Java Virtual Machine und Container: ein Dream Team mit Startschwierigkeiten

(Bild: PHOTOCREO Michal Bednarek/Shutterstock)
Das problemlose Miteinander von Java Virtual Machine und Containern setzt eine gezielte Konfiguration voraus, damit Anwendungen effizient und fehlerfrei laufen.
Die Programmiersprache Java ist in der Softwareentwicklung fest etabliert – genauso wie Container-Technologien. In der täglichen Arbeit treffen Entwicklerinnen und Entwickler oft beides zusammen an. Als Container noch relativ neu waren, lief das Zusammenspiel allerdings nicht ganz reibungsfrei. Startete der JVM-Prozess (Java Virtual Machine) als Container, ignorierte er die in der Konfiguration eingestellten Grenzen für Ressourcen wie CPU und Speicher. Er betrachtete schlicht sämtliche Ressourcen des Hosts als Grundlage, um etwa die Größe des Heap zu bestimmen, die dann zwangsläufig größer war als die dem Container zur Verfügung stehende. Das führte zu den bekannten OOM Kills (Out-Of-Memory), da der Linux-Kernel rigoros Prozesse stoppt, die mehr Ressourcen verbrauchen, als ihnen zugewiesen sind.
Erst seit Java 9 (und später rückportiert auf Java 8 Update 191 [1]), erkennt die JVM die Container-Limits und berechnet die Heap-Größe korrekt.
Erfahrene Entwicklerinnen und Entwickler wissen, dass die Default-Einstellung für die Heapgröße (1/4 des verfügbaren Speichers) nicht für den Betrieb in Containern geeignet ist und verwenden daher Einstellungen wie -XX:MaxRAMPercentage. um die verfügbaren Ressourcen möglichst effektiv zu nutzen. Vor unerwartetem Verhalten ihrer Java-Anwendung in Containern sind sie dennoch nicht gefeit. Hohe Latenzen, Performance-Einbrüche oder auch Abstürze durch überlaufenden Speicher sind keine Seltenheit.
Viele dieser Probleme lassen sich besser verstehen, wenn man hinter die Kulissen schaut, wie Container eigentlich funktionieren und wie sich die JVM an bestimmte Gegebenheiten anpasst. Als erstes lohnt sich ein Blick darauf, wie der Linux-Kernel eigentlich Limits für Container verwaltet.
Container Limits verwalten mit cgroups
Der Linux-Kernel ist für die Interaktion mit der darunter liegenden Hardware zuständig und stellt den Zugriff darauf für Applikationen zur Verfügung, beispielsweise auf CPU und Speicher. Darüber hinaus kann er den Zugriff auf diese Ressourcen für einzelne Prozesse limitieren. Für die Steuerung und Limitierung der Ressourcennutzung verwendet der Kernel das cgroups-Feature (control groups), das seit 2008 zur Verfügung steht.
Die cgroups bilden eine hierarchische Struktur, in der sich Prozesse zusammenfassen lassen, damit sie sich bestimmte Ressourcen teilen können (siehe Abbildung 1). Zu den per cgroups steuerbaren Ressourcen zählen unter anderem:
- CPU
- Speicher
- Netzwerk
- Festplatten I/O

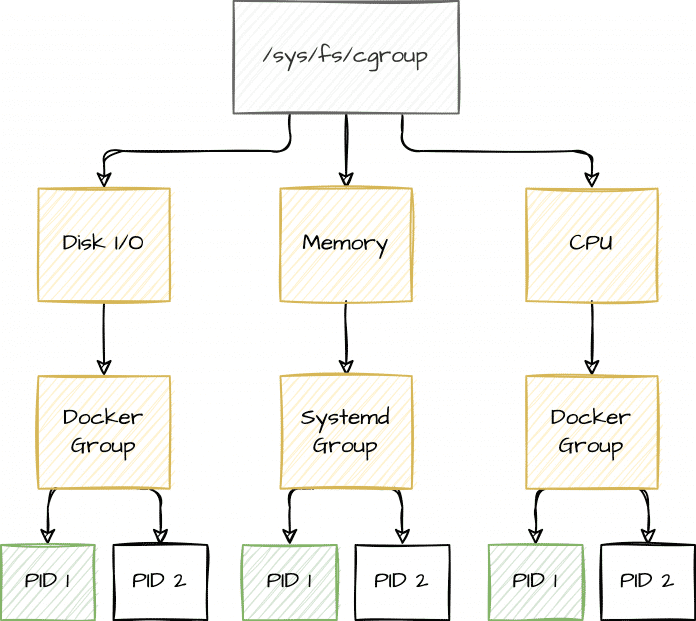
Die Gruppen und Strukturen sind wie in Linux üblich als Ordner und Dateien im Filesystem abgebildet. Startet man mit Docker einen Container und setzt Limits für CPU und Speicher, sind die passenden cgroups-Einstellungen im Filesystem ersichtlich.
