

Herausforderung Brownfield, Teil 4: Komplexität bewältigen durch Differenzierung
Ist das Sicherheitsnetz bei einer Brownfield-Anwendung aus automatisierten Tests, Versionskontrolle und automatisierter Produktion gespannt, geht es darum, den Code zu säubern und ihn sauber zu halten. Das bedeutet, dass Funktionseinheiten klar definierte Verantwortlichkeiten haben.
- Ralf Westphal
- Stefan Lieser

Ist das in den letzten Artikeln der Artikelserie beschriebene Sicherheitsnetz bei einer Brownfield-Anwendung aus automatisierten Tests, Versionskontrolle und automatisierter Produktion gespannt, geht es darum, den Code zu säubern und ihn sauber zu halten. Das bedeutet, dass Funktionseinheiten klar definierte Verantwortlichkeiten haben.
Dass man automatisiert testen sollte, ist nicht neu, in vielen Projekten sind Unit-Tests aber immer noch keine Selbstverständlichkeit, geschweige denn Test-Driven Design (TDD). Dass Entwickler ein Versionsverwaltungswerkzeug einsetzen sollen, ist ebenfalls ein alter Hut. Effektiv nutzen sie das vielfach jedoch immer noch nicht. Dabei könnten moderne verteilte Versionsverwaltungen den Entwicklungsprozess stabiler gestalten. Aber darüber mögen Teams (oder ihre Manager?) nicht nachdenken, weil vor Jahren die Entscheidung für ein Versionsverwaltungssystem gefallen ist, mit dem man schon Mühe genug hat.
Doch einerlei: Das Sicherheitsnetz aus automatisierten Tests, Versionsverwaltung und schließlich automatisierter Produktion (Continuous Integration) mag noch löchrig sein, jedoch ist es im Projekt nun irgendwie vorhanden. Nicht jedes Loch lässt sich ja sofort flicken. Man mag sich Mühe geben, aber TDD einzuführen braucht eben seine Zeit.
Herausforderung Brownfield
Im Rahmen einer Artikelserie beleuchten die Initiatoren der "Clean Code Developer"-Initiative, Stefan Lieser und Ralf Westphal, die Herausforderungen an Clean Code Developer in Brownfield-Projekten.
- Teil 1: Was sind die Probleme?
- Teil 2: Das Sicherheitsnetz aufspannen
- Teil 3: Das Sicherheitsnetz erweitern
- Teil 4: Komplexität bewältigen durch Partitionierung
- Teil 5: Explizite Architektur als Ziel für Refaktorisierungen
- Teil 6: Partitionen durch Refaktorisierung evolvierbar machen
- Teil 7: Alle Veränderung in kleinen Schritten durchführen
Das Team hat auch keine Angst mehr, seinen Brownfield-Code tief umzugraben, um daraus wieder fruchtbaren Humus für eine längerfristige Weiterentwicklung an der Anwendung zu erzeugen. Doch wo soll es beginnen? Die übliche Antwort lautet: Refaktorisieren – dort im Code beginnen, wo es schlecht riecht (Code Smell), und sich Stück für Stück vortasten. Der Code soll in einem besseren Zustand als vorgefunden hinterlassen werden. Es lässt sich zweifelsfrei über dem Sicherheitsnetz arbeiten – auf der Mikroebene. Das Team braucht allerdings ein dem großen Ziel angemessenes "Big Picture".
In der Code-Presse entsteht das Brownfield
Spätestens nach der Installation eines Sicherheitsnetzes stellt sich die Frage, wie denn das Big Picture für das Projekt, die Anwendung, aussieht. Das mag überflüssig klingen. Es liegt ja ein Auftrag vor. Der Kunde hat den Wunsch geäußert: "Entwickeln Sie eine Warenwirtschaft" oder "Wir brauchen ein neues Buchungssystem" oder "Unsere Verträge sind so kompliziert, die müssen wir jetzt automatisiert prüfen". Darauf wurden die Anforderungen erhoben und geplant und getan und losgewerkelt ... aber nun steht man im Brownfield-Matsch. Irgendwie war das mit dem Big Picture vielleicht doch nicht ausreichend. Selbst eine vielleicht gemalte Schichtenarchitektur hat nicht so viel genützt.
