Höchster Reifegrad für REST mit HATEOAS

Das Erstellen einer sauberen REST-Schnittstelle ist nicht trivial. HATEOAS ermöglicht eine klare Struktur und Aufgabenteilung.
HATEOAS ist ein in den letzten Jahren viel diskutiertes Thema: Einige bezeichnen es für REST-Schnittstellen als unverzichtbar [1]. Andere Autoren hängen es etwas tiefer auf und bezeichnen eine HATEOAS-konforme Schnittstelle lediglich als dritten und höchsten Reifegrad von REST [2]. Leider gibt es noch keinen einheitlichen Standard, wie HATEOAS zu implementieren ist. Ziel dieses Artikels ist es, einen Überblick über aktuelle Entwicklungen zu geben und Argumente zu liefern, warum REST-Schnittstellen auf keinen Fall darauf verzichten sollten.
Eine kleine REST-Geschichte
Die folgende Geschichte einer REST-Schnittstelle soll sich in einem Unternehmen genau so abgespielt haben. Das Ziel war die Entwicklung einer Webseite, um Wetterdaten diverser Messstationen zu präsentieren und einzulesen.

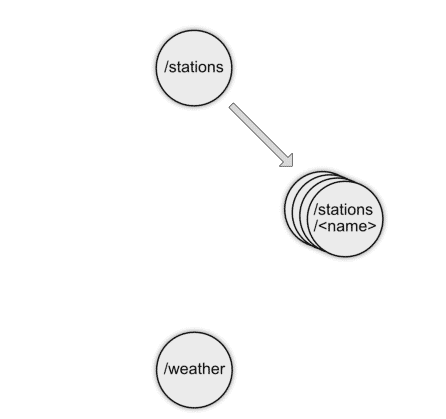
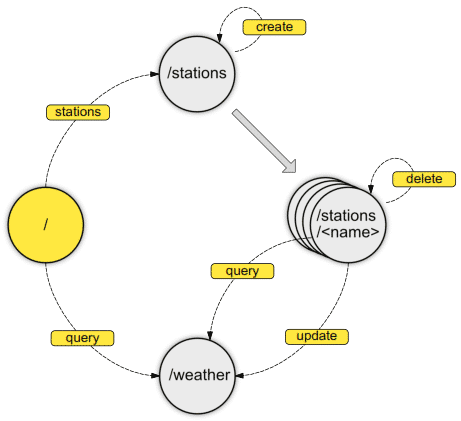
Das Team beschließt, eine REST-Schnittstelle zu entwickeln, und hat die Hoffnung, sie später auch von Apps und IoT-Devices ansprechen zu können. Als vermeintlich schnellsten Ansatz programmiert es drei REST-Ressourcen, deren URL fest in den Clients verlinkt ist. Die Frage des Rechtemanagements am Client verschieben die Beteiligten auf später. Damit entsteht eine Schnittstelle, die dem Schema in Abbildung 2 entspricht.
Im nächsten Schritt wollen die Entwickler das Anlegen und Bearbeiten von Stationen durch eine Administratorrolle absichern. Um diese Information zugänglich zu machen, erstellen sie kurzerhand eine Ressource für Berechtigungen, die Abbildung 3 darstellt.
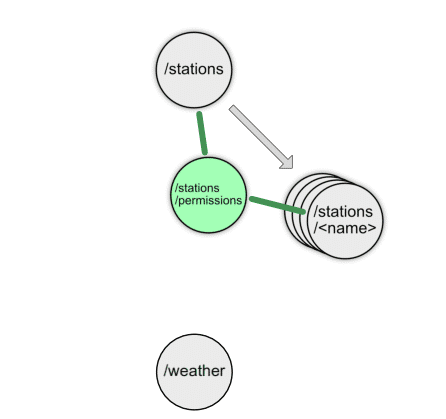
Der Ansatz ist problematisch, da er die Bedeutung der Administrator-Rolle an zwei Stellen verankert: Am Server, wenn dort ein Request eintrifft, und am Client, der evaluieren muss, ob der derzeitige Nutzer den entsprechenden Button sehen darf. Außerdem beeinflusst der Ansatz das Laufzeitverhalten des Clients maßgeblich, der erst nach dem Laden der Berechtigungen sinnvoll eine Anzeige aufbauen kann.