Als Beispiel dient der folgende Aufruf:
docker run -d --memory 256m --cpus 2 traefik/whoami
cd693d893c47737ca5e10c9ac1f550fcceb51cdf5203c9b68b0f11483ed9957c
Die Ausgabe zeigt die ID des Containers und auch die zugehörige cgroup. All verfügbaren cgroups befinden sich unter /sys/fs/cgroup mit eigenen Unterordnern pro Ressourcen-Typ.
ls -l /sys/fs/cgroup/
total 0
dr-xr-xr-x 6 root root 0 Jun 1 11:02 blkio
lrwxrwxrwx 1 root root 11 Jun 1 11:02 cpu -> cpu,cpuacct
dr-xr-xr-x 6 root root 0 Jun 1 11:02 cpu,cpuacct
lrwxrwxrwx 1 root root 11 Jun 1 11:02 cpuacct -> cpu,cpuacct
dr-xr-xr-x 3 root root 0 Jun 1 11:02 cpuset
...
dr-xr-xr-x 6 root root 0 Jun 1 11:02 memory
lrwxrwxrwx 1 root root 16 Jun 1 11:02 net_cls -> net_cls,net_prio
dr-xr-xr-x 3 root root 0 Jun 1 11:02 net_cls,net_prio
lrwxrwxrwx 1 root root 16 Jun 1 11:02 net_prio -> net_cls,net_prio
...Für den angelegten Container findet man unter diesen Ordnern dann auch die konfigurierten Limits. Da im Beispiel etwa die CPU limitiert wurde, findet man einen passenden Ordner mit der ID unterhalb des cpu-Ordners:
ls -l /sys/fs/cgroup/cpu/docker/cd693d893c47737ca5e10c9ac1f550fcceb51cdf5203c9b68b0f11483ed9957c/
total 0
-rw-r--r-- 1 root root 0 Jun 1 11:14 cgroup.clone_children
-rw-r--r-- 1 root root 0 Jun 1 11:08 cgroup.procs
-rw-r--r-- 1 root root 0 Jun 1 11:08 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 Jun 1 11:08 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 Jun 1 11:14 cpu.shares
-r--r--r-- 1 root root 0 Jun 1 11:14 cpu.stat
-rw-r--r-- 1 root root 0 Jun 1 11:14 cpu.uclamp.max
-rw-r--r-- 1 root root 0 Jun 1 11:14 cpu.uclamp.min
-r--r--r-- 1 root root 0 Jun 1 11:14 cpuacct.stat
-rw-r--r-- 1 root root 0 Jun 1 11:14 cpuacct.usage
-r--r--r-- 1 root root 0 Jun 1 11:14 cpuacct.usage_all
-r--r--r-- 1 root root 0 Jun 1 11:14 cpuacct.usage_percpu
-r--r--r-- 1 root root 0 Jun 1 11:14 cpuacct.usage_percpu_sys
-r--r--r-- 1 root root 0 Jun 1 11:14 cpuacct.usage_percpu_user
-r--r--r-- 1 root root 0 Jun 1 11:14 cpuacct.usage_sys
-r--r--r-- 1 root root 0 Jun 1 11:14 cpuacct.usage_user
-rw-r--r-- 1 root root 0 Jun 1 11:14 notify_on_release
-rw-r--r-- 1 root root 0 Jun 1 11:14 tasksDocker legt alle cgroups für Container, die per docker gestartet werden, unter einem eigenen Ordner an, sodass diese nicht in Konflikt mit anderen cgroups geraten. Welche Prozesse zu einer cgroup gehören, lässt sich in der Datei cgroup.procs nachschauen:
cat /sys/fs/cgroup/cpu/docker/cd693d893c47737ca5e10c9ac1f550fcceb51cdf5203c9b68b0f11483ed9957c/cgroup.procs
3632
Die eingestellten Limits stehen in cpu.cfs_period_us
cat /sys/fs/cgroup/cpu/docker/cd693d893c47737ca5e10c9ac1f550fcceb51cdf5203c9b68b0f11483ed9957c/cpu.cfs_quota_us
200000
Die Quota ist in Mikrosekunden angegeben und entspricht umgerechnet den im Beispiel definierten zwei CPUs. Um genau zu sein, sagt die Quota aus, dass in einem CPU-Zyklus, der standardmäßig mit 100.000 Mikrosekunden definiert ist, Prozesse in dieser cgroup 200.000 Mikrosekunden CPU-Zeit verwenden dürfen. Das heißt, die Angabe der CPUs wird umgerechnet in cpu.cfs_quota_us/cpu_cfs_period_us.