Das Big Picture lastet wie eine Presse auf dem Code. Kräfte jenseits der Entwicklerkompetenz wie Zeit und Budget drücken den Code mit Macht zusammen. Andere Kräfte sind jedoch relevanter.

Zu nennen wäre das persistente Datenmodell. Ein Repräsentant dafür ist das oft gesetzte relationale Datenbank-Management-System (DBMS). Mehr oder weniger offen ausgesprochen versuchen viele Projekten, die persistenten Daten einer Anwendung in einem einzigen Datenmodell zu beschreiben und in einem Persistenzmedium zu halten. (Von Import-/Export-Daten sei abgesehen, sie sind nur temporär von Interesse.) Sie versuchen, alle Vorgänge von Warenwirtschaft, Buchungssystem oder Vertragsprüfung vorzugsweise auf dieses eine Datenmodell auszurichten. Wenn möglich soll es sich sogar anwendungsübergreifend nutzen lassen. Ist es so nicht am besten? Beugt man nicht so Inkonsistenzen am effizientesten vor? Sind nicht nur dann alle Daten immer für jeden verfügbar? Ist Homogenität nicht kostengünstig)? Ist Konsolidierung nicht nur bei Hardware gut, sondern auch innerhalb von Software? Gründe für das universelle, das eine Datenmodell gibt es viele.
Es übt allerdings nicht nur als Konzept eine ungeheure Kraft auf das Denken aus, sondern auch über sein Schema auf den Code. Wenn es nur ein Datenmodell gibt, dann auch nur eine API für das Persistenzmedium. Damit gibt es keine zwei Meinungen mehr über den Zugriff, der sich schnell mal einstreuen lässt. So entsteht enge Kopplung. Das eine Datenmodell suggeriert Konstanz und Verlässlichkeit, sodass sich Code ohne Risiko breit daran binden kann. Das ändert auch eine Datenzugriffsschicht kaum, also eine Kapselung der konkreten Persistenz-API oder gar des Schemas.
Das eine Datenmodell zwingt immer wieder zu Kompromissen. Es "verklebt" Code vertikal im Funktionsdurchstich von der GUI bis zur Datenzugriffsschicht und horizontal über Durchstiche hinweg. Denormalisierungen in relationalen Datenmodellen sind dafür ein Beleg. Denn wo man denormalisieren muss, um einer Funktion zu dienen, soll sich ein zweiter Zweck jenseits einer anderen Funktion erfüllen lassen. Ein Anwendungsteil braucht ein flexibles und einfach zu pflegendes Datenmodell, ein anderer ein performantes. Die Presskraft des einen Datenmodells ist stark. Sie drückt Code zusammen von der persistenten Klasse, die der O/R-Mapper befüllt, bis zum GUI-Steuerelement, das sich an persistente Objekte bindet.
Eine weitere Presskraft ist die Benutzerschnittstelle. Wer eine Anwendung realisieren möchte, sieht sie meist durch eine Benutzeroberfläche repräsentiert. Multiple Document Interfaces (MDI) sind das Ergebnis. Vom Sachbearbeiter bis zum Chef schauen alle durch dieselben Fenster in die Daten. Das eine GUI presst nun allerdings Code mit Leichtigkeit zusammen, wenn dem keine rigorose Architektur Widerstand leistet. Wenn dazu noch Erfolgsdruck hinzukommt – "Wir müssen dem Kunden schnell was zeigen!" –, wandert Code wie von Geisterhand gern in die GUI. Für Planung ist kaum Zeit, doch ein Ort, an dem Code auf jeden Fall stehen kann und muss, ist sicher: die GUI. Denn Code wird schließlich immer ausgeführt als Reaktion auf ein Ereignis, und zwar ausgelöst vom Anwender. Warum nicht den Code möglichst dicht an das Ereignis heranführen? Es entstehen Dialoge mit mehreren Tausend Zeilen Code. Eine Brownfield-Anwendung unter Druck des einen Frontends und des einen Datenmodells – so sieht ein guter Teil der Anwendungsentwicklung aus großer Flughöhe aus.