Will das Team anschließend die – grundsätzlich simple – Funktion einfügen, dass jeder Nutzer seine eigenen privaten Stationen anlegen und bearbeiten darf, steht es vor weitreichenden Schwierigkeiten. Für den Fall reicht es nicht mehr aus, eine zentrale Berechtigung zu vergeben, sondern die Rechte müssen an den Objekten selbst stehen. Deswegen hängt es an jede fachliche Stationsressource die Berechtigungen des jeweiligen Nutzers.
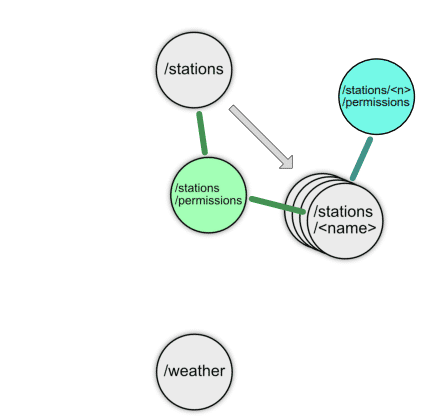
Ganz verfahren wird die Situation, wenn eine Anwendung die Berechtigungsinformationen bereits beim Laden der Liste aller Stationen benötigt, wie Abbildung 5 exemplarisch zeigt. Dann bleibt dem Entwicklerteam nichts anderes übrig, als die Berechtigungen mit in die fachlichen Transferobjekte hinein zu modellieren.
Aus den Designfehlern lernen
In der recht kurzen Lebenszeit der Schnittstelle haben die Entwickler somit drei große API-Breaks erzeugt. Das ist insofern problematisch, als sie gezwungen sind, die alte Version der Schnittstelle weiterhin zu unterstützen. Bei einer kontrollierten Gruppe von Clients ist der Zeitraum überschaubar, im App- und IoT-Umfeld können sie jedoch über Jahre im Einsatz sein. Das Team muss über den Lebenszyklus zusätzlich zu den fachlichen Änderungen an den eigentlichen Wetterstationen noch drei Berechtigungskonzepte pflegen. Damit ist bald der Punkt erreicht, an dem es die Entwicklung an der Schnittstelle einstellt und lieber von vorne anfängt.
Ein Blick auf die beiden Designfehler offenbart zunächst die Vermischung von Berechtigungen mit fachlichen Objekten. Weitaus schlimmer ist jedoch das Duplizieren von Client- und Servercode. Nach den Konzepten des Domain-Driven-Design [1] haben die Entwickler Teile der Server- in die Clientdomäne "sickern" lassen. Das verwässert die Grenze der beiden und führt letztlich dazu, dass eine Superdomäne entsteht, in der Server und alle Clients enthalten sind. Die einschlägige Literatur spricht von einem "verteilten Monolith" [3] oder teilweise wenig schmeichelhaft vom "big ball of mud" [4].
Der verstärkte Einsatz von Shared Libraries verschlechtert häufig die Situation. Sie können den gegenteiligen Effekt vom Erwünschten bringen, da das Team bei der Serverentwicklung jegliche Anforderungen der Clients berücksichtigen muss. Das widerspricht dem Anspruch, dass REST-Schnittstellen eigentlich für eine bessere Entkopplung sorgen sollen. Somit entstehen die Nachteile der verteilten Architektur, ohne einen Vorteil zu bringen.
Leider kommen die meisten REST-Schnittstellen nie über diesen Status hinaus, obwohl ein Ausweg aus dem Dilemma seit längerer Zeit bekannt ist.
Einsatz von HATEOAS
HATEOAS steht für "Hypermedia As The Engine Of Application State" und beschreibt ein Designmodell für REST-Schnittstellen. Ein Client bekommt den aktuellen Zustand der Applikation von den Ressourcen einer REST-Schnittstelle mitgeteilt. Darüber hinaus übermittelt der Server alle möglichen Zustandsübergänge in Form von Hypermedia-Links. Die Domäne des Servers schließt sich somit, da der Client kein Wissen über die Berechnung der Statusübergänge benötigt. Der Client muss "nur noch" die Linknamen, die sogenannten Relationen und eine dedizierte Einsprung-URL kennen, von der er starten kann.
