

Kopienjäger
Aufsehenerregende Plagiatfälle haben in letzter Zeit insbesondere die akademische Gemeinde aufgeschreckt. Lassen sich solche Arbeiten nicht per Software auf Originalität prüfen? An der HTW Berlin untersucht ein wissenschaftlerteam seit einigen Jahren Plagiaterkennungssysteme und hat die fünf besten auf die guttenbergsche Doktorarbeit angesetzt.
- Debora Weber-Wulff
- Katrin Köhler
Nicht nur Universitäten, auch Verlage und andere Betriebe, die für die Öffentlichkeit bestimmte Publikationen generieren, wären froh über eine Art Wunderwaffe, die in Windeseile feststellen kann, ob eine digital vorliegende Arbeit ein Plagiat ist oder nicht. An den Hochschulen brauchten manche Einreichungen von den Dozenten gar nicht erst gelesen werden, man könnte sie gleich dem Prüfungsausschuss melden.
Zwar hat der Doktorvater von zu Guttenberg behauptet, dass diese Programme damals noch nicht so weit waren. Aber die Macher des Plagiaterkennungssystems Turnitin widersprachen: „Herr zu Guttenberg hätte seine Arbeit schon durch unser Programm laufen lassen können. Das hätte ihm viel Ärger erspart.“ [1]
iX-TRACT
- Die HTW Berlin testet seit mehreren Jahren Plagiaterkennungssysteme, die ihre Dienste via Internet anbieten.
- Die fünf besten dieser Systeme mit dem Testurteil „teilweise nützlich“ wurden auf die Dissertation von Karl-Theodor zu Guttenberg angesetzt und ihre Ergebnisse mit denen des GuttenPlagWiki verglichen.
- Das GuttenPlagWiki ist zwar den maschinellen Erkennungssystemen weit voraus, trotzdem können diese bei einem ersten Verdacht wichtige Hinweise auf Plagiate geben.
Schnödes Eigenlob? Seit 2004 werden sogenannte Plagiaterkennungssysteme an der HTW Berlin getestet. Über mehrere Jahre wurden viele Testfälle in verschiedenen Sprachen entwickelt, um mit verschiedenen Arten von Plagiaten, aber auch mit Originalarbeiten diese Systeme auf Herz und Nieren zu testen. Die Hersteller müssen dabei bereit sein, ihr System kostenlos zum Test zur Verfügung zu stellen, was gelegentlich wegen schlechter Bewertungen in der Vergangenheit nicht der Fall war.
Der jüngste Test erschien im Januar 2011 [2], die 26 untersuchten Lösungen wurden entsprechend ihrer Leistungsfähigkeit in drei Klassen eingeteilt: „teilweise nützlich“, „bedingt nützlich“ und „nutzlos“. Selbst die besten Systeme finden höchstens 60 bis 70 Prozent der plagiierten Anteile. Eine ganze Reihe weiterer Systeme ist hingegen kaum brauchbar. In der Kategorie der nutzlosen Systeme haben wir sogar einige Betrüger ausfindig gemacht, die nur die Dokumente einsammeln wollen.
Die Systeme können naturgemäß den zu prüfenden Text nur mit digital verfügbaren Inhalten vergleichen. Sie arbeiten internetbasiert, man lädt sein Dokument über eine Webform auf das System oder schickt es per E-Mail ein und bekommt nach mehr oder weniger langer Wartezeit ein Ergebnis, das auf ähnliche oder gleiche Textstellen im Web verweist. Dabei versuchen die Erkennungssysteme auch zu überprüfen, ob diese Textstellen im zu analysierenden Dokument als Zitat gekennzeichnet sind – was aber in der Praxis nur selten funktioniert.
Schwarmintelligenz in der „Crowd“
Eine häufig geäußerte Kritik an der Testmethode war die geringe Länge der untersuchten Dokumente zwischen 389 und 1055 Wörtern. Im Februar 2011 beschlossen wir daher, die Arbeit von Karl-Theodor zu Guttenberg zu testen. Hier hatten wir die Gelegenheit, ein 475-seitiges Werk, das durch „Crowd-Sourcing“, die Zusammenarbeit vieler Menschen über das Internet, bereits detailliert in seine plagiierten Einzelteile zerlegt wurde, mit den fünf „teilweise nützlichen“ Systemen zu untersuchen. Es sollte also darum gehen, ob die „Crowd“ die in der Cloud arbeitenden Softwaresysteme schlägt oder vice versa.