Damit aber nicht genug. Es gibt noch eine weitere, oft übersehene Kraft, die auf dem Code lastet. Die geht von einem Nichts, einer Lücke aus. Sie entspringt der Leere zwischen dem großen Ganzen der Anforderungen – "Wir brauchen eine neue Warenwirtschaft" – und dem Schichtenmodell oder einem anderen typischen Lösungsansatz aus.
Von den Anforderungen zur Architektur ist immer ein Sprung zu vollziehen – das ist die kreative Leistung der Softwareentwicklung. In vielen Fällen ist dieser jedoch viel zu groß, um zu evolvierbarem Code zu kommen. Das Team springt – und fällt in die Lücke zwischen Anforderungen und Architektur, weil das Bewältigen der Distanz über seine Kräfte geht. Es gibt nur eine Mittel: Für das eine große Ganze der Anforderungen gibt es nur den einen Entwurf. Eine Anwendung ist gefordert, also gibt es eine Architektur und eine Codebasis und ein Datenmodell. Das ist eine Gleichung, die in vielen Teams tief verankert ist.
Sind die Anforderungen genügend kompliziert – und das ist öfter und schneller der Fall, als man denkt –, klafft eine Lücke zwischen ihnen und dem Entwurf. Der Entwurf deckt sie nicht wirklich ab. Deshalb ist er lückenhaft und unspezifisch. Deshalb füllen Projektteams weiße Flächen ad hoc aus. Brownfield-Code entsteht, weil ihm der Planungsrahmen fehlt. Die Last der Leere zwischen Anforderungen und Planung drückt ihn unerbittlich zusammen. Was lässt sich dagegen tun? Projektteams müssen die bisherige Leere zwischen Anforderungen und Planung mit Differenzierungen füllen.
Spezialisierte Frontends
Spezialisierte Frontends differenzieren die User Experience
Wie viele Frontends braucht eine Anwendung? Das kommt darauf an. Wenn die Anwendung auf unterschiedlichen Geräten laufen soll, ist für jedes Gerät ein Frontend zu entwickeln, etwa eines fürs Web, eines für den PDA, eines für den Desktop. Hat jemand entschieden, dass geräteübergreifend nur ein Browser-Frontend zu benutzen ist? "One size fits all", ist ja oft die Devise bei Devices. Auf die Frage, wie viele Frontends eine Anwendung pro Gerät braucht, wenn schon nicht "One size fits all", lautet die Antwort meist eins. Ein Frontend, ein Programm pro Gerät, alles möglichst einheitlich, ist dann die Maxime in vielen Projekten. Und damit läuft die Code-Presse.

Wie anders könnte es sein, wenn die Gleichung etwa lauten würde: "Ein Frontend pro Anwenderrolle" ist eine zu erwägende Alternative. Die könnte für eine simple Fakturaanwendung bedeuten, dass es ein Frontend für die Rechnungslegung inklusive Gutschriften gibt, eines für das Mahnwesen, ein anderes für den Zahlungseingang, noch eines für die Umsatzsteuervoranmeldung, eines für den Datenexport und schließlich noch eines für zumindest einfache Auswertungen. Sechs Frontends statt einem, womit nicht sechs GUI-Fenster gemeint sind, sondern sechs Programme, Icons auf dem Desktop, EXE-Dateien unter Windows und Visual-Studio-Projektmappen.