Dementsprechend befinden sich die Speicher-Limits unter dem memory-Ordner:
cat /sys/fs/cgroup/memory/docker/cd693d893c47737ca5e10c9ac1f550fcceb51cdf5203c9b68b0f11483ed9957c/memory.limit_in_bytes
268435456
Die Ordnerstruktur für Speicher ist identisch zu der für CPUs aufgebaut. Aus Sicht des Kernels sind das getrennte cgroups, die aber denselben Namen/ID tragen. Das macht die cgroups sehr flexibel. Denn theoretisch lassen sich Prozesse in verschiedenen cgroups für unterschiedliche Ressourcentypen zusammenfassen oder auch trennen: für Speicher könnten sich zwei Prozesse eine cgroup teilen, für CPU aber getrennte Limits und cgroups haben.
Darüber hinaus sind cgroups hierarchisch strukturiert, sodass sich bestimmte Limits auf höherer Ebene definieren und dann in den unteren Ebenen weiter zerteilen lassen. Als Beispiel dient die CPU-cgroup von docker:
cat /sys/fs/cgroup/cpu/docker/cpu.cfs_quota_us
-1
Für dockergibt es standardmäßig kein Limit, es lässt sich aber eines setzen. Ist für die cgroup beispielsweise 200.000 gesetzt, dann könnten alle Container, die per Docker gestartet und als Unterordner unter dem docker-Ordner angelegt werden, zusammen nie mehr als zwei CPUs verwenden. Diese hohe Flexibilität ist aber in den meisten Fällen nicht notwendig und macht die Verwaltung nur unnötig komplex. Daher steht mit cgroups v2 eine neue Implementierung parallel bereit, die in Zukunft die alte ablösen soll.
Eine neue cgroup-Hierarchie vereinfacht die Verwaltung
cgroups v2 ist seit dem Kernel 4.5 verfügbar und vereinfacht die Struktur, sodass sich in einer cgroup alle Ressourcen-Limits zusammenfassen lassen. Für das obige Beispiel lassen sich mit cgroups v2 alle Informationen unter folgendem Ordner finden:
ls -l /sys/fs/cgroup/system.slice/docker-cd693d893c47737ca5e10c9ac1f550fcceb51cdf5203c9b68b0f11483ed9957c.scope/
total 0
...
-rw-r--r-- 1 root root 0 Jun 1 11:54 cgroup.procs
-r--r--r-- 1 root root 0 Jun 1 11:55 cgroup.stat
...
-rw-r--r-- 1 root root 0 Jun 1 11:54 cpu.max
-rw-r--r-- 1 root root 0 Jun 1 11:55 cpu.pressure
-r--r--r-- 1 root root 0 Jun 1 11:54 cpu.stat
-rw-r--r-- 1 root root 0 Jun 1 11:54 cpu.weight
...
-rw-r--r-- 1 root root 0 Jun 1 11:55 io.max
-rw-r--r-- 1 root root 0 Jun 1 11:55 io.pressure
-r--r--r-- 1 root root 0 Jun 1 11:54 io.stat
-rw-r--r-- 1 root root 0 Jun 1 11:54 io.weight
...
-r--r--r-- 1 root root 0 Jun 1 11:55 memory.current
-r--r--r-- 1 root root 0 Jun 1 11:54 memory.events
-r--r--r-- 1 root root 0 Jun 1 11:55 memory.events.local
-rw-r--r-- 1 root root 0 Jun 1 11:54 memory.high
-rw-r--r-- 1 root root 0 Jun 1 11:54 memory.low
-rw-r--r-- 1 root root 0 Jun 1 11:54 memory.max
-rw-r--r-- 1 root root 0 Jun 1 11:54 memory.min
...Neben der Vereinfachung und Vereinheitlichung der Hierarchie sowie der Umbenennung einiger Dateien in dem Ordner fällt aber die Unterstützung für einige Ressourcentypen weg, die sich mit v1 noch nutzen ließen. Diese Beschränkung fällt aber in der Regel kaum ins Gewicht. Die neue cgroup-Implementierung ist bei vielen Linux-Distributionen bereits standardmäßig aktiv, darunter:
- Fedora (seit 31)
- Arch Linux (seit April 2021)
- openSUSE Tumbleweed (seit c. 2021)
- Debian GNU/Linux (seit 11)
- Ubuntu (seit 21.10)
Applikationen müssen Containerumgebungen erkennen
cgroups sind jedoch nur eine Seite der Medaille. Applikationen, die in einem Container laufen, sind nicht auf magische Weise der Sicht auf die unterliegende Hardware beraubt, sondern müssen eigenständig erkennen, dass sie in einem Container laufen und aktiv die Limits auslesen. Dieses Verhalten bezeichnet man allgemein als "Container Awareness".