Nachdem der Bremer Jura-Professor Andreas Fischer-Lescano im Februar 2011 einen Plagiatverdacht gegenüber der Dissertation von Karl-Theodor zu Guttenberg geäußert hatte und Letzterer den Vorwurf „abstrus“ nannte, fand sich eine kleine Gruppe von interessierten Personen, unter anderem Doktoranden und Promovierte, in einem Wikia-Wiki zusammen. Wikia ist eine werbefinanzierte, offene Kollaborationsplattform, die kostenlose Wikis mit einem recht simpel gehaltenen WYSIWYG-Editor anbietet. Da Plagiatoren selten nur an einer Stelle plagiieren, wurde das GuttenPlagWiki gegründet, und man begann damit, die Arbeit zu sezieren.
Mit der Zeit entwickelte die Kerngruppe, die nur aus circa 20 Leuten besteht, eine für die Weiterverarbeitung nützliche Art der Darstellung. Eine Fundstelle wird als „Fragment“ bezeichnet und mit der Seitenzahl im Plagiat benannt, gefolgt von den entsprechenden Zeilen in einer Von-Bis-Notation.
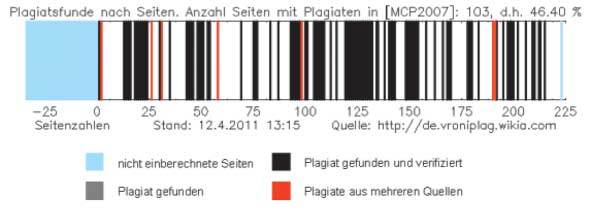
Das Symbol der Plagiarismusjäger – der „Barcode“ – zeigt an, welche Seiten Plagiate enthalten (Abb. 1). Mithilfe einer Visualisierungssprache wurde der Barcode auf Basis der Fragmentenliste halbautomatisch generiert, gegen eine vollautomatische Erstellung hatte sich der innere Kern der Gruppe entschieden, weil man falsche Plagiatmeldungen im Wiki befürchtete, die das Projekt hätten diskreditieren können. Bevor der Barcode erschien, gab es immer eine Plausibilitätsprüfung. Die Schärfe der Auseinandersetzung war auch für Unbeteiligte unübersehbar, weniger bekannt geworden sind die Fälle von Textvandalismus, Beschimpfungen und anonymen Drohungen.
Die „Cloud“ als Alternative
Dass die Zu-Guttenberg-Arbeit in großen Teilen ein Plagiat ist, ist mittlerweile unumstritten; zu Details der GuttenPlag-Auswertung später. Die Idee, alle akademischen Arbeiten digital einzureichen und durch eine Software testen zu lassen, um Plagiaten vorzubeugen, ist auf dem Hintergrund der Geschehnisse naheliegend.
So haben wir bei den fünf besten Plagiaterkennungssystemen die Guttenberg-Dissertation eingereicht. Alle beteiligten Anbieter – PlagAware, Turnitin/iThenticate, Ephorus, PlagScan und Urkund – arbeiten „in der Cloud“: Man weiß nicht, auf welchem Server in welchem Land die hochgeladene Arbeit landet und ebenso wenig, wer alles darauf Zugriff hat. Bei einigen der von uns 2010 geprüften Systeme beinhalten die AGB sogar, dass man alle Nutzungsrechte an den Texten der jeweiligen Firma einräumt, etwa bei Turnitin: „With regard to papers submitted to the Site, You hereby grant iParadigms a non-exclusive, royalty-free, perpetual, world-wide, irrevocable license to reproduce, transmit, display, disclose, archive and otherwise use in connection with the Services any paper You submit to the Site.“
Doch zurück zur KTzG-Arbeit. Bei deren digitaler Version handelt es sich um ein professionell gesetztes PDF, das Ligaturen verwendet und den Blocksatz mittels schmaler Leerzeichen (Gevierte) herstellt. Es ist 7,3 MByte groß und besteht inklusive Anhängen et cetera aus 475 Seiten mit rund 190 000 Wörtern; die genaue Zahl hängt von der Zählweise von Ausdrücken wie „§ 6, Abs. 1“ zusammen.