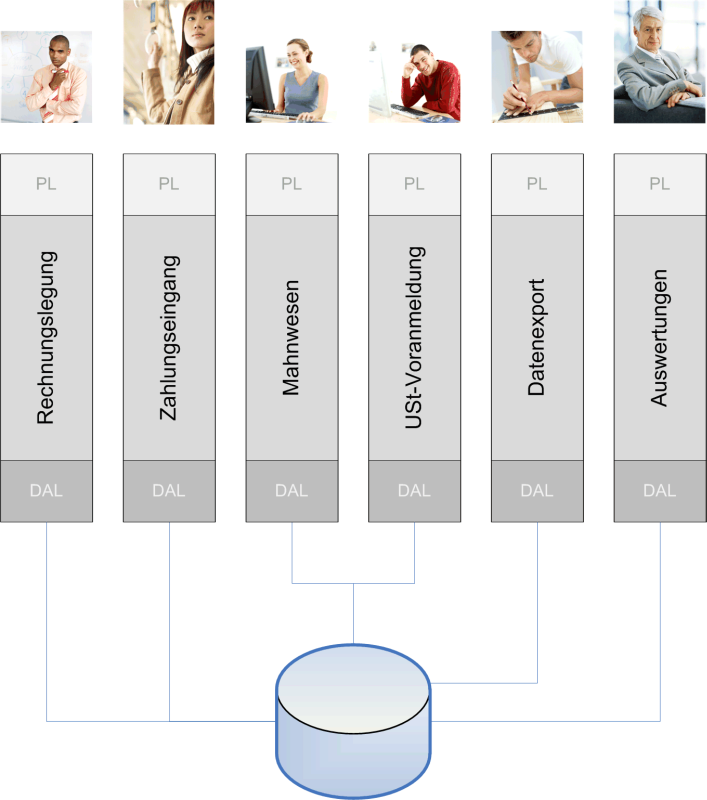
Durch rollenspezifische Frontends partitioniert man den Umgang mit einem Datenmodell. Jede Partition ist ein schmaler Durchstich von der Benutzerschnittstelle durch die Domänenlogik bis zum Datenzugriff.
Denkt man in Partitionen, bekommt man auch "Verhandlungsmasse" für das agile Vorgehen. Als Durchstiche sind Partitionen anwenderrelevant, das heißt, selbst wenn man die Entwicklungsaktionen auf nur eine Partition beschränkt, bekommt der Kunde einen Wert. Er kann sogar priorisieren und sagen: "Ich hätte gern, dass Sie zuerst Rechnungslegung und Zahlungseingang realisieren."
Solch partitionsbezogene Priorisierung fokussiert die Anstrengungen. Für einen Moment (zum Beispiel einen Sprint) schrumpft die Anwendung auf die Partition und wird viel überschaubarer. Es gibt keinen Zwang, partitionsübergreifend Code wiederzuverwenden (auch wenn sich das beispielsweise für den Datenzugriff anbietet). Wenn man plant, sollte man ein BDUF (Big Design Up Front) vermeiden. Darüber hinaus sind Partitionen geeignet, Anwender zufrieden zu stellen. Denn wenn man nicht mehr alle Rollen durch das eine Frontend zwängt, lässt sich jeder Rolle eine hochspezialisierte, optimale Benutzerschnittstelle zuweisen. Anwender mögen das, weil solche Benutzerschnittstellen sie effizienter machen und weil sie daran ablesen, dass der Entwickler sich wirklich bemüht, ihre Domäne zu verstehen. Das ist Wertschätzung, die später über so manchen Bug-Frust hinweg hilft.
Partitionen sind von sich aus nicht weiter gefeit gegen Kräfte, die ihren Code zu einem Brownfield zusammenpressen. Dagegen muss Architektur Widerstand leisten – davon aber im nächsten Artikel mehr. Hinsichtlich der Gesamtanwendung ist die Partitionierung hingegen ein Brownfield-Gegengewicht. Code, der auf Partitionen verteilt ist, kann nicht "verklumpen".
Mit der Partitionierung der Anwendungen kann man jederzeit beginnen. Sie bezieht sich nur auf den Code. Am Ende ist der Effekt, so gut er sein mag, begrenzt. Auf Partitionen lastet ja immer noch der Druck des einen Datenmodells, das sich alle teilen. Man sollte daher über Partitionen hinaus denken und die Anforderungen noch grundsätzlicher hinterfragen.
Spezialisierte Datenmodelle
Spezialisierte Datenmodelle differenzieren die Domänenlogik
Erhält man den Auftrag für eine Anwendung mit einem Satz an Anforderungen, ist es nachvollziehbar, dass man dafür eine Lösung im Sinne eines Programms entwickeln will. Das eine Programm repräsentiert meist ein Datenmodell.