Nimmt man die JVM als Beispiel, so muss sie selbstständig erkennen, ob es sich um cgroup v1 oder v2 handelt. Laut cgroups man-page [2] existiert die Datei /proc/cgroups, die beim Start-up ausgelesen werden kann. Der Inhalt sieht wie folgt aus:
cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 0 167 1
cpu 0 167 1
cpuacct 0 167 1
blkio 0 167 1
memory 0 167 1
devices 0 167 1
freezer 0 167 1
net_cls 0 167 1
perf_event 0 167 1
net_prio 0 167 1
hugetlb 0 167 1
pids 0 167 1
rdma 0 167 1
misc 0 167 1Diese Datei beschreibt, welche cgroups-Controller (Subsysteme pro Ressourcentyp) im Kernel kompiliert und wo diese in der cgroup-v1-Hierarchie aufgehängt sind. Die Hierarchie beinhaltet eine 0, wenn der Controller nicht in die v1-Hierarchie, sondern in v2 gemountet ist. Diese Information kann daher zur Unterscheidung dienen und wird auch aktiv von der JVM verwendet [3].
Nach der Unterscheidung muss der Prozess auf die Limits zugreifen. Die cgroup-Informationen sind innerhalb des Containers im Ordner /sys/fs/cgroup verfügbar. Um etwa das Speicher-Limit einer v2 cgroup auszulesen, lässt sich der folgende Befehl nutzen:
docker run –memory 256m ubuntu cat /sys/fs/cgroup/memory.max
268435456
Über diesen Weg kann die JVM dann Informationen wie die Heap-Größe oder die Threadanzahl korrekt berechnen, wenn sie in einem Container gestartet wird.
CPU-Zeit gewichtet auf Prozesse verteilen
Die bisherigen Beispiele haben sich auf "einfache" Ressourcen beschränkt, etwa die maximale CPU-Zeit oder Speicher, die einem Prozess zugeteilt sind. Es gibt aber auch noch die sogenannten CPU Shares als Ressource, die Einfluss darauf haben kann, wie sich die JVM in einem Container verhält. CPU Shares sind ein Maß für die Gewichtung, wenn mehrere Prozesse um CPU-Zeit konkurrieren. Sie stellen kein Limit im eigentlichen Sinn dar, sondern beziehen sich lediglich auf das Verhältnis verschiedener Prozesse zueinander.
Beim Starten eines Containers beträgt der Standardwert für CPU Shares 1024, sofern Entwicklerinnen oder Entwickler keinen anderen definieren. Dieser Wert lässt zunächst keine Rückschlüsse darauf zu, wieviel CPU-Zeit ein Prozess verwenden kann. Läuft auf einem Server nur ein einziger Container, kann dieser die komplette CPU-Zeit nutzen. Startet auf demselben Server ein zweiter Container mit einem größeren CPU Share (beispielsweise 2048), hat das solange keine Auswirkung auf den ersten Prozess und dessen CPU-Zeit, wie ausreichend Ressourcen zur Verfügung stehen.
Die Gewichtung greift erst dann, wenn die Ressourcen knapp werden und der Kernel den Zugriff auf die CPU priorisieren muss. Dann wird dem Container mit dem größeren CPU Share mehr CPU-Zeit zugesprochen – im obigen Beispiel also genau doppelt so viel.

Die CPU Shares lassen sich unter cgroup v1 wie folgt auslesen:
docker run ubuntu cat /sys/fs/cgroup/cpu/cpu.shares
1024
Unter cgroup v2 sieht das etwas anders aus:
docker run ubuntu cat sys/fs/cgroup/cpu.weight
100
Abgesehen von der Namensänderung von CPU Shares zu CPU Weight beträgt der Standardwert nun 100 statt 1024. Greifen Entwicklerinnen und Entwickler jedoch auf Docker CLI zurück, um Container zu starten, bleibt der Standardwert bei 1024 und auch der Begriff CPU Shares gilt unverändert. Docker übernimmt im Hintergrund das Umrechnen des Wertes für den CPU Share auf den passenden für CPU Weight mit der folgenden Formel [4]:
cpu.weight = (1 + ((cpu.shares – 2) * 9999) / 262142)
Das Ergebnis lässt sich im Container ansehen:
docker run –cpu-shares 1024 ubuntu cat /sys/fs/cgroup/cpu.weight
39
Auch Kubernetes macht Gebrauch von CPU Shares respektive CPU Weight.
apiVersion: v1
kind: Pod
metadata:
name: app
spec:
containers:
- name: app
image: nginx
resources:
requests:
cpu: 2Im obigen Beispiel wird der CPU Request einer Applikation auf 2 gesetzt. Den Wert nutzt Kubernetes, um für die Platzierung der Applikation einen geeigneten Server zu wählen. Dabei wird der CPU-Request-Wert auch als CPU Share beim Starten des Containers gesetzt: 2*1024 = 2048.
Obwohl sich anhand dieser Angabe keine Aussage über die aktuell verfügbare CPU-Zeit machen lässt, zieht die JVM diese Information unter bestimmten Umständen als Grundlage zum Bestimmen der konkret verfügbaren CPUs heran. Das kann zu unerwartetem, bisweilen sogar sehr sonderbarem Verhalten führen.