Wegen der Größe der Datei kam es zu einigen Problemen beim Hochladen. PlagAware brach auf Seite 159 ab, weil bereits zu viele Übereinstimmungen gefunden worden waren. iThenticate zerlegte die Arbeit in 13 Teile à 15 000 Wörter und prüfte jeden Teil einzeln. Bei Urkund schien zunächst das ganze System gecrasht zu sein. Die Korrespondenz mit dem technischen Support ergab, dass insbesondere durch die Übereinstimmungen mit dem GuttenPlagWiki die interne Grenze von 1000 Hits erreicht und der Bericht daher nicht darstellbar war. Die Techniker konnten das in einer Wochenendschicht fixen und ermöglichten so doch noch einen Bericht. PlagScan hatte zwar kein Problem mit der Dateigröße, musste aber eine Nacht rechnen, bis ein Ergebnis vorlag.
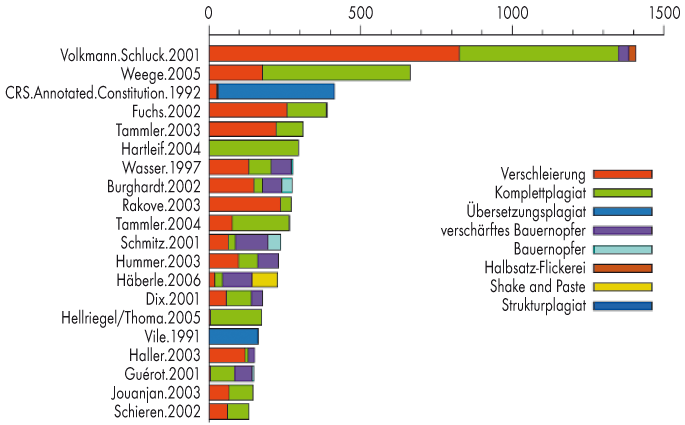
Zur Beurteilung der Resultate dienten die GuttenPlagWiki-Ergebnisse. Dabei ergaben sich zwei Fragestellungen, die typisch für Information Retrieval sind:
1. Wie viele der am meisten plagiierten Quellen (siehe Abb. 2) sind gefunden worden (Ausbeute)?
2. Wie viele der gemeldete Funde sind tatsächlich Primärquellen (Präzision)? Am Anfang gab es bei GuttenPlag sogar 151 gemeldete Quellen, aber während des Tests wurden einige Texte aus der Liste gestrichen, weil diese in anderen Werken zu finden waren. Einige von diesen Werken waren „Plagiatsvettern“, haben also von den gleichen Quellen wie zu Guttenberg ohne Quellenangabe übernommen, andere haben korrekt zitiert. Wir haben immerhin auch eine Quelle gefunden, die noch nicht im GuttenPlagWiki verzeichnet war (Pernice) und diese dort nacherfasst.
Vorab seien noch zwei eventuell nicht jedem geläufige Begriffe aus der Plagiatdiskussion erklärt.
Ein Bauernopfer ist – laut Lahusen – die richtige Referenzierung eines kleinen Zitats und die anschließende weitere wortwörtliche Übernahme ohne Zitatzeichen. Damit entsteht der Eindruck, der Text sei vom Autor.
Ein verschärftes Bauernopfer ist die Unterbringung der Quelle im Literaturverzeichnis, ohne die genaue Verwendungsstelle zu kennzeichnen.
Als Strukturplagiat wird die Übernahme eines Gedankengangs, einer Argumentenkette oder der Fußnoten in aufsteigender Reihenfolge aus einem anderen Werk bezeichnet. Das wird zwar volkstümlich nicht als Plagiat angesehen („Die Quelle wurde genannt“ beziehungsweise „Das ist ganz anders gesagt worden“), wissenschaftlich aber durchaus.
Abdeckung der Top-Quellen
Erstaunlicherweise finden die Systeme nicht alle auffindbaren, häufig verwendeten Originale. Sieben der 20 Top-Quellen stammen aus dem Wissenschaftlichen Dienst des Deutschen Bundestages und sind nicht veröffentlicht, bei vier handelte es sich um Bücher, die man über Google-Books finden kann. Eine Quelle, Vile 1991, wurde übersetzt und ist damit maschinell unauffindbar. Insgesamt waren also acht der 20 Top-Quellen im Prinzip online auffindbar, sieben davon fanden immerhin mindestens 3 der 5 Systeme (Tabelle 1).
