinge wie Zugfahrten, Segmente, Abschnitte, Halte oder Bahnhöfe.
Das Projekt hatte das System in unterschiedliche Kontexte gegliedert. Die darin verankerten Anwendungsfälle basierten auf unterschiedlichen Modellen von Zugfahrten. In einem Kontext bestand eine Zugfahrt aus einer Sequenz von Halten. Ein Halt bezog sich auf einen Bahnhof sowie eine Abfahrts- und Ankunftszeit. In einem anderen Kontext nutzte ein Anwendungsfall ein Modell, in dem eine Zugfahrt aus einer Sequenz von Abschnitten bestand. Ein Abschnitt hatte einen Abfahrts- und Ankunftsbahnhof jeweils mit Abfahrts- und Ankunftszeit. In anderen Kontexten wiederum bestand eine Zugfahrt aus einer Sequenz von Segmenten und jedes Segment aus einer Sequenz von Abschnitten. Wieder andere hatten Segmente, die aus Halten bestanden.
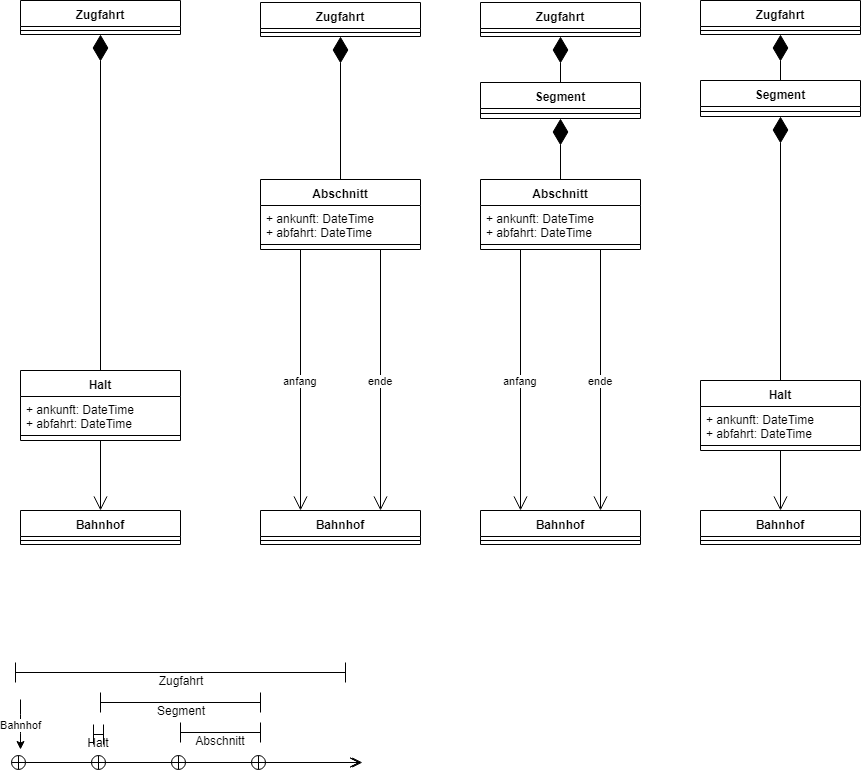
Manchmal sahen die Modelle austauschbar aus, obwohl sie sich in Feinheiten unterschieden. Beispielsweise lässt sich eine Sequenz von Abschnitten in eine Sequenz von Halten umrechnen. Je nach Kontext war das eine oder andere Modell jedoch geeigneter für den jeweiligen Anwendungsfall.
Eines der Teams tat sich schwer mit der Implementierung eines Anwendungsfalls. Sie fühlte sich sperrig an, und jede Änderung an der Software dauerte länger als erwartet. Das Team führte einige Diskussionen dazu mit einem der Architekten und diese führten zu einem neuen Modell. Im Kern stand ein neues UML-Klassendiagramm, mit dem alle Beteiligten zufrieden waren. Letztlich kam es zu einer hohen Aufwands- und Kostenschätzung für ein Refactoring, das im Wesentlichen einer Neuimplementierung einiger Kernmodule gleichkam. Aufgrund des hohen Aufwands sollte ein inkrementeller Weg zum Refactoring gefunden werden, der einige schnelle "Quick Wins" erlauben sollte.