Um das Gesamtbild zu verstehen, muss man sich auch anschauen, wie die JVM mit diesen Einstellungen umgeht.
Wie sich die JVM der Umgebung anpasst
Bevor sich Container als Deployment-Methode etabliert hatten, war die JVM eine willkommene Möglichkeit, ein und dieselbe Java-Applikation portabel auf Windows- oder Linux-Plattformen zu betreiben. Zu dieser Zeit waren große Java-Client-Applikationen noch stärker verbreitet als heutzutage. Java-Anwendungen mussten auf unterschiedlichster Hardware und parallel zu anderen Applikationen einsetzbar sein. Um die knappen Ressourcen effizienter teilen zu können, überprüft die JVM beim Starten den Umfang der insgesamt verfügbaren Ressourcen und konfiguriert den eigenen Ressourcenbedarf wie etwa für die Heapgröße entsprechend. Die Standardeinstellungen lassen sich dabei über verschiedene Programmparameter überschreiben und steuern.
Dieses Anpassen der JVM an die begrenzten Hardwareressourcen bezeichnet man als Ergonomics [5].
Folgende Einstellungen der JVM werden durch die Hardware bestimmt:
java -XX:+PrintFlagsFinal -version | grep ergonomic
intx CICompilerCount = 4 {ergonomic}
uint ConcGCThreads = 2 {ergonomic}
uint G1ConcRefinementThreads = 8 {ergonomic}
size_t G1HeapRegionSize = 2097152 {ergonomic}
uintx GCDrainStackTargetSize = 64 {ergonomic}
size_t InitialHeapSize = 268435456 {ergonomic}
size_t MarkStackSize = 4194304 {ergonomic}
size_t MaxHeapSize = 4294967296 {ergonomic}
size_t MaxNewSize = 2575302656 {ergonomic}
size_t MinHeapDeltaBytes = 2097152 {ergonomic}
size_t MinHeapSize = 8388608 {ergonomic}
uintx NonNMethodCodeHeapSize = 5839372 {ergonomic}
uintx NonProfiledCodeHeapSize = 122909434 {ergonomic}
uintx ProfiledCodeHeapSize = 122909434 {ergonomic}
uintx ReservedCodeCacheSize = 251658240 {ergonomic}
bool SegmentedCodeCache = true {ergonomic}
size_t SoftMaxHeapSize = 4294967296 {ergonomic}
bool UseCompressedClassPointers = true {ergonomic}
bool UseCompressedOops = true {ergonomic}
bool UseG1GC = true {ergonomic}
bool UseNUMA = false {ergonomic}
bool UseNUMAInterleaving = false {ergonomic}Die Wichtigsten darunter sind:
- Die Auswahl des Garbage Collectors
- Die Heapgröße
- Die Anzahl der möglichen parallelen Threads (zum Beispiel für den Garbage Collector, CI Compiler aber auch für den Default Thread Pool für Parallel Streams)
Diese Einstellungen sind sinnvoll, wenn sich eine Applikation Ressourcen mit anderen teilen muss. In einer containerisierten Welt, in der alle Ressourcen innerhalb eines Containers im Normalfall dem laufenden Hauptprozess in Gänze zur Verfügung stehen, sind aber viele Standardeinstellungen nicht mehr zeitgemäß.
Um das Zusammenspiel von JVM und Containern besser verstehen zu können und etwaige Stolperfallen zu vermeiden, kommen in den nächsten Abschnitten alle Einstellungen separat auf den Prüfstand.
Der Heap im Kleinen wie im Großen
Standardmäßig nutzt die JVM ein Viertel des gesamten Speichers für die Heapgröße. In einem Container ist diese Einstellung höchst ineffizient, da dann drei Viertel des dem Container zugeteilten Speichers ungenutzt bleiben.
In moderneren Java-Versionen empfiehlt es sich daher, diesen Wert mit Hilfe des Parameters -XX:MaxRAMPercentage=XX zu überschreiben – etwa wie folgt:
docker run -m 512m eclipse-temurin:18.0.1_10-jre java -XX:MaxRAMPercentage=80 -XX:+PrintFlagsFinal -version | grep -E "\sMaxHeapSize"
size_t MaxHeapSize = 429916160 {product} {ergonomic}Damit stehen 80 Prozent der zugewiesenen 512 MByte als Heap zur Verfügung.
Zu beachten ist, dass der MaxRAMPercentage-Wert bei sehr kleinem Speicher nicht greift. Nehmen wir als Beispiel 248 MByte für den Container.
docker run -m 248m eclipse-temurin:18.0.1_10-jre java -XX:MaxRAMPercentage=80 -XX:+PrintFlagsFinal -version | grep -E "\sMaxHeapSize"
size_t MaxHeapSize = 130023424 {product} {ergonomic}Die Heapgröße beträgt dann nicht wie zu vermuten 80, sondern nur 50 Prozent des gesamten Speichers. Die Erklärung dafür ist, dass bei wenig verfügbarem Speicher automatisch der Parameter -XX:MinRAMPercentage=XX greift, der standardmäßig auf 50 steht.