Es ist zum Beispiel bei einer Faktura-Anwendung naheliegend, dass das Datenmodell die Anforderungen von Rechnungslegung und Mahnwesen, Zahlungseingangsbuchung und Auswertung erfüllen muss. Schließlich hat sich der Kunde die Funktionen gewünscht. Daran ändert auch nichts, dass man Rollen identifiziert hat und die Anwendung partitioniert. Das eine Datenmodell, oft repräsentiert durch die reflexartige Entscheidung für ein relationales Datenbanksystem, wird es schon richten. Nur so ist Datenkonsistenz, Verfügbarkeit und Sicherheit gewährleistet – oder?
Es geht auch anders. Man nehme den einen Wunsch des Kunden nicht als Auftrag, eine Anwendung (gegliedert in mehrere Partitionen) zu liefern, und schaue genauer hin. Der Kunde selbst weiß es nicht besser, aber die Entwickler. Sie sollten die Anforderungen betrachten und sich fragen, ob damit wirklich eine Anwendung beschrieben ist oder ob es mehrere sind. Sie sollten besser davon sprechen, dass der Kunde ein Softwaresystem will, nicht eine Anwendung. In "System" steckt ja drin, dass es mehrere Funktionseinheiten geben kann, die im Sinne des Gesamtzwecks zusammenwirken.
Auch sollten Entwickler sensibel für die Sprache der Anforderungsdokumente sein. An ihnen haben viele Stakeholder mitgearbeitet, die alle nur das Beste für ihren Bereich wollen. Das führt – wie es bei Menschen und ihren Wünschen üblich ist – zu Widersprüchen; die einen wollen etwa Effizienz, die anderen Flexibilität. Das mündet aber auch in Missverständnissen. Die entstehen oft durch Homonyme, das heißt gleich klingende Worte, die Unterschiedliches bedeuten. Bei einer Faktura-Anwendung könnte das etwa der Begriff "Rechnung" sein.
Für die Rechnungslegung ist eine Rechnung ein Dokument, vergleichbar mit einem Word-Dokument, nur etwas strukturierter. Ein intelligentes Formular, das beim Ausfüllen hilft mit Zugriff auf Stammdaten von Kunden und Produkten. Für die Zahlungseingangsbuchung hingegen ist eine Rechnung nur ein Tupel bestehend aus Rechnungsnummer, -datum, -betrag, Zahlungsbedingung und vielleicht einer Kurzinformation über den Kunden. Für die Auswertung schließlich ist eine Rechnung vielleicht ein Tupel bestehend aus Umsatzdatum, Umsatz, Kosten, Umsatzregion.
Die Stakeholder dreier Rollen haben sich im Anforderungsdokument "verewigt" und dabei denselben Begriff benutzt: Rechnung. Ohne sich dessen bewusst zu sein, haben sie jedoch mehr oder weniger unterschiedliche Vorstellungen davon, was eine Rechnung ist. Deshalb sollten sich alle Begriffe in Anforderungsdokumenten mit ihren Rollen qualifizieren lassen (zum Beispiel Rechnungslegung.Rechnung, Zahlungseingang.Rechnung, Auswertung.Rechnung), solange nicht ausdrücklich klar ist, dass sie rollenübergreifend dasselbe bedeuten.
Derzeit ist das aber noch nicht der Fall und deshalb ist die Gefahr groß, dass Homonyme in Anforderungsdokumenten nicht erkannt werden. Das führt dazu, dass zwischen ihnen nicht zu unterscheiden ist und Entwickler versuchen, es allen Rollen mit dem einem Datenmodell rechtzumachen. Das führt nicht nur zu aufgeblähten Datenmodellen, sondern auch zu ineffizienten. Wieder sei das Beispiel Faktura-Anwendung herangezogen: Versucht man die Anforderungen an Rechnungslegung.Rechnung und Auswertung.Rechnung in einem (relationalen) Datenmodell zu erfüllen, kommt man wahrscheinlich auf eine von zwei Lösungen:
- Entweder berechnet man für die Auswertung Umsatz und Kosten aus den Rechnungspositionen, weil sich nur so der Forderung nach einer normalisierten Datenbank nachkommen lässt. Allemal zwängt man dafür Dokumente (Rechnungslegung.Rechnung) in ein relationales Schema. Das allein sollte schon Schmerzen bereiten.