Ein Lernprozess
So wurde zunächst der Code analysiert und insbesondere die Historie sämtlicher Änderungen am Code. Dabei ließen sich einige Hotspots ermitteln. Es handelte sich um Teile des Codes, die eine hohe Komplexität beziehungsweise hohe Kopplung aufwiesen sowie oft und von fast allen Entwicklern verändert wurden. Weitere Analysen der Hotspots und deren Veränderungshistorie ergaben weitere spannenden Einblicke. Beispielsweise gab es folgende Methode:
List<Abschnitt> getAbschnitte() {
return getSegmente()
.map(segment -> segment.getAbschnitte().stream())
.collect(Collectors.toList();
}
Die Methode wurde im Rahmen einer Delta-Berechnung genutzt, die zum Beispiel bei der Planung neuer Halte einer Zugfahrt zum Einsatz kommt:
List<Delta> calculateDelta(Zugfahrt base, Zugfahrt new) {
return calculateDelta(base.getAbschnitte(), new.getAbschnitte()) {
}
Darüber hinaus ließ sich folgende Zeile finden:
List<Abschnitt> abschnitteAdded = detectAbschnitteAdded()
Sie nutzte die oben genannte calculateDelta-Methode. Bei weiterer Betrachtung der Änderungshistorie fiel folgende kleine Änderung an der Zeile auf:
List<Abschnitt> halteAdded = detectAbschnitteAdded()
Es stellte sich die Frage, ob hier ein Algorithmus auf Basis von Abschnitten oder von Halten für die Berechnung der Deltas sinnvoller war. Mit der Änderung ging eine weitere in der calculateDelta-Methode einher:
List<Delta> calculateDelta(Zugfahrt base, Zugfahrt new) {
return calculateDelta(calculateHalteFrom(base.getAbschnitte()), calculateHalteFrom(new.getAbschnitte()));
}
List<Stop> calculateStopsFrom(List<Section> sections) {
// ...
}
Noch später in der Änderungshistorie gab es eine Änderung, die den betrachteten Hotspot in eine andere Klasse verschob und umformulierte:
List<Halt> halteAdded = detectHalteAdded();
Auf den ersten Blick sahen die Änderungen aus wie ein einfaches Refactoring. Die Delta-Erkennung wurde von einem auf Abschnitten basierenden auf einen auf Halten basierenden Algorithmus umgestellt. Allerdings war nun die Codebasis durchzogen mit Transformationen hin und zurück von Segmenten auf Abschnitte und diese wiederum auf Halte.
Fehler nicht zweimal machen
Es wurde nun deutlich, warum das Team die Implementierung sperrig empfand und nicht so richtig produktiv wurde. Das Team musste verstehen, ob es Abschnitte oder Halte als Kern seines Modells nutzen wollte. In einer Review mit UX Engineer und Product Owner ergab sich, dass an der Stelle tatsächlich nur ein haltebasierter Algorithmus sinnvoll ist. Ein klassischer Lernprozess, bis das Team zu der Erkenntnis kam, einen solchen Algorithmus verwenden zu wollen.
Ein weiterer Blick auf das neue UML-Modell zeigte jedoch, dass im Kern Zugfahrten mit Abschnitten modelliert wurden. Darüber hinaus sollten Halte aus Abschnitten abgeleitet beziehungsweise berechnet werden. Das war das vollständige Gegenteil der Erkenntnisse, die das Team gesammelt hatte und die Experten für sinnvoll hielten. Letztlich wurde gegen diese Form der Neuimplementierung entschieden. Stattdessen entschied man sich für kleinere Refactorings, die Abschnitte vollständig aus dem Code entfernen. Aber das war nicht der Kernpunkt. Vielmehr kamen grundlegende Fragen auf.
Schulden bewältigen
Welches Problem packt dieses Refactoring an? Sind Refactorings nicht das Mittel der Wahl, um technische Schulden abzubauen? Zumindest erscheint das gängige Meinung oder zumindest Praxis in der Softwareindustrie zu sein. Demgegenüber steht jedoch, dass die Codebasis sauber und gut geschrieben war. Sie war gut getestet und folgte gängigen Softwaredesign-Prinzipien. Allerdings war das grundlegende Modell fundamental ungeeignet, da es den Entwicklern anfangs an Fachwissen über diesen Teil der Fachdomäne und des Problemraums fehlte. Als Ergebnis ihrer Designentscheidungen war der Aufwand für das Hinzufügen neuer Features deutlich höher, als sie mit einem anderen Modell hätten sein müssen.
Wie verhält sich das nun zu technischen Schulden? Wie zuvor erwähnt, manifestieren sich Schulden in der Regel als Aufwandstreiber. Das initiale Erstellen und Implementieren des Modells kosteten Zeit und Geld. Gleiches gilt für die durchgeführten Refactorings. Die Neuimplementierung hätte ebenfalls viel Zeit und Geld gekostet. In diesem Sinn gab es hier eine Menge Aufwandstreiber.
Handelt es sich dabei jedoch um technische Schulden? Nirgends in der Problematik tauchen technische Konstrukte wie Microservices, Message Queues, Datenbanken, fehlende Dokumentation, schlechter Programmierstil oder zu geringe Code Coverage auf. Das Problem dreht sich lediglich um ein Modell, das nicht genügend auf den Anwendungsfall zugeschnitten war. Vielleicht handelte es sich hier nur um die Manifestation der (Miss-)Verständnisse von Entwicklern über die Fachdomäne. Abgesehen von der Tatsache, dass man Code immer als technisches Artefakt ansehen kann, waren hier keine technischen Aspekte zu finden.