Die Konstellation bringt übrigens die Versuchung mit sich, die Links zum Dokumentieren zu (miss-)brauchen. Jedoch ist es eine Illusion, dass Entwickler lediglich vor der Schnittstelle sitzen müssen, um ihre Funktionsweise zu erkennen. Das kann HATEOAS nicht leisten. Durch den grundsätzlich dynamischen Ansatz sind selten alle möglichen Links auf Anhieb sichtbar. Eine geeignete Dokumentation ist somit weiterhin erforderlich.
Relationen im Zentrum
Die zentrale Rolle bei HATEOAS nehmen die Relationen ein. Entwickler müssen einen geeigneten Weg finden, die Semantik zum Client zu transportieren. Ansatzweise beschreibt RFC5988 [5] das Vorgehen. Für Standardrelationen existiert eine Registry bei der IANA (http://www.iana.org/assignments/link-relations/link-relations.xhtml). Die RFC bleibt jedoch (bewusst?) vage hinsichtlich des Einfügens eigener Relationen. Roy Fielding schlägt dazu zwei Vorgehensweisen vor. Die erste ist die Verwendung eines eigenen Medientyps [6].
Dabei müssen Entwickler jedoch aufpassen, dass sie nicht für jedes Businessobjekt und für jede Version einen eigenen Typ einführen. Ansonsten entsteht erneut eine Art Shared Library und damit eine enge Kopplung. Außerdem explodiert damit die Anzahl der zu verwaltenden Medientypen. Dass das erfahrungsgemäß in einem (eher ungeeigneten, weil nicht maschinenlesbaren) Wiki-System erfolgt, verschlimmert die Situation nur weiter.
Das andere Extrem wäre, einen sehr generischen Medientyp ohne jegliche eigene Relationen zu wählen. Das birgt die Gefahr, dass am Ende ein Äquivalent zu HTML entsteht. Die Wartung und Entwicklung eines solchen Typs und des zugehörigen Clients ist äußerst aufwendig. Es gilt also, einen gesunden Mittelweg zu finden.
Kommunikation mit HAL
HAL als eigene Sprache
Das HAL-Format (Hypertext Application Language [7]) liegt zurzeit bei der IETF als Internet Draft [8] vor. Es wird von Spring HATEOAS [9] verwendet und setzt voraus, dass eigene Relationen einen geeigneten Weg zum Client finden. Das lässt sich beispielsweise durch die Verwendung von Spring REST Docs [10] erreichen. Der Medientyp für eine Response wäre hal+json beziehungsweise hal+xml. Das folgende Listing zeigt eine Beispiel-Response in hal+json:
{
"_links": {
"self": {
"href": "/station/1" },
"delete": {
"href": "/station/1" }
},
"id":"1"
}
Zusätzlich existiert die Möglichkeit, Ressourcen einzubetten, um beispielsweise jedem Member weitere Links hinzuzufügen. Allerdings kann der Client nicht auf Änderungen an den Payloads reagieren. Er geht immer davon aus, dass sein Verständnis davon das gleiche wie am Server ist. Auch verzichtet der Ansatz auf das Übertragen von HTTP-Verben, obwohl sie am Server bekannt sein müssen. Das führt wie im vorherigen Listing dazu, dass mehrere Relationen zur gleichen URL führen können, obwohl sie semantisch etwas vollkommen anderes bedeuten. Das provoziert am Client Zugriffe, die recht umständlich sind, wie folgendes Listing in Pseudocode zeigt:
// for delete
response.followRel("delete").withDelete();
//for getting self
resonse.followRel("self").withGet();
In Spring HATEOAS (Client) gilt die implizite Voraussetzung, dass alle Links GET-Anfragen sind (Stand Version 0.20.0).