- Oder man speichert Umsatz, Kosten und Zahlungseingänge denormalisiert – beispielsweise im Rechnungskopf. Dann widerspricht der jedoch dem Single Responsibility Principle – und das sollte auch Schmerzen verursachen.
Wie man es dreht und wendet, man wird immer wieder zu Kompromissen gezwungen, die Datenbanken und Datenobjektmodelle in die Unwartbarkeit treiben, wenn man Anforderungen als großes Ganzes sieht, dessen Lösung nur ein Datenmodell haben soll.
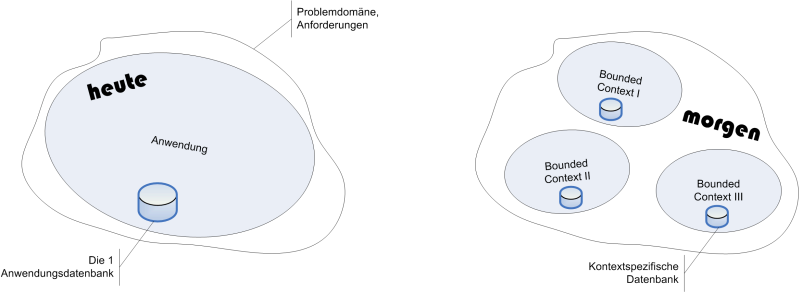
Stattdessen sollte der Entwickler die Grenzen zwischen den "Sprachgemeinschaften" der Stakeholder oder besser den "Begriffsgültigkeitsbereichen", kurz Kontexten, erkennen. Manche Begriffe sind wirklich universell, aber viele haben nur eine begrenzte Reichweite. Innerhalb der Anforderungen gibt es daher meist mehrere Kontexte, die so unterschiedlich sind, dass sie eine eigene Anwendung verdienen. Domain Driven Design (DDD) nennt die Kontexte Bounded Contexts (BC) und weist ihnen eigene Datenmodelle zu.
In der Faktura-Anwendung könnten etwa Rechnungslegung, Auswertung und Verwaltung (Mahnwesen, Zahlungseingang, USt-Voranmeldung, Datenexport) drei Bounded Contexts darstellen. Ihre jeweilige Sicht auf die Daten ist so anders, dass es sich lohnt, sie durch unabhängige Datenmodelle zu beschreiben und auch unterschiedliche Persistenzmedien zu benutzen. Für die Rechnungslegung könnte eine Dokumentendatenbank wie CouchDB optimal sein, die Auswertung könnte von einer OLAP-Datenbank profitieren, und die restlichen Partitionen setzen vielleicht auf ein RDBMS.

Partitionen dienen besserer Usability. Jede Rolle bekommt ein auf sie genau zugeschnittenes Frontend. Das wiederum dient der Modularisierung des Anwendungscodes. Bounded Contexts hingegen dienen nichtfunktionalen Anforderungen wie Performance oder Skalierbarkeit. Indem sie das Datenmodell modularisieren, schaffen sie es, innerhalb jedes Kontexts Struktur und Technik optimal für die darin enthaltenen Partitionen zu wählen. Das wiederum dient der Entkopplung von Daten und Code.
Die Vorteile der vielen Datenmodelle mit ihren optimalen Persistenztechniken haben allerdings ihren Preis. Der besteht nicht so sehr darin, sich potenziell in viele Techniken einarbeiten zu müssen. Er ist vielmehr in Form von explizitem Synchronisationsaufwand zu zahlen. Denn kontextspezifische Datenbanken enthalten oft Daten redundant. Noch einmal als Beispiel die Faktura-Anwendung: Im Verwaltungs- wie im Auswertungskontext geht es etwa um Rechnungsdatum und Umsatz. Ändern sich die Daten in einem Kontext, die für andere relevant sind, sind die betroffenen Kontexte zu synchronisieren.