In einem containerisierten Umfeld sind kleine Container unterhalb von 250 MByte keine Seltenheit. Wenn ein Container daher unerwartet mit einem OOM aussteigt oder der Heap in der JVM vollläuft, kann das häufig an einer fehlenden oder falschen Einstellung von MinRAMPercentage liegen. Unterhalb von 250 MByte greift MinRAMPercentage, erst darüber MaxRAMPercentage.
Noch undurchsichtiger wird die Situation dadurch, dass ab 250 MByte nicht einfach der von MaxRAMPercentage berechnete Wert angesetzt wird, sondern erst eine Prüfung erfolgt, ob der Wert größer ist als der größtmögliche mit MinRAMPercentage berechnete. Der größte MinRAMPercentage-Wert ist:
possible_min_heap_size = MinRamPercentage * 249m
Dieser Wert gilt, wenn er größer ist als der mit MaxRAMPercentage berechnete – zum Beispiel:
docker run -m 512m eclipse-temurin:18.0.1_10-jre java -XX:MaxRAMPercentage=10 -XX:+PrintFlagsFinal -version | grep -E "\sMaxHeapSize"
size_t MaxHeapSize = 132120576 {product} {ergonomic}Obwohl als MaxRAMPercentage 10 angegeben ist, nimmt die Heapgröße 126 MByte anstatt 51 MByte an. Im Beispiel kommt daher so lange der von MinRAMPercentage berechnete Wert zum Einsatz, bis der von MaxRAMPercentage berechnete größer ist.
Um den Heap in einem Container optimal zu konfigurieren, müssen Entwicklerinnen und Entwickler daher immer beide Einstellungen im Augen behalten.
Thread Count und die magische Zahl
Die Anzahl der möglichen Threads, der sogenannte ActiveProcessorCount, richtet sich nach den verfügbaren CPUs, die die JVM sehen kann. Dieser Wert lässt sich durch die Parameter --cpus oder --cpu-shares beim Starten des Containers beeinflussen.
Sind beide Parameter gesetzt, wird stets nur --cpus ausgewertet, wie das folgende Beispiel zeigt:
docker run --cpus 3 --cpu-shares 1024 eclipse-temurin:18.0.1_10-jre java -Xlog:os+container=trace -version | grep -A3 -E "CPU Shares"
[debug][os,container] CPU Shares is: 1024
[trace][os,container] CPU Quota count based on quota/period: 3
[trace][os,container] CPU Share count based on shares: 1
[trace][os,container] OSContainer::active_processor_count: 3Das Ergebnis der CPU-Shares-Berechnung ist 1, da aber drei CPUs gesetzt wurden, hat dieser Wert Vorrang. Wenn nur CPU Shares gesetzt wird, kommt 1 als Ergebnis zum Einsatz.
docker run --cpu-shares 1024 eclipse-temurin:18.0.1_10-jre java -Xlog:os+container=trace -version | grep -B3 -A2 -E "CPU Shares"
[trace][os,container] Path to /cpu.weight is /sys/fs/cgroup//cpu.weight
[trace][os,container] Raw value for CPU shares is: 39
[trace][os,container] Scaled CPU shares value is: 1024
[debug][os,container] CPU Shares is: 1024
[trace][os,container] CPU Share count based on shares: 1
[trace][os,container] OSContainer::active_processor_count: 1Das Beispiel macht noch eine Besonderheit deutlich. Es läuft mit cgroup v2, daher rechnet Docker den CPU-Shares-Wert um in Weight – hier im Beispiel 39. Die JVM nutzt aber wieder den CPU-Shares-Wert, um den ActiveProcessorCount zu berechnen, das heißt, die JVM rechnet Weight eigenhändig wieder mit der bekannten Formel in CPU Shares um.
Dieses zweifache Umrechnen führt zu Rundungsfehlern, wie im folgenden Beispiel zu erkennen ist:
docker run --cpu-shares 1048 eclipse-temurin:18.0.1_10-jre java -Xlog:os+container=trace -version | grep -B3 -A2 -E "CPU Shares"
[0.001s][trace][os,container] Path to /cpu.weight is /sys/fs/cgroup//cpu.weight
[0.001s][trace][os,container] Raw value for CPU shares is: 40
[0.001s][trace][os,container] Scaled CPU shares value is: 1050
[0.001s][trace][os,container] Closest multiple of 1024 of the CPU Shares value is: 1024
[0.001s][debug][os,container] CPU Shares is: 1024
[0.001s][trace][os,container] CPU Share count based on shares: 1
[0.001s][trace][os,container] OSContainer::active_processor_count: 1Obwohl 1048 gesetzt ist und Weight den Wert 40 anstatt 39 annimmt, berechnet die JVM den CPU-Shares-Wert zu 1024. Das kann irritieren, insbesondere dann, wenn man die gleiche Applikation mit denselben Einstellungen in einer Umgebung startet, in der noch cgroup v1 aktiv ist. Dasselbe Beispiel auf cgroup v1 kommt nämlich zu einem anderen Ergebnis.