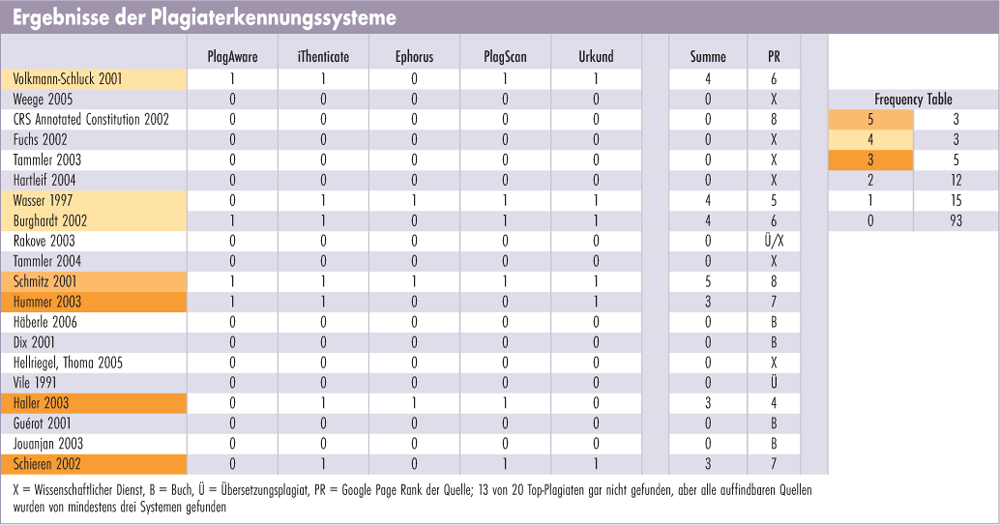
Die Hauptquelle, Volkmann-Schluck, nannten alle Systeme außer Ephorus, und zwar an erster Stelle. Nur Schmitz 2001 (4. Platz unter den auffindbaren Quellen), der FAZ-Artikel von Zehnpfennig (Platz 9) und ein Aufsatz von Nettesheim 2002 (Platz 10) wurden von allen fünf Systemen gefunden. Allerdings stand Zehnpfennig oft erst recht weit hinten in der Liste, PlagScan beispielsweise meldete diese Quelle erst an 38. Stelle. Teilweise fanden die Systeme auch nur wenig Übereinstimmung, wir haben jedoch nur „ja/nein“ bewertet: gemeldet oder nicht. Daher sind diese Zahlen als Obergrenzen dafür anzusehen, was mit einem solchen System auffindbar wäre.
Die Systeme im Detail
Die GuttenPlag-Gruppe fand heraus, dass auf 94 % der Seiten und in 63 % der Zeilen Plagiate enthalten sind. Die Systeme gaben die Prozentzahlen wie in der Tabelle „Prozentuale Plagiatgewichtung“ an, wobei nirgends erklärt wird, was diese Prozentzahlen bedeuten – handelt es sich um Prozent der Stichprobe oder um Prozent der Gesamtarbeit?

Außerdem variierten die angegebenen Prozentzahlen und Fundstellen durchaus von Tag zu Tag, obwohl wir in der Zwischenzeit keine neuen Berichte angefordert hatten.
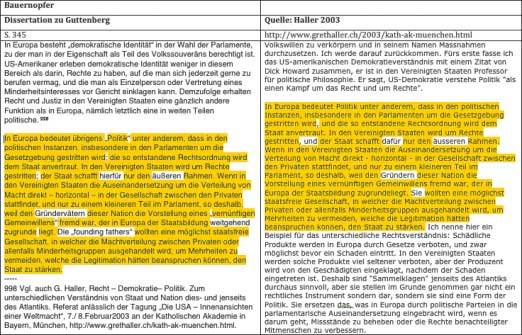
Neben der Auswertung selbst ist deren Präsentation wichtig sowie die Benutzerfreundlichkeit der Software. Hier gibt es viel Verbesserungsbedarf. So konnte man bei keinem der Berichte auf die gemeldete Plagiatstelle klicken, um die Seitennummer zu sehen. Dies wäre aber notwendig, wenn ein Plagiatfall vor einem Promotionsausschuss verhandelt würde. Nötig wäre eine gut lesbare und klar nachvollziehbare, farblich markierte Gegenüberstellung des plagiierten Textes und des Originaltextes, wie in Abbildung 3 beispielhaft händisch erstellt. Um ein Plagiat für einen Prüfungsausschuss zu dokumentieren, müsste die Quelle mit genauen Angaben dokumentiert sein.