Teilt man den Code in mehrere Bounded Contexts auf, muss der Entwickler zusätzlich Synchronisationscode schreiben. Beim einem traditionellen Datenmodell ist das, wenn er die Daten vollständig normalisiert hält, nicht nötig. Aber oft sind auch universelle Datenmodelle unsauber, das heißt denormalisiert, sodass dafür konsistenzsichernder Code zu schreiben ist, etwa in Form von Triggern.

Ist die Synchronisierung ein K.O.-Kriterium für Bounded Contexts? Nein. Erstens ist der Aufwand, der in die Synchronisation geht, wahrscheinlich geringer als der, der in die Wartung des einen undurchsichtigen universellen Datenmodells und des darauf basierenden Codes geht. Zweitens zeigt eine explizite Synchronisierung, was vorher unsichtbar war. Sie repräsentiert damit eine Erkenntnis, ist sozusagen aktives Wissens-Management, und sie ist Repräsentant der Grenze zwischen den "Kulturen des Umgangs mit Daten".
An der expliziten Synchronisierung hängt allerdings noch ein weiterer Preis, ihre Latenz. Daten sind nicht sofort, wenn sie persistiert wurden, softwaresystemweit verfügbar. Synchronisierung braucht ihre Zeit; das können Sekunden, Minuten oder Stunden sein. Arbeitet eine Projektteam mit Bounded Contexts, ist es gezwungen, sich auf Eventual Consistency einzulassen. Das ist aber nicht schlimm. Wenn es im Faktura Beispiel etwa fünf Minuten dauern sollte, bis eine neue Rechnung in der Verwaltung und der Auswertung ankommt, ist die Verzögerung aus Sicht der abhängigen Bounded Contexts nicht zu unterscheiden von einer Speicherung, die fünf Minuten später stattfindet.
Synchronisierung und Eventual Consistency sind also vergleichsweise kleine, dafür jedoch explizite Kosten im Vergleich zu den versteckten, kaum bezifferbaren Kosten, die undurchsichtige monolithische Datenmodelle verursachen.
Fazit
Fazit
Über dem Sicherheitsnetz aus automatisierten Tests, Versionskontrolle und automatisierter Produktion geht es darum, den Code zu machen und zu halten. Das bedeutet, dass Funktionseinheiten saubere Verantwortlichkeiten haben. Die Prinzipien Single Responsibility und Separation of Concerns beziehen sich jedoch nicht nur auf Klassen oder Methoden, das heißt kleine Funktionseinheiten, sondern auf Einheiten aller Granularitätsebenen.

.
Bounded Contexts und Partitionen sind zwei grobe konzeptionelle Funktionseinheiten, die helfen, das große Ganze der Anforderungen an eine Anwendung sauber zu zerlegen. Sie wirken damit den Brownfield erzeugenden Kräften des einen Frontends und des einen Datenmodells entgegen.
Es mag ungewohnt sein, nicht gleich für den gesamten Anforderungshorizont eine Karte in Form von Komponenten oder Klassen zu erstellen. Doch es lohnt sich, das eine große Ganze zu zerlegen in "kulturell" unterschiedliche Gebiete und in denen unterschiedliche Herangehensweisen zu unterscheiden. Die eigene kognitive Last nimmt dadurch ab. Komplexität wird handhabbarer. Nur mit einer solchen hierarchischen Sicht haben Projekte eine Chance, über dem Sicherheitsnetz realistische Kunststücke zu vollführen, die das Stakeholder-Publikum langfristig erfreuen.
Stefan Lieser
ist freiberuflicher Berater/Trainer/Autor aus Leidenschaft. Seine Schwerpunkte liegen im Bereich Clean Code Developer sowie Domain Driven Design.
Ralf Westphal
ist Microsoft MVP für Softwarearchitektur und freiberuflicher Berater, Projektbegleiter und Trainer für Themen rund um .NET-Softwarearchitekturen
(ane)