docker run --cpu-shares 1048 eclipse-temurin:18.0.1_10-jre java -Xlog:os+container=trace -version | grep -B1 -A2 -E "CPU Shares"
[0.001s][trace][os,container] Path to /cpu.shares is /sys/fs/cgroup/cpu,cpuacct/cpu.shares
[0.001s][trace][os,container] CPU Shares is: 1048
[0.001s][trace][os,container] CPU Share count based on shares: 2
[0.001s][trace][os,container] OSContainer::active_processor_count: 2Mit dem identischen Docker-Aufruf berechnet die JVM jetzt, dass sie zwei aktive Prozessoren zur Verfügung hat anstatt einem. Dies bleibt Entwicklerinnen und Entwicklern im Betrieb vermutlich verborgen, kann aber große Auswirkungen auf die Performance der Applikation haben.
Über die genannten Unterschiede zwischen cgroups v1 und v2 hinaus gilt es noch eine weitere Besonderheit beim Festlegen von CPU Shares zu beachten, und zwar dann, wenn man aktiv den Standardwert von 1024 setzt (bei cgroups v1):
docker run --cpu-shares 1024 eclipse-temurin:18.0.1_10-jre java -Xlog:os+container=trace -version | grep -B1 -A2 -E "CPU Shares"
[0.001s][trace][os,container] Path to /cpu.shares is /sys/fs/cgroup/cpu,cpuacct/cpu.shares
[0.001s][trace][os,container] CPU Shares is: 1024
[0.001s][trace][os,container] OSContainer::active_processor_count: 4
[0.001s][trace][os,container] CgroupSubsystem::active_processor_count (cached): 4Die JVM berechnet bei 1024 nicht den zu erwartenden Wert von 1, sondern 4. Das Beispiel läuft auf einer Maschine mit vier physischen Kernen. Die JVM ignoriert in diesem Fall also die CPU Shares komplett und berechnet den Wert anhand der physikalischen Umgebung.
Da keine befriedigende Dokumentation zur JVM existiert, die diesen Sachverhalt erklärt, liegt die Vermutung nahe, dass die JVM nicht unterscheiden kann, ob der Standardwert aktiv gesetzt oder gar nicht erst angegeben wurde. Ist kein Wert gesetzt, dürfen Entwicklerinnen und Entwickler davon ausgehen, dass der Prozess auch nicht limitiert ist.
Der Vollständigkeit halber sei erwähnt, dass dieser Effekt auch in cgroups-v2-Umgebung auftritt. Der Standardwert für CPU Weight ist dort 100. Umgerechnet mit der Formel ergibt sich ein CPU-Shares-Wert von 2623. Ist dieser Wert beim Start des Containers gesetzt, ergibt sich dasselbe Ergebnis:
docker run --cpu-shares 2623 eclipse-temurin:18.0.1_10-jre java -Xlog:os+container=trace -version | grep -B1 -A2 -E "CPU Shares"
[0.026s][trace][os,container] Raw value for CPU shares is: 100
[0.026s][debug][os,container] CPU Shares is: -1
[0.026s][trace][os,container] OSContainer::active_processor_count: 4Auch hier droht stets die Gefahr, durch falsch eingestellte Werte ein unerwartetes Verhalten auszulösen.
Vor diesem Hintergrund überrascht es, dass die CPU Shares überhaupt zur Berechnung des ActiveProcessorCounts herangezogen werden – zumal deren Wert nur sinnvoll ist im Vergleich mit anderen Containern, die auf demselben Server laufen. Die Berechnung, die ergibt, dass 1025 CPU Shares nur einer CPU entsprechen, kann dazu führen, dass nur wenige Threads zum Einsatz kommen, obwohl dem Container sehr viel mehr CPU-Zeit zur Verfügung stünde.
Solche Probleme lassen sich durch eine der folgenden Maßnahmen beheben:
- Stets ein CPU-Limit setzen mit
—cpus - oder die Berechnung des
ActiveProcessorCountdeaktivieren und ihn direkt mit-XX:ActiveProcessorCount=Xsetzen.
Die zweite Lösung kommt häufig bei Buildpacks zum Einsatz, die ein Java-Image nur auf Basis des Sourcecodes erzeugen können. Die Vorgehensweise scheint ganz allgemein geeignet zu sein, um sich vor Überraschungen zu schützen.
Die Wahl des Garbage Collector
Traditionell kennt die JVM zwei Betriebsmodi: auf dem Server oder auf dem Client. Da unterschiedliche Anforderungen zu erfüllen sind, kommen in beiden Fällen verschiedene Gargabe Collectors (GC) zum Einsatz.