Frei von Typen
Fieldings zweiter Vorschlag ist, auf neue Medientypen zu verzichten und stattdessen bestehende durch neue Links zu erweitern:
Link: </stations/1>;
rel="delete self";
type = "application/custom.v1"
Entwickler können das erreichen, indem sie, wie in RFC5988 beschrieben, die Links in den Response-Header schreiben. Das Jersey-Framework [11]Jersey-Framework [12] verwendet diesen Ansatz.
Der Medientyp bleibt von der Verlinkung unbeeinflusst. Dabei entstehen ähnliche Probleme wie beim HAL-Format, da keine HTTP-Methoden mitgeliefert werden. Durch das im Link vorhandene type-Attribut kann der Client Informationen über den Medientyp der Ressource erhalten und bei entsprechender Versionierung der Typen im Vorfeld mitbekommen, ob seine Vorstellung noch mit der des Servers übereinstimmt. Dieses Vorgehen birgt aber die oben beschriebenen Gefahren. Erschwerend kommt hinzu, dass sich Header-Links nicht im Payload einbetten lassen.
JSON Hyperschema
Die oben beschriebenen Nachteile werden durch JSON Hyperschema [13] behoben. Diese Spezifikation liegt zurzeit bei der IETF als Draft Version 4 vor. Die zentrale Rolle spielt dabei das Link Description Object (LDO [14]). Ein einfaches Beispiel sieht folgendermaßen aus:
1 {
2 "rel": "add-comment",
3 "method": "POST",
4 "href": "http://example.org/api/stations/1/",
5 "targetSchema": {},
6 "schema": {
7 "type": "object",
8 "properties": {
9 "message": {
10 "type": "string"
11 }
12 },
13 "required": [ " message " ]
14 }
15 }
Das Listing zeigt ein LDO mit einer HTTP-Methode (3), einem Schema (6) beziehungsweise Target-Schema (5). Dabei ist im Feld schema ein JSON-Schema für den Payload angegeben, den die Ressource erwartet – beziehungsweise bei einem GET-Request die möglichen Request-Parameter. Im Feld targetSchema steht ein Schema für den zu erwartenden Payload.
Wenn die Schnittstelle dem CQRS-Prinzip (Command Query Responsibility Segregation [15]) folgt, sollte möglichst immer nur eines der beiden Schemata belegt sein. Ein GET-Request bildet wiederum eine Ausnahme, da er durchaus mit Query-Parametern versehen sein kann. Da REST-Schnittstellen in den meisten Fällen eher leseoptimiert sein sollten, ist das Aufbauen von separaten Lese- und Schreibmodellen meist eine sehr gute Idee.
Die Angabe der HTTP-Methode reduziert menschliche Fehler beim Zugriff auf die Schnittstelle, da er genau definiert ist. Außerdem kann man durch die Angabe der beiden Schemata die Vorstellung der Clients im Vorfeld mit der des Servers abgleichen und gutartige Veränderungen in den Schemata kompensieren. Dadurch lassen sich unter anderem Felder ausblenden, die nicht mehr in den Schemata auftauchen. Ein konformes JSON Hyperschema enthält auf der höchsten Ebene in der Eigenschaft "schema", ein Array, das eine beliebige Zahl von LDOs als erlaubte Links enthalten kann.
Frameworks, Beispielcode und Fazit
Passende Frameworks
Nachdem das passende Format für den Austausch der Links gefunden ist, beginnt die Suche nach geeigneten Frameworks, die das Format unterstützen. Derzeit existieren nur wenige Implementierungen. Spätestens, wenn Entwickler dynamisch Schemata und Links anpassen wollen, müssen sie selbst Hand anlegen. In Jersey gibt es eine gewisse Dynamik, die aber leider nur eingeschränkt brauchbar ist, da sie über Annotationen funktioniert, die in der Expression Language zu verfassen sind. Dadurch entsteht schwer wartbarer Code.