Nun zu den Ergebnissen im Einzelnen: PlagAware: Die Gegenüberstellung, die uns bei kurzen Dokumenten bislang gefallen hatte, zeigte sich bei dieser langen Arbeit als extrem problematisch. Es wurden oft nur drei bis vier Wörter markiert, dann folgten „[…]“ und wieder drei bis vier Wörter. Zunächst musste man also eine weite Strecke scrollen, um über das Vorwort und das Inhaltsverzeichnis hinauszukommen. Ein Jura-Professor hätte bei solch einem Ergebnis das System vermutlich als kaputt eingeschätzt und den Test abgebrochen. Darüber hinaus ist nicht ersichtlich, aus welchem Teil der Arbeit die markierten Stellen kamen – wir mussten danach händisch im PDF suchen. Etliche der gemeldeten Quellen gehörten zu Pastebin, einer Website zur einfachen Textveröffentlichung, oder dem GuttenPlagWiki. Solche Quellen ließen sich aber vom Vergleich ausnehmen. Der Bericht verschwand zwischendurch nach einem Software-Update aus der Datenbank – was hoffentlich bei zahlenden Kunden nicht vorkommt. Wir hatten, wie bei allen Kandidaten, einen kostenlosen Testaccount.
iThenticate irritierte damit, dass über 40 % der Links zu den Quellen eine HTTP-404-Fehlermeldung („file not found“) zurücklieferten, obwohl die Fundstellen verfügbar waren, wie eine Nachprüfung von Hand ergab. Letzteres wurde zusätzlich erschwert, weil sich Text aus dem Bericht nicht einfach kopieren ließ – wir mussten eine Phrase oder zwischen drei und fünf Wörter abschreiben und erneut per Google suchen. Das war auch bei vielen großen PDF-Quellen notwendig. Das heißt: iThenticate meldete Plagiat, und wir mussten weitere Nachforschungen anstellen, um die übernommenen Stellen zu finden. Ab und zu waren diese Stellen jedoch korrekt zitiert – was dem System entgangen war. Es ist zu befürchten, dass spätestens bei der Flut der 404-Fehler nicht nur ein IT-unerfahrener Jura-Professor den Test abgebrochen hätte. Schließlich waren bei 6 der 13 Teile, in die iThenticate die Arbeit zerstückelt hatte, die Top-Plagiate genau solche 404er.
Ephorus bietet eine angenehme Gegenüberstellung, beinhaltet jedoch für jede Quelle eine komplette Kopie der gesamten Dissertation. Wir nehmen an, dass darum der Test nach 10 Quellen abbrach, der Bericht hatte bereits 54 MByte erreicht. Dabei ist es schlicht überflüssig, die nicht plagiierten Teile zu wiederholen. Der kopierte Teil und die Angabe der Seitennummern sind das, was interessant ist.
PlagScan meldete zwar nicht viel, aber was gemeldet wurde, war tatsächlich Plagiat – wenn man die Stellen finden konnte. Es gibt für jede Stelle eine ausklappbare Liste der Quellen. Man muss jede Quelle einzeln öffnen und dann darin suchen, um die Stelle zu finden. Die Gesamtdarstellung verwendet fliegende Fenster, aber es gibt keine gute Gegenüberstellung. PlagAware weist eine mögliche Quelle aus – und übersieht eine Größere.
Urkund zeigte sich extrem langsam. Nach Ansicht des Anbieters hängt das damit zusammen, dass es mit der Menge an Treffern und Alternativtreffern (besonders von aktuellen Medien, die über den Fall berichten und eine Plagiatstelle zitieren) nicht zurechtkommt. Es gab viele Navigationsprobleme und die gemeldeten Zahlen sind nicht verständlich. Inzwischen lässt sich auch dieser Bericht nicht mehr laden.
Von den insgesamt 131 zum Testzeitpunkt durch GuttenPlag nachgewiesenen Quellen fand PlagAware 7 (5 %), iThenticate 30 (23 %), Ephorus 6 (5 %), PlagScan 19 (15 %) und Urkund 16 (12 %); alle zusammen entdeckten 38.