Bei Serverapplikationen stehen der Durchsatz und niedrige Latenzen im Vordergrund, daher empfiehlt sich ein GC, der keine Stop-the-world-Events auslöst und seine Arbeit parallel zu den von der Applikation verwendeten Threads ausübt. Dabei ist es akzeptabel, einen aufwendigeren GC zu nutzen, der insgesamt mehr Ressourcen verbraucht.
Bei Clientapplikationen spielt der Durchsatz keine Rolle, wichtiger ist ein kleiner Footprint. Im Clientumfeld kommt daher standardmäßig der weniger komplexe SerialGC zum Einsatz.
Auch wenn diese Unterscheidung im Allgemeinen heutzutage nicht mehr relevant ist, spielt sie für die JVM weiterhin eine Rolle, denn die JVM definiert einen Server als eine Maschine mit:
- >= 1 CPU
- >= 2 GB (um genau zu sein 1792m)
Alle Maschinen, die weniger Ressourcen bieten, sind aus Sicht der JVM ein Client. Mithin kommt dann der SerialGC zum Einsatz, wie im folgenden Beispiel beschrieben:
docker run -m 1791m eclipse-temurin:18.0.1_10-jre java -XX:+PrintFlagsFinal -version | grep -E "Use(G1|Serial)GC"
bool UseG1GC = false {product} {default}
bool UseSerialGC = true {product} {ergonomic}Die Wahl des SerialGC kann maßgeblichen Einfluss auf die Performance haben, insbesondere, wenn Entwicklerinnen und Entwickler hohe Anforderungen bezüglich der Antwortzweiten stellen.
Darüber hinaus kommt es in der Praxis häufig vor, dass Java-Anwendungen weniger als zwei GByte Speicher zur Verfügung stehen, um den Ressourcenverbrauch im Container möglichst niedrig zu halten. Eine Skalierung erfolgt dann horizontal, in dem dieselbe Anwendung mehrfach läuft. Infolge dieser Vorgehensweise dürften viele Applikationen – gerade in Produktion – ungewollt mit dem SerialGC laufen.
Umgehen lässt sich das Problem, in dem Entwicklerinnen und Entwickler aktiv den gewünschten GC vorgeben, etwa mit -XX:+UseG1GC:
docker run -m 1791m eclipse-temurin:18.0.1_10-jre java -XX:+PrintFlagsFinal -XX:+UseG1GC -version | grep -E "Use(G1|Serial)GC"
bool UseG1GC = true {product} {default}
bool UseSerialGC = false {product} {ergonomic}Fazit: The Good, the Bad and the JVM
Die JVM hat über die letzten Jahre hinweg viele neue Features hinzubekommen, die die Zusammenarbeit und Integration mit Container-Technologien verbessern. Zaubern kann sie deswegen aber noch lange nicht: viele Entscheidungen beruhen noch immer auf einem veralteten Verständnis der physikalischen IT-Umgebung und funktionieren in einer containerisierten Welt nicht – stattdessen lösen sie öfter Stirnrunzeln bei den Beteiligten beziehungsweise Betroffenen aus.
Deswegen ist der Blick hinter die Kulissen so wichtig, um ein Verständnis zu gewinnen, wie das Zusammenspiel zwischen JVM und Container im Detail funktioniert. Nur so lässt sich die effektivste Konfiguration finden und bösen Überraschungen vorbeugen.
Denn eins muss man der JVM lassen: Es gibt kein Verhalten, dass Entwicklerinnen und Entwickler nicht selbst beeinflussen könnten – im Guten wie im Schlechten.
Sascha Selzer
ist Senior Consultant bei der innoQ Deutschland GmbH. Er hat langjährige Erfahrung in der Entwicklung mit JVM-basierten Sprachen und in Software-Architektur. Sein aktueller Fokus liegt auf der Konzeption und Umsetzung von Backend-Architekturen, sowie von Continuous Delivery/Deployment-Strategien. Er beschäftigt sich darüber hinaus mit Themen im Bereich Cloud wie Monitoring- und Tracinglösungen als auch dazugehörende Architektur- und Entwicklungsparadigmen (Microservices, DevOps).
(map [6])
URL dieses Artikels:
https://www.heise.de/-7329126
Links in diesem Artikel:
[1] https://www.oracle.com/java/technologies/javase/8u191-relnotes.html
[2] https://www.man7.org/linux/man-pages/man7/cgroups.7.html
[3] https://github.com/openjdk/jdk/blob/master/src/hotspot/os/linux/cgroupSubsystem_linux.cpp#L142
[4] https://github.com/containers/crun/blob/main/crun.1.md#cpu-controller
[5] https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/ergonomics.html
[6] mailto:map@ix.de
Copyright © 2022 Heise Medien