Die derzeitigen Standard-Frameworks in Java sind Jersey (als JAX-RS-Referenzimplementierung) und Spring MVC mit Spring HATEOAS. Jersey lässt sich mittlerweile durch ein Plug-in [16] dazu bringen, ein JSON-Hyperschema in die Responses zu schreiben. Die Erweiterung trägt der Dynamik der erzeugten Links Rechnung, da Entwickler bei Linkerzeugung nur Optionals in der Hand hat. Jersey wertet standardmäßig bereits die JAX-RS-Annotationen zur Berechtigung aus. Entwickler können dem Framework weitere Annotationen bekanntmachen.
HATEOAS in Aktion
Zur Umsetzung des eingangs beschriebenen Anwendungsfalls mit HATEOAS müssen Entwickler zunächst eine Einsprungsressource erstellen und die jeweils richtigen Links ausliefern. Eine Implementierung dafür findet sich auf GitHub [17].
Der Client überprüft von Anfang an dauerhaft, ob die Links vorhanden sind, sodass er generisch sein darf. Ein Beispiel für einen Java-Client findet sich auf GitHub [18].
Änderungen an der Struktur der Berechtigungen erfordern kein erneutes Release des Clients. Auch andere Faktoren wie dynamisches An- und Abschalten von Features und Änderungen in der Businesslogik lassen sich komplett am Server umsetzen, ohne die Clients anpassen zu müssen. Das klingt zunächst nach einem deutlichen Mehraufwand für den Serverentwickler, der sich allerdings meist in Grenzen hält. Die Ergänzung sorgt sogar dafür, dass der Einsatz von HATEOAS die Schnittstelle deutlich aufwertet.
Das folgende Beispiel zeigt anhand der Methode getStation(), wie leicht die Integration von HATEOAS mit dem Framework durchzuführen ist. Ausgangspunkt ist die Methode vor der Änderung:
@GET
@Produces(MediaType.APPLICATION_JSON)
public WithId<Station> getStation(@PathParam(STATION_ID)
UUID stationId) {
log.debug("getStation('{})'", stationId);
return stationRepository.getStationById(stationId)
.getOrElseThrow(()
->new NotFoundException("Station with id "
+ stationId
+ " was not found"));
}
Zum Hinzufügen der Schemainformation existiert ein Wrapper-Typ namens ObjectWithSchema. Entwickler müssen die Antwort lediglich darin verpacken und mit den passenden Links anreichern:
@GET
@Produces(MediaType.APPLICATION_JSON)
public ObjectWithSchema<WithId<Station>> getStation(
@PathParam(STATION_ID) UUID stationId) {
log.debug("getStation('{})'", stationId);
return stationRepository.getStationById(stationId)
.map(station -> hyperSchemaCreator.create(
station,
stationLinkCreator.createFor(baseUri,
station.id),
weatherLinkCreator.createForStation(baseUri,
station.id)
)
).getOrElseThrow(() ->
new NotFoundException("Station with id " +
stationId +
" was not found"));
}
Das Erzeugen der Links ist in eine separate *Creator-Klasse ausgelagert und lässt sich darin umfangreich testen. Der Erzeuger für einen Link auf eine Messstation sieht folgendermaßen aus:
public List<Link> createFor(URI baseUri, UUID stationId) {
return collect(stationLinkFactory.forCall(
baseUri,
Rel.SELF,
r -> r.getStation(stationId)),
stationLinkFactory.forCall(
baseUri,
Rel.DELETE,
r -> r.deleteStation(stationId)));
}
Mithilfe einer integrierten LinkFactory für die passende Ressource erwartet die Funktion lediglich die Basis-URI des Services, die Relation und ein Lambda mit dem gewünschten Ressourcenaufruf. Die Angabe von Argumenten beim Aufruf der Methode legt den erlaubten Wert für den jeweiligen Parameter auf den übergebenen Wert fest. Diese Werte werden dann in Schema und URI des erzeugten Links übernommen.
Darüber hinaus gibt es die Option, die erlaubten Werte für einen Parameter flexibel zu setzen. Bei Verwendung einer Enumeration übernimmt das System die erlaubte Werte. Der normale Aufruf der Methoden an den Ressourcenklassen gewährleistet die Unterstützung von IDEs. Entwickler können bei Änderungen an den Ressourcen erkennen, an welchen Stellen sie benötigt werden. Damit offenbart sich der Vorteil der gegenüber dem Client abgeschlossenen Serverdomäne.