Bezogen auf die Top 20 online verfügbaren GuttenPlag-Quellen sieht die Ausbeute folgendermaßen aus: iThenticate fand davon 16 (80 %), Urkund 13 (65 %), PlagScan 12 (60 %) und PlagAware und Ephorus jeweils 6 (30 %).
Auch wenn iThenticate 80 % der wichtigsten Quellen gefunden hat, gingen sie in der schieren Menge von 1156 gemeldeten Quellen unter – ein großes Präzisionsproblem. Davon waren aber nur etwas mehr als 400 überhaupt länger als 20 Wörter. Wir haben nur die 117 Quellen untersucht, die 100 oder mehr Wörter lang waren. Gut 40 % hiervon waren jedoch unter der angegebenen URL nicht mehr im Internet auffindbar, unter anderem sechs der 13 „Top-Quellen“, die für jeden Abschnitt gemeldet wurden.
Unter diesen Top-Quellen befand sich ein absolut korrektes Zitat (auch das kam vor) und eine Korrespondenz zwischen zu Guttenbergs Bibliografie und der Bibliografie einer anderen Quelle. Immerhin waren drei von derselben, Volkmann-Schluck, und zwei von der zweithäufigsten Onlinequelle.
Fazit
Hätten die Jura-Professoren an der Universität Bayreuth die Plagiate in der Guttenberg-Dissertation mithilfe von Software entdecken können? Zumindest hätten die Erst- und Zweitgutachter einen Hinweis auf ein paar mögliche, nicht ausgewiesene Quellen bekommen und nach weiteren Übereinstimmungen forschen können.
Doch sämtliche untersuchten Systeme kranken an Mängeln in der Ergebnisdarstellung und an Bedienproblemen. So sind die gemeldeten Werte für die „Menge“ an Plagiat irreführend. Auch wenn Ephorus nur 5 % findet (und viele Systeme melden „grün, kein Plagiat“ für Werte unter 10 %) – die gefundenen Stellen sind schwerwiegende Plagiate.
Andererseits meldet iThenticate für Teil 5 der Dissertation 56 % Plagiat, doch acht der 13 Quellen mit mindestens 100 kopierten Wörtern sind nicht mehr im Internet unter den angegebenen URLs vorhanden. Zur Ehrenrettung der Software sei gesagt, dass eine Quantifizierung von Plagiat schwierig ist. So meldet GuttenPlagWiki 94 % der Seiten mit Plagiat – was gelegentlich in der Presse als Plagiatanteil von 94 % wiedergegeben wurde. Das stimmt so nicht, 63 % der Zeilen wäre eine treffendere Aussage über die Menge an Plagiat.
Unsere Empfehlung: Wenn Dozenten einen Verdacht haben und mit Google nicht fündig werden, sollten sie eines der Softwaresysteme einsetzen, besser noch zwei bis drei verschiedene. Sie brauchen aber Hilfestellung bei der Interpretation der Resultate, etwa durch geschultes Personal an den Universitätsbibliotheken. Grundsätzlich alle Arbeiten durch ein Plagiaterkennungssystem zu schicken, um dann oberhalb einer einfachen „Schwelle“ die Lehrkräfte zu alarmieren, führt zu viel zu vielen Fehlalarmen. Mit Vorsicht zu genießen ist der Vorschlag der Turnitin-Anbieter, Studierende mögen die Systeme selber anwenden. Das könnte nämlich einige auf die Idee bringen, Synonymisierungssysteme einzusetzen, die in der eigenen Arbeit systematisch die gefundenen Wörter durch Wörter ähnlicher oder gleicher Bedeutung ersetzen.
Die aktuellen Plagiaterkennungssysteme funktionieren am besten mit kleineren Texten wie Hausarbeiten. Für komplexe Texte mit vielen Zitaten und Fußnoten sind sie ungeeignet. So gewinnt bei der Plagiaterkennung eine hinreichend große Crowd, besonders weil sie viel exakter ist und auch Offline-Quellen einsetzen kann.
Prof. Dr. Debora Weber-Wulff
ist Professorin für Medieninformatik an der HTW Berlin.
Katrin Köhler
ist Master-Studentin in Internationale Medieninformatik an der HTW Berlin.
Literatur
[1] FAZ 5./6.3.2011, S. 4: www.faz.net/-01pecc
[2] Homepage des Teams an der HTW Berlin: plagiat.htw-berlin.de/software (js)