Domain Debt
Es handelt sich hier nicht um technische, sondern vielmehr um fachliche Schulden (Domain Debt). In den Codebasen dieser Welt schlummern Tonnen solcher Schulden. Die Softwareindustrie redet jedoch nur wenig darüber. Sie übernimmt viel zu wenig Verantwortung dafür. Dabei haben IT-Teams heute viele wirksame Methoden an der Hand, um fachliche Schulden zu verhindern oder ihnen zu begegnen.
Einige wie eine allgegenwärtige Sprache (Ubiquitous Languages) oder abgegrenzte Kontexte (Bounded Context) sind seit über 15 Jahren bekannt. Sie rückten vor allem in den letzten Jahren durch den Microservice-Trend wieder vermehrt in den Fokus. Die Aufteilung von Systemen in viele kleinere Teile erfordert in der Regel eine strikte Trennung von Funktionen unter fachlichen Gesichtspunkten.
Diese Trennung fördert oftmals allerdings das zuvor genannten Problem zu Tage. Bei nicht konsequent verfolgten fachlichen Schnitten werden (Teil-)Modelle von einem Kontext in einen anderen übernommen. Das zuvor genannte Fallbeispiel weist solche Aspekte auf. Hier hätten klarere Abgrenzungen der Modelle sicherlich geholfen. Genau den Vorteil bieten abgegrenzte Kontexte. Sie trennen die Anwendbarkeit eines
Domänenmodells klar und deutlich von anderen Kontexten. Zugleich gewährleisten sie somit eine konzeptionelle Integrität.
Ein großes Problem dieser Abgrenzung ist allerdings, dass eine Fachsprache oftmals nur kontextbezogen eindeutig ist. Schaut man sich das zuvor genannte Beispiel der Zugfahrten an, wird das deutlich. Von welcher Art Zugfahrt spricht man, wenn keine Kontextinformationen vorhanden sind? Daher ist es umso wichtiger, eine allgegenwertige Sprache zu etablieren und diese rigoros anzuwenden – von der Anforderungserhebung über die Dokumentation bis in den Code.
Dabei ist es wichtig zu verstehen, in welchem Kontext man sich grade bewegt. Das ist insbesondere für Entwickler schwierig, die oftmals mit mehreren Kontexten konfrontiert sind. Ein guter Teamschnitt oder soziotechnische Architekturpatterns können hier Abhilfe schaffen.
Von DDD lernen
Vielfach hilft es allerdings nur, das Big Picture mit allen Kontexten oder zumindest angrenzende Kontexte und deren Abgrenzungskriterien zu verstehen. Methoden wie Event Storming oder Domain Story Telling, die in den letzten Jahren vor allem in der DDD-Community (Domain-Driven Design) entstanden sind, sind ein hervorragendes Mittel, um dieses Verständnis in frühen Phase gemeinsam im Team zu erarbeiten. Sie sind aber auch auf unterschiedlicher technischer wie fachlicher Tiefe und iterativ, inkrementell anwendbar.
So hilft Event Storming als Form eines informellen, moderierten Workshops ein gemeinsames Verständnis des Domänenmodells zu schaffen und unter den beteiligten Personen zu teilen. Das wird vor allem durch Teilnahme möglichst vieler Interessensvertreter erreicht. Egal ob Entwickler, Product Owner, Projektleiter oder Fachexperte, alle sind gemeinsam an der Modellierung beteiligt. Die Modellierung erfolgt mit einer großen Menge Post-its an einer Wand. Dabei wird das Modell in der Regel vorwärts und rückwärts durchgegangen, um sicherzustellen, dass alle relevanten Punkte abgedeckt sind. Die Methode erlaubt es, mögliche auftretende Ereignisse, deren Auslöser, Informationen, Benutzer, externe Systeme bis hin zu zeitlichen Aspekten zu modellieren. So entsteht eine gemeinsame Ausrichtung des Entwicklungsteams mit den Fachexperten und eine gemeinsame Terminologie. Vielen Missverständnissen lässt sich auf diese Art einfach entgegenwirken und fachliche Schulden vermeiden.
Mit all diesen Methoden an der Hand ist es daher letztlich an der Zeit, dass die Softwareindustrie und jeder Einzelne (sei es Enwickler, Product Owner, Projekt Manager ...) seinen Teil an Verantwortung übernimmt, um fachlichen Schulden mindestens genau so zu begegnen wie technischen Schulden.
Sven-Torben Janus
ist mitverantwortlich für den Bereich Softwarearchitektur bei der Conciso GmbH. Er befürwortet einen agilen und praktikablen Entwurf von Softwarearchitekturen. Sein Unbehagen über technologiegetriebene Designs führte ihn zum Domain-Driven Design und zur Gründung des DDD Meetup Rhein/Main.
(ane)