Die Annotation @RolesAllowed(Roles.ADMIN) erlaubt ausschließlich der Admin-Rolle den Zugriff auf die Methode deleteStation(<id>). Um eine redundante Konfiguration von Zugriffsregeln zu vermeiden, gilt die Rolleneinschränkung auch für die Link-Generierung. Im konkreten Fall bedeutet das, dass ohne weitere Anpassungen nur Nutzer mit Admin-Rechten den Link mit der Relation delete erhalten. Ein komplexes Berechtigungsszenario lässt sich ebenfalls umsetzen, das ohne Redundanz sowohl für die Zugriffskontrolle als auch für die Beschreibung der möglichen Zugriffe über das Hyperschema wirksam ist.
Da die Generierung der Schemainformationen dynamisch erfolgt, lassen sich auch weitere Annotationen umsetzen. Mit deren Hilfe können Entwickler beispielsweise einzelne Ressourcenmethoden oder spezielle Datenfelder für einen bestimmten Nutzerkreis ein- oder ausblenden.
Mithilfe des beschriebenen Ansatzes lassen sich einfache und performante Unit-Tests erstellen. Die Verwendung des Jersey-Testframeworks ist dafür nicht erforderlich.
Fazit
Die Vorteile für den Einsatz von HATEOAS sind somit auch beim konkreten Programmieren zu spüren und nicht nur abstrakt greifbar, was teilweise von Entwicklern am Server bemängelt wird. Vor allem die Abgeschlossenheit der Serverdomäne erlaubt eine Skalierung in mehreren Bereichen. Software lässt sich schneller fertigstellen und im Nachhinein ändern.
Nicht zu unterschätzen ist auch der verringerte Kommunikationsaufwand zwischen den Entwicklern von Client und Server. Die Teams tauschen sich nur noch über Statusübergänge aus, die uniform möglich sind. Fachliche Clientlibraries oder seitenlange Wikidokumentationen zu Statusübergängen können entfallen.
Schwierigkeiten liegen jedoch in der fehlenden Standardisierung und recht dünnen Frameworkunterstützung. Dieses Problem ist jedoch erkannt und wird zur Zeit aktiv behoben. Es steht also nichts mehr im Wege, heute schon von den genannten Vorteilen zu profitieren.
Jörg Adler
ist zur Zeit bei der Mercateo AG als Softwareentwickler tätig. Aktuelle Schwerpunkte sind REST-Schnittstellen und interne Systeme.
Andreas Würl
ist zur Zeit Senior Consultant bei der TNG Technology Consulting GmbH. Sein Schwerpunkte sind agile Softwareentwicklung und modernes Softwaredesign.
Literatur
- Eric Evans; Domain-Driven Design. Tackling Complexity in the Heart of Software; Addison-Wesley; 2003.
(rme [19])
URL dieses Artikels:
https://www.heise.de/-3550392
Links in diesem Artikel:
[1] http://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven
[2] http://martinfowler.com/articles/richardsonMaturityModel.html
[3] https://www.infoq.com/news/2016/02/services-distributed-monolith
[4] https://de.wikipedia.org/wiki/Big_Ball_of_Mud
[5] https://tools.ietf.org/html/rfc5988
[6] http://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven
[7] http://stateless.co/hal_specification.html
[8] https://tools.ietf.org/html/draft-kelly-json-hal-08
[9] http://projects.spring.io/spring-hateoas/
[10] https://projects.spring.io/spring-restdocs/
[11] https://jersey.java.net/documentation/latest/declarative-linking.html
[12] https://jersey.java.net/documentation/latest/declarative-linking.html
[13] http://json-schema.org/latest/json-schema-hypermedia.html
[14] http://json-schema.org/links
[15] http://martinfowler.com/bliki/CQRS.html
[16] https://github.com/Mercateo/rest-schemagen
[17] https://github.com/TNG/rest-demo-jersey
[18] https://github.com/Mercateo/rest-hateoas-client
[19] mailto:rme@ix.de
Copyright © 2016 Heise Medien